Blog
Bereitstellen eines benutzerdefinierten Docker-Images auf Azure ML unter Verwendung einer blau-grünen Bereitstellung mit Python

Einführung
Azure Machine Learning (Azure ML) ist ein beliebter Dienst für maschinelles Lernen. Azure ML bietet viele vordefinierte Funktionen für die Bereitstellung von Endpunkten für Machine Learning-Modelle, was großartig ist. Wenn Sie jedoch versuchen, eine benutzerdefinierte Lösung zu erstellen, kann das ziemlich schwierig sein!
In diesem Blogpost werden wir uns mit einer solchen maßgeschneiderten Lösung beschäftigen. Wir werden Folgendes tun:
- Setzen Sie unser ML-Modell mit einem benutzerdefinierten Docker-Image ein.
- Verwenden Sie eine blau-grüne Bereitstellungsstrategie, um sicherzustellen, dass es bei der Bereitstellung unseres Modells keine Ausfallzeiten gibt.
- Führen Sie Smoke-Tests durch, um zu sehen, ob unser Einsatz wie erwartet funktioniert, bevor wir unser bisheriges Modell ersetzen.
- Verwenden Sie das Azure ML Python SDK zur Konfiguration und Verwaltung der Bereitstellung auf Azure ML.
Das ist eine Menge Inhalt, also fangen wir an!
Voraussetzungen
Wir empfehlen den Lesern, den Code selbst zu schreiben, um den größten Nutzen aus diesem Blogpost zu ziehen. Dazu benötigen Sie Folgendes:
- Python 3.12, mit dem unser Code geschrieben wurde
- Docker, damit wir unser eigenes Docker-Image erstellen, testen und veröffentlichen können
- Ein bestehender Azure ML Arbeitsbereich
- Eine bestehende Azure Container-Registrierung
Außerdem sind die folgenden Python-Pakete erforderlich. Sie können sie mit pip installieren:
pip install fastapi=="0.109.2" azure-ai-ml=="1.13.0" azure-identity=="1.15.0"
Warum ein benutzerdefiniertes Docker-Image auf AzureML verwenden?
Azure bietet viele vorgefertigte Docker-Images. Diese Images verwenden gängige Python-Pakete und werden mit einem Flask-Server erstellt.
Diese vorgefertigten Bilder sind jedoch nicht immer für unsere Bedürfnisse geeignet. Vielleicht möchten wir ein anderes Web-Framework verwenden, eine umfassende Datenvalidierung durchführen, bevor wir die Daten verarbeiten, oder Modelle von außerhalb von Azure ML verwenden.
Für dieses Beispiel werden wir FastAPI verwenden. FastAPI verwendet
Warum Python und nicht das Azure CLI verwenden?
Wahrscheinlich haben Sie die Azure-Befehlszeilenschnittstelle bereits für Aufgaben wie die Authentifizierung und die Bereitstellung von Ressourcen in Azure verwendet. Die Azure-Befehlszeilenschnittstelle ist gut geeignet, um mit Azure-Ressourcen zu experimentieren, aber es kann schwierig sein, wenn Sie die Befehlszeilenschnittstelle für die Bereitstellung mehrerer voneinander abhängiger Ressourcen verwenden. Dies kann besonders schmerzhaft sein, wenn Sie Azure ML aus CI/CD-Pipelines heraus bereitstellen: Die Logik muss oft in Bash-Skripten oder in der YAML-Syntax der Pipeline selbst implementiert werden.
Die Verwendung von Python bietet uns einige Vorteile:
- Leichter zu lesen
- Leichter zu schreiben
- Einfacher zu argumentieren
- Ermöglicht es uns, eine Befehlszeilenschnittstelle (CLI) zu erstellen, der wir benutzerdefinierte Argumente übergeben können.
- Integration mit unseren Redakteuren, die Ihnen Tipps geben können, was Sie schreiben sollen
Mithilfe von Python können wir unserer Bereitstellung auch eine besondere Note verleihen: eine blau-grüne Bereitstellungsstrategie.
Was ist ein blau-grüner Einsatz und warum wird er verwendet?
Bei einer unkomplizierten Bereitstellung wird eine laufende Serveranwendung sofort durch die neue Version ersetzt. Dies kann zu einer gewissen Ausfallzeit führen, oder noch schlimmer: Die Anwendung funktioniert möglicherweise überhaupt nicht! In diesem Fall besteht die einzige Möglichkeit zur Wiederherstellung darin, die alte Version erneut zu verteilen oder das Problem zu beheben und eine noch neuere Version zu verteilen. Aber es gibt einen besseren Weg.
Bei der blau-grünen Bereitstellung werden unsere neuen Änderungen auf einem Server (grün) getrennt vom laufenden Server (blau) bereitgestellt. Auf diese Weise können wir unsere Änderungen bereitstellen, sie testen und erst dann in unsere Anwendung übernehmen, wenn unsere Tests erfolgreich verlaufen sind. Dieser letzte Schritt erfolgt, indem wir den gesamten Datenverkehr von der blauen auf die grüne Anwendung umleiten. Um dies tun zu können, haben wir eine separate Schicht zwischen unseren Benutzern und unserer Anwendung.
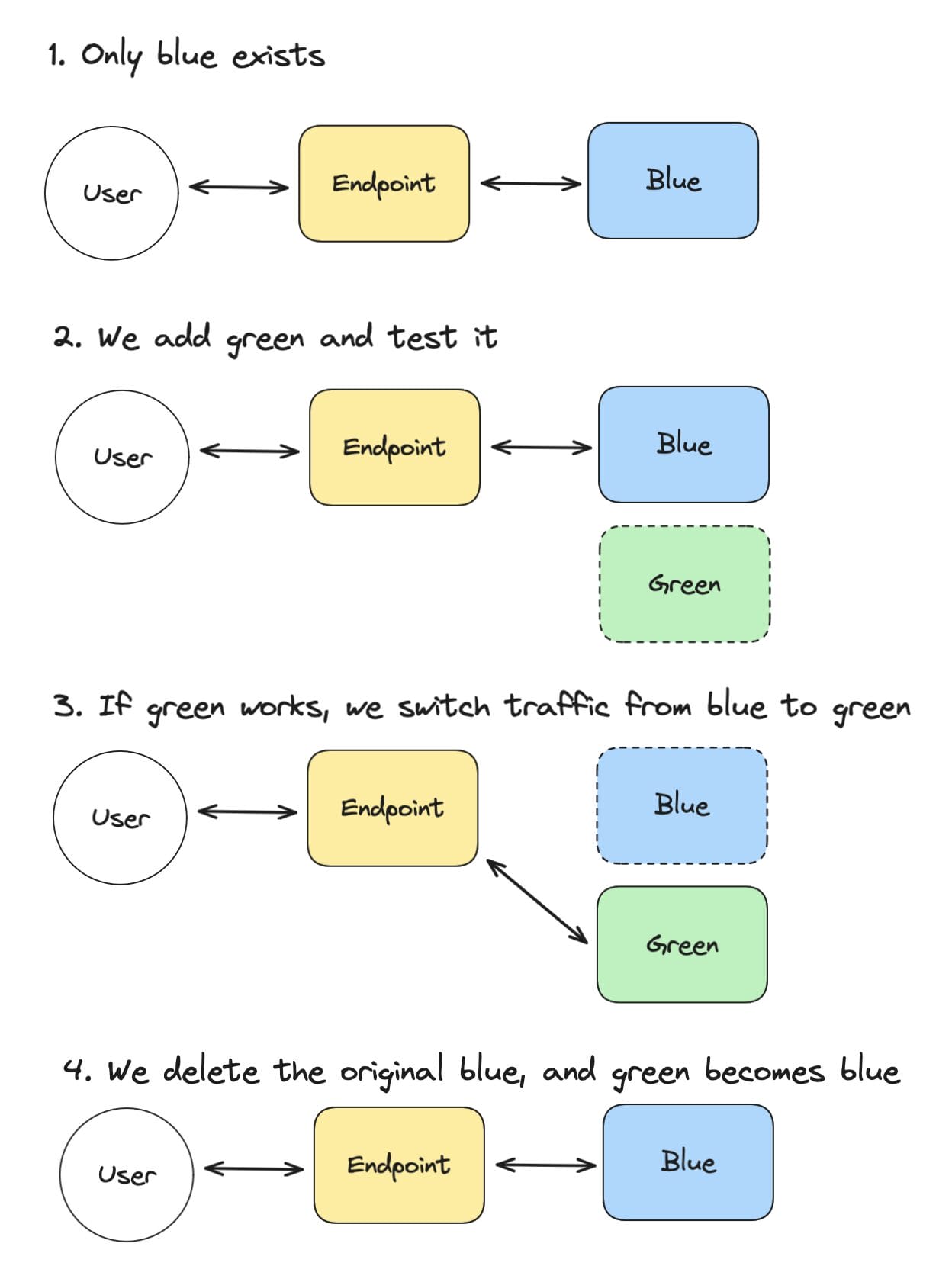
In Schritten funktioniert dies folgendermaßen:
- Wir haben nur die blaue Anwendung. Der Endpunkt leitet die Benutzer zur blauen Anwendung.
- Wir fügen eine grüne Anwendung hinzu, die wir separat testen. Die Benutzer kommunizieren weiterhin über den Endpunkt mit der blauen Anwendung.
- Wenn unsere grüne Anwendung wie erwartet funktioniert, schalten wir den gesamten Endpunktverkehr von blau auf grün um. Die Benutzer werden nun die grüne Anwendung verwenden.
- Wir löschen die ursprüngliche blaue Anwendung. Unsere grüne Anwendung wird die neue blaue Anwendung. Jetzt kann der ganze Prozess für neue Änderungen von vorne beginnen.
Benutzerdefiniertes Docker-Image mit FastAPI einrichten
Die FastAPI-Anwendung
Für dieses Beispiel werden wir eine kleine FastAPI-Anwendung erstellen. Diese Anwendung wird ein lineares Regressionsmodell enthalten, das Vorhersagen liefern kann. Wir packen den Code in ein Docker-Image, das wir als Azure ML-Bereitstellung bereitstellen werden.
Unsere FastAPI-Anwendung wird Folgendes tun: - Einrichten der FastAPI-Anwendung: mit einer Route für Gesundheitschecks und einer Route für Vorhersagen. - Erstellung von Anfrage- und Antwortmodellen mit Pydantic, die eine automatische Datenvalidierung für uns durchführen. Diese Modelle werden in den FastAPI-Endpunkten verwendet. - Trainieren Sie ein einfaches lineares Regressionsmodell. Beachten Sie, dass das Modell sofort trainiert wird, wenn wir die Datei ausführen. In einem realen Szenario würden Sie Ihr Modell separat trainieren und es in Ihre Anwendung laden.
Hier ist der Code für unsere FastAPI-Anwendung, den wir in einer Datei namens api.py ablegen:
from fastapi import FastAPI
from pydantic import BaseModel
from sklearn import linear_model
# We train a very simple model, since this is just an example
model = linear_model.LinearRegression()
X = [[0, 0], [1, 1], [2, 2]]
y = [0, 1, 2]
model.fit(X, y)
app = FastAPI(title="ML Endpoint")
class PredictionRequest(BaseModel):
values: list[list[float]]
class PredictionResponse(BaseModel):
predictions: list[float]
@app.get("/health")
def health():
return {"status": "ok"}
@app.post("/predict", response_model=PredictionResponse)
def predict(request: PredictionRequest):
y_pred = model.predict(request.values)
return PredictionResponse(predictions=y_pred)
Beachten Sie, dass der FastAPI-Code mit der Umgebungskonfiguration übereinstimmen muss
Bauen mit Docker
Mit Docker können wir unsere FastAPI-Anwendung in ein Docker-Image einbauen. Dadurch wird sichergestellt, dass unsere Anwendung überall gleich funktioniert. Wir verwenden dazu die folgende Dockerfile:
FROM python:3.12-slim
WORKDIR /app
ADD requirements.txt .
RUN pip install --no-cache-dir -r requirements.txt
ADD api.py .
EXPOSE 8000
CMD ["uvicorn", "api:app", "--host", "0.0.0.0", "--port", "8000"]
Den Docker-Container lokal testen
Zu Testzwecken können Sie den Container wie folgt erstellen:
docker build -t my-fastapi-app .
Sie können es mit dem folgenden Befehl ausführen:
docker run -p 8000:8000 my-fastapi-app
Stellen Sie dann eine Verbindung zu http://localhost:8000/docs her, um die Dokumentation Ihres lokalen Endpunkts anzuzeigen.
Wenn wir bestätigt haben, dass es wie erwartet funktioniert, können wir das Image erstellen und an die Azure Container Registry senden.
Erstellen und Übertragen des Docker-Images in die Azure Container Registry
Um unser Docker-Image zu erstellen und zu veröffentlichen, müssen wir Folgendes tun: 1. Melden Sie sich bei Azure Container Registry (ACR) an 2. erstellen Sie unser Image mit dem richtigen Tag 4. Pushen Sie unser Image
Anmeldung bei Azure Container Registry (ACR)
az acr login --name $ACR_NAME
Unser Image aufbauen
docker build -t $ACR_NAME.azurecr.io/$IMAGE_NAME:$IMAGE_TAG .
Unser Image fördern
docker push $ACR_NAME.azurecr.io/$IMAGE_NAME:$IMAGE_TAG
Jetzt, wo unser Image gepusht wurde, können wir damit beginnen, es auf Azure ML zu verteilen.
Azure ML Endpunkt und Bereitstellung erstellen
Importieren Sie Ihre Abhängigkeiten
Um die Beispiele zu verdeutlichen, importieren wir zu Beginn alle unsere Abhängigkeiten:
from azure.ai.ml import MLClient
from azure.ai.ml.entities import (
Environment,
ManagedOnlineDeployment,
ManagedOnlineEndpoint,
)
from azure.identity import DefaultAzureCredential
Holen und setzen Sie Ihre Variablen
Um Azure ML richtig konfigurieren zu können, benötigen Sie die folgenden Variablen:
SUBSCRIPTION_ID="..."
WORKSPACE_NAME="..."
RESOURCE_GROUP="..."
ACR_NAME="..."
INSTANCE_TYPE="..."
IMAGE_NAME="..."
IMAGE_TAG="..."
Sie können diese Variablen im Azure-Portal finden.
- SUBSCRIPTION_ID: Siehe die Azure Docs.
- ARBEITSBEREICH_NAME: Suchen Sie im Azure Portal nach "Azure Machine Learning", klicken Sie darauf und kopieren Sie den Namen, den Sie in der Liste sehen.
- RESOURCE_GROUP: Wie der Name des Arbeitsbereichs, aber kopieren Sie die Ressourcengruppe.
- ACR_NAME: Suchen Sie im Azure Portal nach "Container-Registrierungen", klicken Sie darauf und kopieren Sie den Namen Ihrer Container-Registrierung.
Den Azure ML Client einrichten
Um Azure ML-Ressourcen zu konfigurieren, verwenden wir den MLClient aus der Azure ML-Bibliothek.
# The credential is required
credential = DefaultAzureCredential()
# The MLClient configures Azure ML
ml_client = MLClient(
credential=credential,
subscription_id=SUBSCRIPTION_ID,
resource_group_name=RESOURCE_GROUP,
workspace_name=WORKSPACE_NAME,
)
Was sind Endpunkte und Einsätze?
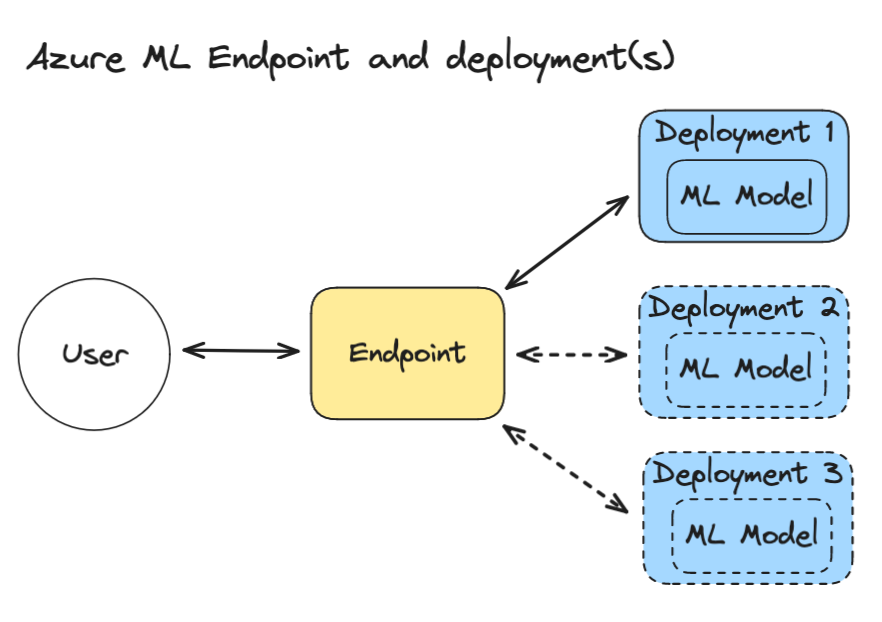
Ein Azure ML-Endpunkt ist ein Webserver, mit dem Ihre Benutzer oder Anwendungen kommunizieren können. Der Endpunkt bearbeitet eingehende Anfragen und die Authentifizierung. Hinter dem Endpunkt können sich ein oder mehrere Einsätze befinden. In den Deployments werden Ihre Modelle oder Ihr Code ausgeführt, die auf der Grundlage der eingehenden Daten Berechnungen durchführen.
Einen Endpunkt erstellen
Wir erstellen einen Endpunkt wie folgt. Wenn der Endpunkt bereits existiert, wird er aktualisiert.
endpoint = ManagedOnlineEndpoint(
name="my-endpoint-1234abc", # Choose your own name; Note that it has to be unique across the Azure location (e.g. westeurope)
auth_mode="key", # We use a key for authentication
)
# Create the endpoint
ml_client.online_endpoints.begin_create_or_update(endpoint).result()
Beachten Sie, dass die Methode create_or_update asynchron ist, so dass wir .result() verwenden, um tatsächlich auf ihre Beendigung zu warten. Wenn Sie dies nicht hinzufügen, müssen Sie zusätzlichen Code schreiben, um den Status zu überprüfen. Die gleiche Technik wird auch bei anderen Bereitstellungsschritten verwendet.
Wenn wir unseren Endpunkt haben, können wir damit beginnen, ihm Bereitstellungen hinzuzufügen.
Eine Bereitstellung erstellen
Ein Azure ML-Endpunkt kann viele Bereitstellungen haben und Sie können konfigurieren, wie der Endpunkt den Datenverkehr zwischen verschiedenen Endpunkten aufteilt. Bevor wir unseren Einsatz erstellen können, müssen wir eine Umgebung erstellen:
Schaffen Sie eine Umgebung
Bevor wir einen benutzerdefinierten Docker-Container bereitstellen können, müssen wir eine benutzerdefinierte Azure ML-Umgebung konfigurieren. Die Umgebung erfordert:
- ein Name
- einen Link zu dem Docker-Image
- eine Inferenzkonfiguration, die festlegt, wie bestimmte Anrufe weitergeleitet werden sollen. Diese muss mit den Routen des FastAPI-Codes übereinstimmen, den wir zuvor geschrieben haben.
Hier sehen Sie, wie Sie ihn im Code erstellen:
# Configure a model environment
# This configuration must match with how you set up your API`
environment = Environment(
name=f"{image_name}-env",
image=f"{ACR_NAME}.azurecr.io/{IMAGE_NAME}:{IMAGE_TAG}",
inference_config={
"scoring_route": {
"port": 8000,
"path": "/predict",
},
"liveness_route": {
"port": 8000,
"path": "/health",
},
"readiness_route": {
"port": 8000,
"path": "/ready",
},
},
)
Die Variable environment kann nun an die Erstellung der Bereitstellung übergeben werden:
Einsatz mit Umgebung erstellen
Richten Sie eine Bereitstellung mit ein:
# Configure the deployment
deployment = ManagedOnlineDeployment(
name=f"dp-{datetime.now():%y%m%d%H%M%S}", # Add the current time to make it unique
endpoint_name=endpoint.name,
model=None,
environment=environment,
instance_type=INSTANCE_TYPE,
instance_count=1, # we only use 1 instance
)
# create the online deployment.
# Note that this takes approximately 8 to 10 minutes.
# This is a limitation of Azure. We cannot speed it up.
ml_client.online_deployments.begin_create_or_update(deployment).result()
Jetzt, wo wir unser Deployment erstellt haben, sollten wir testen, ob es funktioniert!
Führen Sie Smoke-Tests durch, um zu sehen, ob die Bereitstellung funktioniert.
Beim Smoke-Testing wird geprüft, ob Sie eine Bereitstellung akzeptieren oder ablehnen können. Dies passt zur Blue-Green-Bereitstellung, denn wir können unsere neue Bereitstellung testen, bevor wir den gesamten Datenverkehr darauf umstellen. Dadurch wird sichergestellt, dass alles funktionsfähig bleibt.
Testen Sie die Bereitstellung
Wo Rauch ist, ist auch Feuer. Schauen wir also, ob unser Einsatz wie erwartet funktioniert! Wir werden Folgendes tun: 1. Wir rufen die Endpunkt-URI ab 2. Wir rufen das Endpunkt-Token ab, das wir zur Authentifizierung verwenden 3. Wir setzen die Anfrage-Header mit dem Token und dem Bereitstellungsnamen (wenn wir das nicht tun, wird die Anfrage an die Standardbereitstellung weitergeleitet) 4. Wir erstellen einige Testdaten, die der erwarteten Eingabe unserer FastAPI-Anwendung entsprechen 5. Wir senden eine Anfrage mit den Daten an den Endpunkt unter Verwendung der httpx-Bibliothek
import httpx
test_data = {"values": [[0, 1], [1, 2]]}
endpoint_token = ml_client.online_endpoints.get_keys(name=endpoint.name).primary_key
headers = {
"Authorization": f"Bearer {endpoint_token}",
"Content-Type": "application/json",
"azureml-model-deployment": deployment.name,
}
response = httpx.post(endpoint.scoring_uri, json=test_data, headers=headers)
Wir haben unsere Anfrage abgeschickt und eine Antwort erhalten. Jetzt können wir überprüfen, ob sie den Erwartungen entspricht:
Validieren Sie die Antwort
httpx bietet eine Methode raise_for_status, die eine Ausnahme auslöst, wenn die Antwort nicht erfolgreich ist:
response.raise_for_status()
Dieser Code wird unser Programm auch zum Absturz bringen, wenn die Antwort fehlschlägt. Das ist nicht das, was wir wollen, denn dadurch bleibt die fehlgeschlagene Bereitstellung aktiv. Um dieses Problem zu lösen, können wir einen try-except-Block hinzufügen, um die Ausnahme abzufangen und die Bereitstellung zu löschen, wenn sie fehlschlägt. In diesem Fall können wir das Programm auch beenden, da wir nicht mehr weiterkommen.
try:
response.raise_for_status()
except Exception:
# When our test fails, we delete the deployment and stop the program
print(f"Endpoint response error {response.status_code}: {response.text}")
# Retrieve the logs for the failed deployment, so we can see what happened
logs = ml_client.online_deployments.get_logs(
name=deployment.name, endpoint_name=endpoint.name, lines=50
)
print(logs)
# Delete the failed deployment
ml_client.online_deployments.begin_delete(
name=deployment.name, endpoint_name=endpoint.name
).result()
# Quit the program
raise SystemExit("Deployment failed.")
Leiten Sie den Verkehr auf die neue Bereitstellung um
Wenn unsere neue Bereitstellung wie erwartet funktioniert, können wir 100 % des Endpunktverkehrs auf sie umleiten. Wir können dies wie folgt tun:
endpoint.traffic = {deployment.name: 100}
ml_client.online_endpoints.begin_create_or_update(endpoint).result()
Alte Einsätze löschen
Nachdem der gesamte Datenverkehr auf die neue Bereitstellung umgestellt wurde, können wir alle unsere alten Endpunkte löschen. Natürlich können Sie sie auch behalten, wenn Sie eine Ausweichlösung für unvorhergesehene Probleme mit Ihrer neuen Bereitstellung haben möchten.
Löschen Sie Ihre alten Bereitstellungen:
for existing_deployment in ml_client.online_deployments.list(endpoint_name=endpoint.name):
if existing_deployment.name != deployment.name:
ml_client.online_deployments.begin_delete(
endpoint_name=endpoint.name,
name=existing_deployment.name
).result()
Schreiben Sie eine Befehlszeilenschnittstelle (CLI), um Ihren Endpunkt einzusetzen.
Bis jetzt wird der gesamte Code, den wir geschrieben haben, manuell ausgeführt. Im Geiste von MLOps sollten wir diesen Prozess automatisieren. Wir können dies tun, indem wir ein CLI-Skript erstellen, das Argumente entgegennimmt und unseren Endpunkt mit einem Befehl bereitstellt. Dieses CLI kann in unsere CI/CD-Pipeline integriert werden, z. B. in Github Actions oder Azure DevOps Pipelines.
Wir verwenden argparse zu verwenden. Wir haben uns für argparse entschieden, weil 1) unsere CLI einfach ist und 2) argparse in Python integriert ist, so dass keine Installation erforderlich ist. Das spart Zeit, vor allem wenn wir das Skript in unserer Deployment-Pipeline häufig wiederholen, da Abhängigkeiten oft neu installiert werden müssen.
Wir richten unser Argument-Parsing wie folgt ein:
import argparse
arg_parser = argparse.ArgumentParser(description="Deploy an Azure ML endpoint and deployment.")
arg_parser.add_argument("--subscription-id", type=str, required=True, help="Azure subscription ID")
arg_parser.add_argument("--resource-group", type=str, required=True, help="Azure resource group name")
arg_parser.add_argument("--workspace-name", type=str, required=True, help="Azure ML workspace name")
arg_parser.add_argument("--endpoint-name", type=str, required=True, help="Azure ML endpoint name")
arg_parser.add_argument("--acr-name", type=str, required=True, help="Azure Container Registry name")
arg_parser.add_argument("--image-name", type=str, required=True, help="Docker image name")
arg_parser.add_argument("--image-tag", type=str, required=True, help="Docker image tag")
arg_parser.add_argument("--instance-type", type=str, required=True, help="Azure ML instance type")
args = arg_parser.parse_args()
Jetzt können Sie die Variable args verwenden, um auf die Argumente zuzugreifen, die Sie an das Skript übergeben haben. Sie können zum Beispiel args.subscription_id verwenden, um auf die Abonnement-ID zuzugreifen, die Sie an das Skript übergeben haben. Es sieht dann etwa so aus:
python deploy.py
--subscription-id "..."
--resource-group "..."
--workspace-name "..."
--endpoint-name "..."
--acr-name "..."
--image-name "..."
--image-tag "..."
--instance-type "..."
Achten Sie darauf, die richtigen Werte für jedes Argument einzugeben.
Fazit
In diesem Blogpost haben wir es geschafft, eine Menge zu tun:
- Wir haben ein benutzerdefiniertes Docker-Image auf Azure ML bereitgestellt, das uns die volle Kontrolle über die API und die von uns verwendeten Modelle gibt.
- Wir haben Ausfallzeiten unseres Endpunkts vermieden, indem wir eine blau-grüne Bereitstellungsstrategie verwendet haben.
- Wir haben das Azure ML Python SDK verwendet, um die Bereitstellung auf Azure ML zu konfigurieren und zu verwalten, was es einfacher macht, über unsere Bereitstellung nachzudenken.
- Wir haben eine Befehlszeilenschnittstelle entwickelt, die unseren Endpunkt mit einem einzigen Befehl für die Verwendung in CI/CD-Pipelines bereitstellt.
Wir hoffen, dass Ihnen dieser Blogpost gefallen hat!
Foto von Ivan Bandura auf Unsplash
Verfasst von
Timo Uelen
Timo Uelen is a Machine Learning Engineer at Xebia.
Unsere Ideen
Weitere Blogs




Contact