Event Sourcing ist ein Entwurfsmuster, bei dem Änderungen am Zustand einer Anwendung als Abfolge von Ereignissen gespeichert und in einem Ereignisspeicher abgelegt werden. Durch die Ausführung dieser Ereignisse können wir später den aktuellen oder vorherigen Zustand der Anwendung wiederherstellen. Wir führen keine Aktualisierungs- oder Löschoperationen an den Daten durch. Sehen wir uns ein typisches Event-Sourcing-Design an. Ein typisches Event-Sourcing-Modell besteht aus einer Lese-/Schreib-API.
Die Schreib-API schreibt nicht in die Datenbank, sondern erstellt Ereignisse und speichert sie in einem Ereignisspeicher, während die Lese-API aus demselben Ereignisspeicher liest und den aktuellen Zustand durch die Ausführung der Ereignisse erzeugt. Event Sourcing ermöglicht den schrittweisen Ausbau der Anwendungsarchitektur durch Hinzufügen neuer Leseanwendungen, die dieselben Ereignisse aus dem Ereignisspeicher verarbeiten und in verschiedenen Ansichten anzeigen.
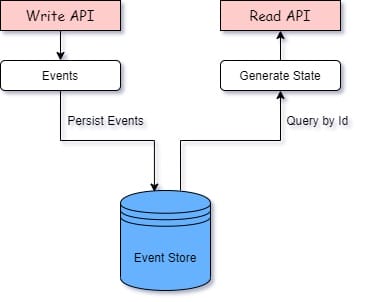 Betrachten wir das folgende Beispiel:
Betrachten wir das folgende Beispiel:
Es gibt eine Person, die zu einer Bank geht, ihr Konto eröffnet und über einige Monate hinweg einige Einzahlungen und Abhebungen tätigt.
Bei einem traditionellen datenzentrierten Ansatz hätte das Design aus einigen wenigen Datenbanktabellen bestanden & wir aktualisieren die Tabellen jedes Mal, wenn eine Einzahlung oder Abhebung vorgenommen wird. Beim Event Sourcing führen wir jedoch keine Operationen an den Daten durch, sondern erstellen ein Aggregat, indem wir jede Operation als eine Folge von Ereignissen in einem Ereignisspeicher wie Cassandra oder Mongo DB speichern. Wir können den aktuellen Status erstellen und haben eine vollständige Historie der Person. Hier sind die Namen der Ereignisse Verben, wie sie in der Vergangenheit passiert sind, und im Allgemeinen leiten wir den Namen von dem Bereich ab, in dem wir arbeiten.
Nachfolgend sehen Sie die Abfolge der Ereignisse, die im Ereignisspeicher für das Bankbeispiel gespeichert sind:
| KontoErstellt | 435266 | Test Name | 10-10-2019 13:59:10.0 | ||
| DepositPerformed | 435266 | $300 | 02-01-2020 11:02:13.0 | ||
| WithDrawalPerformed | 435266 | $250 | 09-01-2020 13:05:25.0 |
| KontoErstellt | 435266 | Test Name | 10-10-2019 13:59:10.0 | ||
| DepositPerformed | 435266 | $300 | 02-01-2020 11:02:13.0 | ||
| WithDrawalPerformed | 435266 | $250 | 09-01-2020 13:05:25.0 | ||
| WithDrawalFailed | 435266 | $1000 | Unzureichende Mittel | 14-01-2020 10:00:21.0 |
| KontoErstellt | 435266 | Test Name | 10-10-2019 13:59:10.0 | ||
| DepositPerformed | 435266 | $300 | 02-01-2020 11:02:13.0 | ||
| WithDrawalPerformed | 435266 | $250 | 09-01-2020 13:05:25.0 | ||
| WithDrawalFailed | 435266 | $1000 | Unzureichende Mittel | 14-01-2020 10:00:21.0 | |
| DepositPerformed | 435266 | $1200 | 10-02-2020 15:00:39.0 |
Dies ist unser Ereignisspeicher, der über einen bestimmten Zeitraum wächst, indem er alle Änderungen als Ereignisse speichert. Die Leseseite kann diesen Speicher abfragen und den neuesten Stand konstruieren.
Command Query Responsibility Segregation (CQRS) ist ein Entwurfsmuster, bei dem die Verantwortung für das Lesen und Schreiben auf zwei verschiedene Modelle in der Anwendung aufgeteilt wird. Die Anwendung wird in zwei Teile aufgeteilt: die Befehlsseite, die dem System befiehlt, Schreibvorgänge durchzuführen, und die Abfrageseite , die den gespeicherten Status abfragt. Außerdem sorgt es für eine Trennung der Belange, da Command & Query sich nicht darum kümmern, was ein anderes Modell tut. Ein Event-Handler kümmert sich um die Veröffentlichung von Ereignissen auf der Leseseite von der Schreibseite aus. Apache Kafka ist ein beliebter Messaging-Dienst, der CQRS sehr effektiv implementiert.
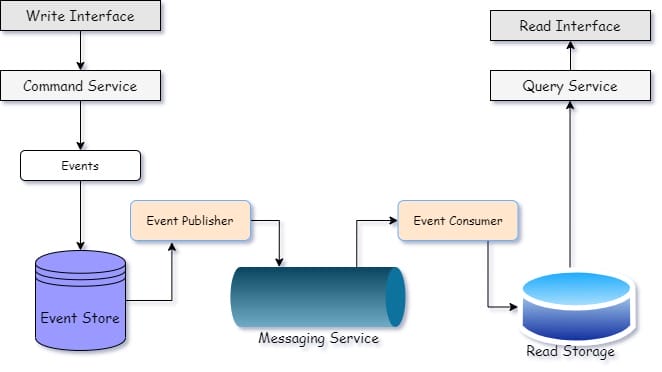 Warum CQRS??
Warum CQRS??
Wie wir wissen, bietet CQRS eine Trennung der Belange. Die Befehls-/Schreibseite kümmert sich um die Geschäftslogik, unabhängig vom Abfragemodell, und das Abfragemodell ist dafür verantwortlich, wie schnell es gespeicherte Daten abrufen kann, sowie für die Optimierung, unabhängig vom Schreibmodell.
Die Last wird zwischen den beiden Modellen aufgeteilt und die Schreib- und Leseseite kann je nach Bedarf individuell skaliert werden. Die Anwendung kann ein einzelnes Schreib- und mehrere Lesemodelle enthalten und jedes Lesemodell kann dieselben Ereignisse verarbeiten und sie in verschiedenen Ansichten anzeigen.
Während des Upgrades können wir ein neues Modell auf der Leseseite hinzufügen, ohne dass es zu Ausfallzeiten kommt, und wir können im Falle eines Fehlers einfach zu einem früheren Zustand zurückkehren und diesen schnell wiederherstellen. Dies macht die Anwendung stabil, belastbar und leistungsfähiger.
CQRS und Event Sourcing werden in der Regel zusammen mit Kafka verwendet.
Vor- und Nachteile von Event Sourcing & CQRS
Vorteile:
- Lose gekoppelte Architektur, Upgrades sind einfach und leicht
- Ausfallsicheres & skalierbares Design
- Last wird zwischen Lese- und Schreibseite verteilt
- Je nach Bedarf können einzelne Modelle skaliert werden
- Die Geschichte der Ereignisse, wie sie geschehen, wird aufgezeichnet
- Im Falle eines Systemabsturzes kann der Anwendungsstatus durch die Ausführung von Ereignissen aus dem Ereignisspeicher leicht wiederhergestellt werden.
Nachteile:
- Dies ist eine andere Art der Programmierung als die herkömmliche und die Entwickler werden einige Zeit brauchen, um sich anzupassen.
- Es entstehen Wartungskosten, da wir verschiedene Datenbanken für Schreib- und Lesemodelle benötigen.
- Die Implementierung kann komplex werden, wenn die Modelle nicht richtig konzipiert sind.
Fazit
Event Sourcing mit CQRS ermöglicht es Anwendungen, ihren Zustand in Form von Ereignissen in Ereignisspeichern zu speichern. Mit diesem Architekturmuster sind Anwendungen lose gekoppelt, belastbar und es besteht nur ein minimales Risiko von Ausfallzeiten, und sie können nach Bedarf skaliert werden. Eine einfache CQRS-Implementierung kann zwar gute Ergebnisse liefern, ohne die Komplexität zu erhöhen, aber wenn sie nicht richtig konzipiert ist, kann sie auch zu einer erhöhten Komplexität und zu unwartbarem Code führen. Kafka ist kein Muss für Event Sourcing oder CQRS, auch wenn die Entwürfe, die Kafka verwenden, dessen Hauptvorteile wie Leistung, Zuverlässigkeit und Null-Fehler-Toleranz nutzen können.
Verfasst von
Atul Kumar Singh
Lead Engineer at coMakeIT




Contact