
Heute befassen wir uns mit einer weiteren Technik, die die Qualität Ihrer Software erheblich verbessern kann: Fuzzing. Im Kern geht es beim Fuzzing um ein ganz einfaches Konzept: Versorgen Sie ein Programm mit ungültigen, zufälligen oder unerwarteten Eingaben, bis es zu einem Absturz kommt.
Die Grundlagen verstehen
Stellen Sie sich vor, Sie haben ein Programm entwickelt, das JPEG-Bilder verarbeiten kann. Nun stellen Sie sich vor, Sie laden ein PNG-Bild, eine PDF-Datei, eine 200 MB große PowerPoint-Präsentation oder sogar eine Datei mit beliebigem Kauderwelsch. Was sollte das Programm tun? Nun, das hängt von Ihrem Programm ab, aber ein kontrollierter Abbruch mit einer aussagekräftigen Fehlermeldung (wie z.B. "die von Ihnen angegebene Datei ist kein gültiges JPEG-Bild") erscheint sinnvoll. Abhängig von der Implementierung der Dateiprüfung könnten Sie die PDF-Datei ablehnen, aber das PNG-Bild könnte durch Ihre erste Prüfung durchkommen, da es ein gültiges Bildformat ist. Aber wie reagiert Ihr Bilddecoder, die Komponente, die für das Lesen und Dekodieren des JPEG-Binärstroms zuständig ist, auf die Bits und Bytes einer PNG-Datei? Macht er anständig weiter oder stürzt er katastrophal ab? Sie könnte überleben, wenn sie die Bytes, die den Dateiheader bilden, nicht verstehen kann. Was aber, wenn wir die PNG-Datei durch eine beschädigte JPEG-Datei ersetzen? Eine mit einem gültigen Dateiheader, aber mit zufälligen Daten danach?
Das Potenzial für Fehler ist enorm. Obwohl rigorose Softwareentwicklungspraktiken wie umfassende automatisierte Tests und sogar Test Driven Development (TDD) in Verbindung mit der Berücksichtigung von Randfällen viele Probleme verhindern können, besteht immer die Möglichkeit unvorhergesehener Fehler.
An dieser Stelle kommt Fuzzing ins Spiel, das den oben beschriebenen Prozess automatisiert. Sie geben das Programm an, das Sie testen möchten, und das Fuzzing-Tool bombardiert es mit zufällig generierten Dateien, bis es etwas entdeckt, das einen Absturz auslöst. Diese absturzverursachenden Dateien können dann manuell untersucht, analysiert und ausgewertet werden, um die Ursachen für diese Abstürze zu beheben. Letztendlich erhöht dies die Qualität Ihres Produkts, insbesondere wenn es um Schwachstellen wie Speicherkorruption oder ausnutzbare Pufferüberläufe geht.
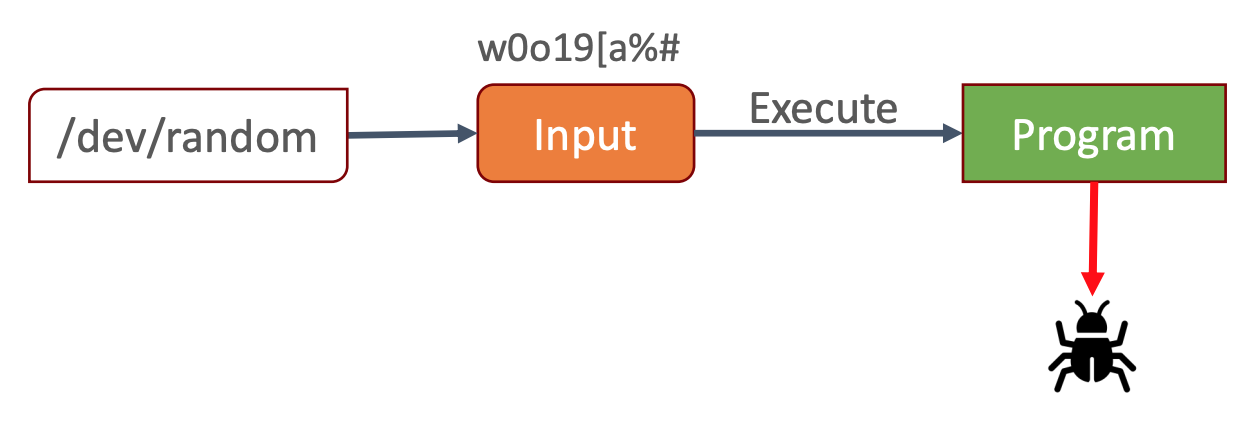
Abbildung 1: Workload-Idee
Herausforderungen mit reinen Zufallsdaten
Nachdem wir nun das Grundprinzip erläutert haben, wollen wir uns dem ersten Schritt widmen: der Erstellung der Dateien, die wir in unser Programm einspeisen wollen, und vor allem der Frage, woher wir sie bekommen.
Die Herausforderung liegt hier darin, dass wir (a) die Dateien nicht selbst bereitstellen können, da ein Teil des Fuzzing-Prozesses darin besteht, unbekannte Probleme aufzudecken, und (b) reine Zufallsdaten nicht ideal sind. Die Erzeugung reiner Zufallsdaten ist in der Tat einfach; wir könnten einfach aus einer Zufallsquelle wie /dev/random lesen. Aber hilft uns das wirklich weiter? In den meisten Fällen handelt es sich bei reinen Zufallsdaten nur um Rauschen im Zusammenhang mit unserem Programm.
Zur Veranschaulichung betrachten Sie Apache Ant, ein Tool zur Build-Automatisierung, das Build-Definitionen aus XML-Dateien interpretiert. Das Ersetzen der XML-Datei durch zufällige Bytes würde zu einem Chaos führen:
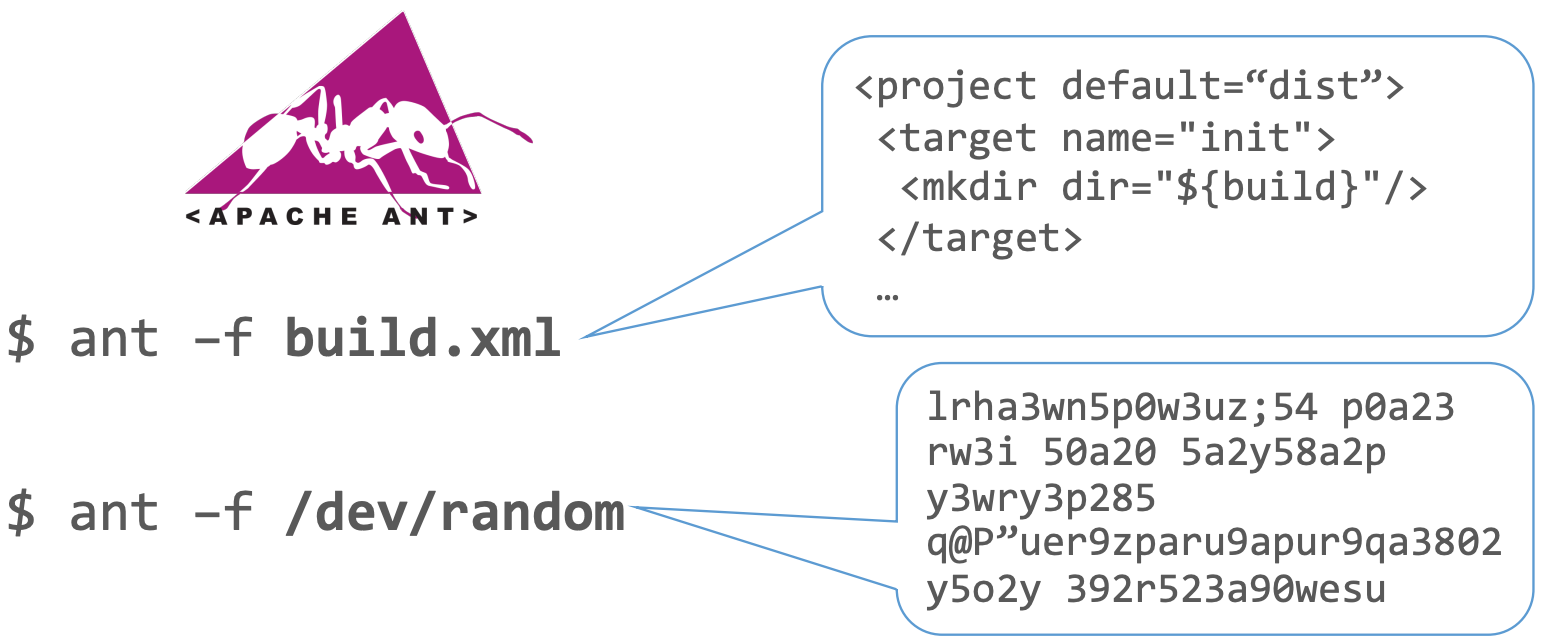
Abbildung 2: Ameise Random
Unsere Zufallsbytes haben keine Ähnlichkeit mit einer gültigen Eingabe. Es ist zwar möglich, mit Zufallsbytes eine gültige XML-Datei zu generieren, aber die Wahrscheinlichkeit ist gering, und wir wollen, dass das Fuzzing innerhalb eines vernünftigen Zeitrahmens verwertbare Ergebnisse liefert. Wir können die Laufzeit unseres Fuzzing-Vorhabens nicht außer Acht lassen.
Da sich zufällige Bytes stark von vernünftigem XML unterscheiden, werden wir wahrscheinlich immer wieder auf dieselben Überprüfungen der Eingabe stoßen. Ist die Eingabe eine gültige XML-Datei? Nein? Beenden Sie vorzeitig. Dieser Zyklus würde sich fortsetzen und jeden geschäftsrelevanten Code umgehen.
Wenn wir jedoch unsere Strategie vom reinen Zufall auf einen leicht "mutierten" Ansatz umstellen (der aufmerksame Leser wird vielleicht den Bezug zu Mutationstests bemerken), kommen wir zu einem Ergebnis wie diesem:
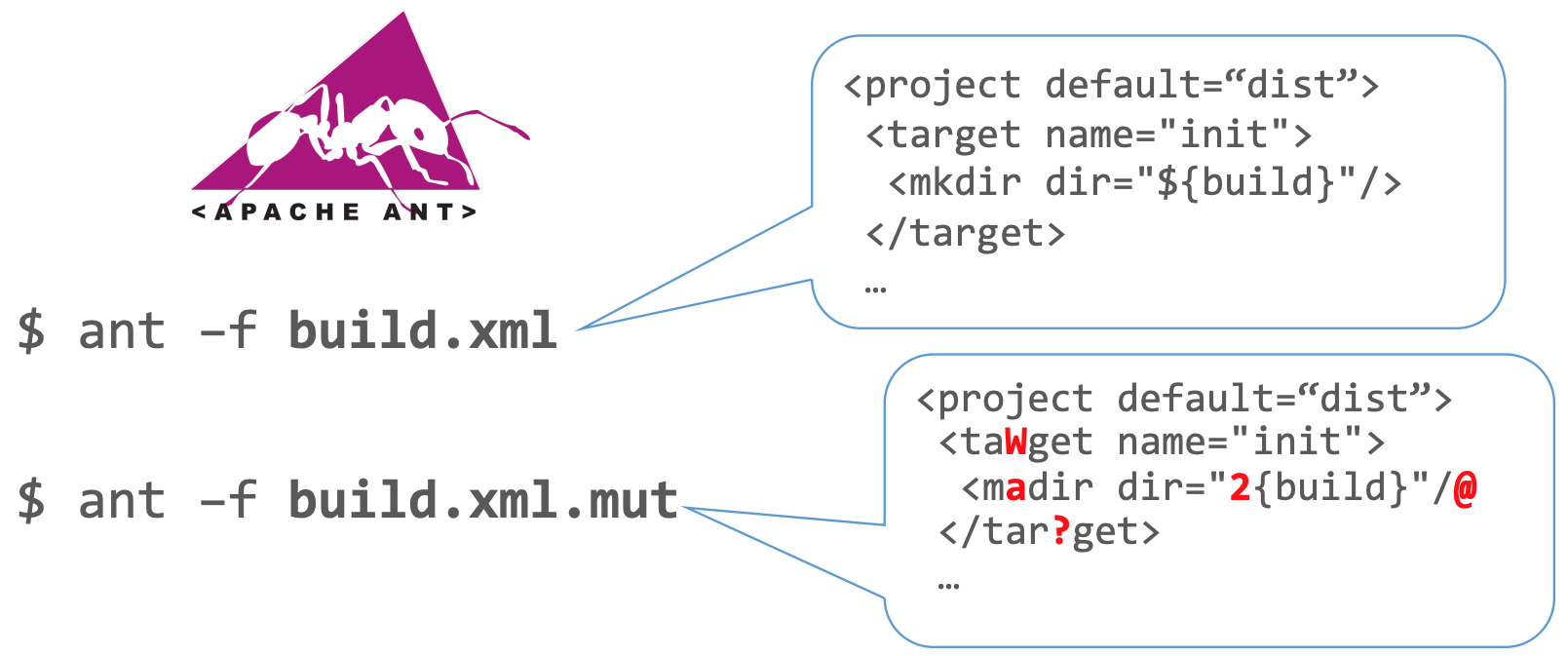
Abbildung 3: Ameise mutiert
Hier werden die Dinge interessant. Unsere neue Eingabe ähnelt immer noch XML, aber mit kleineren Mängeln - Mängel, die subtil genug sind, um den Zugang zu tieferen Teilen unseres Programms zu ermöglichen, aber dennoch Mängel sind. Nehmen wir an, Sie haben einen Code geschrieben, der für die Verarbeitung eines bestimmten XML-Knotens zuständig ist, so dass <mkdir dir="foo" /> ein Verzeichnis namens "foo" erstellt.
Wo registrieren Sie diese neue Aktion? Vielleicht in einer globalen Nachschlagetabelle, wo Sie Ihre Aktions-Callback-Funktion dem Namen mkdir zuweisen? Ausgezeichnet. Dieser zentrale Registrierungspunkt vereinfacht die Definition und Registrierung von Aktionen.
Aber wie geht unser Programm mit dem Zugriff auf diese globale Hashtabelle um? Wird es anständig behandelt, wenn es versucht, die Callback-Funktion für einen unbekannten Aktionsnamen abzurufen? Oder gibt es einen Fehler aus, weil es noch niemand mit ungültigen oder unbekannten Aktionsnamen getestet hat?
Dies zeigt, dass leicht mutierte Daten weitaus effektiver sind als reine Zufallsdaten. Mit einer einzigen, geringfügigen Mutation war unsere Build-Definition in der Lage, eine ungültige Aktion auszulösen (madir, nur einen Ein-Zeichen-Fehler entfernt von der gültigen mkdir).
Fortschritte verfolgen
Wir haben festgestellt, dass mutierte Daten den reinen Zufall übertreffen. Aber wie können wir unseren Fortschritt messen? Wann entscheiden wir, dass wir genug Versuche mit mutierten Daten unternommen haben? Der theoretische Raum der möglichen Funktionsaufrufe ist scheinbar unendlich.
Wäre es nicht fantastisch, irgendwie in das Programm, das wir testen, hineinzuschauen, und sei es nur kurz, um unsere Fortschritte zu beobachten? Wie tief sind wir mit unseren veränderten Eingaben in das Programm eingedrungen?
Das ist genau das, was das abdeckungsgesteuerte Fuzzing tut. Um dies zu implementieren, benötigen wir ein spezielles Build unseres Programms, das mit einigen Instrumenten ausgestattet ist. Diese Instrumentierung hat keinen Einfluss auf das Verhalten des Programms; sie ermöglicht es dem Fuzzing-Tool lediglich, die Ausführungspfade zu überwachen.
Da wir nun die Ausführungspfade verfolgen können, können wir unsere mutierte Eingabe bewerten. Diese Fähigkeit ist von entscheidender Bedeutung, denn sie ermöglicht es uns, eine positive Rückkopplungsschleife zu schaffen, die uns automatisch tiefer in das Programm hineinführt und so mehr Code mit unserer bösartigen Eingabe erreicht. Wie funktioniert das? Lassen Sie uns den Prozess untersuchen:
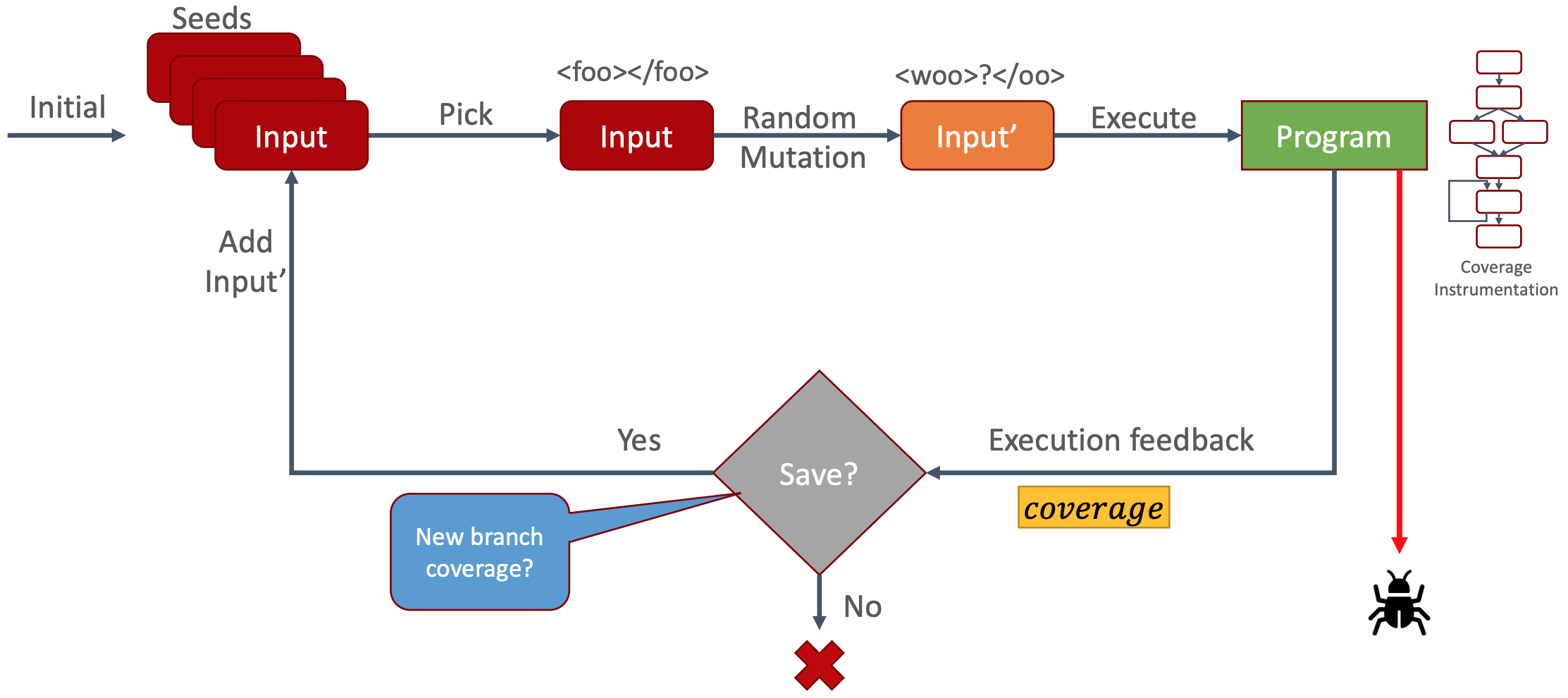
Abbildung 4: Vollständiger Arbeitsablauf
- Initialisieren und bereiten Sie einige Seed-Dateien vor, die durchaus gültige Dateien wie eine funktionale Ant Build-XML-Datei enthalten können.
- Das Fuzzing-Tool wählt eine der Seed-Dateien aus.
- Es wendet eine zufällige Mutation auf die ausgewählte Datei an.
- Die veränderte Datei wird dann zum Testen an das Programm übergeben.
- Ist es abgestürzt? Wenn ja, haben wir etwas entdeckt und melden die Eingabedatei, die den Absturz verursacht hat.
- Wenn kein Absturz erfolgt, untersuchen wir den Ausführungspfad (dank des Instrumentierungscodes).
- Haben wir bisher unerforschte Wege beschritten? Wenn ja, fügen wir die Eingabedatei zu unserer Sammlung von Seed-Inputs hinzu.
- Wenn nicht, können wir einfach alles verwerfen.
Diese Schleife wiederholt sich ständig, aber Schritt 7 ist der entscheidende. Betrachten Sie dies einen Moment lang: Jede Eingabedatei, die zu neuen Ausführungspfaden innerhalb des Programms führt, wird zu unserer Seed-Sammlung hinzugefügt.
Dieser Prozess ähnelt der Evolution. Eine mutierte Eingabedatei der "ersten Generation" könnte gerade erst "einen Fuß in die Tür bekommen". Wenn Sie sie erneut in die Saatgutsammlung einbringen, hat sie die Möglichkeit, eine "zweite Generation" zu erzeugen. Diese Eingabedatei der zweiten Generation könnte sich weiter entwickeln und das Programm vielleicht vollständig infiltrieren. Wir entwickeln uns im Wesentlichen durch Mutation und Versagen weiter.
Den Prozess automatisieren
Bis zu diesem Punkt haben wir die Theorie diskutiert. Aber wie können wir das in die Praxis umsetzen? Müssen wir alles von Grund auf neu entwickeln, oder können wir vorhandene Tools verwenden? Hier kommt
AFL
und
SharpFuzz
. Beide Open-Source-Tools machen Fuzzing in C# zu einem unkomplizierten Prozess.
AFL (Amerikanischer Fuzzy Lop)
gilt als De-facto-Standard für Fuzzing und ist weit verbreitet. Es hat zahlreiche bedeutende Softwarefehler in wichtigen Anwendungen wie OpenSSL, Bash, Firefox und SQLite entdeckt. AFL ist auch im akademischen Bereich weit verbreitet, da akademische Fuzzer oft Forks davon sind und AFL häufig als Basis für die Bewertung neuer Techniken verwendet wird.
SharpFuzz
erweitert die Leistungsfähigkeit von AFL auf .NET. Es handelt sich um eine leichtgewichtige Bibliothek, die das Hinzufügen des erforderlichen Instrumentierungscodes erleichtert (damit AFL mit .NET arbeiten kann) und Funktionen zur Vereinfachung der Einrichtung bietet.
Mit den beiden Tools, die Ihnen zur Verfügung stehen, müssen Sie sich nicht mit den Feinheiten der Fuzzing-Logik befassen. Stattdessen können Sie sich auf Ihren Code konzentrieren.
Was Sie anvisieren sollten
Der letzte Aspekt, den Sie verstehen müssen, ist, dass Fuzzing vielseitig ist - Sie können praktisch alles angreifen. Es muss nicht unbedingt Ihre gesamte Anwendung sein. Stellen Sie sich vor, Sie haben eine Windows-Desktop-Anwendung entwickelt, die HTML rendern kann, und Sie möchten Fuzzing einsetzen, um diesen Rendering-Prozess zu verstärken. Aber die Anwendung ist in mehreren Ebenen von Menüs und Schaltflächen versteckt! Müssen Sie jetzt durch die gesamte Benutzeroberfläche "fuzzy-navigieren"?
Ganz und gar nicht. Sicher, aus der Sicht von AFL ist es einfach eine ausführbare Binärdatei, die veränderte Eingabedateien erhält. Sie können mühelos ein kleines Fuzzing-Harness erstellen, etwa so:
public class Program
{
public static void Main(string[] args)
{
Fuzzer.OutOfProcess.Run(stream => {
try {
new HtmlParser().Parse(stream);
}
catch (InvalidOperationException) {
// Whitelist known or "good" exceptions
}
});
}
}Hier steht HtmlParser für die HTML-Parsing-Bibliothek, die Sie testen möchten. Mit der Hilfe von SharpFuzz ist die Erstellung eines speziellen Fuzzing-Kabelbaums ganz einfach.
Bemerkenswert ist hier die InvalidOperationException, die wir abfangen. Aus der Sicht von AFL wird jeder Programmabsturz als "fehlerhaftes Verhalten" gekennzeichnet und als möglicher Fehler verfolgt. Bei InvalidOperationException ist dies jedoch nicht der Fall. Diese Ausnahme dient HtmlParserdazu, dem Aufrufer zu signalisieren, dass er auf etwas gestoßen ist, das er nicht parsen konnte. Um zu verhindern, dass AFL dies als falsches positives Ergebnis ausgibt, fangen wir diese Ausnahme ab und setzen sie auf die Whitelist.
Mit dem Fuzzing-Kabelbaum benötigen Sie nur eine einzige Seed-Eingabedatei, die eine vollkommen gültige Datei wie dieses prägnante HTML-Snippet sein kann:
<!DOCTYPE html><html><body><h1>h1</h1><p>p</p></body></html>Jetzt können Sie AFL auf Ihr Programm richten und es seine Wirkung entfalten lassen:

Abbildung 5: Amerikanischer Fuzzy Lop
Auch wenn die Ausgabe überwältigend erscheinen mag, handelt es sich um einen Screenshot der AFL Command Line Interface (CLI)-Ausgabe, einer interaktiven Textbenutzeroberfläche (TUI), mit der Sie den Fortschritt in Echtzeit überwachen und verfolgen können. Sie liefert wichtige Informationen, darunter:
- Gesamtlaufzeit (oben links)
- Von AFL entdeckte einzigartige Pfade insgesamt (oben rechts)
- Programmausführungen insgesamt (Mitte links)
- Programmausführungen pro Sekunde (Mitte links)
- Von der AFL angewandte Mutationsstrategien (unten links)
Über diese Schnittstelle können Sie die Ausführung von AFL genau beobachten, und irgendwann könnte AFL einen Absturz entdecken! Sie können dann die von AFL erzeugte Datei untersuchen:
<svg><!DOCTYPE html><<template>html><desc><template>><p>p</p></body></html>Erfolg! Wir haben eine bösartige Eingabe gefunden, die unser HtmlParser zum Absturz bringen kann. Jetzt können wir dieses Problem beheben, einen Unit-Test erstellen, um künftige Regressionen zu verhindern, und die üblichen Entwicklungspraktiken anwenden.
Bilder aus dem Nichts schaffen
Wir haben gesehen, wie AFL unsere einfache HTML-Eingabe so verändert hat, dass sie zu einem Absturz von HtmlParser geführt hat. Aber wie gut ist AFL? Wie weit kann es seine Fähigkeiten ausdehnen? Kurz gesagt, ziemlich weit!
Ich bin auf diesen faszinierenden Artikel von Michal Zalewski gestoßen, in dem er beschreibt, wie AFL scheinbar aus dem Nichts gültige JPG-Dateien erzeugen konnte:

Abbildung 6: Dünne Luft
Zugegeben, es sind keine ästhetisch ansprechenden Bilder, aber es sind zweifellos gültige JPG-Dateien. Sie wurden alle von AFL erstellt, als es sich fleißig seinen Weg durch ein JPG-Dekodierungstool bahnte.
Fazit
Fuzzing ist ein spannendes Abenteuer, mit dem Sie Bugs in Ihrem Programm aufdecken können. Wichtig ist, dass es nicht auf Endbenutzeranwendungen beschränkt ist. Mit einem speziellen Fuzzing-Kabelbaum können Sie einzelne Funktionen oder ganze Bibliotheken isolieren und AFL auf sie richten.
Aufgrund seines generativen Charakters ist es jedoch wichtig, auf die Laufzeit zu achten. Fuzzing ist unweigerlich langsamer als Unit-Tests. Betrachten Sie es daher als ein ergänzendes Werkzeug. Unit-Tests überprüfen die bekannten Pfade, aber Fuzzing eignet sich hervorragend zum Aufspüren der unbekannten Pfade!
Dieser Artikel ist Teil des XPRT. Magazin #15 Hier herunterladen

Verfasst von

Michael Contento
Unsere Ideen
Weitere Blogs




Contact