
Die Spitze des Eisbergs
Wenn wir an Daten denken, denken wir normalerweise an Tabellen, die schön in Zeilen und Spalten strukturiert sind. Aber die weitaus meisten Informationen werden in unstrukturierten Datentypen erfasst. Denken Sie an E-Mails, PDFs, aber auch an Bilder und Videos. Diese Formate wurden so konzipiert, dass die darin enthaltenen Daten von Menschen interpretiert werden können. Das macht es aber auch sehr schwierig, die enthaltenen Informationen für andere Zwecke zu nutzen, z. B. für maschinelles Lernen, die Erstellung von Dashboards und Berichte. Um Erkenntnisse/Wert aus diesen Daten zu gewinnen, müssen wir sie zunächst strukturieren. Aber was verstehen wir unter Strukturierung? Wie verwandeln wir PDFs und Bilder in Zeilen in einer Tabelle?
Zunächst müssen wir festlegen, nach welchen Informationen wir in diesen Dateien suchen möchten. Welche Datenpunkte wollen wir aus ihnen extrahieren? Sind sie kategorisch oder kontinuierlich? Und sind es Zeichenketten, Ganzzahlen, Boolesche Werte oder etwas anderes? Dann brauchen wir einen Mechanismus, der diese Wunschliste aufnimmt und die Elemente aus der Datei extrahiert. Aus technischer Sicht ist dies der schwierigste Teil. Für jede Modalität (ein schickes Wort für die Art der Daten, d.h. Bild/Text/Video) wird der Mechanismus sehr unterschiedlich sein. Für Textformate sind große Sprachmodelle ein geeigneter Kandidat, um diese Aufgabe zu übernehmen. Aber es gibt auch weniger komplexe und kostengünstige Alternativen, die genauso gut funktionieren könnten, je nachdem, wie ehrgeizig Ihre Wunschliste ist.
Beispiel
Schauen wir uns ein Beispiel an, das uns sehr nahe geht: ein Datenberatungsunternehmen. Die Vertriebsmitarbeiter verwenden CRM-Software, um den Verkaufsprozess zu verfolgen. Aus diesen Geschäften lassen sich viele interessante Informationen ableiten. Welche technischen Funktionen werden für das Projekt benötigt? Sind bestimmte Technologien im Moment besonders gefragt? Wie sieht es mit den Vollzeitäquivalenten und dem Zeitplan des Projekts aus? Die Beantwortung dieser Fragen kann helfen, datengestützte Entscheidungen über die Einstellungsstrategie, Schulungsprogramme und vielleicht sogar den Verkaufsprozess selbst zu treffen.
Nehmen wir an, wir können ein Geschäft in eine PDF-Datei exportieren. Die PDF-Datei enthält die folgenden Informationen:
Name: Project W
Company: Umbrella Corporation
Activities:
2025-01-01: Call with the leadership team at Umbrella Corporation to discuss project requirements. Every fall, they experience an unexplainable surge in demand for their storm-proof umbrellas. To manage stock levels, they would like to build a model that can forecast the demand for this product.
2025-01-15: Follow-up meeting with the data science lead to discuss the project proposal. The project will require a data scientist and a machine learning engineer on a full-time basis. The development is expected to take 6 months, just in time for the next fall season. The project will start on 2025-02-01.
Wir würden gerne die folgenden Informationen extrahieren: - Firmenname - Anwendungsfall - FTE - Startdatum - Projektanpassung
Der Grund, warum die oben genannten fünf Felder extrahiert werden, ist, dass wir für ein Datenberatungsunternehmen wissen möchten, welcher Anwendungsfall für welches Unternehmen ist, wie viele Mitarbeiter ab welchem Startdatum benötigt werden und ob dieses Projekt gut passt.
Als englischsprachiger Mensch erhalten Sie den folgenden Auszug: - Firmenname: Umbrella Corporation - Anwendungsfall: Nachfrageprognose - FTE: 2 - Startdatum: 2025-02-01 - Projektanpassung: Hoch
Einfach genug, oder? Sicher, der Firmenname scheint einfach zu sein, denn vor ihm steht das Wort 'Company' und sein Wert steht direkt danach. Die anderen sind etwas komplizierter und erfordern ein gewisses Verständnis des Kontexts. Wir werden das später noch genauer untersuchen.
Wenn wir dies für alle Geschäfte in unserem CRM tun, können wir eine Tabelle erstellen. Jede Zeile steht für ein Geschäft, und wir werden fünf Spalten haben: Firmenname, Anwendungsfall, FTE, Startdatum und Projektanpassung. Diese Tabelle kann dann die Grundlage für weitere Analysen bilden. Wir können zum Beispiel die Anzahl der Geschäfte pro Anwendungsfall im vergangenen Jahr zählen oder die durchschnittliche FTE pro Geschäft berechnen.
Terminologie
Bevor wir in die Details eintauchen, lassen Sie uns einige Begriffe definieren, die wir in diesem und den folgenden Blogposts zu diesem Thema verwenden werden.
- Quelle: Die unstrukturierten Daten, aus denen wir Informationen extrahieren möchten. Das kann eine PDF-Datei, ein Bild, ein Video usw. sein. In dem obigen Beispiel ist die Quelle die PDF-Datei.
- Extraktor: Der Mechanismus, der Informationen aus der Quelle extrahiert. In dem obigen Beispiel waren Sie, der menschliche Leser, der Extraktor.
- Extraktion: Der kombinierte Satz von Informationen, der aus einer einzigen Quelle extrahiert wurde. Sie entspricht einer Zeile in der Tabelle, die wir bereits erwähnt haben.
- Beweismittel: Der Teil der Quelle, der die Informationen enthält, die wir extrahieren möchten. Dies kann ein Satz, ein Absatz, ein Begrenzungsrahmen in einem Bild usw. sein.
Drei Stufen der Extraktion
Auf dem Spektrum von leicht bis schwer gibt es drei Stufen der Extraktion: 1. Genaue Übereinstimmung: Die Antwort ist buchstäblich im Kontext vorhanden. 2. Deduktion: Die Antwort muss aus dem Kontext abgeleitet werden. 3. Begründen: Die Antwort muss auf der Grundlage des Kontexts begründet werden.
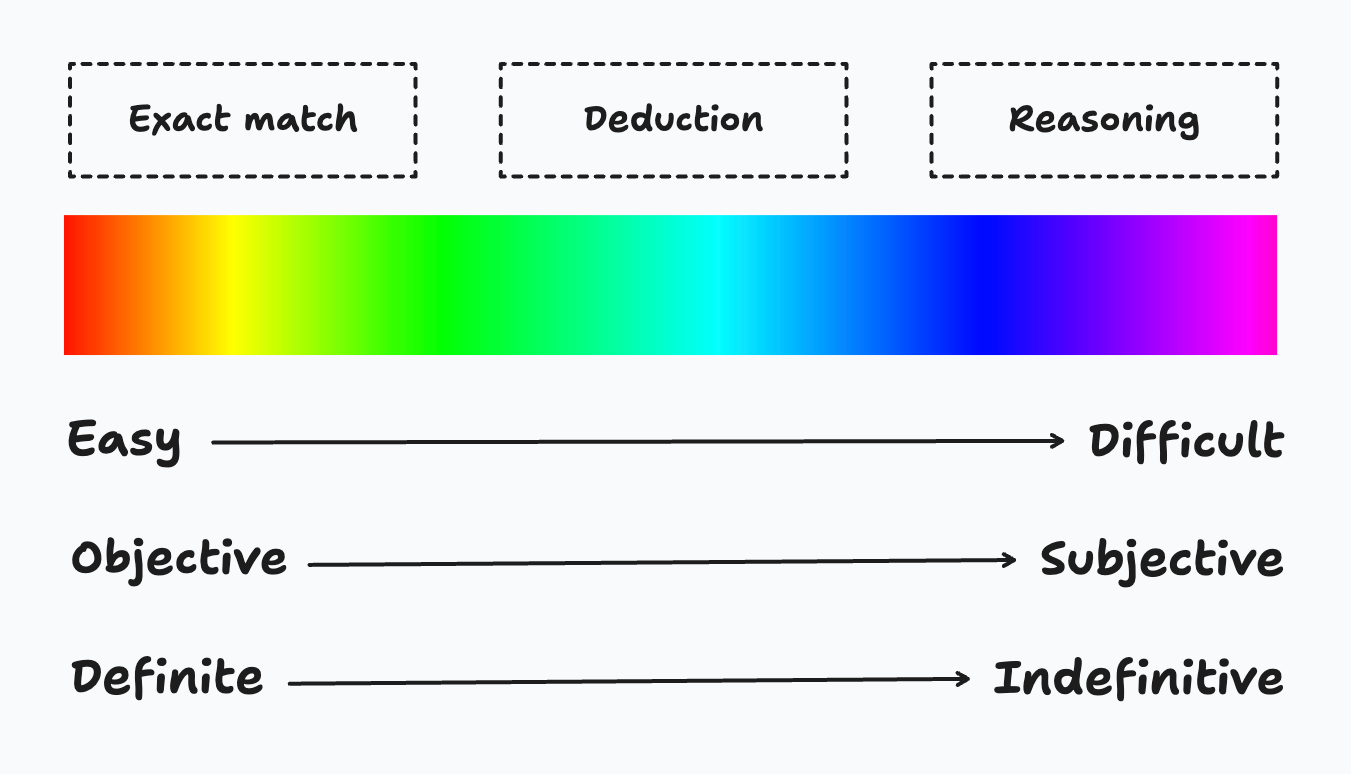
Je schwieriger es ist, die Antwort zu extrahieren, desto subjektiver und unbestimmter wird die Antwort, um ihre Genauigkeit zu bewerten.
Schauen wir uns an, wie das vorherige Beispiel in die drei oben genannten Kategorien fällt. - Firmenname: Genaue Übereinstimmung -> Der Name kommt direkt nach "Firma:". - Anwendungsfall: Abzug -> In der Quelle heißt es, dass "sie ein Modell erstellen möchten, das die Nachfrage vorhersagen kann". - FTE: Abzug -> Es werden ein Data Scientist und ein Machine Learning Engineer in Vollzeit benötigt. In der Summe sind es also zwei. - Startdatum: Abzug -> In der Quelle sind mehrere Daten angegeben: "2025-01-01", "2025-01-15" und "2025-02-01". Nur "2025-02-01" ist das Startdatum des Projekts. - Projekt passt:
Werkzeugbau
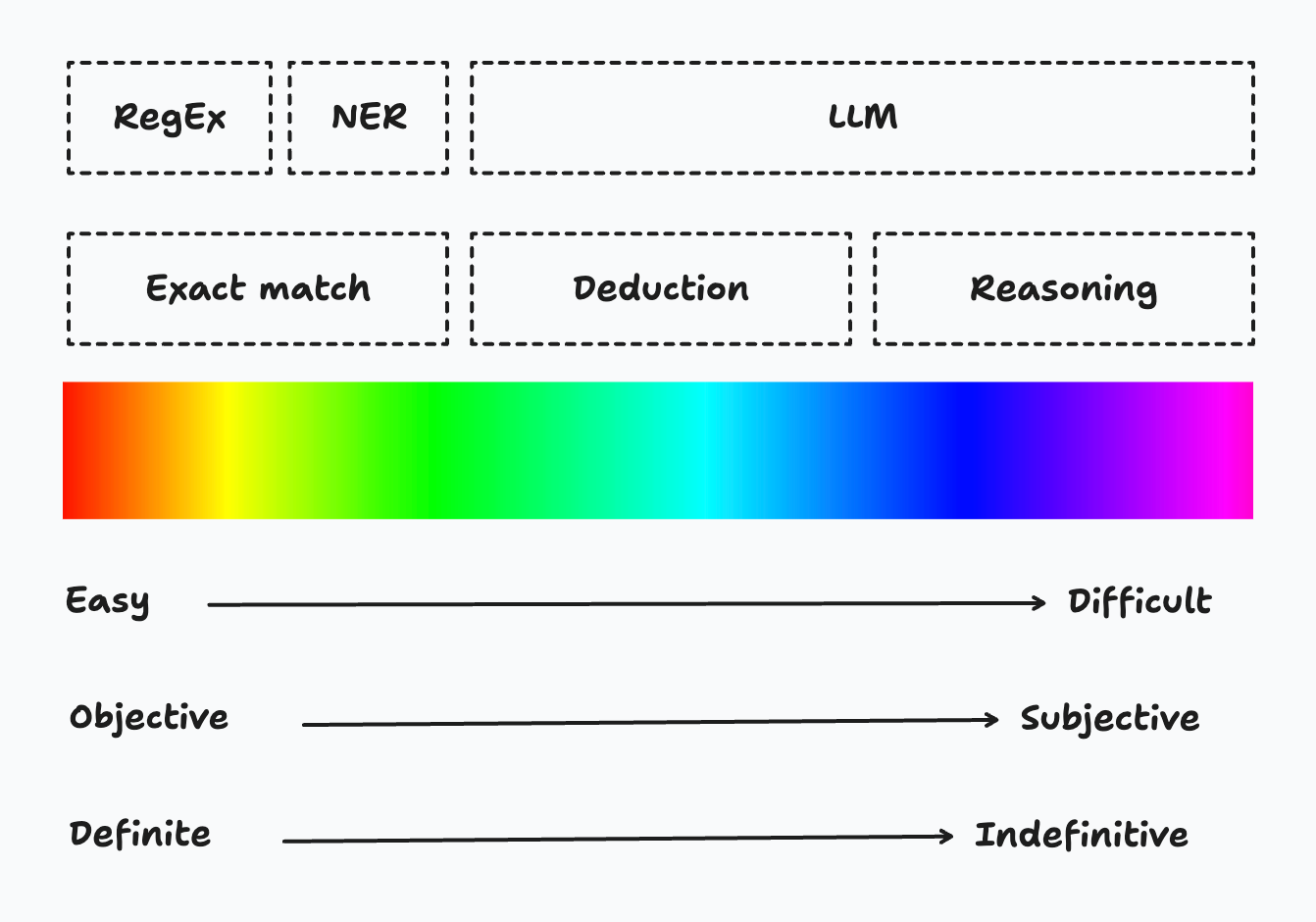
Das Problem der Extraktion ist nicht neu für uns, wir gehen es immer wieder mit verschiedenen Methoden an. Zu den alten und neuen Tools im Arsenal der Extraktionsmethoden gehören der einfache reguläre Ausdruck (RegEx), die Erkennung von benannten Entitäten (NER) und das Large Language Model (LLM).
Kehren wir zu unserem vorherigen Beispiel zurück, um zu sehen, welches Tool für die Extraktion welcher Informationen verwendet werden kann. - Firmenname: NER -> "Firmenname" ist die benannte Entität, die extrahiert werden soll. - Anwendungsfall: LLM -> NER-Modelle können trainiert werden, um Anwendungsfälle zu extrahieren, aber hier wird eine Zusammenfassung eines langen Textes benötigt. - FTE:
Um diese drei Werkzeuge den drei Ebenen der Extraktion zuzuordnen, sieht es nun so aus!
Schauen wir uns die Vor- und Nachteile dieser drei Tools im Detail an.
| Werkzeug | Pro | Nachteile |
|---|---|---|
| RegEx |
|
|
| NER |
|
|
| LLM |
|
|
Vorhandene Tools
Es gibt bereits einige gebrauchsfertige Implementierungen der oben genannten Tools.
Instructor ist eine Open-Source-Python-Bibliothek, die fast alle Modelle Ihrer Wahl verwenden kann, von OpenAI GPT-Modellen über Google Gemini-Modelle bis hin zu Open-Source-Modellen wie Mistral/Mixtral, Ollama, um strukturierte Daten zu erhalten. Sie können Instructor verwenden, um Ihre eigene Datenpipeline zu erstellen.
Trellis AI ist ein SaaS-Produkt, das strukturierte Daten aus Dokumenten extrahieren kann, darunter PDFs, XLSX, Bilder, Folien und DOCX. Es unterstützt die Integration von Datenquellen und -zielen, z.B. den Aufbau einer Datenpipeline von S3 zu PostgreSQL.
Databricks ai_extract Funktion ist in Databricks Notebooks und SQL-Abfragen verfügbar und nutzt ein großes Sprachmodell (LLM), um die Datenextraktion zu erleichtern. Mit dieser Funktion können Benutzer nur die Namen der zu extrahierenden Felder angeben, ohne dass zusätzliche Konfigurationsoptionen für den Extraktionsprozess verfügbar sind.
Aber was kommt als nächstes, nachdem die Daten extrahiert, strukturiert und gespeichert wurden? Ein entscheidender Punkt ist die Bewertung. Von einer Vielzahl von Modelloptionen und Konfigurationen müssen wir wissen, wie gut sie funktionieren.
Was kommt als nächstes?
Im nächsten Artikel werden wir uns eingehend mit der Bewertung befassen. Was ist Evaluierung? Warum ist eine Bewertung notwendig? Wie können wir LLM-Extraktionen bewerten?
Verfasst von
Shu Zhao




Contact