Warum die Feinabstimmung?
Große Sprachmodelle (LLMs) sind beeindruckende Generalisten. Sie schneiden bei einer Vielzahl von Aufgaben immer besser ab. Bei vielen Benchmarks erreichen sie menschliche oder sogar übermenschliche Leistungen. Alles zu können, kann jedoch seinen Preis haben. Diese so genannten Foundation-Modelle haben Milliarden von Parametern und benötigen eine riesige Menge an GPUs zum Trainieren oder Ausführen. Das ist für die meisten unerschwinglich - also nutzen wir stattdessen LLMs aus APIs, was mit eigenen Erwägungen wie Kosten, Datenschutz, Latenz oder Herstellerbindung verbunden ist. Dies ist nicht die einzige Option. Wenn nur spezialisierte Fähigkeiten benötigt werden, kann auf generalistische Fähigkeiten zugunsten von domänenspezifischem Wissen verzichtet werden, so dass wir mit
Was ist Feinabstimmung?
Die Feinabstimmung ist ein Prozess, bei dem wir ein bereits trainiertes Modell auf einem neuen Datensatz weiter trainieren, normalerweise mit einer geringeren Lernrate. Auf diese Weise kann sich das Modell an die spezifischen Merkmale der neuen Daten anpassen, während das allgemeine Wissen, das es beim ersten Training erworben hat, erhalten bleibt. In der Praxis bedeutet dies oft, dass die oberen Schichten des Modells weiter trainiert werden, während die unteren Schichten eingefroren werden, damit die gelernten Merkmale aus dem ursprünglichen Training erhalten bleiben.
Wie können wir uns also feinjustieren? Lassen Sie uns das herausfinden!
Wie man sich selbst verfeinert ✓✓✓.
Genug geredet! Lassen Sie uns praktisch werden. Lassen Sie uns ein Modell auf unserer eigenen Hardware feinabstimmen. Wir haben Zugriff auf die folgende Einrichtung:
- HP Z8 Fury
- 3x NVIDIA RTX 6000 Ada GPUs
Unser Ziel ist: ein Modell zu verfeinern und es mit MMLU Pro, Kategorie Mathematik, zu vergleichen.
Um mit der Feinabstimmung zu beginnen, müssen wir uns also für Folgendes entscheiden:
1. Rahmen für die Feinabstimmung: Axolotl
Es gibt mehrere Frameworks für die Feinabstimmung: Axolotl, Unsloth und torchtune. Wir haben uns für Axolotl entschieden, weil es so einfach zu bedienen ist und eine Fülle von Beispielen enthält, die sofort einsatzbereit sind.
Im ersten Axolotl-Feinabstimmungsbeispiel müssen Sie nur einen einzeiligen Befehl ausführen, um ein Llama3.2-Modell feinabzustimmen:
axolotl train examples/llama-3/lora-1b.yml
Der Datensatz für die Feinabstimmung und die Methode werden alle in der YAML-Datei definiert.
2. Modellwahl
Die erste Frage, die wir uns stellten, war, wie groß ein Modell mit 3 GPUs sein kann. Eine NVIDIA RTX 6000 Ada GPU hat 48 GB, also haben wir insgesamt etwa 150 GB.
Unter der Haube wird Accelerate verwendet. Wir müssen jedoch herausfinden, wie groß das Modell ist, das wir auf den verfügbaren GPUs trainieren können. Die Folien von Zachary Mueller bieten eine praktische Formel, um die Speichernutzung anhand der Menge der Modellparameter zu berechnen.
Nehmen Sie zum Beispiel das Modell Llama 3 8B, das 8 Milliarden Parameter hat. Jeder Parameter ist 4 Byte groß, so dass das Modell etwa 8 × 4 GB benötigt. Außerdem benötigt der Rückwärtsdurchlauf 2× die Modellgröße und der Optimierungsschritt 4× die Modellgröße, was bei der Feinabstimmung am meisten Speicherplatz beansprucht.
Sie können dieses Tool zur Schätzung der Modellgröße auch verwenden, um den Speicherverbrauch auf der Grundlage Ihrer eigenen Modellauswahl zu schätzen.
So können wir zum Beispiel ein DeepSeek V2-Modell nicht feinabstimmen, weil die Speichernutzung über 3 TB liegt, wie unten gezeigt:
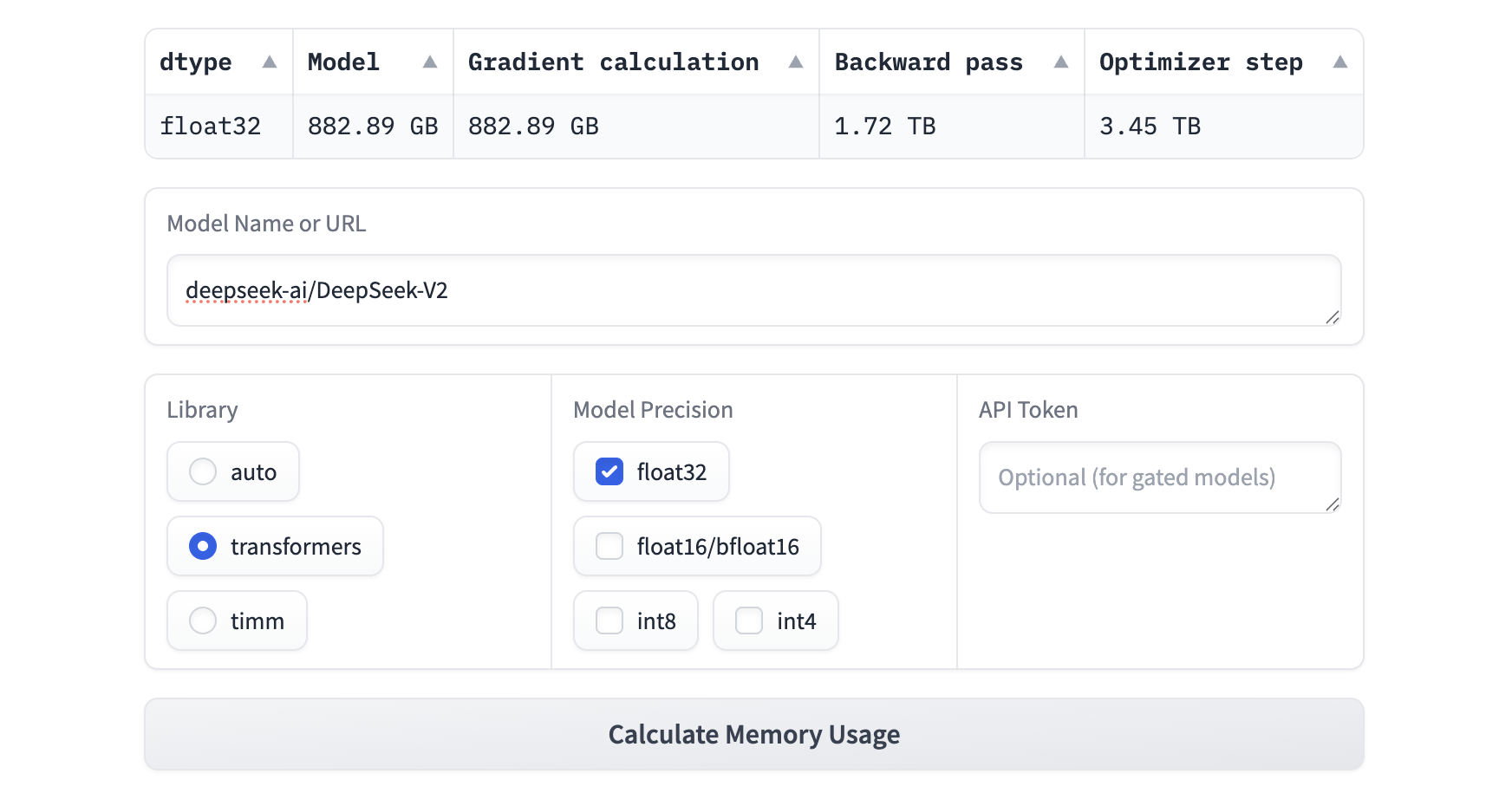
Aufgrund der begrenzten Speicherkapazität wählen wir Gemma-2-2B für die Feinabstimmung und tauchen in die Feinabstimmungstechniken ein.
Der Grund für die Wahl eines Gemma-Modells ist, dass wir ein relativ kleines Modell zur Feinabstimmung für eine bestimmte Aufgabe verwenden wollen, um zu beweisen, dass ein feinabgestimmtes kleineres Modell die größeren Modelle in einem bestimmten Bereich übertreffen kann.
3. Benchmarking-Datensatz: MMLU-Pro
Für den Benchmarking-Datensatz verwenden wir den MMLU-Pro-Datensatz. Er enthält 14 Fragekategorien, die von Mathematik, Physik, Biologie bis hin zu Wirtschaft und Technik reichen. Für jede Frage gibt es 10 Optionen, aus denen Sie für eine richtige Antwort wählen können. Der Datensatz ist in 70 Zeilen für die Validierung und 12.000 Zeilen für den Test aufgeteilt. Der Validierungsdatensatz wird verwendet, um CoT (Chain of Thought) Prompts für den Testdatensatz zu erstellen. Zusammen bilden sie die Prompts für das Benchmarking Ihres Modells.
Das MMLU-Pro Leaderboard zeigt die Benchmarking-Ergebnisse für eine Fülle von Modellen. Zum Beispiel:
Da nur die Gesamtgenauigkeit für Gemma 2- oder 3-Modelle angegeben wird, möchten wir auch die spezifische Genauigkeit für Mathematik wissen.
Das Benchmarking-Skript finden Sie im GitHub-Repository von MMLU-Pro. Wenn wir zum Beispiel ein lokales Modell bewerten wollen, können wir auf dieses Skript verweisen:
modelist<repo>/<model-name>von Hugging Face.selected_subjectskannallfür alle Kategorien odermathfür eine bestimmte Kategorie sein.
python evaluate_from_local.py \
--selected_subjects $selected_subjects \
--save_dir $save_dir \
--model $model \
--global_record_file $global_record_file \
--gpu_util $gpu_util
Wenn wir das obige Skript für --selected_subjects math ausführen, erhalten wir die folgenden Ergebnisse:
Als Nächstes wollen wir ein kleineres Gemma-Modell feinabstimmen, um die Genauigkeit von Berechnungen über 0,107 zu verbessern.
4. Trainingsdatensatz: AceReason-Math
Wir verwenden den NVIDIA AceReason-Math-Datensatz zur Feinabstimmung unseres Modells. Es handelt sich dabei um einen Trainingsdatensatz mit 49,6k Fragen zum mathematischen Denken. Der Datensatz enthält keine Liste von Optionen, sondern nur eine Frage und eine richtige Antwort.
Um dieses Frage/Antwort-Format für die Feinabstimmung eines Modells in Axolotl zu verwenden, müssen wir prüfen, welche Formate für die Anweisungsabstimmung bereitgestellt werden. Dieses Format
datasets:
- path: /data/nvidia_ace_reason_math.parquet
type: alpaca_chat.load_qa
Eine Sache, die Sie beachten sollten, ist, dass wir auch die Spaltennamen des Datensatzes an question und answer anpassen müssen, also benennen wir die ursprüngliche Spalte problem in question um.
5. Feinabstimmungsstrategien: QLoRA, LoRA, FSDP, DeepSpeed
Es gibt viele Techniken und Bibliotheken, die den Feinabstimmungsprozess effizienter machen, viele davon mit dem Schwerpunkt auf Speichereffizienz und Leistung. Dazu gehören vor allem LoRA, QLoRA, FSDP und DeepSpeed. Axolotl unterstützt alle diese Techniken. DeepSpeed oder FSDP können für Multi-GPU-Setups verwendet werden, wobei FSDP mit QLoRA kombiniert werden kann.
Was sind diese Techniken?
- LoRA (Low-Rank Adaptation) is a technique that allows us to fine-tune large models with fewer parameters by introducing low-rank matrices.
LoRA ... [reduces] trainable parameters by about 90%
- https://huggingface.co/learn/llm-course/en/chapter11/4
... das bedeutet, dass wir mehr im Speicher unterbringen und die Feinabstimmung auf Consumer-Hardware einfacher durchführen können. Fantastisch!
-
QLoRA (Quantized LoRA) ist eine Erweiterung von LoRA, die die Modellgewichte quantisiert, um die Speichernutzung weiter zu reduzieren.
-
FSDP (Fully Sharded Data Parallel) ist eine Methode zur Verteilung der Arbeit auf GPUs.
FSDP spart mehr Speicherplatz, da es nicht auf jedem Grafikprozessor ein Modell repliziert. Es verteilt die Modellparameter, Gradienten und Optimierungszustände auf mehrere GPUs. Jeder Modell-Shard verarbeitet einen Teil der Daten und die Ergebnisse werden synchronisiert, um das Training zu beschleunigen. - Vollständig gesplitteteDatenParallel(HuggingFace)
- DeepSpeed ist eine Bibliothek, die Ihnen hilft, verteiltes Training und Inferenz mit Unterstützung von Axolotl durchzuführen.
Kombinationen von LoRA/QLoRA werden als Adapter in der Axolotl-Konfiguration in Kombination mit FSDP für das Finetuning von Gemma2/Llama3.1/Qwen2 auf unseren begrenzten GPU-Ressourcen verwendet ✓. Schauen wir uns nun an, wie man die Feinabstimmung durchführt! 🚀
6. Durchführung der Feinabstimmung 🚀
Axolotl stellt eine Liste von Docker-Images zur Verfügung, die wir sofort verwenden können. Um es zu verwenden, können Sie auf diese Docker-Installation verweisen.
Da unsere GPU-Infrastruktur für die Entwicklung von Argo eingerichtet und verwaltet wird, erstellen wir einen Kubernetes-Job, um den Feinabstimmungsprozess wie unten beschrieben durchzuführen:
apiVersion: batch/v1
kind: Job
metadata:
name: axolotl
spec:
backoffLimit: 0
template:
metadata:
labels:
app: axolotl
spec:
restartPolicy: Never
containers:
- name: axolotl
image: axolotlai/axolotl:main-latest
command: ["/bin/bash", "-c"]
args:
- |
set -e
echo "Start training..."
axolotl train $YAML_FILE --num-processes $NUM_PROCESSES
echo "Merging the LoRA adapters into the base model..."
axolotl merge-lora $YAML_FILE --lora-model-dir=./outputs/out/
echo "Uploading the fine-tuned model to Hugging Face..."
huggingface-cli upload $MODEL_NAME ./outputs/out/merged/ .
securityContext:
privileged: true
runAsUser: 0
capabilities:
add: ["SYS_ADMIN"]
resources:
limits:
nvidia.com/gpu: 1
memory: "40Gi"
requests:
memory: "20Gi"
volumeMounts:
- name: axolotl
mountPath: /workspace/axolotl
- name: huggingface
mountPath: /root/.cache/huggingface
- name: dshm
mountPath: /dev/shm
volumes:
- name: axolotl
persistentVolumeClaim:
claimName: axolotl-pvc
- name: huggingface
persistentVolumeClaim:
claimName: huggingface-pvc
- name: dshm
emptyDir:
medium: Memory
sizeLimit: "10Gi"
Die Variablen stammen aus der in kustomization.yaml definierten config map:
NUM_PROCESSESist die Anzahl der zu verwendenden GPUsYAML_FILEist die YAML-Datei aus den BeispielenMODEL_NAMEist der Name des Modells, das in Hugging Face hochgeladen werden soll.
Ergebnisse
Nach der Feinabstimmung, die etwa 2,8 Stunden dauert, können wir python evaluate_from_local.py verwenden, um das Ergebnis wie folgt zu bewerten:
Im Vergleich zu einem nicht feinabgestimmten Gemma-3-12B-it-Modell, das auf Mathematik basiert, verbessert das feinabgestimmte Modell die Genauigkeit von Mathematik von 0,107 auf 0,238 ✓.
Fazit
In diesem Blogpost erfahren wir: - Was Feinabstimmung ist und warum sie nützlich ist. - Wie wir mit Axolotl ein Modell auf unserer eigenen Hardware feinabstimmen. - Wie man das feinabgestimmte Modell mit MMLU-Pro testet. - Wie man den Feinabstimmungsprozess in einem Kubernetes-Job ausführt.
Wir haben erfolgreich ein Modell feinabgestimmt und es mit MMLU-Pro, Kategorie Mathematik, verglichen. Die Ergebnisse zeigen, dass die Feinabstimmung kleinerer Modelle zu einer konkurrenzfähigen Leistung bei bestimmten Aufgaben führen kann, was die Stärke von domänenspezifischem Wissen in LLMs demonstriert.
Finetuning ist definitiv nicht immer der richtige Ansatz - aber wenn es einer ist, kann er sehr wirkungsvoll sein. Viel Glück bei Ihren eigenen Abenteuern mit dem Feintuning! 🍀
Zitate
Verfasst von

Jeroen Overschie
Machine Learning Engineer
Jeroen is a Machine Learning Engineer at Xebia.
Unsere Ideen
Weitere Blogs




Contact