
Vor kurzem hat GoDataDriven einen Cloudera-Cluster auf Microsoft Azure installiert. In diesem Artikel geben wir Ihnen einige Informationen über den Anwendungsfall, das implementierte Design und einige grundlegende Informationen über Microsoft Azure. Wir erörtern, wie Sie Cloudera auf Azure installieren können und teilen Best Practices zur Installation eines verteilten Systems auf Azure.
Einführung
Die Verarbeitung großer Mengen unstrukturierter Daten erfordert erhebliche Rechenleistung und auch Wartungsaufwand. Da die Auslastung der Rechenleistung typischerweise aufgrund von zeitlichen und saisonalen Einflüssen und/oder zu bestimmten Zeiten laufenden Prozessen schwankt, ist eine Cloud-Lösung wie Microsoft Azure eine gute Option, um leicht skalieren zu können und nur für das zu zahlen, was tatsächlich genutzt wird.
Der Anwendungsfall: Data Science-Infrastruktur für einen großen europäischen Flughafen
Um Daten zu untersuchen und zu analysieren, wandte sich einer der größten europäischen Flughäfen an GoDataDriven, um eine Vorproduktionsumgebung mit angemessenen Sicherheitsmaßnahmen einzurichten, die robust genug für die Produktionslast ist. Cloudera wurde als Hadoop-Distribution ausgewählt, die auf MS Azure installiert werden sollte.
Der erste Anwendungsfall, der die Installation von Cloudera motivierte, war die Möglichkeit, die Computing-Mechanismen zu nutzen, die für die vorausschauende Wartung der Anlagen des Flughafens zur Verfügung stehen. Durch die Sammlung von Daten aus allen Anlagen im Cloudera-Cluster konnte der Flughafen auf der Grundlage von Stromverbrauch, Besucherströmen und Sensordaten Vorhersagemodelle für die Wartung entwickeln.
Anforderungen & Design
Anforderungen
Die allgemeinen Anforderungen für unseren Anwendungsfall waren:
- Cloudera Enterprise Hadoop auf Azure installieren
- Stellen Sie sicher, dass Single Sign-On möglich ist
- Um die Kosten zu senken, verwenden Sie zunächst nur 5 Worker Nodes mit jeweils drei 1-TB-Datenfestplatten.
Und die folgenden technischen Anforderungen wurden hinzugefügt:
- Setzen Sie 3 Master-Knoten ein, damit die Last bewältigt werden kann, wenn der Cluster erweitert wird.
- Stellen Sie sicher, dass HDFS und YARN mit aktivierter Hochverfügbarkeit konfiguriert sind
- Verbinden Sie den Cloudera-Cluster mit dem Active Directory, um die Benutzer zu authentifizieren, die den Cluster nutzen dürfen.
- Installieren und konfigurieren Sie Sentry, um die Zugriffskontrolle zu gewährleisten.
- Richten Sie einen Gateway-Rechner ein, von dem aus die Benutzer arbeiten können. Auf diesem Gateway würden wir auch RStudio und IPython installieren, damit diese für die Analyse verwendet werden können
Entwurf
Unser Ziel war es, einen produktionsreifen Hadoop-Cluster aufzubauen, einschließlich der Bereitstellung von Maschinen. Natürlich gab es auch einige sicherheitsrelevante Anforderungen, die wir berücksichtigen mussten. Zum Beispiel: Benutzer und Administrator mussten einen VPN-Tunnel verwenden, um auf die Azure-Umgebung zugreifen zu können. Single Sign-On musste auf allen Rechnern aktiviert werden und Sentry musste konfiguriert werden.
Also haben wir ein Design entworfen, das Sie in der Abbildung unten sehen:
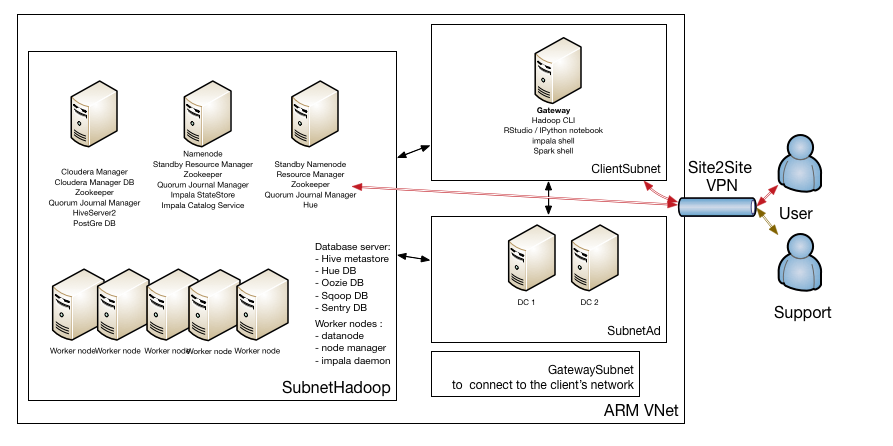
Das GatewaySubnet wird benötigt, um das Site2Site VPN zwischen dem Client-Netzwerk und dem Azure-Netzwerk, in dem sich der Hadoop-Cluster befindet, einrichten zu können.
Für die Benutzerverwaltung haben wir uns entschieden, zwei Active Directory Server einzurichten, die auch Domain Name Server sind. Diese befinden sich in ihrem eigenen Subnetz.
Aufgrund des hohen Datenverkehrs zwischen allen Knoten im Cluster befinden sich die Hadoop-Maschinen in einem eigenen Subnetz. Sie fragen sich vielleicht warum, aber lassen Sie uns kurz erklären, wie HDFS funktioniert: Wenn Sie eine Datei in HDFS schreiben, wird diese Datei in Blöcke aufgeteilt (die Blockgröße beträgt in der Regel 128 MB) und diese Blöcke werden auf den Datanodes abgelegt. Jeder Block hat einen Replikationsfaktor von 3. Nur der Master-Knoten (Namenode) weiß, welcher Block zu welcher Datei gehört. Der Namenode speichert keine Blöcke, aber er verwaltet den aktiven Replikationsfaktor. Wenn ein Client eine Datei aus dem HDFS lesen möchte, wendet er sich zunächst an den Namenode, um den Speicherort der Blöcke zu erfahren und dann die Blöcke von den Datanodes zu lesen. Die Datanodes senden Heartbeats an den Namenode und wenn der aktive Namenode feststellt, dass ein Block nicht den angeforderten Replikationsfaktor hat, weist er einen anderen Datanode an, den betreffenden Block zu kopieren.
Sie sehen also, dass es eine Menge Datenverkehr zwischen Namenode - Datanode und auch zwischen Datanode - Datanode gibt. Und hier haben wir nur die Kommunikation zwischen einer Komponente erwähnt, HDFS....
Wir haben uns dafür entschieden, den Hadoop-Cluster in einem eigenen Subnetz unterzubringen, weil wir so auch besser einschränken können, wer auf dieses Subnetz zugreifen kann.
Wir haben auch ein ClientSubnet für die Rechner, die auf den Cluster zugreifen können. Benutzer können sich mit den Rechnern in diesem Subnetz verbinden und ihre Analysen durchführen, aber sie können nicht per SSH auf die Rechner im Hadoop-Subnetz zugreifen.
Durch die Konfiguration von Single Sign-On über Active Directory auf Linux-Ebene und die Konfiguration von Kerberos über Active Directory für die Hadoop-Dienste können Benutzer überall ein einziges Passwort verwenden.
Um dem Kunden eine Arbeitsumgebung zur Verfügung stellen zu können, mussten wir ein paar Dinge über Microsoft Azure, den bevorzugten Cloud-Anbieter des Kunden, lernen.
Microsoft Azure Grundlagen zum Starten eines Clusters
Microsoft Azure ist ein Cloud-Dienst für Infrastructure-as-a-Service (IaaS) und Platform-as-a-Service (PaaS) mit Rechenzentren rund um den Globus. Wir brauchten nur den IaaS-Teil, um das Netzwerk einzurichten und die Maschinen zu starten, also werden wir das im Folgenden erklären.
Für Cloudera Enterprise-Implementierungen auf Azure sind die folgenden Serviceangebote relevant:
- Azure Virtual Network (VNet), ein logisches Netzwerk-Overlay, das Dienste und VMs enthalten kann und über ein VPN mit Ihrem lokalen Netzwerk verbunden werden kann.
- Azure Virtual Machines ermöglichen es Endbenutzern, virtuelle Maschinen verschiedener Konfigurationen bei Bedarf zu mieten und für die Zeit der Nutzung zu bezahlen. Images werden in Azure verwendet, um eine neue virtuelle Maschine mit einem Betriebssystem zu versehen. In Azure können zwei Arten von Images verwendet werden: VM-Image und Betriebssystem-Image. Siehe Über Images für virtuelle Maschinen Ein VM-Image enthält ein Betriebssystem und alle Festplatten, die mit einer virtuellen Maschine verbunden sind, wenn das Image erstellt wird. Dies ist die neuere Art von Image. Bevor VM-Images eingeführt wurden, konnte ein Image in Azure nur ein allgemeines Betriebssystem und keine zusätzlichen Festplatten enthalten. Ein VM-Image, das nur ein allgemeines Betriebssystem enthält, ist im Grunde dasselbe wie der ursprüngliche Imagetyp, das OS-Image. Aus einem VM-Image können Sie mehrere VMs bereitstellen. Diese virtuellen Maschinen werden auf dem Hypervisor ausgeführt. Die Bereitstellung kann über das Azure-Portal oder über die PowerShell oder die Azure-Befehlszeilenschnittstelle erfolgen.
- Azure Storage bietet die Persistenzschicht für Daten in Microsoft Azure. Pro Abonnement können bis zu 100 einzigartige Speicherkonten erstellt werden. Cloudera empfiehlt Premium Storage, das Daten auf der neuesten Technologie von Solid State Drives (SSDs) speichert, während Standard Storage Daten auf Hard Disk Drives (HDDs) speichert. Ein Premium-Storage-Konto unterstützt derzeit nur Festplatten von virtuellen Azure-Maschinen. Premium Storage bietet leistungsstarke Festplattenunterstützung mit niedriger Latenz für I/O-intensive Arbeitslasten, die auf Azure Virtual Machines ausgeführt werden. Sie können mehrere Premium Storage-Festplatten an eine virtuelle Maschine (VM) anschließen. Mit Premium Storage können Ihre Anwendungen über bis zu 64 TB Speicherplatz pro VM verfügen und 80.000 IOPS (Eingabe-/Ausgabevorgänge pro Sekunde) pro VM und 2000 MB pro Sekunde Festplattendurchsatz pro VM bei extrem niedrigen Latenzen für Lesevorgänge erreichen. Cloudera empfiehlt ein Speicherkonto pro Knoten, um höhere IOPS nutzen zu können. Die Auswirkungen der Verwendung von SSD- gegenüber HDD-Laufwerken für Hadoop können Sie im Blog Die Wahrheit über MapReduce-Leistung auf SSD nachlesen.
- Availability Sets bieten Redundanz für Ihre Anwendung und stellen sicher, dass während eines geplanten oder ungeplanten Wartungsereignisses mindestens eine virtuelle Maschine verfügbar ist und die 99,95% Azure SLA erfüllt.
- Netzwerksicherheitsgruppen ermöglichen die Segmentierung innerhalb eines virtuellen Netzwerks (VNet) sowie die vollständige Kontrolle über den Datenverkehr, der in eine virtuelle Maschine in einem VNet eintritt oder aus ihr austritt. Außerdem lassen sich damit Szenarien wie DMZs (demilitarisierte Zonen) realisieren, die es Benutzern ermöglichen, Backend-Dienste wie Datenbanken und Anwendungsserver streng zu schützen.
Modi für die Bereitstellung
Zurzeit stehen in Azure zwei Bereitstellungsmodi zur Verfügung:
- ASM (Azure Service Management)
- ARM (Azure Ressourcen-Manager)
Die ASM-API ist die "alte" oder "klassische" API und steht in Verbindung mit dem Webportal.Azure Service Management ist eine XML-gesteuerte REST-API, die im Vergleich zu JSON einen gewissen Overhead bei API-Aufrufen verursacht.
Die Azure Resource Manager (ARM) API ist eine JSON-gesteuerte REST-API zur Interaktion mit Azure-Cloud-Ressourcen. Microsoft empfiehlt die Bereitstellung im ARM-Modus.
Einer der Vorteile der ARM-API ist, dass Sie Cloud-Ressourcen als Teil einer so genannten "ARM JSON-Vorlage" deklarieren können. Eine ARM JSON-Vorlage ist eine speziell erstellte JSON-Datei, die Definitionen von Cloud-Ressourcen enthält. Sobald die Ressourcen in der JSON-Vorlage deklariert sind, wird die Vorlagendatei in einem Container namens Ressourcengruppe bereitgestellt. Eine ARM-Ressourcengruppeist ein logischer Satz korrelierter Cloud-Ressourcen, die sich ungefähr eine Lebensdauer teilen.Mit dem ARM-Modus können Sie Ressourcen parallel bereitstellen, was in ASM eine Einschränkung war.
Das neue Azure Ibiza Preview Portal wird für die Bereitstellung von Azure Cloud-Ressourcen mit ARM verwendet. Wenn Sie Cloud-Ressourcen über das "alte" Azure-Portal bereitstellen, werden sie über die ASM-API bereitgestellt. Sie sind nicht auf das Portal beschränkt, um Ihre Vorlagen bereitzustellen. Sie können die PowerShell oder die Azure-Befehlszeilenschnittstelle verwenden, um alle Azure-Ressourcen zu verwalten und vollständige Vorlagen bereitzustellen. Die Azure CLI basiert auf NodeJs und ist daher in allen Umgebungen verfügbar. Sowohl ARM als auch ASM sind Modi, die über die CLI konfiguriert werden können. Sie können überprüfen, in welchem Modus Sie arbeiten, indem Sie die
azure konfiguration
und ändern Sie den Modus mit dem Befehl
azure config mode <arm/asm> Befehl.
Wenn Sie sich für ein Bereitstellungsmodell entscheiden, müssen Sie darauf achten, dass Ressourcen, die im ASM-Modus bereitgestellt werden, von den Ressourcen, die im ARM-Modus bereitgestellt werden, standardmäßig nicht gesehen werden können. Wenn Sie dies erreichen wollen, müssen Sie einen VPN-Tunnel zwischen den beiden VNets einrichten.
Um die Unterschiede zwischen ASM und ARM besser zu verstehen, lesen Sie den Artikel Azure Compute, Network, and Storage Providers unter Azure Resource Manager.
Wie installiert man Cloudera auf Azure?
Es gibt mehrere Möglichkeiten, wie Sie Cloudera auf Azure installieren können. Nach einigen Überlegungen haben wir uns für die folgenden 2 Szenarien entschieden:
-
Installieren Sie alles von Grund auf neu:
- Bereitstellung von Maschinen und Netzwerken mit Azure CLI
- Verwenden Sie ein Provisioning-Tool (wir bevorzugen Ansible), um die Linux-Konfiguration durchzuführen.
- Cloudera Manager installieren
- Installieren Sie CDH (Cloudera Distribution für Apache Hadoop) mit Cloudera Manager
-
Cloudera stellt eine ARM-Vorlage zur Verfügung, mit der ein Hadoop-Cluster installiert werden kann, einschließlich der Abstimmung von Betriebssystem und Netzwerk sowie der Abstimmung der Hadoop-Konfiguration. Die Vorlage finden Sie auf GitHub. Es gibt auch ein Azure VM-Image, das von Cloudera erstellt und gepflegt wird und bei der Bereitstellung verwendet wird. Dieses Image ist auf dem Azure Marketplace verfügbar. Sofort einsatzbereite Funktionen der Vorlage:
- Erstellen Sie eine Ressourcengruppe für alle Komponenten
- VNet und Subnetze erstellen
- Erstellen Sie Verfügbarkeitsgruppen. Platzieren Sie Master und Worker in verschiedenen Verfügbarkeitsgruppen
- Sicherheitsgruppen erstellen
- Erstellen Sie Masternode- und Workernode-Instanzen mit dem Cloudera VM Image (CentOS-Image, das von Cloudera erstellt und gepflegt wird). Die Vorlage verwendet automatisch Azure DS14-Maschinen, die die einzigen von Cloudera empfohlenen und unterstützten Maschinentypen für Hadoop-Installationen sind.
- Für jeden Host wird ein Premium Storage-Konto erstellt
- Fügen Sie den Rechnern Festplatten hinzu, formatieren und mounten Sie die Festplatten (10 Datenfestplatten von 1 TB pro Knoten)
- Vorwärts-/Rückwärtssuche zwischen Hosts mit der Datei /etc/hosts einrichten
- Abstimmen von Linux-Betriebssystemen und Netzwerkkonfigurationen wie SELinux deaktivieren, IPtables deaktivieren, TCP-Tuning-Parameter, große Seiten deaktivieren
- Einrichten der Zeitsynchronisation mit einem externen Server (NTPD)
- Einrichten des Cloudera Managers und der vom Cloudera Manager verwendeten Datenbank
- Einrichten von Hadoop-Diensten mit der Cloudera Python API
Die Vorlage hat auch einen Nachteil: Sie ist für den Start eines Clusters gedacht, aber Sie können keine zusätzlichen Datenknoten erstellen und dem Cluster hinzufügen. Die Vorlage stellt keinen Gateway-Rechner für Sie bereit.
Nachdem wir die Lücken zwischen der von Cloudera bereitgestellten Vorlage und den Anforderungen des Kunden analysiert hatten, entschieden wir uns für einen goldenen Mittelweg:
- Verwenden Sie die Cloudera-Azure-Vorlage, um das Netzwerk bereitzustellen, die Maschinen einzurichten, das Betriebssystem zu konfigurieren und den Cloudera Manager zu installieren.
- Verwenden Sie den Cloudera Manager (also nicht die Cloudera-Azure-Vorlage), um den CDH-Cluster zu installieren.
In unserem nächsten Blog werden wir näher darauf eingehen, worin diese Lücken bestanden.
Bewährte Verfahren für eine manuelle Implementierung
Wir haben auch einige bewährte Verfahren ermittelt, die wir beachten müssen, wenn wir die Vorlage nicht verwenden wollen:
- Wenn Sie ein Linux-Image auf Azure bereitstellen, wird ein temporäres Laufwerk hinzugefügt. Wenn Sie die DS14-Maschinen verwenden, ist die angehängte Festplatte auf /mnt/resource eine SSD und ziemlich groß (etwa 60 GB). Dieser temporäre Speicher darf nicht zum Speichern von Daten verwendet werden, die Sie nicht verlieren wollen. Der temporäre Speicher befindet sich auf dem physischen Rechner, der Ihre VM beherbergt. Ihre VM kann aus verschiedenen Gründen (Hardwareausfall usw.) jederzeit auf einen anderen Host umziehen. In diesem Fall wird Ihre VM auf dem neuen Host unter Verwendung des Betriebssystemlaufwerks von Ihrem Speicherkonto neu erstellt. Alle Daten, die auf dem vorherigen temporären Laufwerk gespeichert sind, werden nicht migriert und Ihnen wird ein temporäres Laufwerk auf dem neuen Host zugewiesen. Das temporäre Laufwerk auf virtuellen Maschinen in Windows Azure verstehen
- Die Root-Partition des Betriebssystems (auf der sich auch das Verzeichnis /var/log befindet) ist ziemlich klein (10 GB). Das ist perfekt für eine Betriebssystemfestplatte, aber Cloudera legt auch die Pakete (eine alternative Form der Verteilung für Cloudera Hadoop) in /opt/cloudera und die Protokolle in /var/logs ab. Diese nehmen ziemlich viel Platz in Anspruch, so dass eine 10 GB Festplatte nicht ausreicht. Deshalb sollten Sie die Pakete und die Protokolldatei auf eine andere Festplatte verschieben. (Zur Erinnerung: Normalerweise übernimmt die Vorlage diese Aufgabe für Sie.) Wenn Sie Cloudera installieren, ohne diese Dateien auf eine andere Festplatte zu verschieben, werden Sie im Cloudera Manager Warnmeldungen sehen, dass nicht genügend freier Speicherplatz verfügbar ist.
- In einem verteilten System, also auch für einen Hadoop-Cluster (insbesondere wenn Kerberos verwendet wird), ist die Zeitsynchronisation zwischen den Hosts unerlässlich. Microsoft Azure bietet eine Zeitsynchronisierung, aber die VMs lesen die (emulierte) Hardware-Uhr von der zugrunde liegenden Hyper-V-Plattform nur beim Booten. Von diesem Zeitpunkt an wird die Uhr vom Dienst mit Hilfe eines Timer-Interrupts aufrechterhalten. Dies ist natürlich keine perfekte Zeitquelle, und deshalb müssen Sie NTP-Software verwenden, um die Genauigkeit zu gewährleisten.
- Wenn Sie Linux auf Azure ausführen, installieren Sie die Linux Integration Services (LIS) - eine Reihe von Treibern, die die Unterstützung synthetischer Geräte in unterstützten virtuellen Linux-Maschinen unter Hyper-V ermöglichen.
Weitere Informationen
Zuvor, am 3. November 2015, hat GoDataDriven bereits ein Webinar über den Betrieb von Cloudera auf MS Azure präsentiert, das aufgezeichnet wurde und nach der Registrierung angesehen werden kann.
Fortsetzung folgt...
Im nächsten Beitrag werden wir näher auf die Lücken eingehen, die wir zwischen unseren Kundenanforderungen und der Cloudera-Vorlage gesehen haben, und wir werden zeigen, wie wir die Cloudera-Vorlage modifiziert haben, um unsere Anforderungen zu erfüllen.




Contact