Blog
Geschäfte machen, die Bayes'sche Methode (Teil 2)

Teil 2: Von einer Bayes'schen Lösung zu Geschäftseinblicken
In Teil 1 dieser Serie haben wir uns mit einigen der Grundprinzipien der Bayes'schen Modellierung vertraut gemacht. Außerdem haben wir ein anschauliches Geschäftsproblem kennengelernt: Es geht darum, dem B2B-Dienstleister Virtuoso zu helfen, seine regionalen Kunden und deren Preissensibilität besser zu verstehen und möglicherweise bessere Preisstrategien für jeden Markt zu finden. Falls Sie Teil 1 noch nicht gelesen haben, empfehlen wir Ihnen, dies zu tun, denn hier werden wir mit dem Aufbau eines Bayes'schen Rahmens fortfahren, der zuvor definiert wurde. Dieser Teil wird eher technischer Natur sein. Wenn Sie sich also zumindest auf konzeptioneller Ebene mit (Bayes'scher) Statistik vertraut gemacht haben, wird er Ihnen leichter zugänglich sein. Alle Daten sowie alle weiteren Analysen, Diagramme und Modelle sind in diesem GitHub-Repository verfügbar.
Modellbau mit PyMC3
Wie in Teil 1 erläutert, besteht unser Ziel darin, die Posterior-Verteilungen für die Parameter der Preissensitivität in jedem regionalen Markt zu ermitteln. Dabei stützen wir uns auf weitgehend uninformierte Preisempfindlichkeitsprioritäten. Mit Hilfe unseres Fachwissens werden wir diese Prioritäten so einschränken, dass sie immer negativ sind, da die Kaufwahrscheinlichkeit mit steigendem Preis abnehmen sollte. Schließlich verwenden wir die Bernoulli-Likelihood-Funktion, um das Eingabedatum (Preise) mit dem Ergebnis (Kauf oder Nichtkauf) abzugleichen.
Aber wie kann man all dies in einem brauchbaren Modell und Python-Code zusammenfassen? Um das zu erreichen, verwenden wir das Python-Paket PyMC3. Es scheint schwieriger zu erlernen zu sein als die üblichen "fit-predict"-Bibliotheken wie scikit-learn, aber es ermöglicht die Konstruktion von hochgradig anpassbaren probabilistischen Modellen. Der folgende Code setzt unsere vorherige Intuition in ein optimierungsfähiges Bayes'sches Framework um:
with pm.Model() as pooled_model:
# define b0 and b1 priors
b0 = pm.Normal('b0', mu=0, sd=100)
b1 = pm.Lognormal('b1', mu=0, sd=100)
# compute the purchase probability for each case
logit_p = b0 - b1 * X_train['price']
likelihood = pm.Bernoulli('likelihood', logit_p=logit_p, observed=y_train)
posterior = pm.sample(draws = 6000, tune = 3000)PyMC3 verstehen
Hier geht es um eine Modelldefinition innerhalb eines Kontextmanagers. Wir definieren ein allgemeines PyMC3-Modell und nennen es pooled_model (da wir zunächst alle Länder zusammen betrachten). Dann beginnen wir mit der Definition der Modellparameter, einen nach dem anderen. Eine Bernoulli-Wahrscheinlichkeit erfordert einen Satz realer Beobachtungen
Das Interessante dabei ist, dass wir offen zugeben, dass wir nicht genau wissen, was b0 und b1 sind. Sie brauchen keine schwierigen Annahmen zu treffen! Wir haben nur eine grobe Vorstellung von den Parametern: b0 kann alles sein, was aus einer allgemeinen Normalverteilung mit einem Mittelwert von 0 und einem Standardwert von 100 stammt. Er liegt also höchstwahrscheinlich bei Null, kann aber auch weiter davon entfernt sein. Zweitens ist b1 positiv (höhere Preise verringern die Chancen, dass ein Angebot angenommen wird) und liegt irgendwo in der Nähe von [0; 100]. Die gute Nachricht ist, dass uns die Bayes-Formel zu den realistischeren Parameterwerten korrigiert, wenn wir uns in diesem Punkt irren (erinnern Sie sich, wie die Bayes'sche Aktualisierung aus Teil 1 funktioniert?). Dies macht die Bayes'sche Modellierung nicht nur sehr flexibel, sondern auch sehr transparent und zu einem risikoärmeren Ansatz. Wenn wir außerdem über Fachwissen verfügen, können wir es auch hier einfließen lassen. Wenn wir zum Beispiel wüssten, dass es eine gesetzliche Obergrenze für die Preisfestsetzung gibt, könnten wir diese nutzen, um unsere Parameterdefinitionen weiter einzuschränken.
Gepooltes Bayes'sches Modell
Alles zusammengenommen; dieses gepoolte Modell sagt uns, wie die Wahrscheinlichkeit der Angebotsannahme mit den verschiedenen Preisniveaus in allen Ländern zusammenhängt. Alles, was wir tun müssen, ist, einen der (Stichproben-)Algorithmen von PyMC3 anzuwenden, die sich um die Anwendung der Bayes-Formel auf unser Problem und die Erstellung der Posterior-Verteilung kümmern. Um diesen Teil für alle zugänglicher zu machen, werden wir nicht näher darauf eingehen, wie diese Algorithmen genau funktionieren, aber wir empfehlen Ihnen, sich separat über den berühmten Markov-Chain-Monte-Carlo-Algorithmus (MCMC) zu informieren. Was wir wissen müssen, ist, dass PyMC3 automatisch eine Verteilung generiert, die nachweislich ohne Verzerrungen zur realen posterioren Verteilung konvergiert, vorausgesetzt, es werden genügend Proben genommen. Wenn etwas schief geht, z.B. wenn nicht genügend Stichproben genommen wurden, gibt PyMC3 Feedback und Vorschläge, wie Sie Ihr Skript verbessern können. Was den Code betrifft, so beschaffen wir uns die Stichproben für diese generierte Verteilung mit der letzten Zeile in der vorherigen Codesequenz und hier ist das Ergebnis:
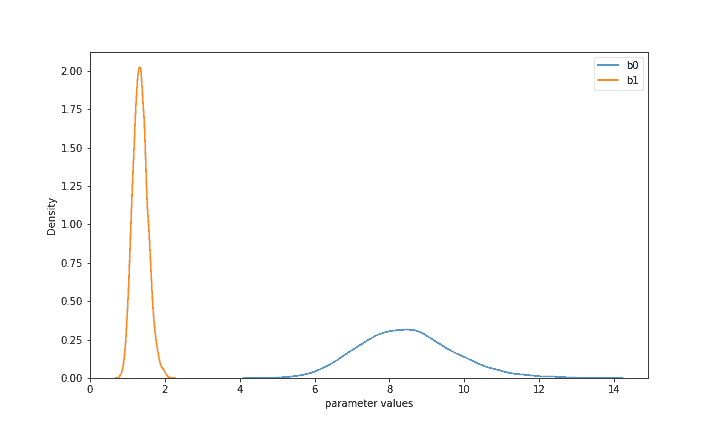
Auf der Grundlage der gelieferten Daten wurden unsere Prioritätsverteilungen von b0 und b1 erheblich aktualisiert. Die beiden Verteilungen geben nun an, welche Parameter angesichts Ihrer Prioritäten und der beobachteten realen Daten am wahrscheinlichsten sind. Jetzt liegt b1 (Preisempfindlichkeit) mit hoher Wahrscheinlichkeit in allen Ländern zusammen zwischen 1 und 2, während b0 zwischen 6 und 11 liegt. Dies ermöglicht uns einige Schlussfolgerungen und impliziert bereits ein wertvolles Ergebnis: Es scheint sehr unwahrscheinlich, dass die Kunden von Virtuoso Preise über 13 akzeptieren, während Preise unter 10 eine mindestens 50%ige Chance haben, akzeptiert zu werden. Im Gegensatz zu anderen Modellierungsansätzen liefert die Bayes'sche Modellierung ganze Verteilungen der Akzeptanzwahrscheinlichkeiten für verschiedene Preise, die es uns ermöglichen, die Unsicherheit bei schwierigen Entscheidungen direkt zu berücksichtigen.
Wir können dieses Modell auch direkt für herkömmliche Prognosen verwenden und seine Genauigkeit (und andere Metriken) schätzen. Wir haben den gesamten Datensatz zuvor in einen 2:1-Train-Test-Split aufgeteilt, und nur die Trainingsdaten wurden an PyMC3 übergeben. Jetzt können wir direkt auf alle verfügbaren Posterior-Werte dieses Modells zugreifen (über die Variable 'posterior'), um weitere Vorhersagen für verschiedene Preise zu treffen. PyMC3 verfügt zwar über eingebaute Methoden, um dies zu tun, aber es ist anschaulicher, die Wahrscheinlichkeiten selbst zu rekonstruieren. Wenn wir eine Punktschätzung wünschen, können wir eine einzelne Eigenschaft jeder Posterior-Verteilung ableiten, z. B. den Mittelwert. Wie in Abbildung 1 zu sehen ist, liegt der Mittelwert von b0 bei 8,5 und von b1 bei 1,3. Bei einem Preis von 5 würde dies folglich zu logit(8,5 - 1,3 5) = 0,85 führen. wobei logit die Standard-Logit-Funktion ist. Mit anderen Worten, ein Preis von 5 bedeutet, dass die Chance, in jedem Land angenommen zu werden, im Durchschnitt 85% beträgt. Auf ähnliche Weise können wir die Wahrscheinlichkeiten für jedes der X_test-Preise, konvertieren Sie sie in 1 oder 0 (z.B. auf der Grundlage einer Standardschwelle von 0,5) und vergleichen Sie sie mit den realen y_test Werte. Infolgedessen ist diese Das gepoolte Bayes'sche Modell* hat eine Genauigkeit von 85,4% und einen gewichteten f1-Score von 85%, der noch verbessert werden kann, wenn wir Aspekte wie die gewählte Wahrscheinlichkeitsschwelle oder die Posterior-Statistiken ändern (z.B. einen Quantilwert wie den Median statt des Mittelwerts verwenden).
Ein hierarchischer Rahmen
Wir können das sogar noch besser machen. Bislang haben wir alle Länderdaten zusammengefasst und uns darauf beschränkt, nur die "durchschnittliche Wahrheit" zu lernen. Aber die Bayes'sche Modellierung glänzt vor allem dann, wenn wir sie mehrere unterschiedliche, aber verwandte Probleme zusammen behandeln lassen. Wir gehen davon aus, dass es eine gewisse Hierarchie und eine gemeinsame Logik darin gibt, wie die Menschen in den verschiedenen Ländern auf unsere Preise reagieren. Diese Reaktionen sind wahrscheinlich ähnlich und doch etwas unterschiedlich. Wir können diese Idee in unser Bayes'sches Modell einbeziehen, indem wir annehmen, dass unsere drei Länder unterschiedliche b0 und b1 haben, die dadurch zusammenhängen, dass sie durch gemeinsame Verteilungen erzeugt werden. Das mag kompliziert klingen, aber betrachten Sie das folgende vereinfachte Beispiel:
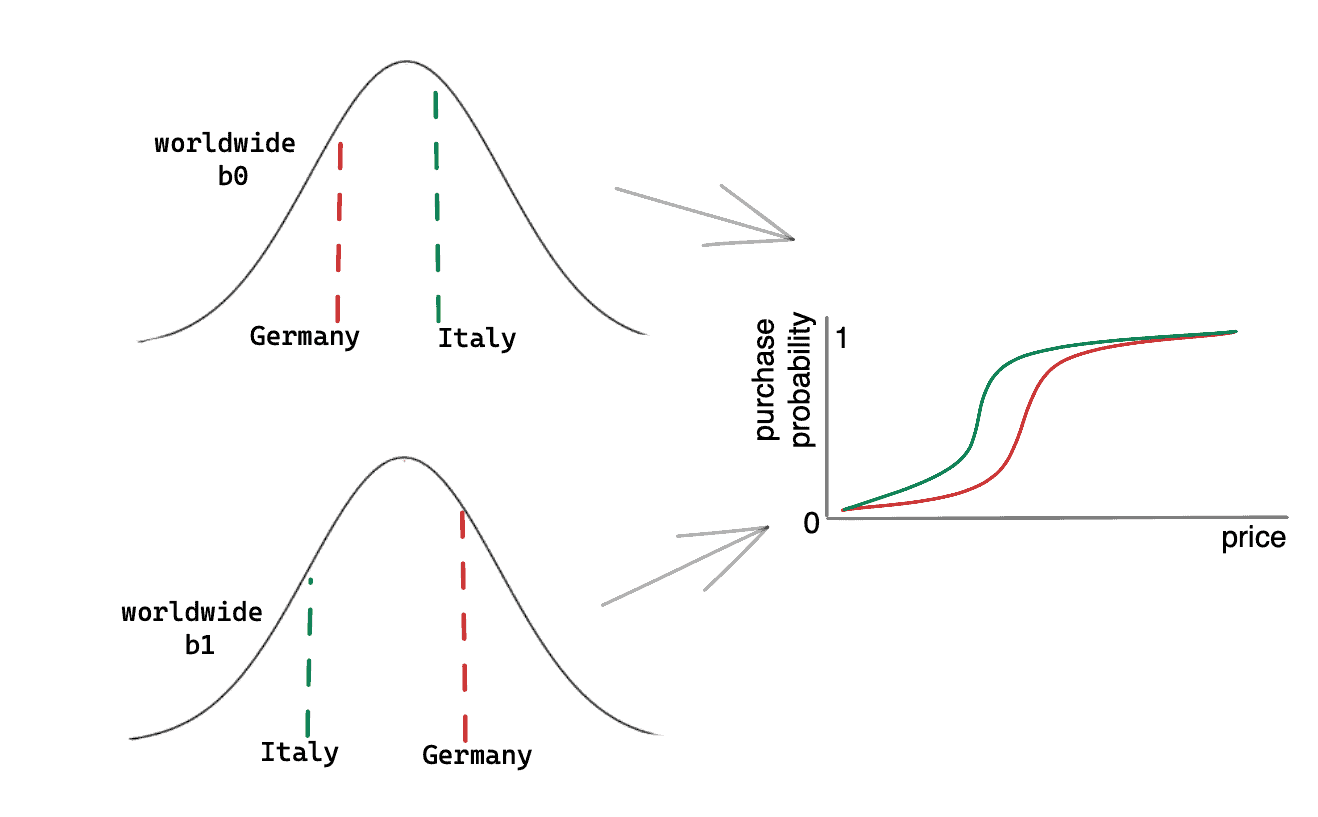
In diesem Beispiel gibt es nur Deutschland und Italien. Beide haben unterschiedliche Wahrscheinlichkeiten, zu jedem Preis zu kaufen, wie die logistischen Kurven in der Grafik ganz rechts zeigen. Wir haben bereits gesehen, dass wir für jede dieser Kurven zwei Parameter benötigen: b0 und b1. Hier sind sie für jedes Land unterschiedlich, aber sie stammen aus gemeinsamen Verteilungen (links). Das ist in etwa so, als würde man sagen, dass es in den Ländern weltweit unterschiedliche Preisempfindlichkeiten gibt, die wie in der Grafik unten links verteilt sind. Deutschland und Italien mögen unterschiedliche Parameter haben, aber diese Parameter haben einen gemeinsamen Ursprung.
Sie fragen sich vielleicht, woher wir diese gemeinsamen weltweiten Verteilungen kennen. Tatsächlich wissen wir das nicht. Aber wir können bestimmen, wie sie aussehen könnten, wenn wir das Bayes'sche Problem als Ganzes lösen! Wenn wir Daten aus mehreren Ländern haben, können wir etwas über das Problem als Ganzes lernen. Dies kann uns später auch Aufschluss über die Länder geben, die wir bisher noch gar nicht gesehen haben oder über die wir nur sehr wenige Daten haben.
Mit diesem hierarchischen Rahmen müssen wir also nicht davon ausgehen, dass Italien, Deutschland und Frankreich gleich sind, aber wir gehen auch nicht davon aus, dass sie nichts gemeinsam haben. Infolgedessen lernen solche Modelle die Unterschiede und erkennen gleichzeitig die in den Daten vorhandenen Ähnlichkeiten an. Dies stellt einen wertvollen Mittelweg dar, den andere Modellierungsansätze nur selten bieten können. Was den Code betrifft, so hat unser erweitertes Modell diese Form:
with pm.Model() as hier_model:
# priors for common distribution's mu and sigma
mu_b0 = pm.Normal('mu_b0', mu=0, sd=100)
mu_b1 = pm.Normal('mu_b1', mu=0, sd=100)
sigma_b0 = pm.InverseGamma('sigma_b0', alpha=3, beta=20)
sigma_b1 = pm.InverseGamma('sigma_b1', alpha=3, beta=20)
# country-specific draws
b0 = pm.Normal('b0', mu=mu_b0, sd=sigma_b0, shape=n_countries)
b1 = pm.Lognormal('b1', mu=mu_b1, sd=sigma_b1, shape=n_countries)
# compute the purchase probability for each case
logit_p = b0[ids_train] - b1[ids_train] * X_train['price']
likelihood = pm.Bernoulli('likelihood', logit_p=logit_p, observed=y_train)
posterior = pm.sample(draws = 10000, tune = 5000, target_accept = 0.9)Dieses Modell sieht vielleicht komplizierter aus, aber es basiert auf einer Idee, die dem vorherigen gepoolten Modell sehr ähnlich ist. Auch hier kombiniert die Bernoulli-Likelihood die beobachteten Daten von y_train mit den logistischen Wahrscheinlichkeiten, die b0 und b1 (diesmal für jedes Land unterschiedlich, aber miteinander verbunden) kombinieren. Jedes b0 und b1 stammt immer noch aus der gleichen Art von Vorabverteilungen wie zuvor, aber jetzt nicht mehr aus festen, sondern aus "flexiblen" Verteilungen mit unbekannten mu und std. Diese mu und std haben alle ihre eigenen Prioritäten, wie bereits in Abbildung 2 dargestellt. Diese neuen zusätzlichen Prioritäten sind sehr allgemein (uninformiert), da wir keine gute Vorstellung davon haben, wie mu und std weltweit verteilt sind. Eine Normalverteilung um Null mit einem großen std ist in diesem Fall eine übliche Wahl. Schließlich müssen wir jedem Land einen Index zuweisen und ihn in die Wahrscheinlichkeitsdefinitionen einfügen, damit PyMC3 die richtigen Betas für jedes Land verwendet. Diese Variable ids_train muss die gleiche Reihenfolge der Länder haben wie die Preise in X_train.
Jetzt sind wir wieder bereit, mit Hilfe von MCMC Stichproben für die posteriore Verteilung zu erzeugen. Wenn dies gelingt, können wir die für jedes Land erzeugten eindeutigen Parameterverteilungen untersuchen:
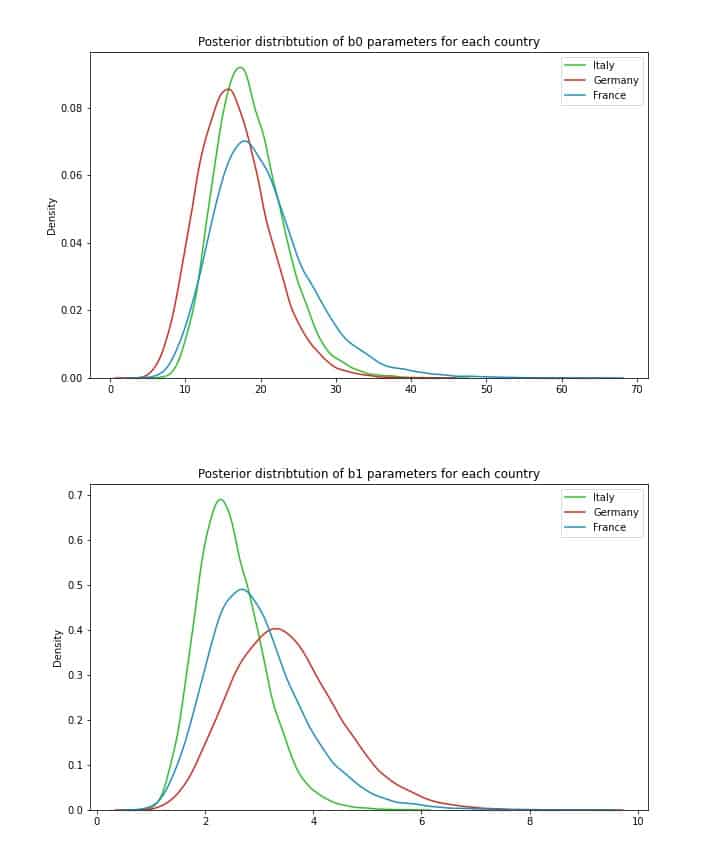
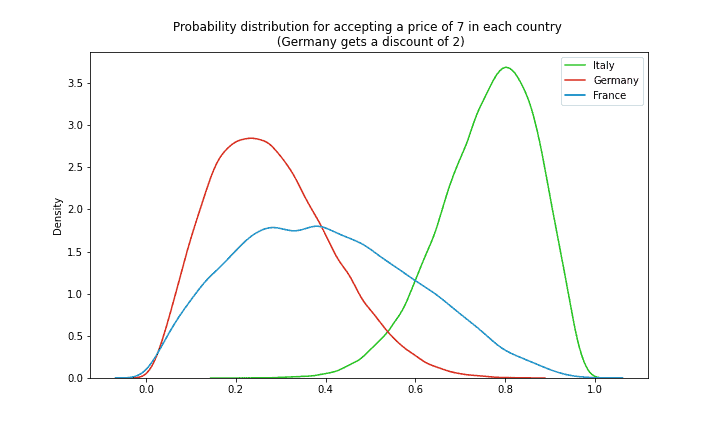
Schlussfolgerungen
Wie wir bisher gesehen haben, ist die Bayes'sche Modellierung nicht nur ein ausgefallenes, verwirrendes Konzept, mit dem Statistiker Erstsemester erschrecken wollen. Es handelt sich um ein flexibles und leistungsstarkes Rahmenwerk, das erhebliche Vorteile gegenüber "traditionellen" Ansätzen bietet. Wir können damit mehr Transparenz, direktes Fachwissen und/oder fundierte Annahmen direkt in das Modell einbringen. Und selbst wenn wir uns geirrt haben sollten, werden die Daten aus der realen Welt über das Bayes-Theorem korrigiert, so dass wir ein realistischeres Verständnis des vorliegenden Problems und einen brauchbaren Prognoserahmen erhalten. Darüber hinaus wurde die Unsicherheit quantifiziert und es wurden wertvolle analytische Erkenntnisse gewonnen. Dieser Anwendungsfall hat uns wiederum einige wichtige praktische Lektionen gelehrt. Es gab mehrere Faktoren, die die Konstruktion eines Bayes'schen Modells (mit PyMC3) erfolgreich machten. Erstens mussten wir mehrere Entscheidungen hinsichtlich der Komplexität treffen, die unser Modell berücksichtigen sollte (z.B. die Kombination von Fällen/Ländern, die Behandlung von Verkäufen als binäre Ereignisse usw.). Zweitens war eine sorgfältige Auswahl der priorisierten Parameterwerte erforderlich (die unsere Überzeugungen und unser Domänenwissen einbeziehen und das Modell nicht unnötig einschränken). Dann mussten wir das Ganze in einer geeigneten Likelihood-Funktion mit den ihr zugeführten realen Daten kombinieren. Schließlich haben wir mit dem automatisierten MCMC-Sampling-Algorithmus von PyMC3 Posterior-Stichproben gewonnen. Und voila - ein genaues und informatives Bayes'sches Modell steht uns zur Verfügung. Wenn Sie diese Schritte sorgfältig befolgen und mehr praktische Erfahrung mit dem Bayes'schen Rahmenwerk sammeln, wird es zu einem leistungsstarken und praktischen Werkzeug, das oft konkurrierende Ansätze schlägt oder uns hilft, wenn keine Alternativen zur Verfügung stehen. Prüfen Sie unser Bayesian Modeling TrainingVerfasst von
Vadim Nelidov
Unsere Ideen
Weitere Blogs




Contact