
Vor kurzem hat GoDataDriven einen Cloudera-Cluster auf Microsoft Azure installiert. In diesem Artikel geben wir Ihnen einige Informationen über den Anwendungsfall, das implementierte Design und einige grundlegende Informationen über Microsoft Azure. Wir erörtern, wie Sie Cloudera auf Azure installieren können und teilen Best Practices zur Installation eines verteilten Systems auf Azure.
Im ersten Beitrag haben wir einige Informationen über den Anwendungsfall, das Design und einige grundlegende Informationen über Microsoft Azure besprochen. Wir haben einige Möglichkeiten aufgezeigt, wie Sie Cloudera auf Azure installieren können und welche bewährten Verfahren wir bei der Installation eines verteilten Systems auf Azure gesehen haben. Dies ist die zweite Hälfte dieser Serie.
Einführung in die Cloudera-Azure-Vorlage
Hinweis: Wenn Sie den ersten Teil dieses Beitrags gelesen haben oder wissen, was die Cloudera-Azure-Vorlage leisten kann, können Sie diesen Teil überspringen :)
Cloudera stellt eine ARM-Vorlage zur Verfügung, mit der ein Hadoop-Cluster installiert werden kann, einschließlich der Abstimmung von Betriebssystem und Netzwerk sowie der Abstimmung der Hadoop-Konfiguration. Die Vorlage finden Sie auf GitHub. Es gibt auch ein Azure VM-Image, das von Cloudera erstellt und gepflegt wird und bei der Bereitstellung verwendet wird. Dieses Image ist auf dem Azure Marketplace erhältlich. Sofort einsatzbereite Funktionen der Vorlage:
- Erstellen Sie eine Ressourcengruppe für alle Komponenten
- VNet und Subnetze erstellen
- Erstellen Sie Verfügbarkeitsgruppen. Platzieren Sie Master und Worker in verschiedenen Verfügbarkeitsgruppen
- Sicherheitsgruppen erstellen
- Erstellen Sie Masternode- und Workernode-Instanzen mit dem Cloudera VM Image (CentOS-Image, das von Cloudera erstellt und gepflegt wird). Die Vorlage verwendet automatisch Azure DS14-Maschinen, die die einzigen von Cloudera empfohlenen und unterstützten Maschinentypen für Hadoop-Installationen sind.
- Für jeden Host wird ein Premium Storage-Konto erstellt
- Fügen Sie den Rechnern Festplatten hinzu, formatieren und mounten Sie die Festplatten (10 Datenfestplatten von 1 TB pro Knoten)
- Vorwärts-/Rückwärtssuche zwischen Hosts mit der Datei /etc/hosts einrichten
- Abstimmen von Linux-Betriebssystemen und Netzwerkkonfigurationen wie SELinux deaktivieren, IPtables deaktivieren, TCP-Tuning-Parameter, große Seiten deaktivieren
- Einrichten der Zeitsynchronisation mit einem externen Server (NTPD)
- Einrichten des Cloudera Managers und der vom Cloudera Manager verwendeten Datenbank
- Einrichten von Hadoop-Diensten mit der Cloudera Python API
Die Vorlage hat auch einen Nachteil: Sie ist für den Start eines Clusters gedacht, aber Sie können keine zusätzlichen Datenknoten erstellen und dem Cluster hinzufügen. Die Vorlage stellt keinen Gateway-Rechner für Sie bereit.
Was haben wir geändert?
Nachdem wir die Lücken analysiert hatten, beschlossen wir, die Vorlage zu verwenden, aber einige Teile zu ändern, um alles installieren zu können, was wir brauchen. Wir beschlossen, die Cloudera-Azure-Vorlage zu verwenden, um das Netzwerk bereitzustellen, die Maschinen einzurichten, das Betriebssystem zu konfigurieren und den Cloudera Manager zu installieren. Dann haben wir den Cloudera Manager (also nicht die Cloudera-Azure-Vorlage) verwendet, um den CDH-Cluster zu installieren. Wir sind so vorgegangen, weil wir auf diese Weise die gewünschten Maschinen erhalten und sie anschließend dem Cluster hinzufügen können. Wenn zusätzliche Knoten benötigt werden, können wir dies mit der gleichen Vorlage tun.
Wir haben die folgenden Änderungen an der ursprünglichen Vorlage vorgenommen:
- Erstellung des virtuellen Netzwerks mit einer separaten Vorlage. Dadurch können wir die Anzahl der Subnetze ändern und eine Site2site-VPN-Verbindung herstellen. Die Cloudera-Vorlage wurde geändert, um ein bestehendes VNet und Subnetz zu verwenden
- Einrichten der DNS-Komponente des Active Directory für die Rechner, um Forward- und Reverse-Lookup durchzuführen
- Hinzufügen der HTTPS-Ports zu den Sicherheitsgruppen, da bei der Verwendung von TLS für Cloudera Manager verschiedene Ports verwendet werden
- IPv6 deaktivieren
- Verwenden Sie den vom Client bereitgestellten Zeitserver
- Verringerung der Anzahl der Datenplatten pro Knoten
- Wir haben die Hadoop-Komponenten selbst installiert, um besser kontrollieren zu können, was wohin kommt. Außerdem unterstützt die Vorlage nicht die Integration von Hadoop mit dem Active Directory, so dass wir dies manuell durchgeführt haben
- Fügen Sie der Vorlage einen neuen Knotentyp hinzu, um einen Gateway-Knoten einzurichten
Ändern der Vorlage
Um die Vorlage ändern zu können, mussten wir zunächst verstehen, wie die Vorlage funktioniert.
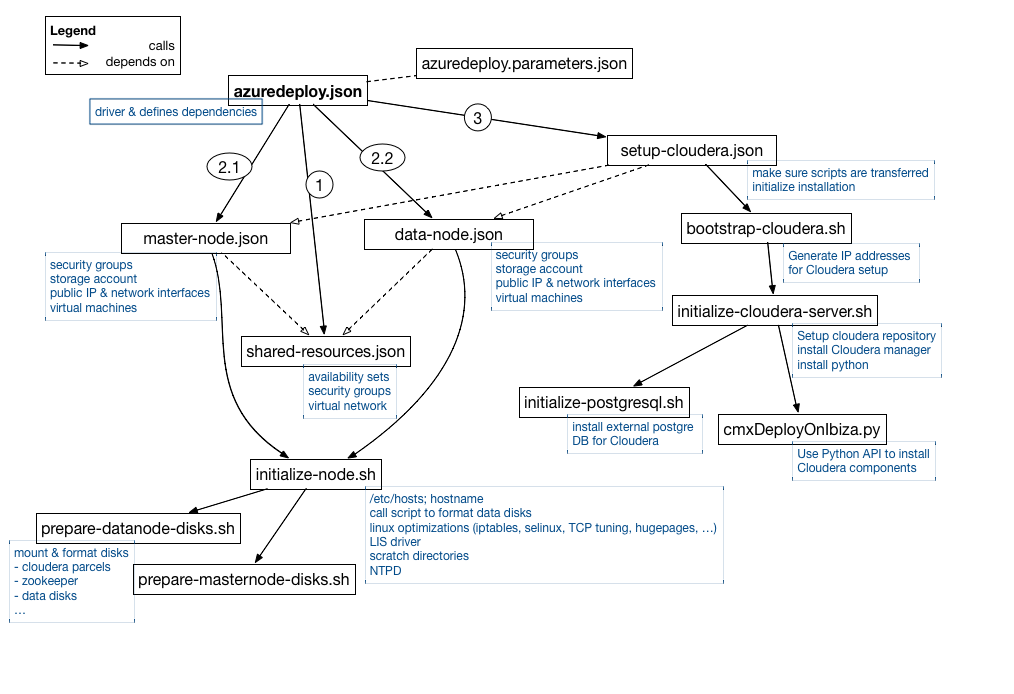
Wenn Sie die Bereitstellung über den Marketplace vornehmen, interagieren Sie über die Benutzeroberfläche mit der Datei azuredeploy.parameters.json, da in dieser Datei die Parameter angegeben werden. Diese Datei wird von der Hauptvorlagendatei azuredeploy.json gelesen, die die Abhängigkeiten zwischen den Elementen der Vorlagendatei definiert.
Zunächst erstellt die Vorlage das virtuelle Netzwerk, die Sicherheitsgruppen und die Verfügbarkeitsgruppen. Dies geschieht in shared-resouces.json.
Nach der Bereitstellung dieser Ressourcen können wir mit der Erstellung der virtuellen Maschinen beginnen, indem wir master-node.json und data-node.json parallel aufrufen. Diese Skripte richten die spezifischen Sicherheitsgruppen für Master- und Datenknoten ein, erstellen die Speicherkonten (eines pro Knoten), richten die Netzwerkschnittstellen ein und definieren die öffentlichen IPs. Auch die Rechner werden erstellt, und dann wird das Skript initialize-node.sh aufgerufen. In diesem Skript:
- hosts-Datei wird eingerichtet
- selinux ist deaktiviert
- iptables ist deaktiviert
- hugepages sind deaktiviert
- NTPD ist konfiguriert und gestartet
- Der Linux Integration Service-Treiber ist installiert. Dies ist eine Reihe von Treibern, die die Unterstützung synthetischer Geräte in unterstützten virtuellen Linux-Maschinen unter Hyper-V ermöglichen
- Scratch-Verzeichnisse werden erstellt
- Je nach Knotentyp werden die Skripte für die Festplatten aufgerufen (prepare-datanode-disks.sh oder prepare-masternode-disks.sh)
Was bewirken die Disketten-Skripte also? Diese Skripte bereiten die Rechner mit einer spezifischen, auf dem Betriebssystem basierenden Einstellung vor und rufen prepare-datanode-disks.sh oder prepare-masternode-disks.sh auf. Sie formatieren und mounten die verschiedenen Festplatten. Für den Datenknoten werden die 10 Datenfestplatten eingehängt und eine weitere Festplatte wird für die Cloudera-Pakete erstellt.
Auf den Master-Knoten wird eine Festplatte für die Cloudera-Pakete, eine weitere Festplatte für die externe PostgreSQL-DB, eine weitere Festplatte für den Zookeeper-Prozess und eine weitere Festplatte für den Quorum Journal Manager-Prozess erstellt.
Nachdem diese Skripte abgeschlossen sind, können wir mit der Installation von Cloudera auf den Rechnern beginnen. Die setup-cloudera.json wird aufgerufen und initialisiert die Installation durch den Aufruf von bootstrap-cloudera.sh. Dieses Skript sammelt die privaten IPs, die von der Installation verwendet werden sollen, und ruft dann initialize-cloudera-server.sh auf. Dieses Skript wird nur auf dem ersten Master-Knoten ausgeführt, bei dem es sich um den Cloudera Manager-Server handelt. Wir müssen hier einige spezielle Pakete installieren, darunter Python zur Installation der Hadoop-Dämonen und natürlich den cloudera-scm-server. Initialize-cloudera-server.sh ruft dann das Datenbank-Installationsskript (initialize-postgresql.sh) auf, das eine PostgreSQL-Datenbank für die mit dem Cloudera Manager verbundenen Dienste (wie Aktivitätsmonitor, Dienstverwaltung usw.) und auch eine separate Datenbank für den Hive-Metastor installiert. In dieser separaten Datenbank werden die Schemata der Tabellen für Hive und Impala gespeichert (bei Hive und Impala befinden sich die Daten selbst im HDFS, nur die Schemata werden in einer relationalen DB gespeichert).
Nachdem die Datenbank installiert ist, wird der Cloudera Manager gestartet und als letzter Schritt wird das Skript cmxDeployOnIbiza.sh auf dem ersten Masternode aufgerufen, um alle Hadoop-Dämonen auf verschiedenen Hosts zu installieren. Es verwendet Python, um Cloudera Manager über die Rest-API anzuweisen, die verschiedenen Komponenten zu installieren.
Jetzt sollten Sie einen laufenden Cluster haben. Wenn Sie die Vorlage im Modus 'Produktion' ausführen, erhalten Sie eine Cloudera CDH 5.4.x-Installation, bei der die verschiedenen Hadoop-Dämonen wie folgt auf den Knoten platziert sind:
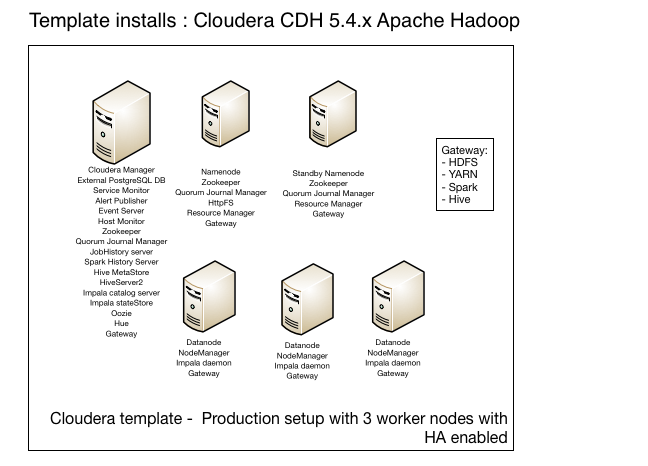
Die Vorlage unterstützt auch die Installation von Sentry, HBase, Flume, Sqoop und KMS. Diese Komponenten sind jedoch nicht standardmäßig aktiviert und können auch nicht einfach durch das Setzen einer Variable aktiviert werden, so dass Sie das Skript ändern müssen, um auch diese Komponenten zu installieren.
Nachdem wir verstanden haben, welche Datei was tut, haben wir begonnen, die Dinge zu ändern, und das werden wir im Rest dieses Beitrags erklären. Sie finden unsere geänderte Vorlage auf GitHub.
Verwendung eines bestehenden VNet/Subnetzes
Wir haben das VNet separat erstellt, indem wir eine Vorlage ähnlich der 101-create-site-to-site-vpn-Vorlage auf Azure github verwendet haben. Nachdem wir das VNET erstellt hatten, mussten wir den Teil aus der Cloudera-Vorlage herausnehmen, der ebenfalls ein VNet erstellt. Entfernen Sie in der Datei shared-resources.son den folgenden Teil:
{ "apiVersion": "2015-05-01-Vorschau", "Typ": "Microsoft.Network/virtualNetworks", "Name": "[parameters('networkSpec').virtualNetworkName]", "hängt ab von": [ "[concat('Microsoft.Network/networkSecurityGroups/', parameters('networkSpec').virtualNetworkName, '-sg')]" ], "Standort": "[Parameter('Ort')]", "Eigenschaften": { "addressSpace": { "addressPrefixes": [ "[parameter('networkSpec').addressPrefix]" ] }, "Teilnetze": [ { "Name": "[parameters('networkSpec').virtualNetworkSubnetName]", "Eigenschaften": { "addressPrefix": "[parameter('networkSpec').subnetPrefix]", "networkSecurityGroup": { "id": "[resourceId('Microsoft.Network/networkSecurityGroups', concat(parameters('networkSpec').virtualNetworkName, '-sg'))]" } } } ] } }
Dann haben wir eine neue Variable namens vNetResourceGroup in der azuredeploy.parameters.json hinzugefügt
"vnetResourceGroup": { "Wert": "my-networking" },
und wir haben dafür gesorgt, dass diese von der Vorlagendatei gelesen werden kann. Um dies zu erreichen, haben wir sie in der azuredeploy.json definiert:
"vnetResourceGroup": { "Typ": "string" },
In azuredeply.json haben wir auch dafür gesorgt, dass die VnetID nun auf diesen Parameter verweist. Die Variable VnetID befindet sich im Abschnitt networkSpec:
"VnetID": "[resourceId(parameter('vnetResourceGroup'),'Microsoft.Network/virtualNetworks', parameter('virtualNetworkName'))]"
Als Nächstes müssen wir in den Dateien master-node.json und data-node.json sicherstellen, dass der Subnetzbezug tatsächlich über die zuvor definierte VnetID hergestellt wird. Dies geschieht im ipConfigurations-Teil der Netzwerkschnittstellen:
"Teilnetz": { "id": "[concat(parameters('networkSpec').VnetID, '/subnets/', parameters('networkSpec').virtualNetworkSubnetName)]" },
Wenn Sie genau hinsehen, werden Sie feststellen, dass wir eigentlich keinen zusätzlichen Parameter zwischen der azuredeploy.json und der master-node.json/data-node.json senden müssen, obwohl wir einen neuen Parameter hinzugefügt haben. Das liegt daran, dass wir VNetID zu der Parametergruppe namens networkSpec hinzugefügt haben und diese Gruppe an die benötigten Vorlagendateien übertragen wird.
DNS zum Auflösen von Hostnamen verwenden
Um den DNS-Server für Forward- und Reverse-Lookup zu verwenden, mussten wir die Datei /etc/resolv.conf auf den Linux-Rechnern einrichten. Dazu mussten wir die IP-Adressen und Hostnamen der DNS-Server festlegen. Außerdem mussten wir den Hostnamen richtig einstellen, d.h. wir mussten das Domain-Suffix kennen. In einem ersten Schritt stellten wir sicher, dass alle diese Parameter in azuredeploy.parameters.json definiert sind:
"dns1IP": { "Wert": "172.20.210.4" }, "dns2IP": { "Wert": "172.20.210.5" }, "dns1Name": { "Wert": "dc1.meinedomain.nl" }, "dns2Name": { "Wert": "dc2.meinedomain.nl" }, "dnsNameSuffix": { "Wert": ".mydomain.nl" },
Wir mussten dafür sorgen, dass azuredeploy.json diese Parameter lesen kann:
"dnsNameSuffix": { "Typ": "string", "Metadaten": { "Beschreibung": "Internes DNS-Suffix" } }, "dns1IP": { "Typ": "string", "Metadaten": { "Beschreibung": "DNS IP" } }, "dns2IP": { "Typ": "string", "Metadaten": { "Beschreibung": "DNS IP" } }, "dns1Name": { "Typ": "string", "Metadaten": { "Beschreibung": "DNS-Name" } }, "dns2Name": { "Typ": "string", "Metadaten": { "Beschreibung": "DNS-Name" } },
Als nächstes haben wir die neuen Parameter mithilfe der komplexen Variable vmSpec in azuredeploy.json übertragen
"vmSpec": { "vmSize": "[Parameter('vmSize')]", "privateIPAddressPrefix": "[Parameter('nodeAddressPrefix')]", "adminBenutzername": "[Parameter('adminUserName')]", "adminPasswort": "[parameter('adminPasswort')]", "dnsNameSuffix": "[Parameter('dnsNameSuffix')]", "domainName": "[Parameter('DomainName')]", "hadoopAdmin": "[Parameter('hadoopAdmin')]", "dns1IP": "[Parameter('dns1IP')]", "dns2IP": "[Parameter('dns2IP')]", "dns1Name": "[Parameter('dns1Name')]", "dns2Name": "[Parameter('dns2Name')]", "masterNodeASName": "[concat(parameters('dnsNamePrefix'), '-mnAS')]", "dataNodeASName": "[concat(parameters('dnsNamePrefix'), '-dnAS')]" },
Auf diese Parameter kann nun über die Vorlagendateien master-node.json und data-node.json zugegriffen werden. In diesen Dateien müssen wir also dafür sorgen, dass die Parameter an die Skriptdatei initialize-node.sh übergeben werden. Wir haben gerade zusätzliche Befehlszeilenargumente für das Skript definiert, das im Teil Microsoft.Compute/virtualMachines/extensions aufgerufen wird, der einen Typ CustomScriptForLinux aufruft.
"commandToExecute": "[concat('sh initialize-node.sh "', parameters('vmSpec').adminUserName, '" ', 'masternode', ' " ', concat(variables('vmName'), copyIndex(),parameters('vmSpec').dnsNameSuffix), '" " ', parameters('vmSpec').dns1IP, '" " ', parameters('vmSpec').dns2IP, '" " ', parameters('vmSpec').dns1Name, '" " ', parameters('vmSpec').dns2Name, '" " ', parameters('vmSpec').hadoopAdmin, '" " ', parameters('vmSpec').domainName, '" >> /home/$ADMINUSER/initialize-masternode.log 2>&1')]"
Wenn Sie dieses Skript mit dem ursprünglichen Skript vergleichen, werden Sie feststellen, dass wir auch eine ganze Reihe von Befehlszeilenargumenten gelöscht haben, die für die Cloudera-Installation verwendet wurden, was wir mit der Vorlagendatei nicht tun.
Woher weiß das Skript initialize-node.sh also, ob es einen Datenknoten oder einen Masterknoten installiert? Nun, wenn Sie genau hinsehen, sehen Sie, dass das zweite Argument, das an dieses Skript übergeben wird, tatsächlich der Knotentyp ist. Im Skript initialize-node.sh lesen wir dann die Befehlszeilenargumente:
ADMINUSER=$1 NODETYPE=$2 MYHOSTNAME=$3 DNS1IP=$4 DNS2IP=$5 DNS1NAME=$6 DNS2NAME=$7 HADOOPADMIN=$8 DOMAINNAME=$9
Wir können also /etc/resolv.conf einrichten. Um sicherzustellen, dass diese Datei beim Neustart nicht überschrieben wird, haben wir außerdem eine Datei dhclient-enter-hooks erstellt.
Katze >
/etc/dhclient-enter-hooks
#!/bin/sh
make_resolv_conf() {
echo "macht nichts an der resolv.conf"
}
EOF
Katze >
/etc/resolv.conf
#!/bin/sh
search $DOMAINNAME
nameserver $DNS1IP
nameserver $DNS2IP
EOF
chmod a+x /etc/dhclient-enter-hooks
Ipv6 deaktivieren
In der Skriptdatei initialize-node.sh können wir einfach die folgenden Zeilen hinzufügen:
echo "NETWORKING_IPV6=no" >> /etc/sysconfig/network echo "SUCHEN=${DOMAINNAME}" >> /etc/sysconfig/network-scripts/ifcfg-eth0 echo "NETWORKING_IPV6=no" >> /etc/sysconfig/network-scripts/ifcfg-eth0 /etc/init.d/ip6tables speichern /etc/init.d/ip6tables stoppen chkconfig ip6tables aus
und IPv6 wird deaktiviert.
Anderen NTPD-Server konfigurieren
In der Skriptdatei initialize-node.sh fügen wir die folgenden Zeilen hinzu:
sed -i s/^server/#server/' /etc/ntp.conf echo "Server ${DNS1NAME} iburst" >> /etc/ntp.conf Dienst ntpd starten dienst ntpd status chkconfig ntpd ein
und NTPD stellt eine Verbindung zum PDC-Server her, um die Zeit zu erhalten. Dieser Domänencontroller stellt seinerseits eine Verbindung zum externen NTPD-Server her, um seine Zeit zu erhalten. Seltsamerweise schlägt Microsoft vor, nur den PDC mit dem externen Zeitserver zu verbinden. Der BDC sollte seine Zeit vom PDC beziehen. Ich denke, das sollte kein großes Problem sein, es sei denn, Ihr PDC fällt für längere Zeit aus...
Bereitstellen der (angepassten) Vorlage
Bevor Sie mit der Bereitstellung beginnen, sollten Sie zunächst prüfen, ob Sie die angeforderten Maschinen über Ihr Azure-Abonnementkonto starten können. Das Konto hat standardmäßig ein Core-Limit von 20. Es ist wichtig zu betonen, dass die Quoten für Ressourcen in Azure-Ressourcengruppen pro Region gelten, auf die Ihr Abonnement Zugriff hat. Wenn Sie eine Quotenerhöhung beantragen möchten, müssen Sie entscheiden, wie viele Kerne Sie in welcher Region nutzen möchten. Stellen Sie dann eine spezifische Anfrage für Azure Resource Group Core-Quoten für die von Ihnen gewünschten Mengen und Regionen.
Um eine Cloudera PoC-Umgebung mit der Vorlage zu installieren, benötigen Sie mindestens 4 * 16 Kerne, wenn Sie nur 3 Worker Nodes wünschen. Jede von der Cloudera-Vorlage bereitgestellte Maschine ist eine DS14-Maschine mit 16 Kernen. Wenn Sie nichts an der Vorlage ändern möchten, können Sie diese einfach über den Azure Marketplace bereitstellen. In diesem Fall geben Sie einfach die von der Benutzeroberfläche angeforderten Parameter ein und schon haben Sie einen laufenden Cluster.
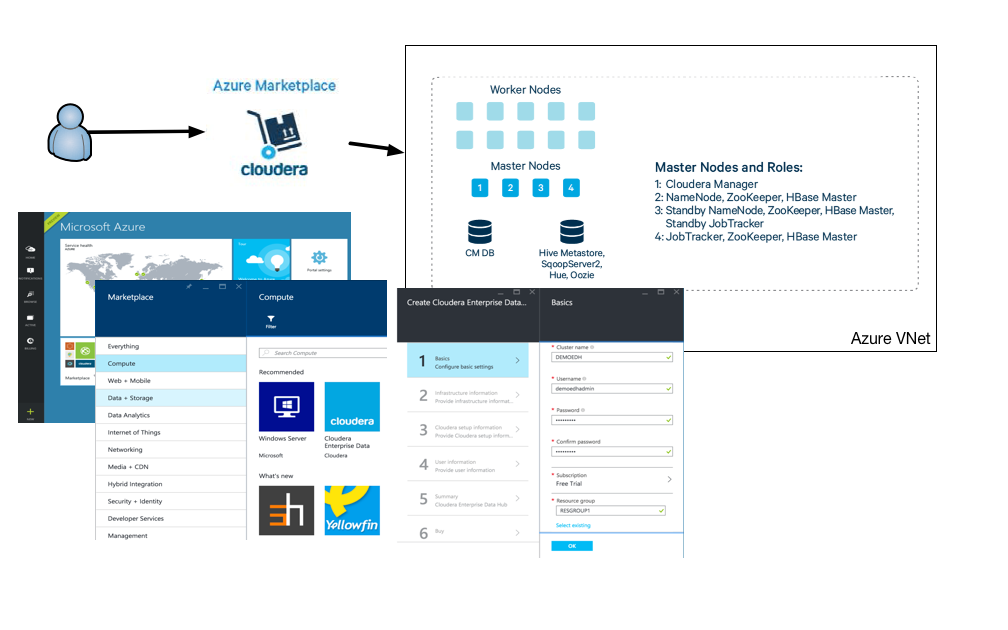
Wenn Sie etwas in der Vorlage ändern, wie wir es getan haben, müssen Sie sicherstellen, dass die Änderungen in einem öffentlichen GitHub-Repository gespeichert sind, da der Bereitstellungsprozess sonst nicht darauf zugreifen kann. Sie können Parameter verwenden, die in der Datei azuredeploy.parameters.json definiert sind. Diese Datei enthält sensible Informationen und sollte sich daher nicht im öffentlichen GitHub-Repository befinden.
Wenn Sie kein öffentliches GitHub-Repository anlegen möchten, können Sie die Skriptdateien auch im Azure-Speicher ablegen und die Informationen zum Speicherkonto und zum Schlüssel angeben.
Um Ihre eigene Vorlage in GitHub verwenden zu können, müssen Sie die Variable scriptsUri in azuredeploy.json ändern. Zuerst definieren wir einen Parameter:
"scriptUri": { "Typ": "string", "Metadaten": { "Beschreibung": "Das öffentliche Github-Repositorium, in dem sich die Skripte befinden." }
Dann stellen wir sicher, dass wir diesen Parameter in azuredeploy.json im Abschnitt Variablen verwenden:
"scriptsUri": "[Parameter('scriptUri')]",
Dann geben wir diese scriptUri in azuredeploy.parameters.json an:
"scriptUri": { "Wert": "https://raw.githubusercontent.com/godatadriven/public_cloudera_on_azure/master" }
Da wir für die Bereitstellung nicht den Marktplatz verwenden, müssen wir eine separate Ressourcengruppe erstellen, in der wir die erstellten Assets ablegen. Auf diese Weise wird es einfacher, die Ressourcen innerhalb dieser Gruppe zu ändern und zu löschen. Mit der Azure CLI können Sie eine Ressourcengruppe auf folgende Weise erstellen:
azure Gruppe erstellen -n "meineRessourcenGruppe" -l "Westeuropa"
Und dann können Sie mit der Bereitstellung Ihres Clusters beginnen:
azure group deployment create -g myResourceGroup -n "MyClouderaDeployment" -f azuredeploy.json -e azuredeploy-parameters.json
Stellen Sie sicher, dass Sie nach der Bereitstellung das Passwort des Benutzers, den Sie gerade für den Zugriff auf die Hosts erstellt haben, und auch das Passwort des Cloudera Manager-Benutzers ändern. Derzeit sind die Passwörter in Ihrer Bereitstellungskonfiguration auf Azure deutlich zu sehen. Auch die an die Shell-Skripte übergebenen Parameter sind auf den Hosts in der Datei /var/log/azure/..../extension.log zu sehen. Hier sehen Sie also auch das Passwort für den Cloudera Manager. Wenn Sie dies ändern möchten, sollten Sie die Integration von Azure Key Vault in die Skripte in Betracht ziehen. Was ist Azure Key Vault? Auf diese Weise könnten Sie SSH-Schlüssel für den Zugriff auf Ihre Rechner verwenden.
Wir haben uns entschieden, die Vorlage ohne Key Vault auszuführen und lediglich dafür zu sorgen, dass sich der angegebene Benutzer nicht mit einem Passwort anmelden kann. Da wir den Cloudera Manager nicht mit der Vorlage installiert haben, mussten wir uns keine Gedanken über das Passwort machen.
Zusammenfassung
Die Cloudera-Vorlage ist eine hervorragende Grundlage für die Bereitstellung eines Hadoop-Clusters auf Azure. Wenn Sie nicht zu viele exotische Anforderungen haben, können Sie die Vorlage so verwenden, wie sie ist. Sie haben die Freiheit und die Verantwortung für die Wartung der Maschinen und des Clusters. Auch wenn Sie spezielle Anforderungen haben, ist die Vorlage ein guter Ausgangspunkt und es ist nicht schwer, sie an Ihre Bedürfnisse anzupassen.




Contact