Blog
Data-Pipeline-Komponenten sind ganz normale Anwendungen

Eine Datenpipeline-Komponente ist nichts anderes als eine normale Anwendung
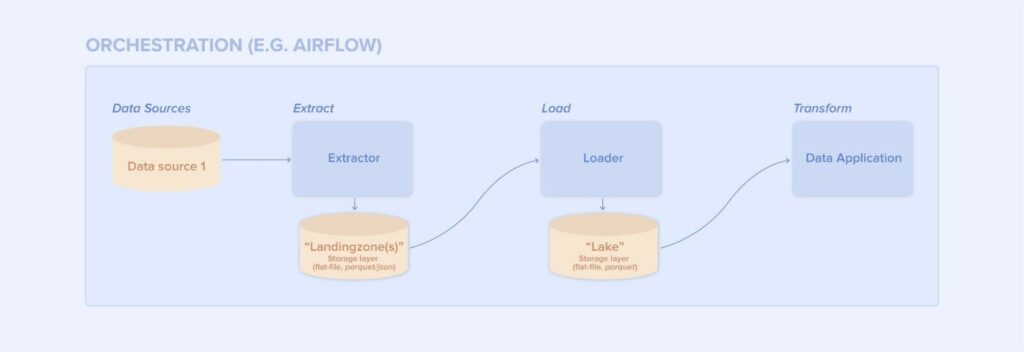
Abb. 1. Beispiel einer Daten-Pipeline: ELT
Sie durchläuft den gleichen Lebenszyklus wie jede andere Anwendung: Die Komponente wird entwickelt und getestet, ein Artefakt wird erstellt und schließlich wird es bereitgestellt. Das Artefakt wird dann als Teil Ihrer Datenpipeline ausgeführt. Dabei verwendet die Anwendung normale Anwendungsentwicklungsprozesse wie:
- CI/CD
- Alle Schritte in der Pipeline werden wie eine normale Anwendung ausgeführt, so dass für jeden von ihnen ein Artefakt erstellt und getestet werden muss. Dies kann auf dieselbe Weise geschehen wie bei jeder anderen Anwendung, d.h. Sie erstellen ein (Docker-)Image, führen Tests durch und verteilen alle Ressourcen, die verteilt werden müssen.
- Überwachung, Dashboarding und Alarmierung
- Nutzen Sie die vorhandene Infrastruktur für Überwachung und Dashboarding. Die meisten Kubernetes-Cluster verfügen über etwas wie Promotheus, um Metriken zu sammeln. Alle Ihre Datenpipeline-Komponenten können damit integriert werden, so dass die Metriken auf die gleiche Weise verfügbar sind wie bei allen anderen Anwendungen, die auf dem Cluster laufen. Auf diese Weise können Sie dieselbe Dashboarding- und Alarmierungslösung nutzen wie alle anderen Teams in Ihrem Unternehmen.
Die Anwendung selbst nutzt und baut auf gängigen Anwendungsbausteinen wie:
- Berechnen Sie
- Der von uns bevorzugte Modus Operandi ist die Ausführung von Aufträgen auf Kubernetes. Dies bietet aus Sicht der Plattform eine Menge Vorteile.
- Lagerung
- Jeder der Pipelineschritte ist für die Speicherung seiner eigenen Ausgabe verantwortlich. Speichern Sie diese Ausgabe getrennt von den Berechnungen, in der Regel auf einem Blob-Speicher.
- Konnektivität zu anderen Systemen/Datenquellen
- Nutzen Sie die vorhandene Konnektivität der Plattform zu anderen lokalen oder Cloud-basierten Systemen und entwickeln Sie keine eigenen Konnektivitätslösungen für Ihre Anwendungen.
- Nicht-Funktionale
- Skalierbarkeit
Der Ressourcenverbrauch der Datenpipeline-Prozesse ist im Allgemeinen vorhersehbar. Daher ist es in den meisten Fällen nicht notwendig, Zeit in die Skalierung der einzelnen Extraktoren oder Lader zu investieren. Es ist jedoch von Vorteil, den zugrunde liegenden Kubernetes-Cluster zu skalieren, um die Kosten zu senken. Dies ermöglicht es auch, alle Datenpipeline-Prozesse in kürzerer Zeit abzuschließen.
- Verlässlichkeit
Da wir Pods auf einem Kubernetes-Cluster betreiben, können wir die üblichen Kubernetes-Mechanismen nutzen, um die Zuverlässigkeit zu gewährleisten. Denken Sie an die Festlegung von Ressourcenanforderungen und -grenzen, Budgets für Pod-Unterbrechungen, Wiederholungen usw.
- Tragbarkeit
Da unser Artefakt nur ein Docker-Image ist, kann es überall ausgeführt werden. Sie können es lokal oder auf CI/CD zu Validierungszwecken ausführen oder es auf einem beliebigen Cluster zur Validierung oder für die Produktion verwenden
- Sicherheit
Wenden Sie auf Ihre Datenpipeline-Komponenten das Prinzip der geringsten Rechte an. Ein Extraktor sollte die einzige Komponente sein, die Zugang zu den Anmeldeinformationen für ein Quellsystem hat und eine Verbindung zu diesem herstellen kann. Auf der anderen Seite sollte ein Loader die einzige Komponente sein, die Daten in Ihren Data Lake schreiben darf. Die übrigen Komponenten sollten keinen Zugriff auf die Daten in Ihrem Lake haben.
- Nutzen Sie Kubernetes-Servicekonten, die an Cloud-Provider-Servicekonten gebunden sind, und verwalten Sie die Berechtigungen für die Cloud-Provider-Servicekonten.
In einigen Fällen ist es zwingend erforderlich, die ausgelagerten Daten auf Anomalien zu überprüfen.
Verwenden Sie separate Namespaces zur Isolierung.
- Instandhaltbarkeit
Verwenden Sie gemeinsam genutzten Code/Bibliotheken für Code, den Sie wiederverwenden möchten.
...mit mehr Fokus auf einige Bereiche
Einige der Bausteine und Prozesse sind bei einer normalen Anwendung und einer Data-Pipeline-Komponente identisch. Es kann jedoch notwendig sein, sich mehr auf bestimmte Bereiche zu konzentrieren. Das liegt vor allem an den inhärenten Herausforderungen der Datendomäne wie dem großen Datenvolumen und der Tatsache, dass Datenanwendungen oft in Stapeln ausgeführt werden und sich alles um die (Verarbeitung) der Daten dreht, anstatt um die Anwendung selbst. Beispiele hierfür sind:
- Nutzen Sie die Skalierbarkeit der Plattform für Ihre ressourcenintensiven Anwendungen. Dies kann für die Datenplattform erhebliche Kostenvorteile mit sich bringen, da Datenanwendungen, die in Stapeln ausgeführt werden, oft einen hohen Ressourcenbedarf haben. Stellen Sie sicher, dass wichtige Aufgaben auf Knoten geplant werden, die nicht einfach verschwinden, damit sie sicher ausgeführt werden können, ohne getötet zu werden.
- Da das Datenvolumen recht groß ist, nutzen Sie den Blob-Speicher der Plattform, um die Daten zu speichern. Dies ist in der Regel sehr viel kostengünstiger als andere Möglichkeiten zur Speicherung dieser großen Datenmengen.
- Wenn Sie Wert auf Qualität und Konsistenz legen, stellen Sie sicher, dass Sie die eingehenden Daten validieren, zum Beispiel anhand eines Schemas, das Teil der Anwendungskonfiguration ist.
- Schreiben Sie Metriken über die von der Anwendung verarbeiteten Daten, um Einblicke zu gewinnen und die Überwachung Ihrer Pipeline zu ermöglichen. Wenn Ihre Datenpipelines in Batches laufen, sollten Sie sicherstellen, dass die Informationen darüber, für welchen Batch die Pipeline ausgeführt wurde, in diese Metriken aufgenommen werden.
...und einige zusätzliche Funktionen
Und schließlich gibt es Funktionen, die nur für eine Datenplattform gelten. Wir bemühen uns, diese auf ein Minimum zu beschränken. Es gibt jedoch einige Ausnahmen, wie zum Beispiel die Registrierung der Daten, die von jeder Anwendung im Datenkatalog erzeugt werden.
Abschließende Gedanken
Betrachten Sie Ihre Datenpipeline-Komponenten als nichts anderes als eine normale Anwendung mit einigen zusätzlichen Funktionen, um sie an die Anforderungen der Datendomäne anzupassen. Das Wissen über normale Anwendungen und ihre Bausteine hilft Ihnen bei der Arbeit an Ihren Datenpipelines. Behalten Sie die Grundprinzipien im Auge und fügen Sie bei Bedarf datenspezifische Funktionalitäten hinzu. Dies sollte Ihr Weg zu einer erfolgreichen Datenpipeline sein.
Wenn Sie mehr darüber erfahren möchten, wie Sie die Daten Ihres Unternehmens optimal nutzen können, sehen Sie sich unsere anderen Ressourcen an:
- DevOps für Datenwissenschaft - Xebia
- Eine Datenplattform ist nur eine normale Plattform - Xebia Blog
- DevOps in einer Welt der Datenwissenschaft - Xebia Blog
- Webinar: DevOps in einer Welt der Datenwissenschaft - Xebia
Behalten Sie auch unseren Kalender im Auge, denn im Jahr 2022 Q1/Q2 werden wir eine weitere kostenlose Data Breakfast Session veranstalten.
Verfasst von
Marcel Jepma
Unsere Ideen
Weitere Blogs




Contact