Blog
Wie ML System Design uns hilft, bessere ML Produkte zu entwickeln

Da sich die Branche auf End-to-End-ML-Teams zubewegt, um ihnen die Umsetzung von MLOPs-Praktiken zu ermöglichen, ist es entscheidend, über das Modell hinauszublicken und das gesamte System zu betrachten, das Ihr maschinelles Lernmodell umgibt. Der klassische Artikel Hidden Technical Debt in Machine Learning Systems erklärt, wie klein das Modell im Vergleich zu dem System ist, in dem es arbeitet. Um ein ML-Produkt zu pflegen, müssen wir daher das System um das maschinelle Lernmodell herum verstehen, es ganzheitlich betrachten und entsprechend gestalten.
Dieser Blogbeitrag veranschaulicht die Schritte des Designprozesses. Zur Veranschaulichung des Prozesses wird ein Fall von Nachfrageprognose verwendet. Die Nachfrageprognose wurde gewählt, weil sie ein sehr greifbares Problem und eine sehr geeignete Anwendung für maschinelles Lernen ist.
Inhaltsverzeichnis
Was ist Machine Learning System Design?
Der Entwurf eines maschinellen Lernsystems ist der iterative Prozess der Definition einer Softwarearchitektur. Er besteht aus:
- isolierte Bausteine
- Wechselwirkungen zwischen diesen Bausteinen
- Daten, die durch die Bausteine fließen
Das System wird durch die Analyse der Geschäftsanforderungen und des Kontextes einer Organisation entwickelt.
Der Entwurfsprozess ist iterativ, da sich die Umgebung und die geschäftlichen Anforderungen ändern können, was sich auf die Architektur Ihres Systems auswirkt. Die isolierten Bausteine sind die einzelnen Anwendungen, die in Ihrem System laufen werden. Es ist wichtig, sich auf den Datenfluss zu konzentrieren, da dies den Unterschied zwischen maschinellen Lernsystemen und normalen Softwaresystemen ausmacht. Die Geschäftsanforderungen bestimmen, ob und wie Ihr Modell einen Mehrwert für Ihr Unternehmen schafft. Der wichtigste und oft übersehene Teil ist schließlich der Kontext der Organisation, in der Sie arbeiten. Ein Unternehmen kann sich für einen Teil des Technologie-Stacks entschieden haben, der Ihr Design einschränkt. Außerdem kann es übergreifende Belange wie Sicherheit und Datenschutz geben, die Ihr Design berücksichtigen muss. Wenn zwei Unternehmen ein System mit denselben Geschäftsanforderungen entwerfen, kann das Endergebnis völlig unterschiedlich aussehen. Das Ziel des Designs von Machine Learning Systemen ist es, die Kompromisse, die Sie eingehen, zu kommunizieren und Engpässe in Ihrem System zu identifizieren.
Entwurfsprozess
Es gibt keinen einzigen Weg, ein System zu entwerfen. Hier schlage ich eine Abfolge von Schritten vor, die Sie bei der Erstellung eines Systemdesigns befolgen können. Der Prozess der Entwicklung eines ML-Systems kann in aufeinander folgende Themen unterteilt werden, die verschiedene Teile des Systems betreffen. Das Systemdesign ist ein iterativer Prozess, der nie abgeschlossen ist, da sich die Anforderungen ändern können. Mehr dazu später in diesem Beitrag.
- Anforderungen klären
- Problem als ML-Aufgabe formulieren
- Identifizieren Sie Datenquellen und deren Verfügbarkeit
- Entwicklung von Modellen
- Vorhersagen servieren
- Beobachtbarkeit
Das untenstehende Design Canvas für ein Machine Learning System kann während des Entwurfs als Handgriff verwendet werden, um den Überblick über Entscheidungen zu behalten. Es enthält Fragen, die Sie durch den Entwurfsprozess leiten können. Ihre Bedeutung wird im Laufe dieses Blogs erläutert.

Anforderungen klären und als ML-Aufgabe formulieren
Die Entwicklung eines ML-Systems ist eine technische Aufgabe. Aber die Einbeziehung von Geschäftsleuten wie Produktmanagern, Fachexperten oder anderen Interessengruppen stellt sicher, dass Ihr technischer Entwurf den geschäftlichen Anforderungen entspricht. Sie werden Ihnen helfen, die geschäftlichen Anforderungen zu klären. Es ist Ihre Aufgabe, die vom Unternehmen gestellten Anforderungen zu klären und sie in technische Spezifikationen zu übersetzen. Oft sind die Anforderungen zu Beginn nicht klar genug. Sie müssen sie gemeinsam mit dem Unternehmen verfeinern, um das Problem als etwas zu formulieren, das mit ML lösbar ist. Am Ende dieser Übung sollten Sie wissen: - Welche Funktionen wird mein System unterstützen? - Wie wird der Benutzer mit den Vorhersagen interagieren? - Wie viele Vorhersagen werden in welchem Zeitrahmen gemacht? - Für welches Geschäfts- und ML-Ziel wird es optimiert?
Beispiel
Ihr Unternehmen bittet Sie, seinen Lagerbestand zu optimieren, weil es oft zu viele oder zu wenige Produkte auf Lager hat. An sich ist dies keine Aufgabe des maschinellen Lernens, also lassen Sie uns das Problem neu formulieren. Wir können die Nachfrage nach Artikeln als Regressionsproblem vorhersagen, um zu bestimmen, wann neue Einkäufe getätigt werden sollen. Das Unternehmen hat P Produkte und tätigt monatliche Bestellungen mit einer Vorlaufzeit von drei Monaten. Wir müssen also jeden Monat 3 x P Vorhersagen machen.
Der Umfang des Entwurfs ist jetzt klar. Wenn Sie diesen Abschnitt erweitern, sehen Sie, wie der vollständig ausgearbeitete Entwurf aussieht.
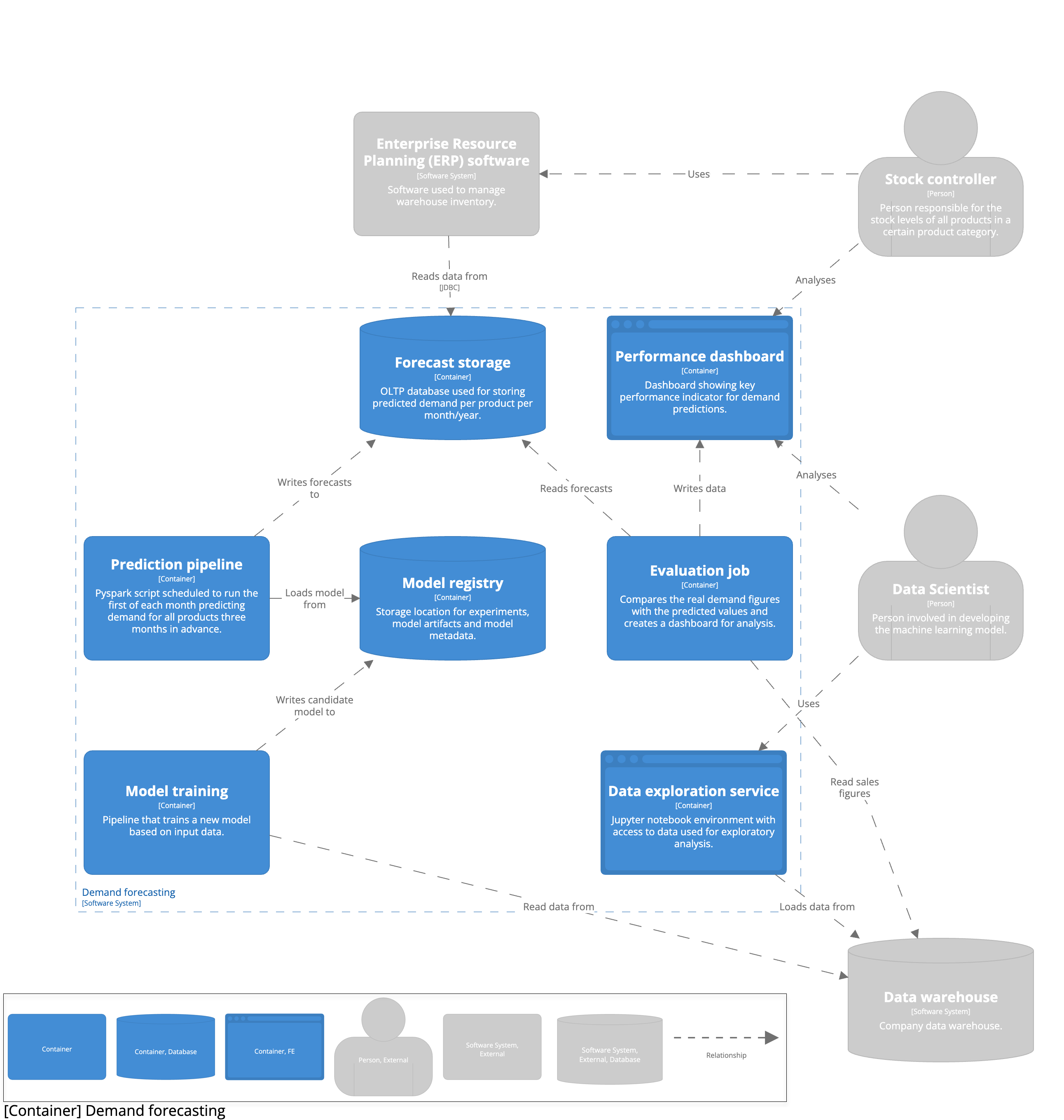
Identifizieren Sie Datenquellen und deren Verfügbarkeit
Wir müssen herausfinden, welche Datenquellen wir haben, welche Art von Daten es gibt und welche Qualität sie haben. Unsere Datenquellen sagen uns, welche Daten wir haben, wo sie gespeichert sind und wem sie gehören. Sie müssen sicherstellen, dass die Daten in einem System gespeichert sind, das für analytische Arbeitslasten geeignet ist, wie z.B. ein Data Warehouse. Die Datenherkunft ist ein weiterer wichtiger Faktor, damit Sie wissen, aus welchem System die Daten stammen und an wen Sie sich wenden können, wenn die Daten nicht den Qualitätsstandards entsprechen. Die Häufigkeit, mit der neue Daten eintreffen, bestimmt, wie oft Sie Ihr Modell neu trainieren können. Stehen uns für die Daten Ground-Truth-Labels zur Verfügung und wann werden diese Labels verfügbar sein? Dies ist auch die Phase, in der Sie Merkmale untersuchen können, die wahrscheinlich eine hohe Vorhersagekraft haben und feststellen können, ob Daten für sie verfügbar sind. Sind die Daten auf der richtigen Granularitätsebene verfügbar? Sie müssen die Daten in irgendeiner Form vorverarbeiten und ein Feature Engineering durchführen. Wo werden Sie diese verarbeiteten Daten speichern?
Beispiel
Im vorherigen Abschnitt haben wir gesagt, dass wir monatliche Vorhersagen erstellen müssen. Wir müssen dafür sorgen, dass neue Daten in dieser Häufigkeit eintreffen. Wir haben die Ground-Truth-Etiketten am Ende eines jeden Monats, wenn die Verkaufszahlen eintreffen. Da wir über einen fiktiven Anwendungsfall sprechen, müssen wir hier einige Annahmen treffen. In unserem Anwendungsfall müssen wir möglicherweise einige Ausreißer und Monate entfernen, in denen wir niedrige Verkaufszahlen hatten, weil einige Produkte nicht auf Lager waren. Wir müssen unsere Daten auf Monatsebene aggregieren, da unsere Verkaufszahlen auf Tagesbasis dargestellt werden. Die verarbeiteten Daten werden in demselben Data Warehouse gespeichert, aus dem wir die Rohdaten abgerufen haben.
Entwicklung von Modellen
Dieser Teil ist der Teil, mit dem sich Data Scientists am wohlsten fühlen. Wir haben die Datenquellen und Metriken identifiziert, für die das Modell optimiert werden soll. Wir müssen entscheiden, wie wir die Daten in Trainings-, Test- und Validierungsdatensätze aufteilen wollen. Wenn ein Basismodell verfügbar ist, gibt es das Ziel vor, das es zu übertreffen gilt. Falls nicht, ist dies auch die Phase, in der Sie die Mindestmetriken festlegen, die Ihr Ausgangsmodell erreichen sollte. Sie möchten ein Setup entwerfen, das es Ihnen ermöglicht, verschiedene Modelle und unterschiedliche Funktionssätze zu testen. Wo werden Sie Ihre Modelle trainieren und wie werden Sie sie gemeinsam entwickeln? Wie geht Ihr Modell mit dem Problem des Kaltstarts um, wenn nicht genügend Eingabedaten für Vorhersagen vorhanden sind? Sie werden einige Modellalgorithmen identifizieren, mit denen Sie anfangen zu experimentieren. Sie sollten die Anforderungen an die Erklärbarkeit, die Fairness und die Verzerrung Ihres Modells berücksichtigen, da dies die Modelloptionen einschränken kann. Ich werde hier nicht auf diese Themen eingehen. Das von Ihnen gewählte Modell kann bestimmte Anforderungen an die Trainingsinfrastruktur stellen. In diesem Stadium stellen Sie vielleicht fest, dass ML für das Problem, das Sie zu lösen versuchen, nicht erforderlich ist. ML bringt viel Komplexität in ein System und sollte daher nach Möglichkeit vermieden werden.
Beispiel
In diesem Fall gehen wir davon aus, dass es ein Basismodell gibt, das ein gewichteter gleitender Durchschnitt der letzten Monate ist. Wir können mit einem einfachen statistischen univariaten Modell wie Prophet beginnen. Dies reduziert den Aufwand für die Entwicklung von Funktionen und ist daher eine gute Möglichkeit, mit der Entwicklung zu beginnen. Sobald wir feststellen, dass dies nicht ausreicht, können wir mit dem Feature-Engineering beginnen und ein Gradient Boosted Tree-basiertes Modell ausprobieren. Zum Trainieren unserer maschinellen Lernmodelle steht uns eine Cloud-Umgebung zur Verfügung und wir werden unseren Code in einem Git-Repository speichern. Wir werden jedes trainierte Modell in einer Modellregistrierung speichern, um die Experimente mit neuen Merkmalen und Modellparametern zu verfolgen. Das Unternehmen hat uns mitgeteilt, dass die Vorhersagen noch am selben Tag verfügbar sein müssen, an dem die neuesten monatlichen Zahlen vorliegen, damit die Unternehmen die Vorhersagen zur Vorbereitung von Bestellungen nutzen können. Das bedeutet, dass wir in der Lage sein müssen, das Modelltraining (und die Vorhersagen) innerhalb eines Zeitrahmens von mehreren Stunden durchzuführen. Das kann eng werden, wenn Sie eine Menge komplexer Merkmale berechnen müssen, bevor Sie Ihr Modell trainieren können.
Bedienung Ihrer Vorhersagen
Das Ziel dieses Abschnitts ist es, festzulegen, wo unsere Vorhersagen ausgeführt und von wo aus sie bereitgestellt werden. Es gibt ungefähr vier Ausgabemuster: Batch, On-Demand, Streaming und On-Device. Wir werden die Online-Lernmethoden ignorieren, bei denen das Training und die Bereitstellung erfolgt. Bei Batch-Prognosen wird Ihr Modell in regelmäßigen Abständen ausgeführt, um Prognosen über eine festgelegte Anzahl von Datenpunkten zu erstellen. Ihre Vorhersagen werden in der Regel in einer Datenbank gespeichert, um dem Benutzer zur Verfügung gestellt zu werden. Bei der bedarfsgesteuerten Bereitstellung beziehe ich mich auf Modelle, die als REST-APIs (oder auch gRPC) bereitgestellt werden, bei denen eine Anfrage eine Vorhersage "auf Abruf" aufruft. Ihr Modell wird auf einem von Ihnen gehosteten Webserver bereitgestellt. Streaming-Prognosen werden kontinuierlich auf einem Datenstrom erstellt, der praktisch unendlich ist, denken Sie an einen Kafka-Stream. On-Device-Prognosen werden beispielsweise auf eingebetteten Systemen oder einem Telefon bereitgestellt. Im letzteren Fall befindet sich das Modell auf dem Gerät, das die Vorhersagen macht. Batch wird gewählt, wenn die Zeitempfindlichkeit der Vorhersagen gering ist und wir große Datenmengen verarbeiten möchten. Die Zeitsensitivität einer Vorhersage ist gering, wenn zwischen der Verfügbarkeit von Daten und der Notwendigkeit einer Vorhersage eine längere Zeitspanne (mehr als Minuten) liegt.
On-Demand ist ein gewünschtes Muster, wenn wir eine hohe Zeitsensitivität haben und die Vorhersage im kritischen Pfad des Benutzers liegt. Mit letzterem meinen wir, dass ein Benutzer aktiv auf die Vorhersage wartet, bevor er mit Ihrem Produkt fortfahren kann. Denken Sie an eine Suche im Internet. Streaming-Vorhersagen werden gewählt, wenn die Vorhersage eine hohe Zeitsensitivität aufweist und Sie die Vorhersagen in großem Umfang zuverlässig bereitstellen müssen. On-Device-Vorhersagen werden gewählt, wenn Sie sehr strenge Anforderungen an die Zeitsensitivität haben und die Netzwerklatenz zu groß ist. Wie werden Ihre Git-, Continuous Integration (CI) und Continuous Deployment (CD)-Workflows aussehen? Dies kann vom Kontext Ihres Unternehmens abhängig sein. Einige Unternehmen erzwingen manuelle Genehmigungen für die Bereitstellung von Modellen in der Produktion.
Beispiel
Die Nachfrageprognose ist ein Batch-Anwendungsfall. Bei der Nachfrageprognose kann es vorkommen, dass Sie innerhalb eines kurzen Zeitrahmens ein neues Training durchführen und anschließend Prognosen auf der Grundlage der neuesten verfügbaren Daten erstellen möchten. Um in diesem engen Zeitfenster so viel manuelle Arbeit wie möglich zu vermeiden, benötigen Sie Tools, mit denen Sie Pipelines erstellen können, so dass Sie die Trainings- und Vorhersageaufträge automatisch ausführen können. Danach können wir eine Validierung durchführen, um sicherzustellen, dass die produzierten Zahlen innerhalb der erwarteten Bereiche liegen - mehr dazu im nächsten Abschnitt.
Beobachtbarkeit
Systeme für maschinelles Lernen sind berüchtigt dafür, auf unerwartete Weise auszufallen. Wenn Sie maschinelle Lernsysteme in Produktion halten, müssen Sie im Voraus planen, wie Sie sicherstellen, dass Sie erkennen können, was schief läuft, damit Sie es beheben können. Im Allgemeinen gibt es zwei Kategorien von Metriken, die Sie im Auge behalten sollten: technische und funktionale. Mit technischen Metriken können Sie messen, ob Ihr System in der Lage ist, Vorhersagen zu machen und diese innerhalb des vereinbarten Zeitfensters zu treffen. Beispiele für diese Metriken sind: Verfügbarkeit, CPU- und Speichernutzung, Latenz und Durchsatz. Funktionale Metriken messen die Leistung Ihres Modells aus einer geschäftlichen Perspektive. Was Sie hier messen, hängt stark von dem Machine Learning Problem ab, das Sie lösen. Überlegen Sie, wie Ihre Benutzer die Vorhersagen nutzen werden und wie Sie ihr Feedback einholen können. Sie sollten sich immer darauf konzentrieren, mehrere funktionale Metriken gleichzeitig zu messen, um einen Tunnelblick zu vermeiden. Stellen Sie außerdem sicher, dass Sie Metriken für verschiedene Segmente Ihrer Daten messen. Sie können auch in Erwägung ziehen, die besten und die schlechtesten Ergebnisse zu verfolgen, da sie gute Anhaltspunkte für Verbesserungsmöglichkeiten bieten und einen Einblick in die Funktionsweise Ihres Modells geben. Sobald Sie sich entschieden haben, was Sie messen wollen, sollten Sie sich überlegen, wie Sie dies umsetzen und wo Sie diese Informationen speichern und visualisieren wollen.
Beispiel
In unserem Batch-Beispiel ist die Implementierung der Beobachtbarkeit etwas einfacher als in einem System, das ständig Vorhersagen für Benutzer bereitstellt. Wir müssen sicherstellen, dass wir die Ressourcen, die unsere Datenbank, in der unsere Vorhersagen gespeichert sind, verbraucht, und ihre Lesegeschwindigkeit überwachen. Der monatliche Batch-Trainings- und Vorhersageprozess kann laufen und scheitern. Angesichts des kurzen Zeitfensters, das uns für die Erstellung neuer Vorhersagen zur Verfügung steht, möchten wir so schnell wie möglich über Fehlschläge informiert werden, zum Beispiel per E-Mail. In diesem Fall möchten wir auch, dass unsere Batch-Protokolle verfügbar sind und klar sagen, was schief gelaufen ist. Nach der erfolgreichen Erstellung der Vorhersagen möchten wir einige Ad-hoc- und automatische Plausibilitätsprüfungen durchführen, bevor wir die Vorhersagen an unsere Kollegen im Einkauf weiterleiten. Außerdem werden wir die Vorhersagen des letzten Monats mit den tatsächlichen Zahlen vergleichen. Wir können dies als Ad-hoc-Aufgabe durchführen oder automatisch ein Dashboard erstellen, das unsere KPIs visualisiert. Unsere Einkaufskollegen möchten ebenfalls Zugriff auf das Dashboard haben, um die Leistung für ihre Produktgruppen von Interesse zu sehen.
Iterieren
Ziel dieses Blogbeitrags ist es, zu zeigen, wie Sie Systeme für maschinelles Lernen iterativ entwerfen können. Bisher haben wir von technischen Implementierungen und den zu verwendenden Werkzeugen abgesehen. Wir haben uns darauf konzentriert, das Geschäftsproblem zu verstehen und zu erkennen, welche technischen Entscheidungen wir treffen müssen. Das war beabsichtigt. Entwürfe sollten iterativ sein. Wenn man sich sofort in die Auswahl von Tools und Technologien stürzt, verliert man das Gesamtbild aus den Augen und trifft uninformierte Entscheidungen. Hoffentlich haben Sie inzwischen die in den vorangegangenen Abschnitten getroffenen Design-Entscheidungen aufgeschrieben, denn jetzt ist es an der Zeit, das Design zu visualisieren. Ohne die Details der Implementierung zu besprechen, können wir bereits die übergeordnete Architektur und die Interaktionen der Komponenten skizzieren. Dies schafft ein gemeinsames Verständnis für das Problem und erleichtert die Identifizierung von Engpässen. Stellen Sie sicher, dass Sie den Benutzer und andere externe Systeme, von denen Sie abhängig sind, in Ihr Architekturdiagramm einbeziehen.
Ausgehend von dieser anfänglichen High-Level-Architektur können wir damit beginnen, konkrete technische Implementierungen zu erstellen. Wie bereits erwähnt, ist die konkrete Umsetzung sehr kontextabhängig. Zunächst einmal hängt es davon ab, welchen Public Cloud-Anbieter Ihr Unternehmen nutzt. Vielleicht arbeitet Ihr Unternehmen auch mit einer On-Premise-Infrastruktur. Einige Unternehmen verfügen über Machine Learning Platform-Teams, die bestimmte Infrastrukturkomponenten für Sie bereitstellen. Als Faustregel gilt: Beginnen Sie mit den Komponenten, die entweder von Ihrem Unternehmen oder vom Public Cloud-Anbieter bereitgestellt werden, es sei denn, Sie haben einen Grund, andere Tools zu verwenden. Unten sehen Sie ein Beispiel für einen Anwendungsfall, der in der Azure-Cloud ausgearbeitet wurde.
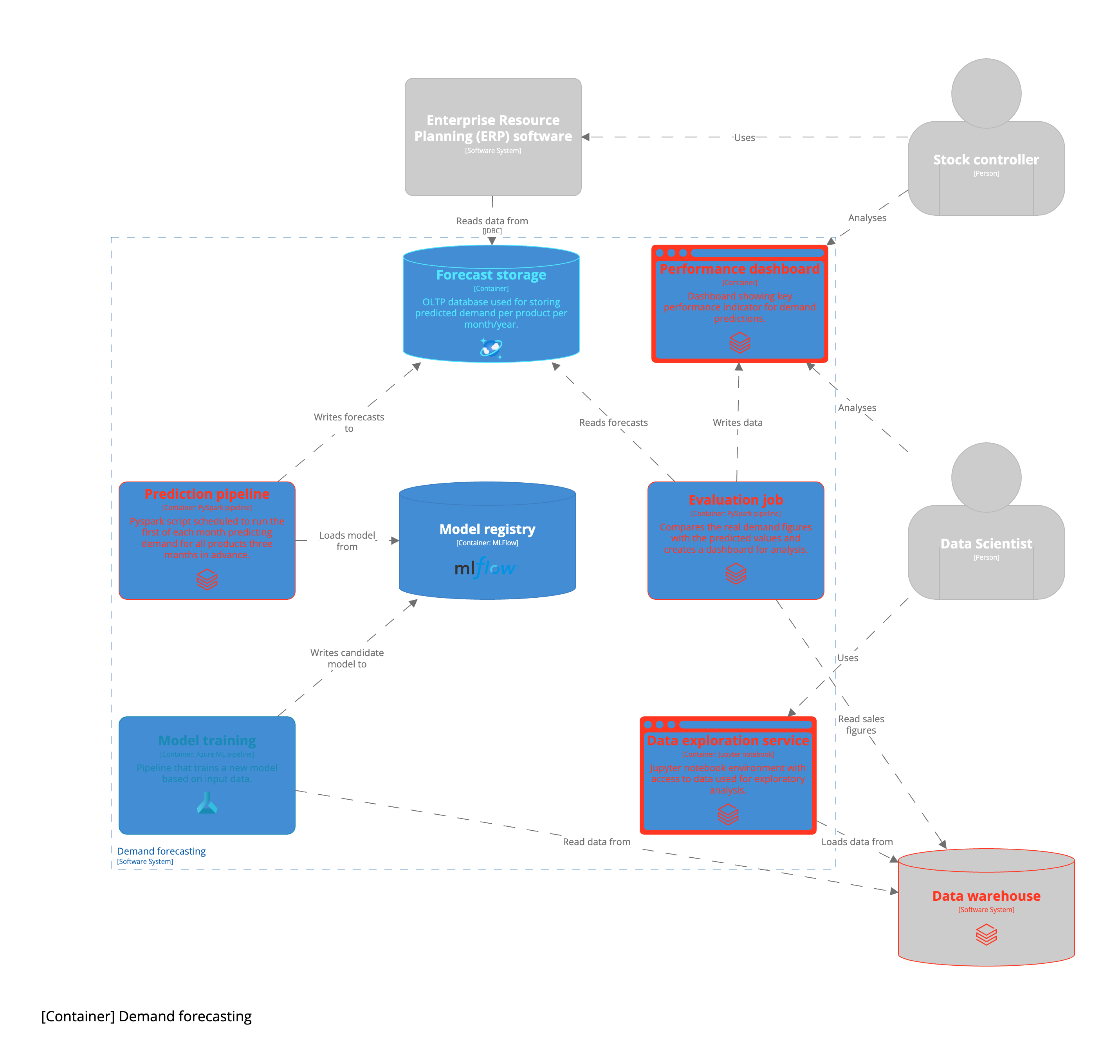
Wir haben den gesamten Prozess der Entwicklung eines maschinellen Lernsystems anhand eines Anwendungsbeispiels durchlaufen. Dieser Prozess ist bei weitem nicht vollständig. Er bietet jedoch eine solide Grundlage für den Anfang. Ich würde gerne mehr über andere Frameworks erfahren, die für die Entwicklung von maschinellen Lernsystemen verwendet werden. Die Schritte und Fragen, die Sie durch das Systemdesign leiten, sind eine Teilmenge, um die Diskussion einzugrenzen. Das vollständige Design Canvas sieht wie folgt aus:
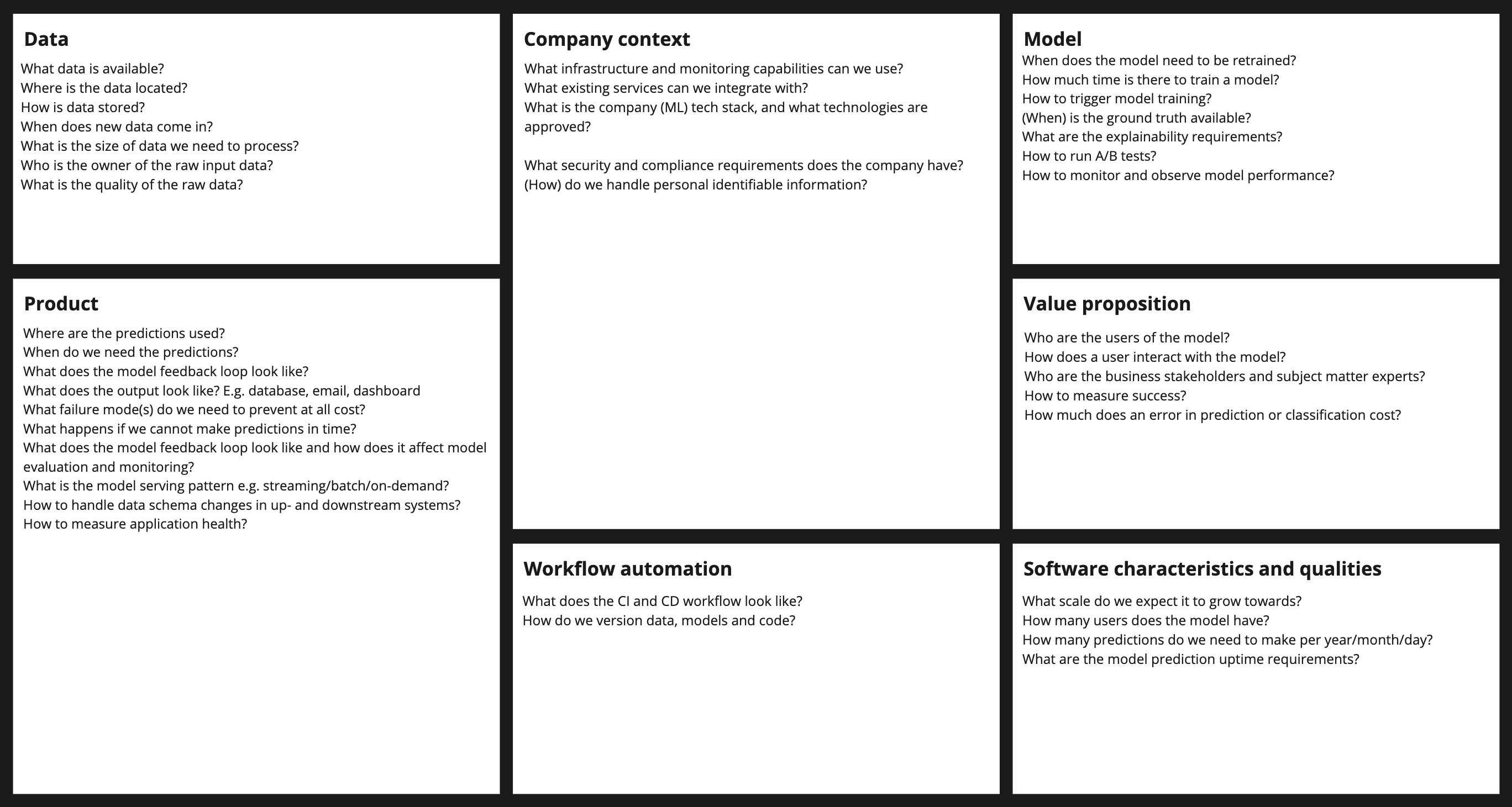 .
.
Verfasst von
Roy van Santen




Contact