Blog
Ein praktischer Leitfaden für die Integration von Kubernetes und JVM

Dieser Blogbeitrag wurde durch einen grossartigen Vortrag meines Kollegen Ben Fradet über ein Kundenprojekt inspiriert, an dem das Team für funktionale Programmierung bei Xebia kürzlich beteiligt war. Bei dem Projekt ging es darum, eine umfangreiche monolithische Scala-Anwendung in kleinere Microservices umzuwandeln. In dieser Zusammenfassung wollen wir einige der Lektionen durchgehen, die wir auf dieser Reise gelernt haben, die es dem Kunden ermöglicht hat, zu skalieren und widerstandsfähiger denn je zu sein. Wir werden uns auf Kubernetes und die Java Virtual Machine (JVM) konzentrieren.
Bevor wir beginnen, lass uns den Kontext und einige der Einschränkungen erläutern, die hier relevant sind. Erstens hat unser Team aktiv zu allen Phasen des DevOps-Lebenszyklus beigetragen, von der Entwicklung bis zur Bereitstellung in den verschiedenen Umgebungen, einschliesslich der Produktion. Zweitens, was die Einschränkungen des Monolithen anbelangt, mussten wir uns an die Skala des Monolithen halten, was die Anfragen pro Sekunde anbelangt, die in der Spitze massiv waren. Ausserdem waren wir gezwungen, so wenig Overhead wie möglich einzuführen, um die durchschnittlichen Latenzzeiten zu erhalten. Ausserdem mussten wir als Vorarbeit die Beobachtbarkeit und die Alarmierungsstrategien für den Monolithen verbessern, um zu wissen, wie der Stilllegungsplan aussehen sollte.
Das Team nutzte das Strangler-Fig-Muster, um das Altsystem schrittweise in neue Scala- und moderne Microservices umzuwandeln, die in Kubernetes laufen.
Jeder Microservice, abgesehen vom Code der Geschäftsdomäne und der dazugehörigen CI/CD-Pipeline, enthält das Helm-Diagramm (YAML-Dateien) mit der Konfiguration und den benötigten Ressourcen, die es dem Service ermöglichen, auf dem Kubernetes-Cluster zu laufen. Von nun an werden wir uns mit dem Abschnitt resources befassen, insbesondere mit CPU und memory.
Beispiel für eine Service-Steuerkarte:
# {prod,stage}_values.yaml
...
resources:
requests:
cpu: "1"
memory: "1500Mi"
limits:
memory: "1500Mi"
serviceConfig:
ENV_VAR: "value"
...Im Abschnitt resources geben wir die Speicher- und CPU-Anforderungen und -Limits für den Container an (im Beispiel 1500 MB Speicher bzw. 1 CPU):
requests: die Mindestmenge an Ressourcen, die der Container zum Betrieb benötigt.limitsMaximale Menge an Ressourcen, die der Container verwenden kann.
Mit anderen Worten: Das obige Beispiel bedeutet, dass der Container 1500 MB Arbeitsspeicher und 1 CPU anfordert und darauf beschränkt ist.
Aus der Sicht der Softwareentwicklung hat die Angabe der Ressourcenanforderungen bei einer Kubernetes-Bereitstellung mehrere Auswirkungen, die wir beachten müssen:
- Leistung: Wenn die Anforderungen zu niedrig sind, benötigt der Container möglicherweise mehr Ressourcen, um effektiv zu arbeiten. Sind die
requestsParameter jedoch zu hoch, verbrauchen die Pods möglicherweise mehr Ressourcen als erforderlich, was zu höheren Kosten führt. - Planen: Die Ressourcenvoraussetzungen spielen eine entscheidende Rolle im Entscheidungsprozess des Kubernetes-Schedulers, wenn Container auf Knoten platziert werden. Der Scheduler bewertet den Ressourcenbedarf bei der Entscheidung, auf welchem Knoten ein Container platziert werden soll, um sicherzustellen, dass der Container über genügend Ressourcen verfügt.
- Ressourcenzuweisung: Die Ressourcenanforderungen bestimmen die Anzahl der Ressourcen, die der Kubernetes Scheduler dem Container zuweist. Der Scheduler sorgt dafür, dass der Container die angegebenen Ressourcen erhält, wobei er die verfügbaren Ressourcen auf dem Knoten und die Anforderungen anderer Container berücksichtigt.
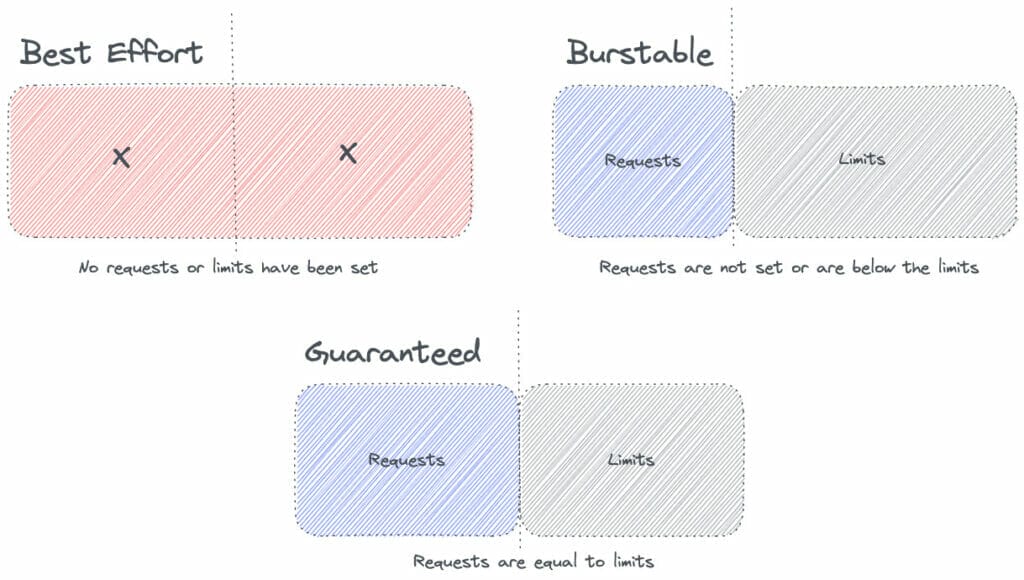
Zusammenfassend lässt sich sagen, dass diese Implikationen das antreiben, was Kubernetes Quality of Service (auch bekannt als QoS) nennt. Im Wesentlichen wird die Klasse QoS vom Kubernetes Scheduler verwendet, um Entscheidungen über die Planung von Pods auf Knoten zu treffen. Es gibt drei Klassen: BestEffort, Burstable, und Guaranteed.
QoS - BestEffort
Einem Pod wird die Klasse BestEffort zugewiesen, wenn weder requests noch limits im Pod-Manifest festgelegt sind.
apiVersion: v1
kind: Pod
spec:
containers:
- name: foo
resources:
limits:
requests:In diesem Fall erhalten diese Pods die niedrigste Priorität für den Zugriff auf die Ressourcen des Clusters und können beendet werden, wenn andere Pods die Ressourcen benötigen.
QoS - Burstabil
Die QoS-Klasse Burstable wird einem Pod zugewiesen, wenn die Parameter requests eingestellt sind, aber der Abschnitt limits nicht definiert ist. Beispiel:
apiVersion: v1
kind: Pod
spec:
containers:
- name: foo
resources:
requests:
memory: 700M
cpu: 500mDiese Pods können vorübergehend mehr Ressourcen nutzen, als sie angefordert haben, wenn die Ressourcen verfügbar sind, aber der Cluster wird diese zusätzlichen Ressourcen nicht garantieren. Diese Pods wären die nächsten in der Reihe, die getötet werden, wenn es keine BestEffort Pods gibt und requests überschreiten.
QoS - Garantiert
Wenn sowohl requests als auch limits eingestellt sind und die Werte für Arbeitsspeicher und CPU gleich sind, kann ein Pod in die QoS-Klasse Guaranteed eingeordnet werden.
apiVersion: v1
kind: Pod
spec:
containers:
- name: foo
resources:
limits:
memory: 1G
cpu: 500m
requests:
memory: 1G
cpu: 500mDaher sorgt der Cluster dafür, dass diese Pods jederzeit Zugriff auf die angeforderten Ressourcen haben.
QoS Rekapitulation
Optisch sehen die verschiedenen QoS Klassen in etwa so aus:
In Kubernetes ist zu beachten, dass ein Pod mehrere Container haben kann, und jeder kann seine CPU- und Speicherressourcenanforderungen und -grenzen haben. In diesem Fall wird die Klasse QoS des Pods auf der Grundlage der restriktivsten Ressourcenanforderung oder des restriktivsten Limits eines jeden Containers bestimmt. Die folgende Tabelle veranschaulicht die möglichen Kombinationen von CPU- und Speicheranforderungen und Limits für einen Pod mit mehreren Containern:
| CPU-Anfragen | CPU-Grenzen | Speicheranfragen | Speicherbegrenzungen | QoS-Klasse |
|---|---|---|---|---|
| Nicht spezifiziert | Nicht spezifiziert | Nicht spezifiziert | Nicht spezifiziert | Bestes Bemühen |
| Angegeben | Nicht spezifiziert | Angegeben | Nicht spezifiziert | Berstend |
| Angegeben | Angegeben | Angegeben | Nicht spezifiziert | Berstend |
| Angegeben | Angegeben | Angegeben | Angegeben | Garantiert |
Beachte, dass die CPU- und Speicheranforderungen und -grenzen eines Containers angegeben werden müssen, damit er als Guaranteed gilt. Der Pod wird als Burstable betrachtet, wenn nur eine der beiden Angaben gemacht wird, und als Best Effort, wenn keine der beiden Angaben gemacht wird.
Bei der Auswahl von Ressourcen in einer Kubernetes-Bereitstellung ist es daher entscheidend, die Art der einzelnen Ressourcen und die gewünschte QoS zu berücksichtigen, um sicherzustellen, dass die Anwendung über genügend Ressourcen verfügt, um effektiv und effizient zu laufen.
Wir müssen jedoch berücksichtigen, dass Speicher und CPU im Kubernetes-Kontext unterschiedlich behandelt werden. Der
betrachtet, weil er eine endliche Ressource ist, die compressible resource betrachtet, weil sie von verschiedenen Prozessen gemeinsam genutzt werden kann, so dass mehrere Prozesse gleichzeitig laufen können. Diese Tatsache ist entscheidend für das Verständnis der folgenden Abschnitte.
Kubernetes und die JVM
Für die JVM, die in einem Container in einem Kubernetes-Cluster läuft, gelten dieselben Konzepte für Ressourcenanforderungen und -begrenzungen. Die JVM verbraucht Speicher- und CPU-Ressourcen aus dem Container. Diese Ressourcen können wie bei jeder anderen Anwendung, die in einem Container läuft, angegeben werden.
Die Überwachung des Speicherverbrauchs (denke daran, dass es sich um eine incompressible resource handelt) der JVM im Container ist jedoch unerlässlich, um sicherzustellen, dass sie die in der Bereitstellung festgelegten Grenzen nicht überschreitet. Wenn der JVM der Arbeitsspeicher ausgeht, kann dies zu einem Absturz der Anwendung oder einem anderen unerwarteten Verhalten führen. Um dies zu vermeiden, ist es wichtig, angemessene Anforderungen und Grenzen für den Speicher festzulegen sowie die Speichernutzung der JVM zu überwachen und die Ressourcengrenzen bei Bedarf anzupassen.
Anfragen, Limits und die JVM
java.lang.OutOfMemoryErrorführt zum Absturz der Anwendung, wenn wir keine angemessene Speichergrenze für die JVM festlegen. Wie wir bereits erwähnt haben, sollte das Speicherlimit hoch genug sein, um den regulären Betrieb der JVM, einschliesslich der Heap-Grösse, des Metaspaces und jeder anderen Speichernutzung, zu ermöglichen. Auf all diese Aspekte werden wir später noch eingehen. Betrachten wir aber zunächst einmal die folgende Einsatzkonfiguration als Beispiel:
apiVersion: v1
kind: Pod
spec:
containers:
- name: foo
resources:
limits:
memory: "125M"
requests:
memory: "100M"
cpu: "500m"Bedenke auch:
- 25m ist der durchschnittliche RAM-Verbrauch für die Anwendung
foo. - 1/4 ist der Standard-Pod-RAM-Anteil für den maximalen Java-Heap-Speicherplatz.
- Wichtiger Hinweis: Wenn Du mit JDK 8u91 arbeitest, ist die Situation anders, da der Standardwert 1⁄4 des Knotenspeichers beträgt.
Daher würde das folgende Diagramm die Speichernutzung in dieser Konfiguration darstellen:
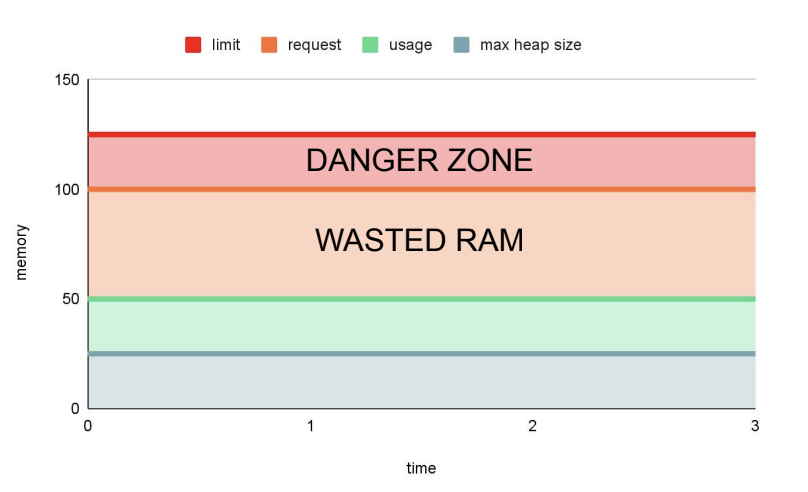
Wie Du sehen kannst, wird Speicherplatz verschwendet. Wie könnte das verbessert werden?
Für den Anfang könnten wir die standardmässige maximale Heap-Grösse der JVM ändern, indem wir das Flag -Xmx verwenden.
apiVersion: v1
kind: Pod
spec:
containers:
- name: foo
resources:
limits:
memory: "125M"
requests:
memory: "100M"
cpu: "500m"
env:
name: "JAVA_OPTS"
value: "-Xmx100M"Mit -Xmx100M setzen wir die maximale Heap-Grösse auf 100 MB. Daher wird die JVM bis zu 100 MB Speicher für den Heap zuweisen. Wächst der Heap über diese Grösse hinaus, kann die JVM einen Garbage Collection-Zyklus auslösen, um ungenutzte Objekte freizugeben und die Heap-Grösse zu verringern. Trotzdem kann es passieren, dass die JVM ein OutOfMemoryError meldet, was zu einem Absturz der Anwendung führen kann.
Das Überwachungsdiagramm würde etwa so aussehen:
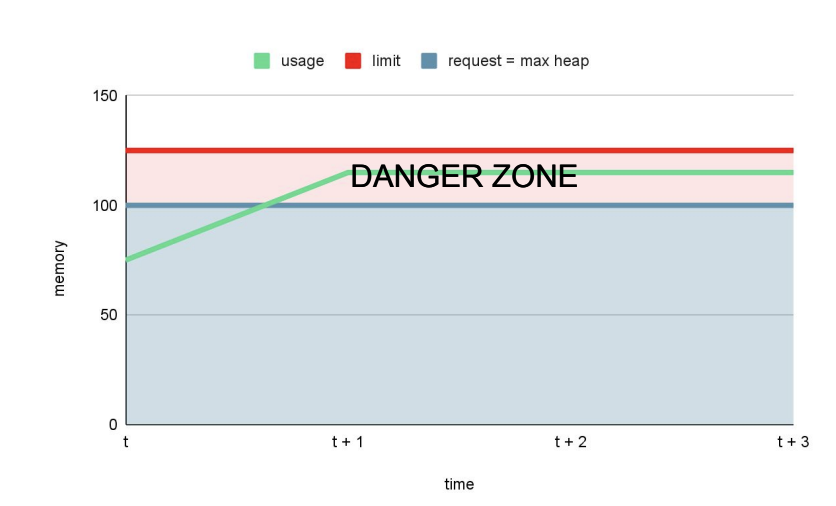
Im Allgemeinen gibt die JVM nur ungern Speicher zurück, so dass der Pod in der Gefahrenzone stecken bleiben kann. Die Gefahrenzone für eine Anwendung kann als der Punkt definiert werden, an dem die Speichernutzung im Laufe der Zeit konstant ansteigt und sich der maximal verfügbaren Speichergrenze nähert. Wenn in dieser Situation die Speichernutzung die maximal verfügbare Grenze überschreitet, besteht die Gefahr, dass die Anwendung einen OutOfMemory (OOM) Fehler erleidet und abstürzt.
Das ist nicht gut genug, also können wir versuchen, requests und limits anzugleichen und die Heap-Grösse zu optimieren.
apiVersion: v1
kind: Pod
spec:
containers:
- name: foo
resources:
limits:
memory: "100M"
requests:
memory: "100M"
cpu: "500m"
env:
name: "JAVA_OPTS"
value: "-Xmx75M"Das würde bedeuten:
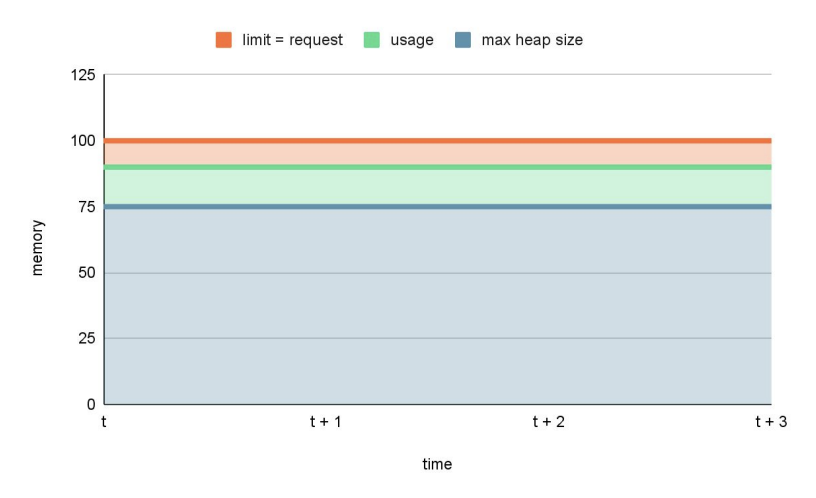
Wie Du sehen kannst, gibt es jetzt keine Gefahrenzone mehr, d.h. es besteht kein Risiko, getötet zu werden. Gleichzeitig haben wir eine minimale Menge an verschwendetem RAM.
Diese Übung hat gezeigt, wie wichtig es ist, die maximale Heap-Grösse auf der Grundlage der verfügbaren Ressourcen und des Speicherbedarfs der Anwendung angemessen festzulegen:
- Setze
-Xmxauf etwas weniger als den Speicherrequestsundlimits. - Die Einstellung
requestsgleichlimitsfür den Speicher ist im Allgemeinen eine gute Idee.
"Helfer" für die Konfiguration der Heap-Grösse
Beachte, dass ich "Helfer" angegeben habe. Die Parameter -XX:InitialRAMPercentage, -XX:MinRAMPercentage und -XX:MaxRAMPercentage können bei der Konfiguration der Heap-Grösse einer JVM-Anwendung helfen. Sie helfen bei der Steuerung der Heap-Grösse einer JVM-Anwendung, indem sie den Prozentsatz des gesamten verfügbaren Speichers angeben, den die JVM verwenden soll.
Durch die Angabe von InitialRAMPercentage können wir die anfängliche Heap-Größe (als Prozentsatz des verfügbaren physischen Speichers) festlegen. Gleichzeitig bestimmen die Parameter MinRAMPercentage und MaxRAMPercentage die minimale bzw. maximale Heap-Größe, auf die die JVM anwachsen kann.
Dies könnte in einem Ökosystem mit Hunderten von Microservices nützlich sein, da diese JVM-Flags dabei helfen können, die Heap-Grösse jeder JVM-Anwendung kontrollierter und skalierbarer zu konfigurieren. Einige Beobachtungen:
- Wenn Du die Heap-Grösse als Prozentsatz des verfügbaren Speichers und nicht als festen Wert festlegst, kann die JVM ihre Speichernutzung automatisch an die verfügbaren Ressourcen anpassen.
- In einer dynamischen Umgebung wie Kubernetes, in der der verfügbare Arbeitsspeicher aufgrund der Skalierung von Pods, Knoten und anderen Faktoren schwanken kann, kann dies sehr hilfreich sein. Dies ist jedoch nur teilweise ein Vorteil an sich, wie wir weiter unten erklären werden.
- Ausserdem sind diese Flags auch mit dem
-XmxJVM-Flag kompatibel, das die maximale Heap-Grösse festlegt, so dass wir sicherstellen können, dass die JVM-Heap-Grösse optimal für die jeweilige Anwendung konfiguriert ist.
In einem Kubernetes-Gebiet ist es jedoch ratsam, die Parameter requests und limits zu verwenden, um die Speicherzuweisung für einen Pod zu verwalten. Zum Beispiel ist -XX:MaxRAMPercentage eine weiche Grenze, und die JVM kann bei Bedarf mehr Speicher verbrauchen. Daher ist die Verwendung dieser JVM-Flags in Kombination mit den Parametern requests und limits ein zuverlässigerer und empfohlener Ansatz für die Verwaltung der Speichernutzung in Kubernetes.
Wie können wir also diese Kubernetes-Speichereinstellungen finden (requests / limits)?
Um diese Frage zu beantworten, müssen wir mehrere Faktoren ausserhalb des Heaps berücksichtigen, die die Leistung und Stabilität einer Scala/Java/Kotlin-Anwendung in Kubernetes beeinflussen können. Einige dieser Faktoren sind:
- Der Nicht-Heap-Speicher, der die permanente Java-Erzeugung und den nativen Speicher umfasst, sollte bei der Einstellung
-Xmxebenfalls berücksichtigt werden. Eine hohe Einstellung für-Xmxkann dazu führen, dass der Nicht-Heap-Speicher erschöpft wird, was zuOutOfMemoryErrorAusnahmen und Anwendungsabstürzen führt. - Metaspace-Speicher: Dies ist ebenfalls ein Nicht-Heap-Speicherbereich, der von der JVM zum Speichern von Klassenmetadaten und dynamisch generiertem Code verwendet wird. Die Grösse des Metaspeichers ist standardmässig nicht begrenzt, kann aber mit dem Flag
-XX:MaxMetaspaceSizekonfiguriert werden. Als Faustregel gilt, dass die Grösse des Metaspeichers auf einen Wert begrenzt werden sollte, der 16 Mal kleiner ist als der verfügbare Speicher. Wenn die JVM also zum Beispiel 4 GB verfügbaren Speicher hat, wäre-XX:MaxMetaspaceSize=256Mrichtig. - RAM-basierte Dateisysteme, wie tmpfs, können ebenfalls die
-XmxKonfiguration beeinflussen. Wenn der Pod beispielsweise über 4 GB verfügbaren Speicher und einetmpfs-Einhängung mit 1 GB verfügt, könnte eine gängige Einstellung für-Xmx-Xmx3Gsein. Dadurch wird sichergestellt, dass die JVM über genügend Arbeitsspeicher verfügt, um auch mit dem zusätzlichen Speicherbedarf der Einhängungtmpfskorrekt zu arbeiten. - Garbage Collection: Die Häufigkeit und Dauer der Garbage Collection kann die Leistung und Stabilität einer JVM-Anwendung beeinflussen. Die JVM-Flags
-XX:+UseG1GCund-XX:MaxGCPauseMillisbeziehen sich auf den Garbage Collector und können verwendet werden, um sein Verhalten zu optimieren:-XX:+UseG1GCaktiviert denG1Garbage Collector, einen gleichzeitigen und parallelen Garbage Collector, der dafür entwickelt wurde, GC-Pausen zu minimieren.-XX:MaxGCPauseMillislegt die maximale GC-Pausenzeit in Millisekunden fest, d.h. die maximale Zeitspanne, die die JVM für die Garbage Collection pausieren wird.
Was die Garbage Collection betrifft, kann eine grössere Heap-Grösse daher zu einer längeren GC-Pause führen, während eine kleinere Heap-Grösse zu häufigeren GC-Pausen führen kann.
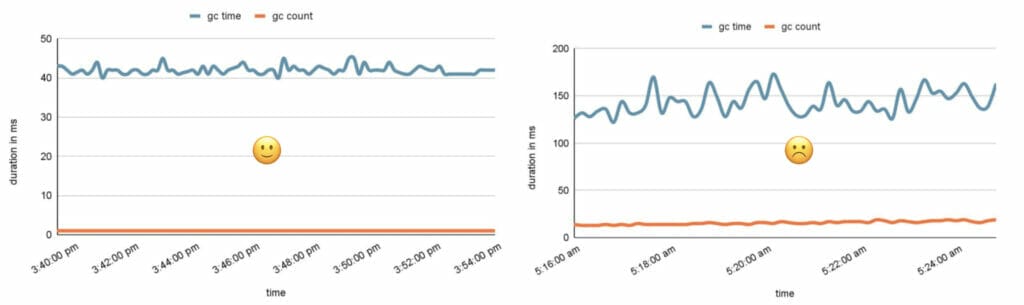
Die obigen Diagramme zeigen auf der linken Seite gute GC-Pausenzeiten und -Anzahl. Im Gegensatz dazu sehen wir auf der rechten Seite häufige und längere GC-Pausenzeiten. Dies könnte ein Zeichen für eine schlechte Leistung sein, wenn wir einen Anstieg der GC-Anzahl und der GC-Pausenzeiten feststellen, was darauf hindeutet, dass der Garbage Collector häufiger und für längere Zeiträume arbeitet.
Es ist wichtig, die maximale Heap-Grösse auf der Grundlage der verfügbaren Ressourcen und des Speicherbedarfs der Anwendung angemessen festzulegen und die Garbage Collector-Flags auf der Grundlage der gewünschten Leistungsmerkmale der JVM abzustimmen. Natürlich hängen die optimalen Einstellungen von den spezifischen Anforderungen der Anwendung und der Betriebsumgebung ab. Aber in der Regel ist eine gute Faustregel:
- Wenn Du zwei oder mehr CPUs und mehr als 1792Mb Arbeitsspeicher hast, solltest Du
G1verwenden. - Andernfalls solltest Du einen seriellen Collector verwenden, der sich am besten für Einprozessor-Rechner eignet.
"Poolbare" Ressourcen
Einige der Ressourcen sind "poolbar", so dass es vorzuziehen sein könnte, grössere Pods zu haben, um den Overhead zu minimieren. Diese grösseren Pods, in denen wir mehrere Container ausführen können, reduzieren jedoch nicht unbedingt den Speicher-Overhead, da jede JVM ihren eigenen Heap und Metaspace hat, die unabhängig von den anderen JVMs Speicher verbrauchen werden. Andererseits teilen sich Container in einem Pod die zugrundeliegenden Ressourcen des Hostsystems, wie CPU, Netzwerk und Dateisystem. Daher kann es in diesen Bereichen zu einer Verringerung des Overheads kommen.
Es ist auch wichtig, die mit grösseren Pods verbundenen Kompromisse zu berücksichtigen. Grössere Pods können zum Beispiel zu einem stärkeren Wettbewerb um Ressourcen, einer geringeren Ausfallsicherheit bei Knotenausfällen und einer höheren Komplexität bei der Ressourcenverwaltung und Skalierung führen.
Daher sollte die Entscheidung für grössere Pods oder kleinere, separate Pods auf einer sorgfältigen Abwägung der spezifischen Anforderungen und Beschränkungen der Anwendung basieren. Wie bereits erwähnt, ist die Überwachung entscheidend für das Verständnis der Leistung und Stabilität einer Scala/Java/Kotlin-Anwendung in Kubernetes. JMX, Prometheus oder ein anderer Monitoring-Stack sollte zur Überwachung der JVM und der Anwendungsleistung verwendet werden.
So weit, so gut. Nach gründlicher Abstimmung und allen oben erläuterten Überlegungen haben wir festgestellt, wie die Speichereinstellungen sein sollten (Anforderungen = Grenzen). Aber was passiert, wenn die Speichernutzung des Pods das Limit erreicht?
OOMKilled werden
Wenn die Speichernutzung eines Pods in Kubernetes das festgelegte Limit erreicht, kann das Betriebssystem damit beginnen, Prozesse innerhalb des Containers zu beenden, um Speicher freizugeben.
In diesen Fällen wird der Pod immer wieder neu gestartet (3 Neustarts im folgenden Beispiel):
> kubectl get pods
NAME READY STATUS RESTARTS AGE
pod-name 1/1 Running 3 11d> kubectl describe pod ${pod_name}
...
Containers:
service-name:
...
Last State: Terminated
Reason: OOMKilled
Exit Code: 137|143
...
QoS Class: BurstableUnd der Container wird effektiv OOMKilled, was überhaupt nicht gut ist, da dies zur Beendigung des gesamten Containers führen kann, was zu einem möglichen Datenverlust oder einer Ausfallzeit der Anwendung führt. Abgesehen davon, dass das Problem OOMKilled behoben ist, könnte ein Shutdown-Hook nützlich sein, wenn eine Bereinigung erforderlich ist. Für PlayFramework gibt es zum Beispiel eine standardmässige "Sequenz" zum Herunterfahren.
Um auf das Hauptproblem zurückzukommen: OOMKilled kann verschiedene Gründe haben, von denen einige bereits erwähnt wurden:
Xmxnicht für die Arbeitslast geeignet ist, was zu einem unzureichenden Heap-Speicher führt.- Die Anfragen / Limits sind möglicherweise nicht hoch genug im Vergleich zu den Einstellungen von
Xmx. - Speicherleck innerhalb oder ausserhalb des Heaps: Wenn die Anwendung ein Speicherleck hat, wird ihr Speicherverbrauch im Laufe der Zeit immer grösser.
- Schlechte Konfiguration der Garbage Collection: Wenn die Garbage-Collection-Konfiguration der JVM nicht optimiert ist, ist sie möglicherweise nicht in der Lage, Speicher effizient zurückzugewinnen, was zu einem
OOMKilledEreignis führt. - Metaspace-Probleme: Wenn die Anwendung eine grosse Anzahl von Classloadern erstellt oder eine grosse Menge an nativem Speicher verwendet, kann dies dazu führen, dass dem Metaspace der JVM der Speicher ausgeht.
Was können wir tun, um das OOMKilled-Problem zu identifizieren?
Es gibt viele interessante Strategien, um die Ursache des OOMK zu identifizieren, wie z.B. die Überprüfung von Protokollen oder die erneute Überprüfung der verschiedenen Dashboards und Metriken. Aus unserer Erfahrung heraus gibt es jedoch nur wenige relevante Optionen:
Flamme Diagramme
Flame-Diagramme liefern visuelle Darstellungen des Aufrufstapels eines Programms und können zur Identifizierung von Leistungsengpässen, einschliesslich Speicherproblemen, verwendet werden. Wenn Du das Flame-Diagramm des betroffenen Pods analysierst, kannst Du sehen, welche Teile des Codes den meisten Speicher verbrauchen und ob es Speicherlecks gibt.
Einige interessante Tools:
Profiling
Profiling-Tools wie JProfiler oder VisualVM können helfen, Speicherlecks, übermässige Speichernutzung und andere Leistungsengpässe zu identifizieren, die zu dem OOMK Ereignis beitragen könnten.
Mit der Portweiterleitung können wir auf Anwendungen zugreifen, die in einem Kubernetes Cluster laufen:
> kubectl port-forward ${pod_name} 1099:1099Dann verwende VisualVM: VisualVM -> Add JMX connection -> localhost:1099, kannst Du die Metriken erhalten, die Ihnen bei der Fehlersuche helfen können.
Überwachung in Echtzeit
Prometheus und Grafana bieten eine schnelle und effektive Möglichkeit, die Leistung der JVM in Echtzeit zu überwachen. So kannst Du Leistungsprobleme erkennen und beheben, bevor sie eskalieren. Hier sind ein paar Beispiele:
- K8s-Metriken über die Pods (CPU, Speichernutzung, I/O usw.). Grafana Dashboard Beispiel.
- JVM-Metriken. Grafana Dashboard Beispiel.
Identifizieren von Speicherlecks
Wenn Du vermutest, dass ein Speicherleck die OOMK verursacht hat, kannst Du einen Heap-Dump des betroffenen Pods erstellen und diesen mit einem Tool wie dem oben erwähnten JProfiler oder VisualVM analysieren. Um im Falle eines OOMKilled Ereignisses einen Heap-Dump zu erhalten, kannst Du die folgenden JVM-Flags setzen:
-XX:+HeapDumpOnOutOfMemoryError: Dieses Flag veranlasst die JVM, einen Heap-Dump zu erzeugen, wenn ein OOM-Ereignis eintritt.-XX:HeapDumpPath=: Dieses Flag gibt den Dateipfad an, in den der Heap-Dump geschrieben werden soll.
Um Zugriff auf den Heap-Dump zu erhalten, musst Du z.B. ein Volume mounten:
apiVersion: v1
kind: Pod
spec:
containers:
- name: foo
resources:
limits:
memory: "100M"
requests:
memory: "100M"
cpu: "500m"
volumeMounts:
- name: heap-dumps
mountPath: /dumps
volumes:
- name: heap-dumps
emptyDir: {}OOMKilled Rekapitulation
Nachdem Du die Ursache des OOMK herausgefunden hast, kannst Du die notwendigen Schritte unternehmen, um das Problem zu beheben, z. B. die Speichernutzung optimieren, die Einstellungen der JVM für die Garbage Collection optimieren oder die Speichereinstellungen des betroffenen Pods anpassen.
Das ist grossartig, aber hier stellt sich eine neue Frage: Könnten wir dies nicht tun und die Autoskalierung auf den Speicher beschränken?
Horizontaler Pod-Autoscaler
Autoskalierung auf Speicher könnte ein Ansatz sein, um OOMKilled Ereignisse in Kubernetes zu vermeiden, indem der Horizontal Pod Autoscaler (HPA) verwendet wird.
Autoscaling ist der Prozess der automatischen Anpassung der Anzahl der Replikate eines Pods auf der Grundlage der Ressourcennutzung. Durch die Konfiguration von Autoscaling für den Speicher können wir sicherstellen, dass die Anzahl der Replikate eines Pods steigt, wenn sich seine Speichernutzung dem Limit nähert, und sinkt, wenn seine Speichernutzung sinkt. Auf diese Weise können wir OOMKilled Ereignisse vermeiden und sicherstellen, dass die Speichernutzung des Pods innerhalb akzeptabler Grenzen bleibt.
Sehen wir uns ein Beispiel für ein Helm-Diagramm an, das die HPA-Ressource verwendet:
# {prod,stage}_values.yaml
autoscaling:
cpu: 70
memory: 75
minReplicas: 5
maxReplicas: 24Wenn die durchschnittliche Speicherauslastung der Pods in der Bereitstellung über der Zielauslastung (75%) liegt, skaliert die HPA die Anzahl der Replikate hoch. Wenn jedoch die durchschnittliche CPU-Auslastung der Pods unter der Zielauslastung liegt, wird die HPA die Anzahl der Replikate verringern. Das Gleiche gilt für die CPU-Auslastung (70%).
Dieses Helm-Diagramm wird in das folgende HPA-Manifest umgewandelt:
apiVersion: autoscaling/v2beta1
kind: HorizontalPodAutoscaler
spec:
minReplicas: 5
maxReplicas: 24
metrics:
- type: Resource
resource:
name: cpu
targetAverageUtilization: 70
- type: Resource
resource:
name: memory
targetAverageUtilization: 75Wie funktioniert die HPA?
Grundsätzlich wird die HPA die Anzahl der Replikate zwischen den unter minReplicas und maxReplicas festgelegten Mindest- und Höchstwerten halten.
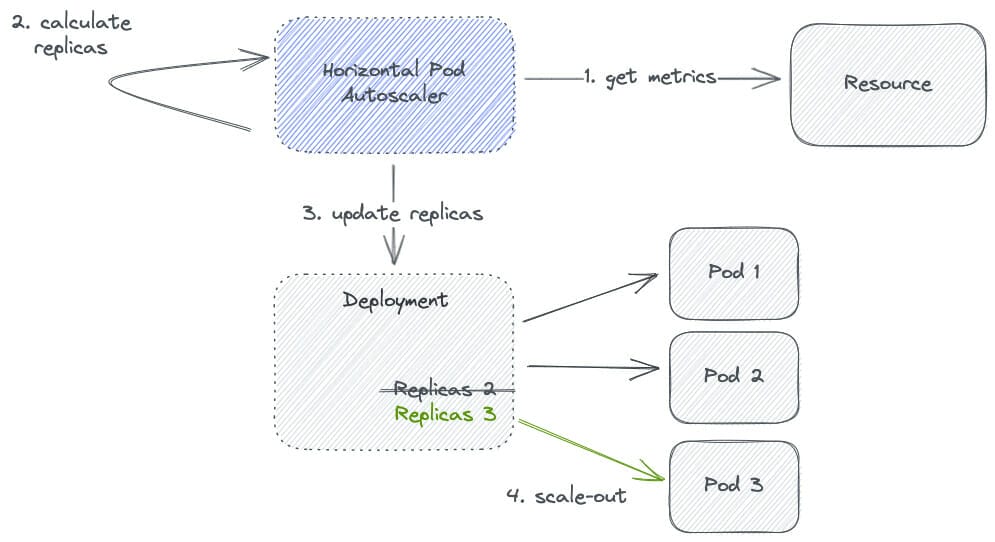
Anhand des Diagramms würde Schritt 2 (Replikate berechnen) in Pseudocode wie folgt berechnet werden:
desiredReplicas = ceil(
currentReplicas * (currentMetricValue / desiredMetricValue )
)
currentMetricValue = avg(metric across all replicas)
desiredMetricValue = targetAverageUtilization * metric’s request value
usage rate = currentMetricValue / desiredMetricValue :
- > 1.1 -> scale up
- < 0.9 -> scale down
- -> no changes
minReplicas <= desiredReplicas <= maxReplicasHPA - CPU Beispiel
Hier ist ein Beispiel für eine Kubernetes HPA-Ressourcenkonfiguration, die sich auf die automatische Skalierung basierend auf der CPU-Auslastung konzentriert:
# values.yaml
resources:
requests:
cpu: "1"
autoscaling:
cpu: 80
minReplicas: 1
maxReplicas: 4Wie Du im obigen Beispiel sehen kannst, fordern wir 1 CPU für den Pod an und streben eine durchschnittliche Auslastung dieser CPU von etwa 80% an, wobei eine Autoskalierung zwischen 1 und 4 Replikaten erfolgt.
# manifests
spec:
containers:
- name: foo
resources:
requests:
cpu: "1"
spec:
minReplicas: 1
maxReplicas: 4
metrics:
- type: Resource
resource:
name: cpu
targetAverageUtilization: 80Lass uns nach dem oben beschriebenen Algorithmus die gewünschte Anzahl der Pods ermitteln:
> kubectl -n ${namespace} get hpa
> kubectl -n ${namespace} describe hpa ${hpa_name}
Metrics: ( current / target )
resource cpu on pods: 90% (900m) / 80%
Min replicas: 1
Max replicas: 4
Deployment pods: 1 current / x desiredDaraus können wir schliessen, dass:
- Wir haben 1 aktuelle Replik.
- Der aktuelle CPU-Wert beträgt 90% (0,9).
- Der gewünschte Wert (
targetAverageUtilization) ist 80% (0,8).
Die Lösung von x, der gewünschten Anzahl von Schoten, würde bedeuten:
x = ceil(currentReplicas * (currentValue / desiredValue))
x = ceil(1 * (currentValue / desiredValue))
x = ceil(1 * (0.9 / desiredValue))
x = ceil(1 * (0.9 / 0.8))
x = ceil(1 * 1.125)
x = 2Die Nutzungsrate beträgt also 1.125, was über 1.1 liegt, so dass eine Skalierung auf 2 Pods erforderlich ist. Abschliessend haben wir hier gezeigt, wie die HPA für die CPU funktioniert, aber wie funktioniert die HPA für den Speicher?
HPA - Speicher Beispiel
# manifests
spec:
containers:
- name: foo
resources:
limits:
memory: "1000M"
requests:
memory: "1000M"
spec:
minReplicas: 1
maxReplicas: 4
metrics:
- type: Resource
resource:
name: memory
targetAverageUtilization: 80Je nach Bedarf kann der Speicher den Cluster nach oben skalieren, und zwar nach folgendem Schema:
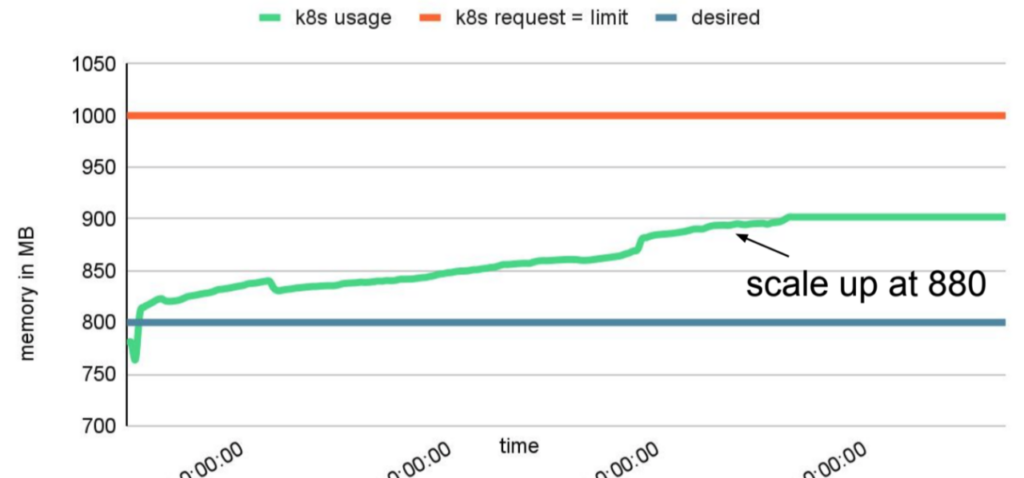
Die JVM ist jedoch nicht daran interessiert, Speicher zurückzugeben, um eine mögliche Verkleinerung zu vermeiden. Dies liegt daran, dass die JVM versucht, die Speichernutzung innerhalb der durch das -Xmx JVM-Flag definierten Heap-Grösse zu halten. Wenn sich die Speichernutzung der definierten maximalen Heap-Grösse nähert, führt die JVM eine GC durch, um ungenutzten Speicher zurückzufordern und die Speichernutzung zu senken. Die GC fordert jedoch nur manchmal den gesamten ungenutzten Speicher zurück, und ein Teil des Speichers wird möglicherweise länger beibehalten. Und warum? Die JVM vermeidet häufige GC, die zu Anwendungspausen führen und die Leistung beeinträchtigen können. Der zurückgehaltene Speicher kann auch für künftige Zuweisungen verwendet werden, wodurch die JVM Speicherverschwendung vermeidet.
Daher kann es sein, dass die JVM nicht genug Speicher zurückgibt, um eine Verkleinerung durch die HPA zu ermöglichen, selbst wenn die Speichernutzung unter dem festgelegten Schwellenwert liegt. Dennoch ist es möglich, mit der richtigen Abstimmung und Untersuchung (wiederum um die Einstellung -Xmx und die GC-Flags herum) das richtige Gleichgewicht zwischen Speichernutzung und der Fähigkeit zur Verkleinerung zu finden.
HPA - Zusammenfassung
Die automatische Skalierung des Arbeitsspeichers kann einen dynamischen und automatisierten Weg bieten, um sicherzustellen, dass die Speichernutzung von Pods innerhalb akzeptabler Grenzen bleibt, wodurch die Notwendigkeit einer manuellen Abstimmung und Konfiguration von Speichergrenzen reduziert wird. Es ist jedoch zu bedenken, dass die automatische Skalierung einen eigenen Ressourcen- und Rechenaufwand mit sich bringt und dass der Scale-Down-Prozess möglicherweise aus zuvor festgelegten Gründen nicht ausgelöst wird. Auch hier wären weitere Untersuchungen erforderlich.
Abschliessende Gedanken
Abschliessend haben wir auf dieser Reise gelernt, dass bei der Bereitstellung von Scala-Microservices in einem Kubernetes-Cluster der Speicherbedarf der JVM sorgfältig berücksichtigt werden muss. Eine automatische Skalierung allein auf der Grundlage der Speichernutzung wird nicht empfohlen, da das Verhalten der JVM bei der Freigabe von Speicher es schwierig machen kann, den richtigen Zeitpunkt für eine Skalierung zu bestimmen. Stattdessen sind Versuch und Irrtum, Nachforschungen und die Überwachung von Metriken entscheidend, um die optimalen Einstellungen für Anfragen und Grenzen zu finden und diese im Laufe der Zeit fein abzustimmen. Der Horizontal Pod Autoscaler (HPA) kann ein effektives Werkzeug für die Skalierung von Replikaten als Reaktion auf Änderungen in der Ressourcennutzung sein, solange er in Verbindung mit den entsprechenden Metriken verwendet und im Laufe der Zeit fein abgestimmt wird. Ausserdem ist es wichtig, die Rolle des Nicht-Heap-Speichers, des Metaspeichers und des Garbage Collectors zu verstehen, die sich auf die gesamte Speichernutzung der JVM auswirken, und in der Lage zu sein, OOMKilled Probleme zu erkennen und zu diagnostizieren.
Darüber hinaus bietet die Klasse Kubernetes Quality of Service (QoS) eine weitere Dimension der Kontrolle über die für die JVM verfügbaren Ressourcen. Mit ihr kann sichergestellt werden, dass kritischere Pods die notwendigen Ressourcen erhalten, während Pods mit niedrigerer Priorität entsprechend eingeschränkt werden. Durch die Kombination von effektiven Ressourcenverwaltungspraktiken und Kubernetes-Tools können wir skalierbare und widerstandsfähige Systeme aufbauen, die besser für die Anforderungen der Ausführung von JVM-basierten Anwendungen in einer containerisierten Umgebung gerüstet sind.

Verfasst von
Juan Pedro Moreno
Juan Pedro boasts over 15 years of experience in the IT sector, with a deep specialization in software engineering, functional programming, data engineering, microservices architecture, and cloud technologies. He likes to balance his professional career with a passion for endurance sports. Residing in sunny Cadiz, Spain, with his family, he actively participates in running, biking, and triathlons, embodying the discipline and resilience he applies to his personal and professional endeavors.
Unsere Ideen
Weitere Blogs




Contact