Blog
Vier Tipps zur besseren Strukturierung von Terraform-Projekten

Infrastructure as Code (IaC) kodiert die Bereitstellung der Infrastruktur. Auf diese Weise können Sie die Vorteile bewährter Software-Engineering-Verfahren nutzen, um eine schnellere und konsistente Bereitstellung der Infrastruktur zu erreichen. Eines der führenden IaC-Software-Tools ist Hashicorps Terraform und mit der Rückkehr der Hashiconf nach Amsterdam Ich habe beschlossen, meine persönlichen Empfehlungen für eine bessere Strukturierung Ihrer Terraform-Projekte mit Ihnen zu teilen! In diesem Blog werde ich vier Tipps geben, die ich bei der Verwendung von Terraform in der Praxis gelernt habe. Aber lassen Sie uns zunächst damit beginnen, ein gemeinsames Verständnis von Terraform zu schaffen.
Ein gemeinsames Verständnis von Terraform
Terraform ist ein herstellerunabhängiges IaC-Software-Tool, d.h. es kann zur Bereitstellung von Diensten verschiedener Anbieter verwendet werden über so genannte Provider. Dies steht im Gegensatz zu Tools wie AWS CloudFormation oder Azure Resource Manager Templates, die nur für einen einzigen Anbieter funktionieren. Beliebte Terraform-Anbieter werden für Cloud-Anbieter wie AWS, Azure und GCP, Open-Source-Tools wie Kubernetes und Helm, Unternehmens-Tools wie Salesforce und Snowflake und mehr verwendet!
Um die Infrastruktur mit Terraform zu definieren, wird Code geschrieben, der die Ressourcen unter Verwendung von Terraform-Anbietern. Der Code ist derzeit ausschließlich in der domänenspezifischen Sprache HCL von Hashicorp geschrieben, wird aber in Kürze gängige Programmiersprachen über die In-Preview unterstützen CDKTF! Während der Bereitstellung wird der Terraform-Code dann über die oben genannten Anbieter in API-Aufrufe des jeweiligen Anbieters umgewandelt, um die Ressourcen bereitzustellen.
Terraform speichert die Metadaten für alle bereitgestellten Ressourcen in einer bestimmten Statusdatei. Vor jeder Terraform-Bereitstellung, die durchgeführt wird (mit terraform apply) wird der Status aktualisiert, d.h. alle bereitgestellten Ressourcen und ihre Metadaten werden abgerufen und mit der Statusdatei verglichen, um festzustellen, welche Änderungen an der Infrastruktur vorgenommen werden sollten. Terraform ist eines der wenigen IaC-Software-Tools, das Statusdateien verwendet. Das macht Terraform zwar einfach und leistungsfähig, aber die Pflege des Status bringt auch eine Reihe von Herausforderungen mit sich (wie in diesem Blog deutlich wird).
Tipps für die Arbeit mit Terraform
Während es einfach ist, Terraform in einer "Hello world"-Einstellung zu verwenden, wird es schnell zu einer Herausforderung, wenn Sie Terraform auf reale Systeme anwenden, die mehrere Ressourcen enthalten. In diesen Situationen wende ich immer Folgendes an eigenwillig Struktur:
1. Verwenden Sie Terraform Arbeitsbereiche zur Trennung von Umgebungen
Jede Umgebung sollte ihre eigene Statusdatei haben: für eine DTAP-Straße also eine separate Status für die Entwicklungs-, Test-, Abnahme- und Produktionsumgebung erforderlich ist. Terraform bietet zwei Möglichkeiten, mit der Situation einer separaten Statusdatei pro Umgebung umzugehen:
- Individuelle Statusdateien: ein Terraform-Backend pro Umgebung:
- Terraform-Workspaces: ein "gemeinsames" Terraform-Backend für alle Umgebungen
Für verschiedene Umgebungen empfehle ich die Verwendung von Terraform Workspaces. Der Wechsel zwischen Umgebungen bei der Verwendung von Workspaces ist im Vergleich zu individuellen Statusdateien weniger mühsam: schnell und einfach terraform.workspace, die eine bequeme Möglichkeit zur Unterscheidung zwischen Ressourceneinstellungen in verschiedenen Umgebungen darstellt.
2. Bevorzugen Sie mehrere kleinere Staaten anstelle eines großen Staates
Es ist zwar praktisch, alle Ressourcen für eine Umgebung in einer einzigen, monolithischen Statusdatei zu speichern, aber ich plädiere gegen dies aus folgenden Gründen:
- Langsame Terraform-Operationen
Die wichtigsten Terraform-Operationen (
terraform plan/apply/destroy) die Statusdatei aktualisieren. Da die Anzahl der in der Statusdatei verfolgten Ressourcen wächst, nimmt die Zeit für die Aktualisierung einer Statusdatei zu. Terraform wendet zwar Gleichzeitigkeit an, um diese Aktualisierungszeit zu minimieren, ist aber auf (ratenbegrenzte) APIs angewiesen, um die erforderlichen Metadaten zu erhalten. Je weniger Ressourcen also in einer einzelnen Statusdatei verfolgt werden, desto besser.
- Weniger Kontrolle über Einsätze Die Verfolgung zu vieler Ressourcen in einer Statusdatei ermöglicht nicht ohne weiteres eine feinkörnige Kontrolle über die Einsätze, wie z.B. den teilweisen (erneuten) Einsatz oder die Zerstörung von Ressourcen. Durch die Verwendung kleinerer Deployments anstelle eines einzigen größeren Deployments wird der Status der Ressourcen von Terraform nur dann aktualisiert, wenn dies wirklich notwendig ist, wodurch die Einführung von (ungewollten) Fehlern verhindert wird.
- Großer Explosionsradius: Die Statusdatei ist die einzige Quelle der Wahrheit für Ressourcen, die mit Terraform bereitgestellt werden. Wenn der gesamte Zustand der Infrastruktur in einer einzigen Statusdatei verfolgt wird, kann ein Fehler (z.B. ein versehentliches Terraform zerstören oder Beschädigung der Statusdatei) gefährdet das gesamte System.
Um diese Probleme zu vermeiden, habe ich mich stattdessen für mehrere kleinere Statusdateien entschieden, eine für jede logische Komponente. Bei einer einfachen Webanwendung (siehe Abbildung 1) würde dies zu separaten Statusdateien führen, beispielsweise für das virtuelle Netzwerk, die Datenbank und die Anwendung. In diesem Fall sind die Statusdateien lose gekoppelt, da die Statusdatei in einem Verzeichnis standardmäßig keine Kenntnis von den Ressourcen in den Statusdateien anderer Verzeichnisse hat. Wenn diese Informationen gewünscht sind, können die Ressourceninformationen über Terraform importiert werden Datenquellen.
[caption id="attachment_55675" align="aligncenter" width="550"]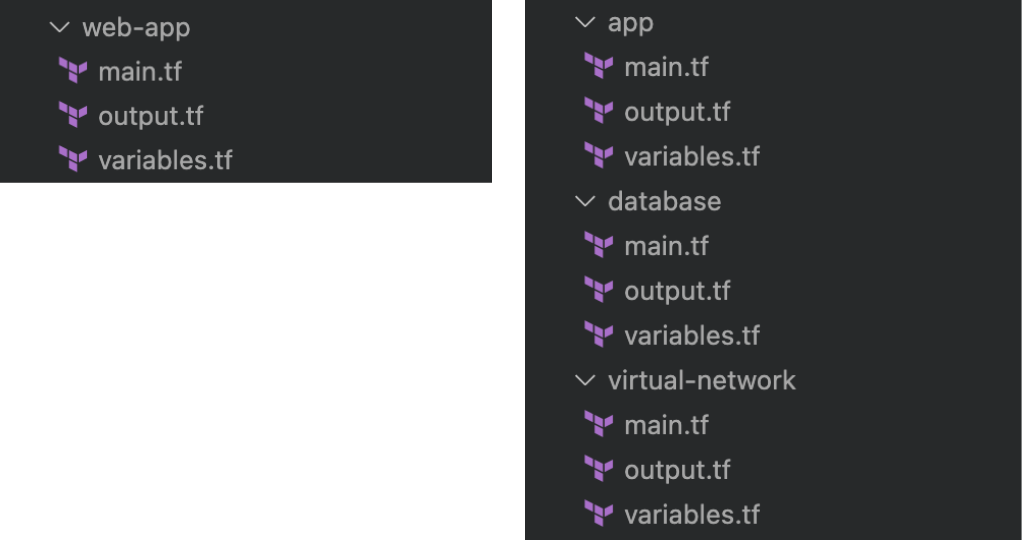 Abbildung 1: Links: Terraform-Setup mit einer monolithischen Statusdatei, rechts: Terraform-Einrichtung mit mehreren kleineren Statusdateien[/caption]
Abbildung 1: Links: Terraform-Setup mit einer monolithischen Statusdatei, rechts: Terraform-Einrichtung mit mehreren kleineren Statusdateien[/caption]
3. Geben Sie Terraform-Dateien logische Namen
Terraform-Tutorials im Internet zeigen oft eine Verzeichnisstruktur, die aus drei Dateien besteht:
main.tf: enthält alle Anbieter, Ressourcen und Datenquellenvariables.tf: enthält alle definierten Variablenoutput.tf: enthält alle Ausgaberessourcen
Das Problem bei dieser Struktur ist, dass die meiste Logik in der einzelnen main.tf Datei, die dadurch ziemlich komplex und lang wird. Terraform schreibt diese Struktur jedoch nicht vor, sondern verlangt nur eine Verzeichnis von Terraform-Dateien. Da die Dateinamen für Terraform keine Rolle spielen, schlage ich vor, eine Struktur zu verwenden, die es den Benutzern ermöglicht, den Code schnell zu verstehen. Ich persönlich bevorzuge die folgende Struktur (siehe auch Abbildung 2):
provider.tf: enthält den Terraform-Block und den Provider-Blockdata.tf: enthält alle Datenquellenvariables.tf: enthält alle definierten Variablenlocals.tf: enthält alle lokalen Variablenoutput.tf: enthält alle Ausgaberessourcen- Ein Dateiname pro Komponente. Für unsere einfache Webanwendung würde das Speicherverzeichnis zum Beispiel Dateien wie die folgenden enthalten
database.tfundpermissions.tf. Diese Namen sind beschreibender alsmain.tfund sagen Sie sofort, welche Art von Ressourcen dort erwartet werden.
[caption id="attachment_55674" align="aligncenter" width="695"]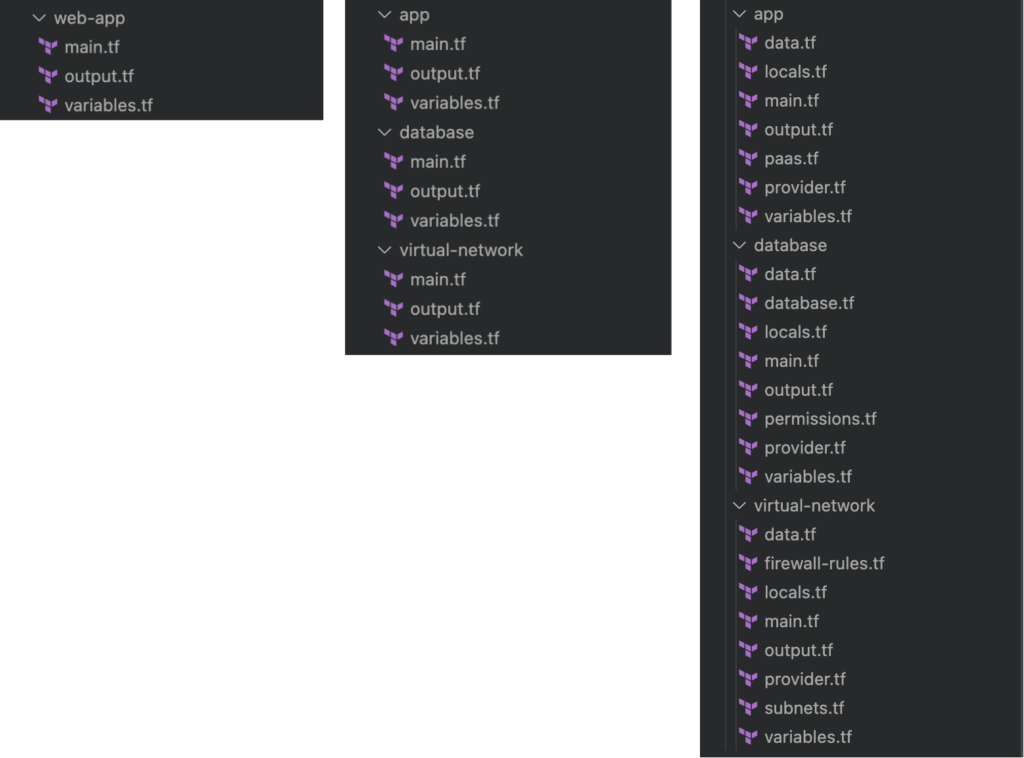 Abbildung 2: Links: Terraform-Setup mit einer monolithischen Zustandsdatei und einem monolithischen
Abbildung 2: Links: Terraform-Setup mit einer monolithischen Zustandsdatei und einem monolithischen main.tf, Mitte: Terraform-Setup mit mehreren kleineren Zustandsdateien und einer monolithischen main.tf, rechts: Terraform-Setup mit mehreren kleineren Zustandsdateien und kleineren Terraform-Dateien[/caption]
4. Einheimische sind oft ausreichend
Terraform erlaubt benutzerdefinierte Eingaben auf zwei Arten:
- Variable Blöcke: sollten für Werte verwendet werden, die nicht im Voraus bekannt sind, wie z.B. IDs, die zur Laufzeit definiert werden.
- Lokale Blöcke: sollten für Werte verwendet werden, die im Voraus bekannt sind, aber gut als Variablen abstrahiert werden können, wie z.B. Konstanten.
Meiner Erfahrung nach können die meisten benutzerdefinierten Eingaben für Terraform durch Locals erfasst werden, was die Terraform-Codebasis erheblich vereinfacht. Außerdem ist es bei locals nicht erforderlich, Werte in *.tfvars(.json)Dateien für eine terraform apply, was die Bereitstellung vereinfacht.
Ein zusätzlicher Tipp, den ich geben möchte, ist die Verwendung von lokalen Blöcken zusammen mit YAML-Dateien. Die Definition umfangreicher Mappings in der HCL ist ziemlich langatmig und ich finde sie schwer zu lesen, aber mit dem yamldecode Funktion können diese Mappings im besser lesbaren YAML-Format gespeichert und in Terraform importiert werden.
[caption id="attachment_55676" align="aligncenter" width="763"] Abbildung 3: Definieren Sie ein Mapping in einem lokalen Block mit HCL (links) und YAML (rechts)[/caption]
Abbildung 3: Definieren Sie ein Mapping in einem lokalen Block mit HCL (links) und YAML (rechts)[/caption]
Fazit
Terraform ist ein beliebtes Software-Tool für Infrastructure as Code, das herstellerunabhängig ist und den Status von Ressourcen-Metadaten verfolgt. Der Einstieg in Terraform ist einfach, aber die Anwendung auf reale Systeme ist schwierig. Deshalb wende ich immer die folgenden Prinzipien an:
- Verwenden Sie Terraform Arbeitsbereiche zur Trennung von Umgebungen
- Bevorzugen Sie mehrere kleinere Staaten anstelle eines großen Staates
- Geben Sie Terraform-Dateien logische Namen
- Einheimische sind oft ausreichend
Was halten Sie von diesen Prinzipien? Haben Sie Tipps für eine noch bessere Einrichtung? Teilen Sie Ihre Gedanken in den Kommentaren unten mit!
Verfasst von
Avinash Pancham
Unsere Ideen
Weitere Blogs




Contact