In unserem vorherigen Beitrag über Lucene haben wir verschiedene positive Aspekte von Lucene hervorgehoben. Jetzt wollen wir uns ansehen, wie Lucene in einer verteilten Umgebung verwendet wurde.
Wir haben diskutiert, ob wir alle benötigten Daten aus dem Lucene-Index selbst abrufen oder alternativ den hybriden Ansatz wählen, bei dem zuerst Lucene und dann die Datenbank abgefragt wird. Im Rahmen unserer geschäftlichen Anforderungen haben wir den ersten Ansatz aus mehreren Gründen nicht bevorzugt, und zwar:
- Die Verwaltung der Anwendungssitzungen wurde aus Gründen, die in diesem Beitrag nicht behandelt werden können, in der Datenbank durchgeführt.
- Die Suche erforderte Datenbankzugriff für einige zusätzliche Einstellungen, die nur in der Datenbank verfügbar sind, sowie für die Erinnerung an die Suchfilter-Schlüsselwörter
- Wir haben uns für eine hybride Form der Lucene-Indizierung entschieden, damit wir nicht alle Datenbankdaten im Index duplizieren müssen und am Ende einen riesigen Index im Dateisystem haben. Die Aktualisierung des Index bei jeder Änderung der Datenbank ist ein teurer Prozess.
- Die Verwendung von Lucene nur für die Suche bedeutet, dass wir die Felder nicht wirklich speichern müssen, sondern sie nur in Token umwandeln, wodurch die Indexgröße verringert und die Suchgeschwindigkeit relativ erhöht wird.
NoSQL anstelle des hybriden Ansatzes wäre ein besserer Fall gewesen. Da NoSQL die Lucene-Indizierung für die Dokumentenspeicherung verwendet, benötigen wir keine Datenbankschicht und können alle Daten in NoSQL speichern, abfragen und durchsuchen.
Die Verwendung von NoSQL für unsere geschäftlichen Anforderungen war aus verschiedenen architektonischen Gründen nicht möglich, da wir mit einem Netzwerk von Anwendungen und Systemen arbeiten, in dem viele bidirektionale Datenflüsse zwischen verschiedenen Anwendungen auf verschiedenen Plattformen stattfinden.
Aufgrund des aktualisierten und komplexen Sicherheitsmodells für die verschiedenen Anwendungen im System beschränken wir die Verwendung von Lucene-Indizes jetzt auf die Freitextsuche. Dieses Sicherheitsmodell erfordert, dass die Anwendung auf die Datenbank zugreift, bevor sie die Daten an die Benutzer weitergibt. In diesem Szenario würde der hybride Ansatz mehr oder weniger die gleiche Leistung wie der reine Datenbankansatz bieten. Die Freitextsuche ist der einzige Bereich, in dem sich Lucene in unserem aktuellen Geschäftsszenario bewährt hat.
Ich bin sicher, dass es auch in anderen Szenarien eingesetzt werden kann, wenn man bedenkt, dass NoSQL immer ausgereifter, stabiler, funktionsreicher und akzeptierter wird.
Verteilte Umgebung
Eine verteilte Umgebung war erforderlich, um die globalen Organisationen von Unilever mit Hauptservern in Großbritannien und den Niederlanden zu unterstützen.
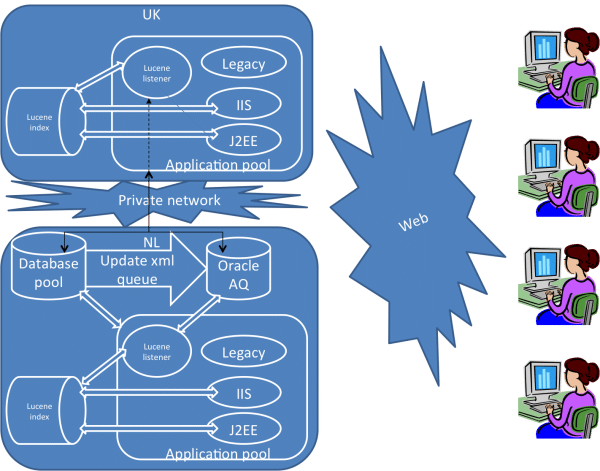
Der Datenbankpool befindet sich an einem Ort mit verschiedenen Datenbankservern für verschiedene Anwendungen, aber mit Verbindungen, wenn eine gemeinsame Nutzung von Daten erforderlich ist.
Der Anwendungspool enthält verschiedene Anwendungen auf verschiedenen Technologien oder Plattformen, die sich den Datenbankpool teilen.
Der Lucene-Index enthält Indizes, die für bestimmte Anwendungen benötigt werden. Es ist möglich, dass ein und derselbe Index von verschiedenen Anwendungen gemeinsam genutzt wird, sogar auf unterschiedlichen Plattformen wie Java und .NET.
Oracle AQ ist ein fortschrittliches RDBMS-basiertes Warteschlangensystem, das Nachrichten für Aktualisierungen der Datenbank speichert. Das Messaging-System wird zur Aktualisierung der Lucene-Indizes, zum Zwischenspeichern von RAM-Daten, für Benachrichtigungen, Abonnement-Mails usw. verwendet. Wir haben uns für Oracle AQ anstelle anderer Messaging-Lösungen wie MSMQ entschieden, weil es eine robuste und sichere Unterstützung für den Einsatz in einer verteilten Umgebung bietet. Wir waren mit Nicht-Datenbank-Messaging-Lösungen in einer verteilten Umgebung nicht zufrieden, insbesondere nicht mit den Fallback-Mechanismen, die sie bieten, wenn das System ausfällt oder der Speicher beschädigt ist.
Architektur
Wie das Diagramm zeigt, sind die beiden Serverstandorte über ein privates Hochgeschwindigkeitsnetzwerk mit einem Datenbankpool an einem Standort und lastverteilten Anwendungsservern an beiden Standorten verbunden.
Datenbank-Trigger
Datenbankaktualisierungen lösen einen Trigger aus, der eine XML-Nachricht mit den aktualisierten Daten in Oracle AQ einreiht.
Duplizierung des Lucene-Index
Der Lucene-Index ist an beiden Standorten dupliziert, da ein einzelnes NAS (Network-attached Storage) zur Speicherung des Index manchmal nicht verfügbar war oder beim Schreiben von mehreren Servern Sperrprobleme auftraten. Da Oracle AQ für mehrere Verbraucher verwendet wurde, haben wir errechnet, dass es den gleichen Arbeitsaufwand bedeutet, doppelte Indizes auf Anwendungsservern statt auf dem NAS zu haben.
Hörer
Die Listening-Threads der Anwendungen würden die Warteschlange auf neue XML-Nachrichten überprüfen und von den vorgesehenen Konsumenten verarbeitet. Der Index-Listener würde die Indexaktualisierungsnachricht aus der Warteschlange verarbeiten und den Lucene-Index aktualisieren. Die beiden Server sind bei Oracle AQ registriert, um die Nachrichten in der Warteschlange zu lesen. Die Nachrichten werden aus der Warteschlange entfernt, wenn alle Verbraucher auf beiden Servern die Verarbeitung der Nachricht abgeschlossen haben. Bei Fehlern wird die Nachricht entweder erneut in die Warteschlange gestellt oder in die tote Warteschlange verschoben.
Anwendung
Die Benutzeranfragen werden auf zwei Servern verteilt. Die erste Anfrage eines Benutzers kann von einem Server bearbeitet werden und die folgende Anfrage desselben Benutzers kann von einem anderen Server in derselben Sitzung bearbeitet werden. Dies erforderte, dass wir die Sitzung in der Datenbank für robuste und skalierbare Faktoren aufrechterhalten.
Suchanfragen von Anwendungen führen eine Suche im entsprechenden Lucene-Index durch und fragen den Datenbankpool nach den gewünschten Details ab. Der RAM-Cache wird für einfache Datenabfragen verwendet, der Lucene-Index für die erweiterte Suche und Filter.
Algorithmen des Analysators
Für tokenisierte Felder haben wir StandardAnalyzer oder WhitespaceAnalyzer verwendet und für nicht tokenisierte Felder haben wir PerFieldAnalyzerWrapper mit dem Standard-Analyzer sowie KeywordAnalyzer darin verwendet. Die Verwendung von PerFieldAnalyzer hilft in Fällen, in denen verschiedene Felder unterschiedliche Analysetechniken erfordern, z.B.: für exakte Übereinstimmungen oder Schlüsselwortsuchen wird KeywordAnalyzer verwendet. Wir haben ComplexPhraseQueryParser verwendet, um den Suchstring zu analysieren, da wir komplexe Suchbegriffe unterstützen.
Ich kann mich nicht mehr daran erinnern, wie die verschiedenen Algorithmen zu Beginn verwendet wurden, welche Probleme auftraten und wie der derzeit verwendete Algorithmus diese gelöst hat. Tatsache ist jedoch, dass lucene und NoSQL an Stärke und Funktionen zunehmen werden und immer akzeptabler werden, um die Leistung unserer Anwendungen zu verbessern.
Verfasst von

Byju Parameshwaran Nair
Unsere Ideen
Weitere Blogs

Testgetriebene Entwicklung (TDD) mit dbt: Erst testen, dann SQL
Testgetriebene Entwicklung mit dbt: Erst testen, dann SQL Wenn Sie mehr als drei Tage als Analytik-Ingenieur verbracht haben, hatten Sie...
Dumky de Wilde

Python Mocking, die heimtückischen Bits
Bei dem Versuch, eine Funktion in meinem Python-Code zu spiegeln, bin ich auf diesen hervorragenden Blog von Durga Swaroop Perla gestoßen. Der Blog...
Jan Vermeir


Contact