Blog
Geschäfte machen, die Bayes'sche Methode (Teil 1)

Teil 1: Von einem Geschäftsproblem zu einer Bayes'schen Lösung
Die Bayes'sche Modellierung ist ein weniger bekannter, aber sehr vielversprechender Bereich der Statistik und Datenwissenschaft. Sie gedeiht dort, wo traditionelle Ansätze scheitern, und bringt einige nette Vorteile mit sich. In dieser Reihe von Blogbeiträgen betrachten wir einen anschaulichen Geschäftsfall zur Preisoptimierung, der zeigt, warum die Bayes'sche Modellierung und die damit verbundene Technologie (wie die
Im ersten Teil dieser Serie lernen Sie einen anschaulichen Geschäftsfall und die wichtigsten Konzepte der Bayes'schen Modellierung kennen und übersetzen die ersteren in die Sprache der letzteren. Der zweite Teil konzentriert sich auf die eigentliche Konstruktion von Bayes'schen Modellen (mit PyMC3), das Ziehen von Schlussfolgerungen und die Entfaltung des vollen Potenzials dieses Bereichs. Alle Daten sowie alle weiteren Analysen, Diagramme und Modelle sind in diesem GitHub-Repository verfügbar.
Im Prinzip sind keine Vorkenntnisse in (Bayes'scher) Statistik erforderlich, aber ein gewisses Vorwissen würde die Lektüre natürlich vereinfachen (siehe z.B. diese Serie für hilfreiches Vorbereitungsmaterial).
Der Business Case
Nehmen wir ein (fiktives) B2B-Dienstleistungsunternehmen "Virtuoso", das in Frankreich, Deutschland und Italien tätig ist. Virtuoso kann in jedem Land unterschiedliche Preise verlangen, weiß aber nicht, wie es dies optimal tun kann. Ihre Daten bestehen aus Preisen, die in der Vergangenheit in jedem Land angeboten wurden und in einigen Fällen zu einem Verkauf geführt haben. Unser Ziel ist es, die Preisstrategie auf Bayes'sche Weise zu optimieren. Dies wird Virtuoso nicht nur dabei helfen, den Umsatz zu steigern, sondern auch festzustellen, wie ausgeprägt, preissensibel und unsicher jeder regionale Markt ist.
Das Problem verstehen
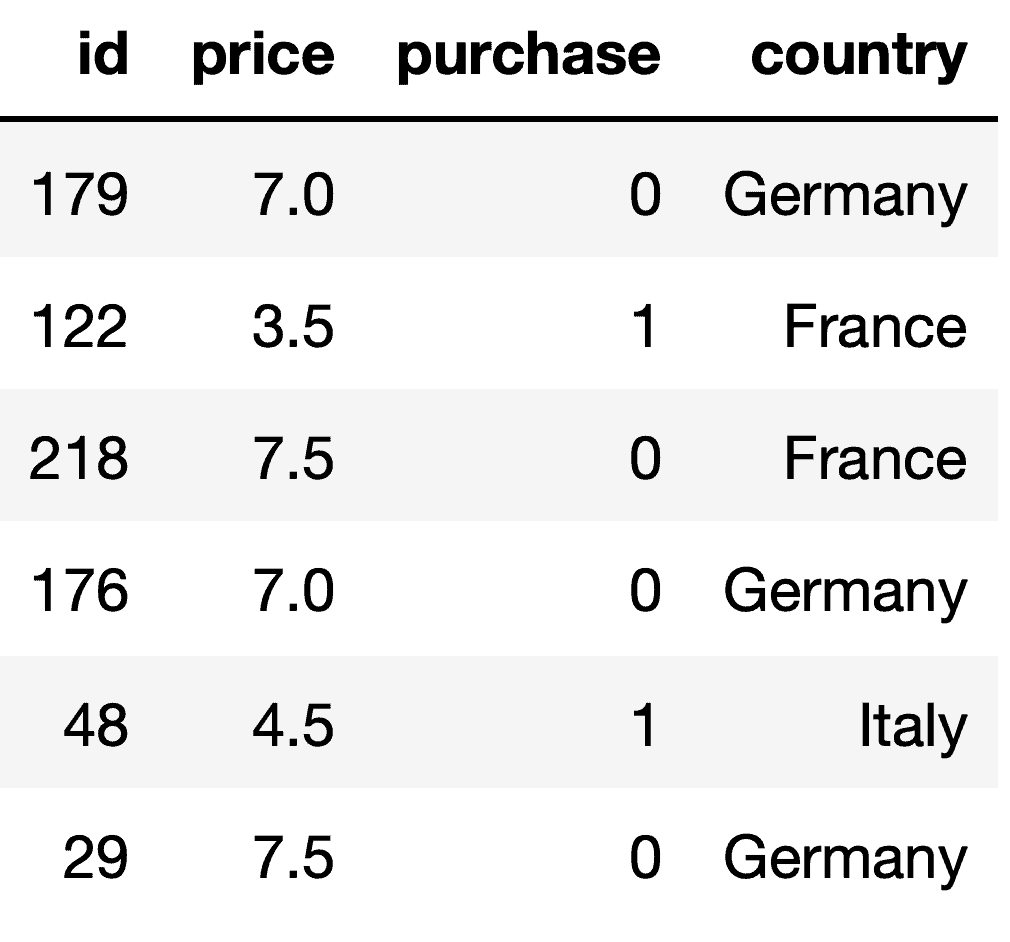
Bevor wir fortfahren, ist es wichtig, einige potenzielle Probleme in der Vergangenheit und der Preisstrategie von Virtuoso zu identifizieren. Dies wird uns bei der Formulierung unserer datengestützten Lösungen helfen. Anhand der Daten erkennen wir schnell, dass erfolgreiche Verkäufe nicht in allen Ländern gleich wahrscheinlich sind. Außerdem unterscheiden sich die Verkaufspreise für Käufe in den einzelnen Ländern. Abbildung 1 veranschaulicht diese beiden Beobachtungen für jedes Land (unter Verwendung von 95 % Konfidenzintervallen, um die Variabilität der Daten und die mögliche Datenknappheit zu berücksichtigen):
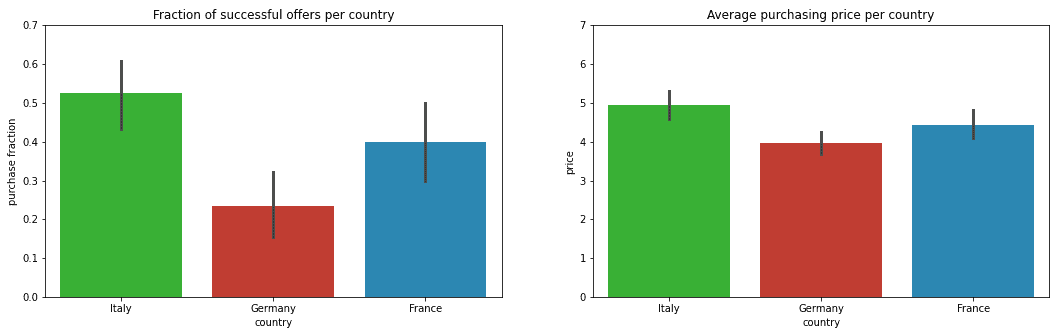
Warum werden in Deutschland mehr Angebote abgelehnt als in Italien? Der durchschnittliche Einkaufspreis in Deutschland ist niedriger, so dass die Kunden möglicherweise ein knapperes Budget haben und preissensibler sind. Daher ist es möglicherweise keine gute Idee, in allen Ländern die gleiche Preisstrategie anzuwenden. Derzeit sind die Einnahmen in Italien im Verhältnis zur Anzahl der Angebote mehr als doppelt so hoch wie in Deutschland. Das lässt eindeutig Raum für Verbesserungen. Wenn wir die Preissensitivität in jedem Land richtig quantifizieren, könnten wir solche Fortschritte erzielen.
Positiv ist, dass die Daten mit erfolgreichen und erfolglosen Angeboten in jedem Land für verschiedene Preise eine perfekte Grundlage für den Einsatz der Bayes'schen Analyse bieten, um die Unterschiede zwischen den Ländern besser zu verstehen und personalisierte Verkaufsstrategien zu entwickeln. Mithilfe des Bayes'schen Ansatzes können wir nicht nur die üblichen Prognosen erstellen (die uns dabei helfen, bessere Preise in jedem Land vorzuschlagen), sondern auch alle Insider-Wahrnehmungen über jedes Land in das Modell einbeziehen (z.B. dass die deutschen Budgets strenger sind). Wenn diese sich als etwas falsch erweisen, werden uns die Daten korrigieren. Also, fangen wir an.
Theorie in aller Kürze
Im Wesentlichen wird bei der Bayes'schen Modellierung eine Form des Bayes-Theorems verwendet, um zu ermitteln, wie das jeweilige Problem angesichts der beobachteten Daten und unseres Insiderwissens/unserer Überzeugungen wirklich aussieht. Wir haben vielleicht nur eine grobe Vorstellung davon, wie fair eine bestimmte Münze ist oder wie streng deutsche Unternehmen sind, aber mit ein paar relevanten Daten können wir diese Probleme viel besser verstehen. Und die Bayes'sche Modellierung sagt uns, wie genau diese neuen Daten in Kombination mit unseren groben Annahmen berücksichtigt werden sollten.
Dieser Ansatz bietet mehrere Vorteile: Im Gegensatz zu traditionellen (frequentistischen) Modellierungsansätzen müssen wir im Vorfeld weniger fragwürdige Annahmen treffen oder willkürliche Schwellenwerte(p-Werte und dergleichen) festlegen und missbrauchen. Stattdessen beziehen wir explizit das ein, was wir im Voraus über das Problem wissen (unsere Prioritäten). Das ist intuitiver, transparenter und lässt weniger Raum für Fehlinterpretationen.
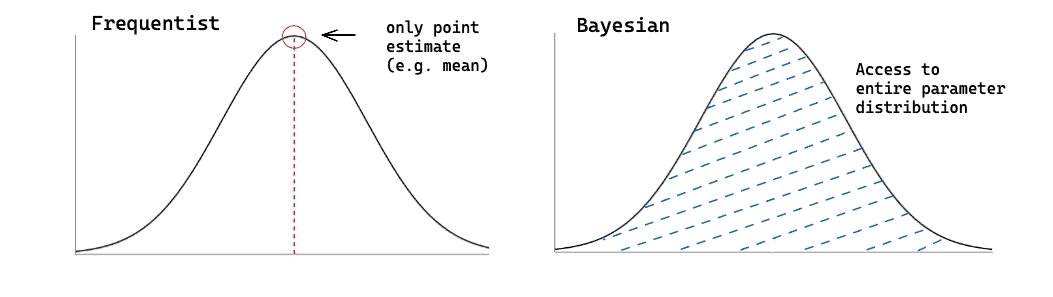
Für den Rest sorgt das Bayes-Theorem. Als Ergebnis erhalten wir nicht nur Punktschätzungen, sondern auch Verteilungen möglicher Modellparameter mit einem Hinweis darauf, wie groß die Unsicherheit bezüglich ihrer Werte ist - eine wertvolle Quantifizierung dessen, wie informativ die beobachteten Daten waren (siehe Abbildung 2). Dies kann wiederum zu wertvollen geschäftlichen Erkenntnissen führen, z. B. nicht nur zu durchschnittlichen vorhergesagten Werten, sondern zu einer Bandbreite solcher Werte in Verbindung mit dem jeweiligen Grad der Sicherheit.
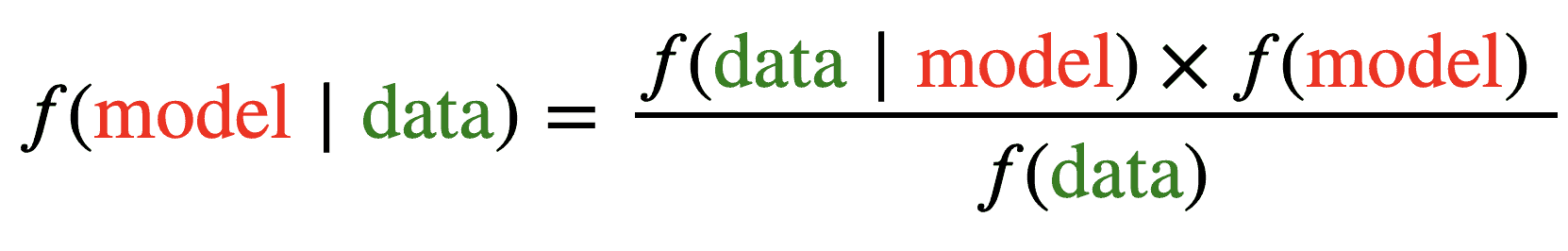
Entwicklung eines Bayes'schen Modells
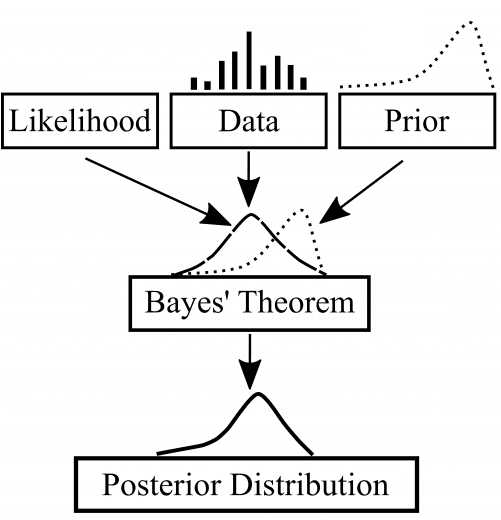
Unser Ziel bei der Arbeit mit Virtuoso ist es, die Bayes'sche Modellierung so anzuwenden, dass wir aus den Daten etwas über die Beziehung zwischen Preisen und Verkäufen in jedem Land lernen. In Bayes'schen Begriffen ausgedrückt, suchen wir nach den posterioren (nach dem Lernen) Verteilungen der Preissensitivitätsparameter (linker Teil von Abbildung 3). Wie die Bayes-Formel für die Modellierung in Abbildung 3 nahelegt, müssen wir drei wichtige Teile bestimmen.
- f(Daten|Modell) ist die "Likelihood-Verteilung" - die statistische Beziehung, die angibt, wie wahrscheinlich die Daten angesichts unseres Modells sind. Diese Komponente ergibt sich in der Regel aus dem Problem selbst: Viele Prozesse im echten Leben sind binäre Ereignisse wie Münzwürfe, die üblicherweise mit einer Bernoulli-Wahrscheinlichkeit modelliert werden.
- f(Modell) ist die "Prioritätsverteilung" - eine weitere statistische Beziehung, die alle anfänglichen Informationen und Annahmen berücksichtigt, die wir über das Problem haben. Wenn wir keine solchen Informationen haben, haben wir es mit "uninformierten Prioren" zu tun, was bedeutet, dass alles möglich ist. Wenn wir über Fachwissen, Erwartungen oder einfach nur Intuition verfügen, können wir diese direkt in das System integrieren.
- f(Daten) ist der technischste und am wenigsten intuitive Parameter. Die gute Nachricht ist, dass es sich im Grunde um einen datenabhängigen konstanten Wert handelt, der bei der praktischen Modellierung ignoriert werden kann.
Das Bayes-Theorem sagt uns, wie wir diese drei Faktoren in einer einzigen Gleichung kombinieren können, die die Posterior-Verteilung ergibt. Das Ergebnis ist, dass die beobachteten Daten unsere vorherige Verteilung in eine besser informierte Verteilung umwandeln. Einfacher ausgedrückt: Unser anfängliches Verständnis des Problems entwickelt sich mathematisch zu einem besser informierten Verständnis. Um dies zu verstehen, müssen Sie die Bayes'sche Modellierung verstehen:
Übersetzen Sie den Business Case.
Um den ersten Teil dieser Serie abzuschließen, lassen Sie uns den Business Case des Virtuoso in die Sprache der Bayes-Modellierung übersetzen. Dies wird für die spätere Konstruktion und Verwendung tatsächlicher Modelle unerlässlich sein.
Erstens: Worum geht es uns in diesem Geschäftsfall eigentlich? Wir möchten besser über das Kaufverhalten in den verschiedenen Ländern und die Unterschiede in der Preissensibilität der Kunden informiert sein. Daher sind wir in erster Linie an der Verteilung der Preissensibilität interessiert (die in jedem Land anders sein kann). Im Sinne von Bayes versuchen wir, Posteriorwerte für die Parameter der Preissensibilität zu erhalten - ganze Verteilungen, nicht nur Punktschätzungen wie Mittelwerte. Sobald wir diese haben, werden wir in der Lage sein, internationale Kunden nicht nur im Durchschnitt zu vergleichen, sondern auch in Bezug auf Risiken und Abweichungen.
Wie werden wir diese Posterioren ermitteln? Wir werden die Bayes-Formel zusammen mit den drei oben vorgestellten Kernkomponenten verwenden.
Mit Priors können wir bereits vorhandenes Wissen direkt in das Problem einfließen lassen. Wenn zum Beispiel die Preise steigen, sind die Kunden in der Regel weniger bereit zu kaufen. Folglich kann unser Prior dies erfassen, indem er die Preissensitivität auf ein negatives Vorzeichen beschränkt. Abgesehen davon wissen wir möglicherweise nur wenig darüber, wie diese Parameter aussehen könnten. In solchen Fällen wird in der Regel ein uninformierter Prior gewählt, um eine breite Palette von Möglichkeiten zuzulassen.
Die Wahrscheinlichkeitsverteilung betrifft den Prozess, der unsere Eingaben (verschiedene Preise) in ein Ergebnis (Kauf oder kein Kauf) umwandelt. Dabei handelt es sich um ein binäres Ereignis, das in der Statistik üblicherweise mit der
Schließlich ist die Verwendung von Daten in diesem Rahmen eine Selbstverständlichkeit, sobald alles andere definiert ist. Wir verfügen bereits über Daten, die Preisvorschläge mit dem Ergebnis 0/1 (Kauf oder kein Kauf) abgleichen. Diese Daten werden in ein Bayes'sches Modell eingespeist, das alle seine Komponenten kombiniert, um die Posteriorverteilung(en) zu erstellen. Die eigentliche Arbeit daran wird jedoch bis zum nächsten Teil dieser Serie warten müssen.
Kurze Retrospektive
In diesem ersten Teil unserer Serie über die Bayes'sche Methode der Unternehmensführung haben wir bisher eine zentrale analytische Frage aus einem realistischen Geschäftsfall identifiziert. Dann haben wir gesehen, wie diese Frage in die Sprache der Bayes'schen Modellierung übersetzt werden kann, und dabei auch einige der wichtigsten Konzepte in diesem Bereich kennengelernt. Wir können unsere Übersetzung mit der folgenden Illustration zusammenfassen:
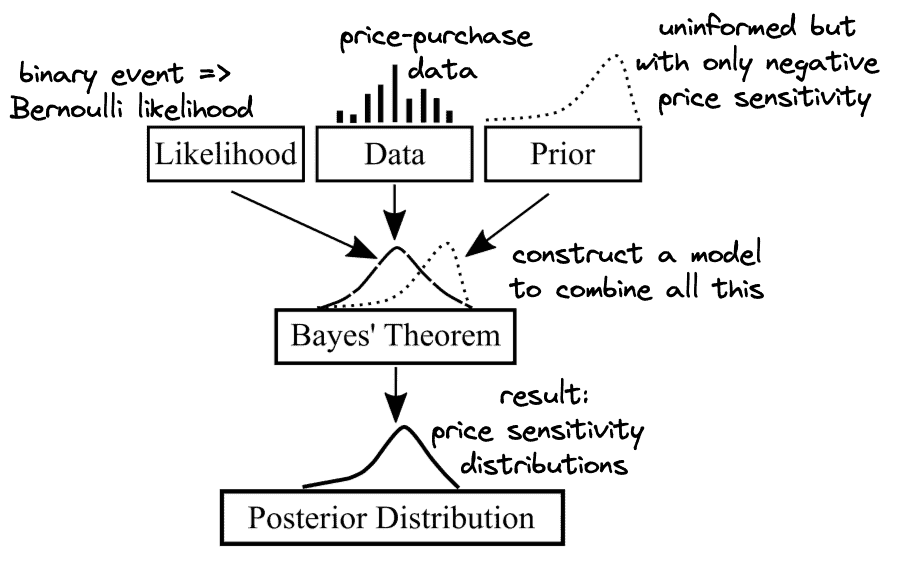
Während wir mit der Konstruktion eines Modells und der Analyse der Ergebnisse bis zum nächsten Teil warten werden, können wir bereits einige Merkmale der Bayes'schen Modellierung schätzen. Dazu gehört, dass wir unser Vorwissen direkt in das Problem einbeziehen können und gleichzeitig die Möglichkeit haben, es zu korrigieren, wenn wir uns irren. Jeder Schritt wird transparent modelliert - was weniger Raum für Fehlinterpretationen und versteckte Probleme lässt. Darüber hinaus hilft die strukturelle Betrachtung des Geschäftsproblems dabei, sein Wesen zu verstehen. Und am Ende können wir nicht nur eine punktuelle Schätzung vorwegnehmen, sondern umfassende Informationen über die betreffende Frage (involvierte Risiken, Ausmaß der Unsicherheit, Variabilität usw.), die für das Unternehmen von höherem Wert sind.
Verfasst von
Vadim Nelidov
Unsere Ideen
Weitere Blogs




Contact