Blog
Verteiltes Dashboarding mit DuckDB-Wasm, könnte das die Zukunft von BI sein?

Ein Blog aus dem Jahr 2023: " BIG DATA IST TOT " von Jordan Tigani hat mich dazu inspiriert, ein wenig in das DuckDB- und MotherDuck-Ökosystem einzutauchen. Tigani ist ein ehemaliger Gründungsingenieur von Google BigQuery und hat mehr als 10 Jahre lang an diesem Produkt gearbeitet. In seinem Blog "BIG DATA IS DEAD" erklärt Tigani, dass sich die Big Data-Ära in seinen Augen anders entwickelt hat als erwartet. Viele Unternehmen bauen diese riesigen Data Warehouses auf und nutzen Cloud Compute, um ihre vermeintlichen Big Data-Workloads in der Cloud auszuführen. In Wirklichkeit stellt sich heraus, dass etwa 90% der Abfragen, die auf BigQuery ausgeführt werden, weniger als 100 MB Daten verarbeiten. Das soll nicht heißen, dass es keine Big Data gibt, aber sie werden nicht so oft abgefragt oder verarbeitet, wie Sie es erwarten würden. Und wenn Sie nicht immer "Big Data" verarbeiten, müssen Sie vielleicht auch nicht immer Daten mit einer Infrastruktur und Tools verarbeiten, die für die Verarbeitung von "Big Data" entwickelt wurden.
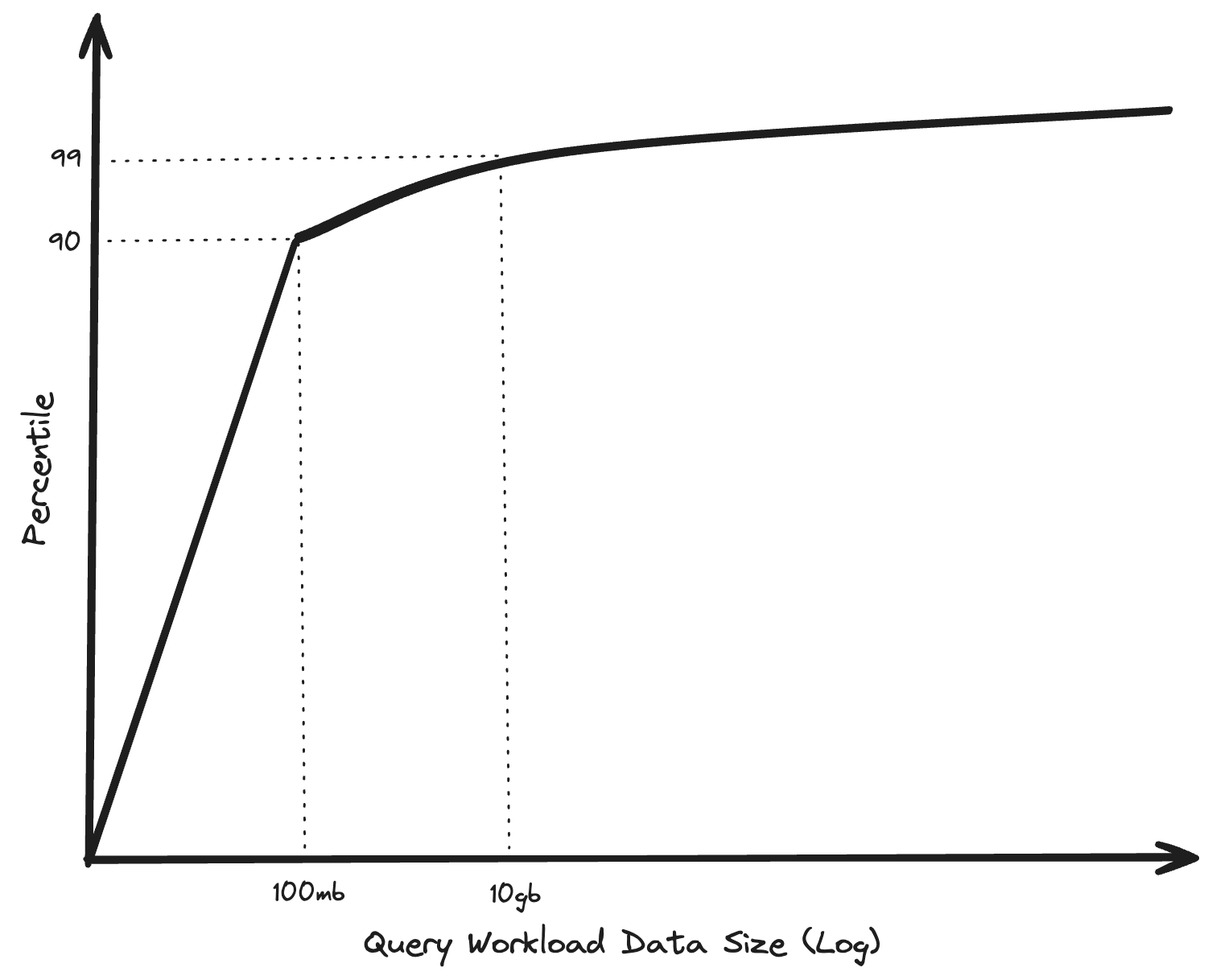
Inzwischen hat sich die Ausstattung eines durchschnittlichen Laptops in den letzten zehn Jahren drastisch verbessert. 16 oder 32 GB Arbeitsspeicher und ein leistungsstarker Multi-Core-Prozessor sind in einem Standard-Business-Laptop eher die Regel als die Ausnahme. Ist es nicht sinnvoller, insbesondere bei kleineren Datenverarbeitungsaufgaben, diese auf Ihrem lokalen Rechner auszuführen? Einem Rechner, für den Sie bereits bezahlt haben. Natürlich bringt dies andere Herausforderungen mit sich, ich meine, wann entscheiden Sie, ob Sie etwas lokal oder in der Cloud ausführen? Und wollen Sie das überhaupt selbst entscheiden? Sind die Kosten für die Übertragung von Daten über ein Netzwerk (bezogen auf die Egress-Kosten in der Cloud) nicht höher als die eigentlichen Cloud-Rechenkosten für die Arbeitslast selbst? Leider werden Sie in diesem Blogbeitrag keine Antworten auf diese Fragen finden, aber das Konzept, mehr Datenverarbeitung aus der Cloud auf den lokalen Rechner zu verlagern, erscheint mir vielversprechend. Stattdessen werde ich in diesem Blogbeitrag erklären, wie ich mir "Distributed Dashboarding" vorstelle, einschließlich eines praktischen Beispiels mit DuckDB-Wasm.
Ein Unternehmen namens MotherDuck hat kürzlich 100 Millionen Dollar aufgenommen für die Arbeit an ihrem Cloud-Angebot von DuckDB zu arbeiten, und arbeitet an Lösungen und Antworten auf die oben genannten Fragen. DuckDB ist ein rasend schnelles, in C++ geschriebenes analytisches Datenbanksystem. MotherDuck ist nicht "nur ein Cloud-Angebot" von DuckDB, sondern bietet einige coole Funktionen zusätzlich zu DuckDB. Hybride Abfrageausführung ist eine dieser Funktionen und auch ein wichtiges Verkaufsargument für MotherDuck. Bei der hybriden Abfrageausführung entscheidet die MotherDuck-Erweiterung, ob eine Abfrage lokal, teilweise lokal und teilweise in der Cloud oder vollständig in der Cloud ausgeführt wird. Dies wird durch die eingebettete Natur von DuckDB und seinen Erweiterungsmechanismus ermöglicht. Wenn Sie mehr über die hybride Abfrageausführung und die Architektur von MotherDuck erfahren möchten, empfehle ich Ihnen die Lektüre des Papier zur hybriden Abfrageausführung das kürzlich auf der CIDR 2024 vorgestellt wurde.
DuckDB-Wasm eröffnet die Möglichkeit, DuckDB vollständig im Webbrowser auszuführen. WebAssembly . Dies erleichtert die Integration von DuckDB (und damit auch von MotherDuck über die Erweiterung) in allgemeine Webanwendungen oder sogar browserbasierte BI-Tools. Stellen Sie sich die Möglichkeiten einer blitzschnellen SQL-Schnittstelle mit nahezu null Latenz vor, die direkt im Browser verfügbar ist. MotherDuck konzentriert sich wirklich auf das Konzept, die Verarbeitung (teilweise oder vollständig) clientseitig durchzuführen, und ich bin sehr gespannt, was die Zukunft bringen wird. Meiner Meinung nach könnte dies ein bahnbrechender Schritt in eine möglicherweise neue Ära im Bereich Data Warehousing und Analyse sein. Ich bin besonders gespannt darauf, ob sich dadurch die Art und Weise ändern wird, wie wir derzeit mit BI-Anwendungsfällen auf "vermeintlich" großen Daten umgehen.
Verteiltes Dashboarding
Der Begriff "Distributed Dashboarding" hat vielleicht Ihre Aufmerksamkeit erregt und Sie dazu veranlasst, diesen Blogbeitrag überhaupt erst zu lesen. Um ehrlich zu sein, ist das ein Begriff, den ich mir nur ausgedacht habe, um Ihre Aufmerksamkeit zu erregen. Das Konzept ist jedoch meiner Meinung nach sehr vielversprechend. Ich denke, wir werden in Zukunft immer mehr Beispiele dafür sehen, vor allem mit der Entwicklung des Internets in Bezug auf Geschwindigkeit und Bandbreite. Das Versenden eines Datensatzes von mehreren hundert Megabyte an Kunden ist heutzutage recht schnell und wird in Zukunft noch schneller werden. Die Idee, die ich mit "Distributed Dashboarding" verfolge, ist, einen Teil oder in manchen Fällen den gesamten Datensatz, der für ein Dashboard benötigt wird, zusammen mit der (analytischen) Verarbeitungslogik an den Client zu senden (daher der Begriff "Distributed"). Der Browser lädt diesen Datensatz einmal herunter und speichert ihn dann im Cache des Browsers. Aufgrund von DuckDB-Wasm und der eingebetteten Natur von DuckDB kann der Browser diesen Datensatz dann in eine clientseitige DuckDB-Wasm-Instanz laden. Dies bietet eine blitzschnelle SQL-Schnittstelle über dem Rohdatensatz. Der größte Teil der Zerlegung der Daten, z.B. für Self-Service-BI-Zwecke, kann im Browser auf dem lokalen Rechner erfolgen, statt dass die Rechenleistung eines großen Data Warehouse erforderlich ist. Die webbasierte BI-Anwendung muss lediglich SQL-Code generieren und diesen SQL-Code gegen die browserinterne DuckDB-Wasm-Instanz ausführen.
Natürlich ist dieses Konzept mit vielen Herausforderungen verbunden, und es wird nicht für alle bestehenden BI- und/oder OLAP-Anwendungsfälle geeignet sein. Es gibt definitiv Anwendungsfälle, bei denen die Verarbeitung wirklich großer Daten erforderlich ist und die nicht lokal auf einem einzelnen Rechner durchgeführt werden können. Ich denke jedoch, dass es viele Anwendungsfälle gibt, in denen dies sehr gut funktionieren kann, insbesondere dort, wo Sie nicht unbedingt extrem große Datenmengen analysieren. Ich werde einige der Herausforderungen, die ich mir vorstellen kann, mit möglichen Lösungen durchgehen. Was ist zum Beispiel, wenn der Datensatz ziemlich groß ist oder die Netzwerklatenz nicht so gut ist? Vielleicht ist es möglich, zunächst voraggregierte Daten für das Dashboard zu senden und dann den gesamten Datensatz (oder den Teil, den der Benutzer benötigt) im Hintergrund herunterzuladen? Wenn der Client eine langsame Netzwerklatenz feststellt, kann er vielleicht entscheiden, die Ausführung in der Cloud statt lokal vorzunehmen. Bei einem anderen Benutzer mit hoher Netzwerklatenz kann er sich entscheiden, den gesamten Datensatz herunterzuladen und die Verarbeitung lokal durchzuführen. Möglicherweise kann ein KI-Modell bei diesen Entscheidungen helfen? Ich denke auch, dass es viele Anwendungsfälle gibt, bei denen die meisten Benutzer nur die Daten der letzten Woche oder sogar der letzten Tage betrachten. Vielleicht ist es möglich, diese (kleinere) Zeitspanne von Daten beim ersten Laden des Dashboards mit einzubeziehen und die analytische Verarbeitung für die meisten Benutzer lokal durchzuführen. Wenn ein Benutzer jedoch weiter zurückblicken möchte als die angegebene Zeitspanne und eine Analyse eines größeren Datensatzes durchführen möchte, wird die Abfrage im Data Warehouse ausgeführt. Eine weitere Herausforderung könnte die Abfrage von Inkrementen sein. Wenn ich zum Beispiel die Daten des letzten Monats lokal im Cache gespeichert habe und morgen das Dashboard öffne, sollte es einen Mechanismus geben, der die Daten des neuen Tages herunterlädt und an den lokalen Datensatz anhängt.
Hoffentlich wird die MotherDuck-Erweiterung für DuckDB in Zukunft Lösungen für einige dieser Probleme bieten und Ihnen die schwere Arbeit der Implementierung einer (teilweise) clientseitigen Datenverarbeitung für BI-Dashboards abnehmen. Ich bin auch gespannt, ob es in den nächsten Jahren Beispiele für BI-Tools geben wird, die das Konzept der lokalen Datenverarbeitung übernehmen. Meiner Meinung nach kann dies ein Alleinstellungsmerkmal für ein BI-Tool sein, insbesondere wenn Sie davon ausgehen, dass viele Benutzer ihre eigenen Self-Service-BI auf Ihren Daten durchführen.
Beispiel für verteiltes Dashboarding mit React und DuckDB-Wasm
Um das Konzept des Distributed Dashboarding ein wenig mehr in die Praxis umzusetzen und mit DuckDB-Wasm zu experimentieren, habe ich beschlossen, eine kleine Dashboard-Anwendung mit React und DuckDB-Wasm zu erstellen. Ein Kollege arbeitete an einem internen Anwendungsfall, bei dem wir die GitHub-Beiträge einiger unserer Xebia-Kollegen verfolgen und ein Dashboard anbieten, um Einblicke in die aktivsten OSS-Projekte zu erhalten. Das Projekt verwendet dbt mit dem dbt-duckdb Adapter und ein selbst entwickeltes dbt-duckdb-Plugin, das Daten von der GitHub API . Schließlich schreibt dbt alle Daten über den dbt-duckdb Adapter in eine speicherinterne DuckDB Datenbank (die eine .duckdb Datei erstellt). Diese .duckdb-Datei enthält alle relevanten GitHub-Beiträge und wird mit der Web-Anwendung ausgeliefert, so dass sie direkt im Browser über DuckDB-Wasm verwendet werden kann.
 Probieren Sie das github-contributions Dashboard selbst aus
Probieren Sie das github-contributions Dashboard selbst aus
Das Tolle daran ist, dass der Browser die Datei github-contributions.duckdb nur einmal herunterladen muss und sie von da an im Browser-Cache speichert (im aktuellen Beispiel nur für 10 Minuten, da die GitHub-Seiten keine Änderung der Caching-Header erlauben). Alle Filter- und Aggregationsfunktionen innerhalb des Dashboards werden von der lokalen DuckDB-Wasm-Instanz über SQL-Anweisungen verarbeitet.
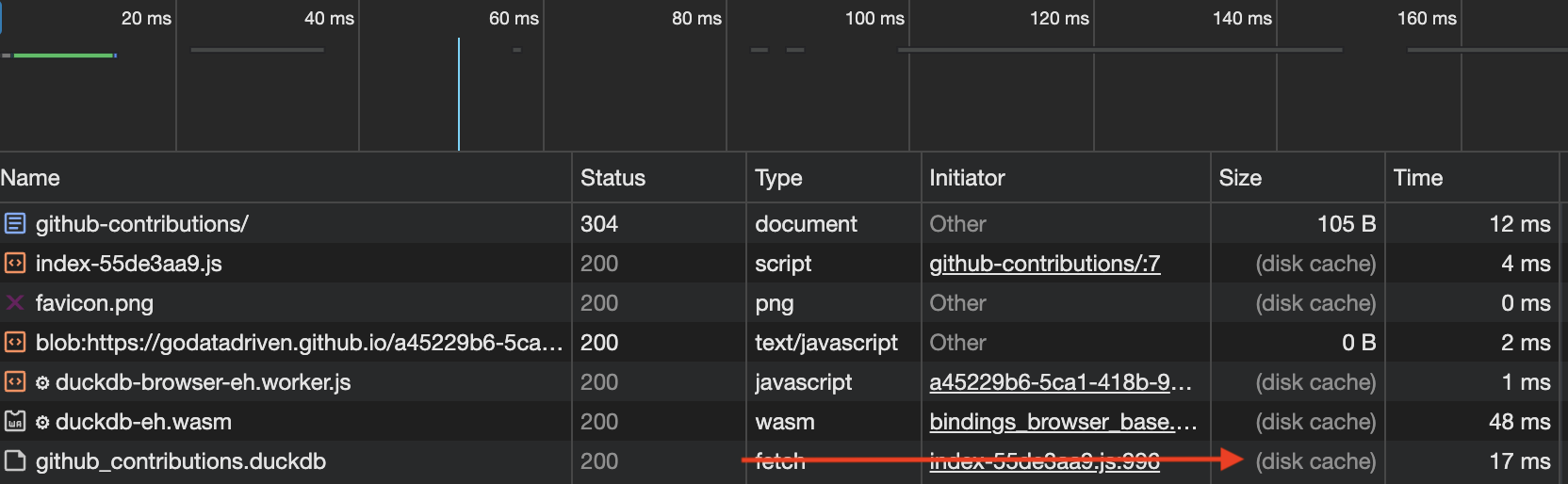
Um dies zu ermöglichen, habe ich das
duckdb-wasm-kit
das die Verwendung von DuckDB-Wasm in React-Anwendungen erleichtert. Das duckdb-wasm-kit bietet Hooks und Dienstprogramme zur einfachen Interaktion mit DuckDB-Wasm. Ich musste einige kleine Beiträge leisten, damit es mit externen
Fazit
Obwohl das Konzept des Distributed Dashboarding vielversprechend ist, würde ich sagen, dass es sich derzeit noch in einem frühen Stadium befindet. Für ein reales Unternehmen würde ich nicht empfehlen, React oder ein anderes Webanwendungs-Framework für die Erstellung von Dashboards zu verwenden, sondern lieber eines der weit verbreiteten BI-Tools zu nutzen. Die Integration von Technologien wie DuckDB-Wasm und der hybriden Abfrageausführung von MotherDuck in weit verbreitete BI-Tools ist jedoch eine spannende Perspektive für die Zukunft. Es war ein schönes Experiment, mit DuckDB-Wasm herumzuspielen und ein Beispiel dafür zu erleben, dass Distributed Dashboarding theoretisch möglich ist. Hoffentlich werden wir in Zukunft mehr und mehr Beispiele dafür sehen.
Wenn Sie Fragen oder Anmerkungen zu diesem Blogbeitrag haben, können Sie uns gerne kontaktieren.
Verfasst von
Ramon Vermeulen
Cloud Engineer
Unsere Ideen
Weitere Blogs



Contact