
It’s been a year since the announcement of the dbt-flink-adapter, and the concept of enabling real-time analytics with dbt and Flink SQL is simply brilliant. The dbt-flink-adapter enables the construction of Flink SQL jobs using DBT models with declarative SQL and runs them via the Flink SQL Gateway. It’s an excellent tool for code modularization, versioning and prototyping. You can learn more about how it works and how to use it here. The latest version 1.3.11 introduces a new feature that also facilitates the maintenance of Flink jobs’ lifecycle in session clusters. This feature fills the gap between prototyping, testing, and deploying across multiple environments.
In diesem Artikel werde ich die zentrale Rolle des dbt-flink-adapters bei der Umwandlung von Datenströmen durch die Integration der SQL-Modelle von dbt mit Flink SQL untersuchen. Wir erfahren, wie dieser Adapter die Analysen verbessert und die Verwaltung der Lebenszyklen von Datenaufträgen rationalisiert und einen einfacheren Weg von der Entwicklung bis zur Bereitstellung bietet. Entdecken Sie die praktischen Vorteile und die neuesten Verbesserungen des dbt-flink-adapters, die Ihre Datenoperationen und die Effizienz Ihrer Arbeitsabläufe erheblich verbessern können.
Hinter den Kulissen von dbt-flink-adapter
Wenn Sie den Befehl dbt ausführeneingeben, wird das Projekt in eine SQL-Anweisung umgewandelt und über die Rest-API an das Flink SQL Gateway gesendet. Daraufhin wird ein neuer Auftrag im Sitzungsmodus erstellt. Wenn Sie denselben Befehl erneut ausführen, wird eine zweite Instanz des Auftrags erstellt. Flink versucht nicht, den Job zu stoppen und einen neuen zu erstellen; das liegt nicht in seiner Verantwortung.
Der Flink SQL Client (ab Version 1.17) unterstützt Anweisungen wie SHOW JOBS und STOP JOB. Damit können Sie alle Jobs im Sitzungscluster auflisten und jeden von ihnen stoppen. Wenn Sie Hilfe bei der Identifizierung des Jobs benötigen, übernimmt der dbt-flink-adapter diese Aufgabe für Sie!
Identifizieren Sie den Job
Der dbt-flink-adapter verarbeitet zwei Arten von materialisierten Eigenschaften des Modells: Ansicht und Tabelle. Die erste hilft bei der Organisation des Codes. Wenn Sie sie ausführen, wird einfach eine temporäre Flink-Ansicht erstellt. Die zweite, 'table', ist für die Auslösung des Auftrags verantwortlich. Lassen Sie uns die 'materialisierte Tabelle' in der Datei model.yml konfigurieren:
version: 2
models:
- name: high_loan
config:
materialized: table
upgrade_mode: stateless
job_state: running
execution_config:
pipeline.name: high_loan
parallelism.default: 1
connector_properties:
topic: 'high-loan'Sie werden einige neue Eigenschaften in der Konfiguration bemerken (fett gedruckte Werte sind Standardwerte):
- upgrade_mode(stateless, savepoint) - bestimmt, ob der Auftrag mit savepoint angehalten werden soll.
- job_state(running, suspended) - ermöglicht es Ihnen, den Auftrag anzuhalten/zu starten.
- execution_config - Konfiguration des Flink-Auftrags. Sie können jede unterstützte SQL Client-Schlüsselwerteigenschaft einstellen.
- pipeline.name - Auftragsname. Dieser wird verwendet, um die job_id mithilfe der Anweisung SHOW JOBS aufzulösen. Halten Sie sie innerhalb des Flink-Session-Clusters eindeutig. Sie ist erforderlich, um den Job mit dbt-flink-adapter zu verwalten.
- parallelism.default - Auftragsparallelität (als Beispiel für alle anderen Konfigurationseigenschaften).
Bitte beachten Sie, dass Sie in der Datei dbt_project.yml Standardwerte für alle Ihre Modelle konfigurieren und diese in der Datei model.yml außer Kraft setzen können.
Aktualisieren Sie den Job
Sobald Sie den pipeline.name festgelegt haben, wird der dbt-flink-adapter versuchen, den Auftrag zu identifizieren und anzuhalten. Wenn Sie upgrade_mode einstellen, wird der Job mit einem Savepoint angehalten. Der erstellte Speicherpunkt wird dann verwendet, um den Zustand des neuen Auftrags wiederherzustellen.
Außerdem können Sie den Auftrag aussetzen, indem Sie job_state auf suspended setzen.
Die Logik für das Upgraden des Auftrags wird im folgenden Diagramm dargestellt.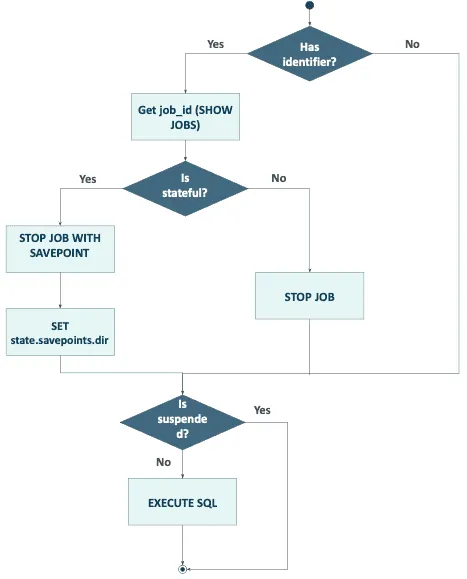
Der dbt-flink-adapter verwendet die Eigenschaft execution_config.state.savepoints.dir bei Job-Upgrades (der Wert des Modells wird überschrieben, wenn der Job läuft). Wenn Sie den Job mit einem bestimmten Speicherpunkt starten möchten, gehen Sie wie folgt vor:
- Halten Sie den Auftrag zunächst an (z.B. setzen Sie job_state + dbt run oder brechen Sie ihn in der Flink-Benutzeroberfläche ab).
- Setzen Sie execution_config.state.savepoints.dir mit dem richtigen Pfad.
- Starten Sie den Auftrag (mit dbt run).
Der dbt-Adapter führt zwei Arten von Anweisungen aus: CREATE VIEW und CREATE TABLE AS. Beide Strukturen werden im Flink-Speicher erstellt, gelöscht und dann während des Job-Upgrades neu erstellt.
Vorteile
- Dbt und Git sind eine hervorragende Kombination für die SQL-Versionierung. Sie erleichtern das Testen Ihrer Pipelines, die Pflege von gut strukturiertem Code und die Trennung von Konfigurationen.
- Mit dem dbt-flink-adapter können Sie CI/CD-Pipelines einfach implementieren und Streaming- (oder Batch-) Aufträge über mehrere Umgebungen hinweg verwalten.
- Im Gegensatz zu Prozessen, die das Erstellen von Jars oder Docker-Images und die Verwaltung der Bereitstellung beinhalten, vereinfacht es die Handhabung des Auftragsstatus und die Konfiguration.
dbt bietet viel mehr
Dbt ist ein unverzichtbarer Helfer, wenn Sie automatisierte Bereitstellungstests benötigen. Alles, was Sie tun müssen, ist die Ausführung der
Datenherkunft? Kein Problem . Dbt kann gerichtete azyklische Graphen (DAGs) und Dokumentationen erstellen, die die Transformationen zwischen Quellen und Modellen veranschaulichen. Außerdem kann Dbt Ihren Daten Metadatenfelder hinzufügen. Benötigen Sie detailliertere Datenabgleichsfunktionen, z.B.
Dbt überbrückt die Kluft zwischen der technischen und der nichttechnischen Welt. Alles, was Sie wissen müssen, ist SQL und YAML, um ETLs zu schreiben und zu veröffentlichen. Außerdem können Sie mit dem dbt-flink-adapter auf die gleiche Weise Streaming-Pipelines erstellen!
Aktueller Stand
Dies ist ein erster Versuch, die Lebenszyklen von Aufträgen mit dbt und Flink SQL Gateway zu verwalten. Es ist zwar leichtgewichtig und zustandslos, aber es fehlt ihm an Robustheit. Es besteht die Gefahr, dass der Auftragsfortschritt verloren geht, wenn die Bereitstellung zwischen internen Schritten wie dem Anhalten mit einem Speicherpunkt und dem erneuten Starten des Auftrags fehlschlägt. Außerdem hilft der dbt-flink-adapter nicht, wenn Ihr Flink Session-Cluster Probleme hat. Es gibt keinen Mechanismus zur automatischen Wiederherstellung von Aufträgen ab dem letzten Savepoint.
Außerdem hat die Arbeit mit Flink SQL ihre Tücken. Das Upgraden von zustandsabhängigen Aufträgen kann knifflig sein und ist manchmal nicht machbar. So ist es in Flink beispielsweise nicht möglich, die UID des Operators über SQL zu setzen. Eine Änderung der SQL-Anweisung, die vom zustandsbehafteten Operator verarbeitet wird oder mit ihm verkettet ist, kann zu einem Fehlschlag führen.
Nächste Schritte
Aufgrund des zustandslosen Charakters von dbt-adapter und des zustandsorientierten Charakters von Flink-Jobs gibt es einige Einschränkungen. Der Auftrag wird nicht vom letzten Speicherpunkt aus wiederhergestellt, wenn Sie ihn anhalten und im nächsten Schritt wieder ausführen. Diese und die anderen Einschränkungen können durch das Speichern von Speicherpunktpfaden in einer externen Datenbank gelöst werden.
Zusammenfassung
Mit dem Dbt-flink-adapter können Sie Ihr Abenteuer mit Flink SQL beginnen und Ihre Pipelines einfach erstellen und bereitstellen. Mit der neuen Funktion können Sie sie mit Ihren CI/CD-Pipelines verwenden und den Lebenszyklus eines Auftrags in mehreren Umgebungen verwalten. Der Start von Streaming war noch nie so einfach!
Verfasst von
Maciej Maciejko
Unsere Ideen
Weitere Blogs




Contact