
Viele Unternehmen haben den Ehrgeiz, ein datengesteuertes Unternehmen zu werden. Im Wesentlichen bedeutet dies, dass die Organisation bessere Geschäftsentscheidungen auf der Grundlage von Erkenntnissen treffen möchte, die von Daten geliefert werden [4]. Daten allein sind nicht in der Lage, ein Unternehmen bei der Entscheidungsfindung zu unterstützen. Deshalb führen diese Unternehmen eine neue Fähigkeit ein: Daten & Analytik.
In diesem Blog erfahren Sie, wie die Einführung von DevOps-Prinzipien die Wertschöpfung in der Welt der Daten und Analysen verbessern kann.
Daten & Analytik sollten in der Lage sein, dem Unternehmen Einblicke zu gewähren, damit es bessere Geschäftsentscheidungen treffen kann. Oder in der (nahen) Zukunft sollte Advanced Data & Analytics das Geschäft optimieren, indem es eigene Entscheidungen trifft und das Geschäft, das es unterstützt, automatisch verbessert.
Daten & Analytik als eigenständiger Unternehmensbereich
Unternehmen unterscheiden oft zwischen verschiedenen Geschäftsbereichen, z. B. Vertrieb, Marketing, Finanzen usw. Jeder Geschäftsbereich benötigt für seinen Betrieb seine eigenen IT-Systeme. Wir sehen, dass Data & Analytics zunächst als separater (Geschäfts-)Bereich eingeführt wurde, der eigene IT-Systeme für den Betrieb benötigt (z.B. eine Data & Analytics-Plattform). Diese Data & Analytics-Domäne hat die Aufgabe, Erkenntnisse über Geschäftsbereiche zu liefern und die einzelnen Geschäftsbereiche bei ihrem Bedarf an "Erkenntnissen" zu unterstützen. In der Praxis tun sich viele Unternehmen schwer mit der Umsetzung des Teils 'erleichtern'. Oft bedeutet "erleichtern" "die Erkenntnisse implementieren und betreiben" für die verschiedenen Geschäfts- und Produktteams.
Ein Beispiel zur Veranschaulichung dessen, was in der Praxis oft passiert: Ein Datenwissenschaftler aus einem Geschäftsteam erstellt ein Analysemodell auf seinem eigenen Laptop und alles funktioniert. Als nächstes bittet der Datenwissenschaftler einen Ingenieur aus dem Bereich Daten & Analytik, das analytische Modell zu 'produzieren'. Die Bitte lautet hier nicht: "Bitte helfen Sie mir, mein Analysemodell in Produktion zu bringen und es danach für mein Unternehmen zu betreiben". Die Anfrage lautet eher wie folgt: ' bitte implementieren Sie eine Insights-Anwendung, die auf der Grundlage meines "Proof of Concept-Analysemodells" in der Produktion laufen kann. Und lassen Sie mich bitte auch wissen, wenn es scheitert". Dieses Beispiel wurde von der DevOps-Community als Problem erkannt. Es ist vergleichbar mit den Herausforderungen der 'normalen' Anwendungsentwicklung, bei der (Business,) IT-Entwicklung und IT-Betrieb getrennt sind.
Im Idealfall bedeutet "die einzelnen Geschäftsbereiche bei der Deckung ihres Bedarfs an Erkenntnissen unterstützen", dass die einzelnen Geschäftsbereiche in der Lage sind, ihren eigenen Bedarf an Daten und Erkenntnissen selbst zu decken. Der Bereich Daten & Analytik muss ihnen dies nur ermöglichen, indem er ihnen die Mittel zur Verfügung stellt, wie z.B. eine Datenplattform, Richtlinien für die Datenverwaltung, einen Entwicklungsprozess für fortgeschrittene Analysemodelle usw... Leider spiegelt der ideale Aufbau in vielen Unternehmen nicht die Realität wider. Lassen Sie uns zunächst kurz die Welt der Data Science erkunden und besser verstehen, warum DevOps helfen kann.
Die Welt der Datenwissenschaft und fortgeschrittenen Analytik
Data Science and Advanced Analytics umfasst eine Reihe von Prinzipien, Problemdefinitionen, Algorithmen und Prozessen zur Extraktion von nicht offensichtlichen und nützlichen Mustern aus großen Datensätzen [1]. Der Schwerpunkt der Datenwissenschaft liegt auf der Verbesserung der Entscheidungsfindung durch die Analyse von Daten [1]. Diese Datenanalyse wird in sogenannten (fortgeschrittenen) Analysemodellen festgehalten.
Typische Anwendungsfälle sind:
- Clustering (oder Segmentierung): Extrahieren Sie Muster, die helfen, Gruppen von Kunden zu identifizieren, die ein ähnliches Verhalten und einen ähnlichen Geschmack aufweisen;
- Erkennung von Anomalien (oder Ausreißern): Extrahieren Sie Muster, die seltsame oder abnormale Ereignisse identifizieren, wie z. B. betrügerische Versicherungsansprüche;
- Assoziationsregel-Mining: Extrahieren Sie ein Muster, das Produkte identifiziert, die häufig zusammen gekauft werden;
- Vorhersage (einschließlich der Unterprobleme Klassifizierung und Regression): Identifizierung von Mustern, die uns helfen, Dinge zu klassifizieren, z. B. SPAM-E-Mails zu erkennen.
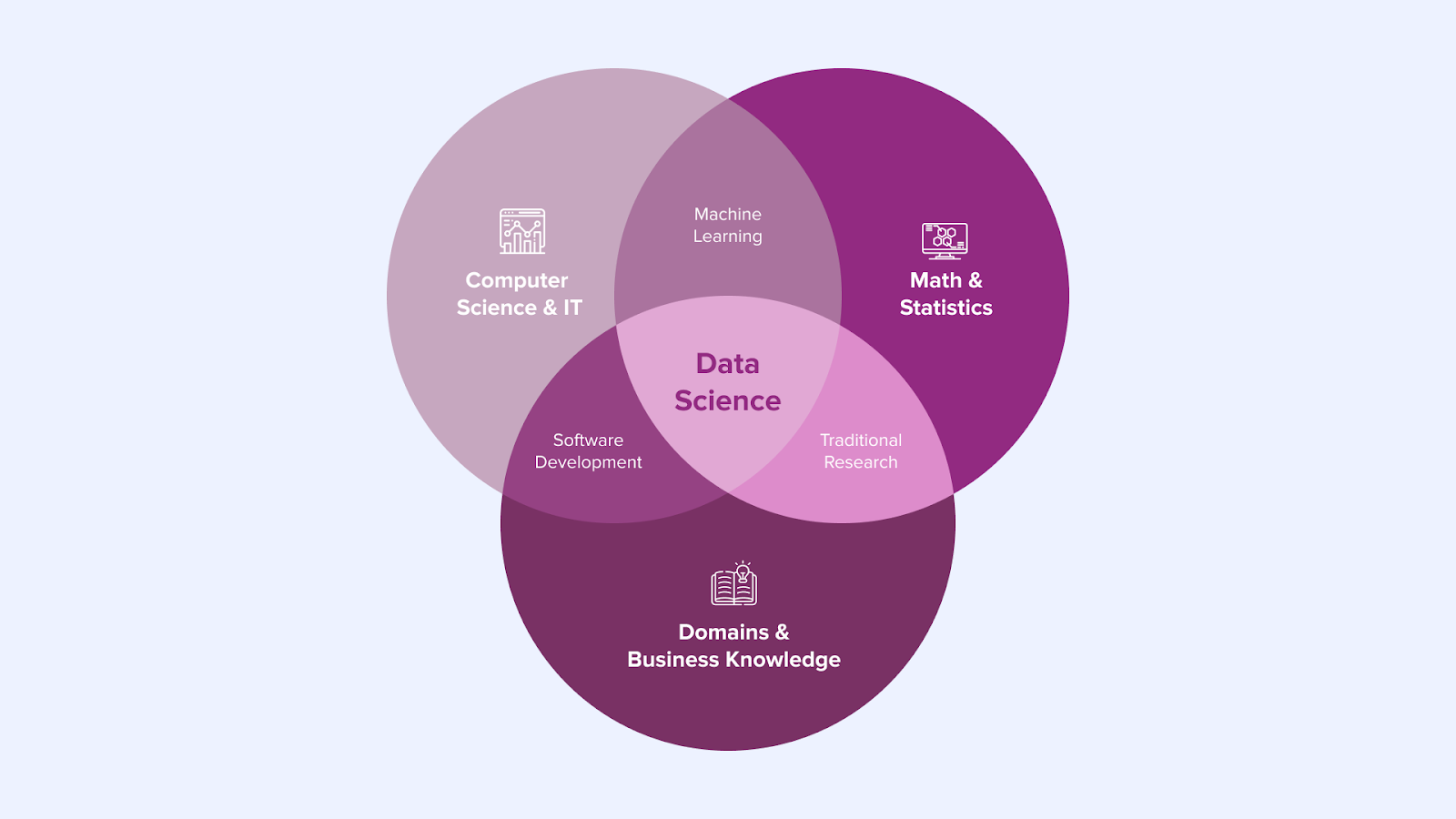
Abbildung 1
Abbildung 1 zeigt die Fähigkeiten eines typischen Datenwissenschaftlers. In der Praxis sind die Fähigkeiten in den Bereichen 'Mathematik & Statistik' und 'Domänen & Geschäftswissen' gut. Die Fähigkeiten in den Bereichen 'Informatik und IT' sind für den Teil des maschinellen Lernens in Ordnung, aber die Softwareentwicklungsfähigkeiten eines Datenwissenschaftlers konzentrieren sich auf die Erstellung des fortgeschrittenen Analysemodells. Die Fähigkeiten zur Softwareentwicklung, um ein fortgeschrittenes Analysemodell in die Produktion zu bringen, sind begrenzt. Es wird zu oft angenommen, dass der Bereich Daten & Analytik dies vollständig abdeckt (wie in der Einleitung angesprochen). Und insbesondere die komplexere / prozesslastige Implementierung eines Freigabeprozesses in einer großen Organisation gehört nicht zu den Fähigkeiten eines durchschnittlichen Data Scientist. Dieser Data Scientist ist also nicht in der Lage, das von ihm entwickelte Modell vollständig zu implementieren und zu betreiben.
Was ist DevOps?
Es gibt viele Bedeutungen, die mit dem Begriff DevOps verbunden sind. Wir verwenden die Definition der DevOps Agile Skills Association [2]:
| DevOps ist ein KULTUR- und BETRIEBSMODELL, das die ZUSAMMENARBEIT fördert, um eine leistungsstarke IT zur Erreichung der Geschäftsziele zu ermöglichen. |
Die DevOps-Gemeinschaft begann mit Patrick Debois [3]. Im Wesentlichen zielt sie darauf ab, die (traditionell getrennten) Welten von Entwicklung und Betrieb zusammenzubringen. In vielen großen Unternehmen sind die Anwendungsentwicklung und der Betrieb von Anwendungen getrennt. Dazwischen existiert eine so genannte 'Wand der Verwirrung' (siehe Abbildung 2).
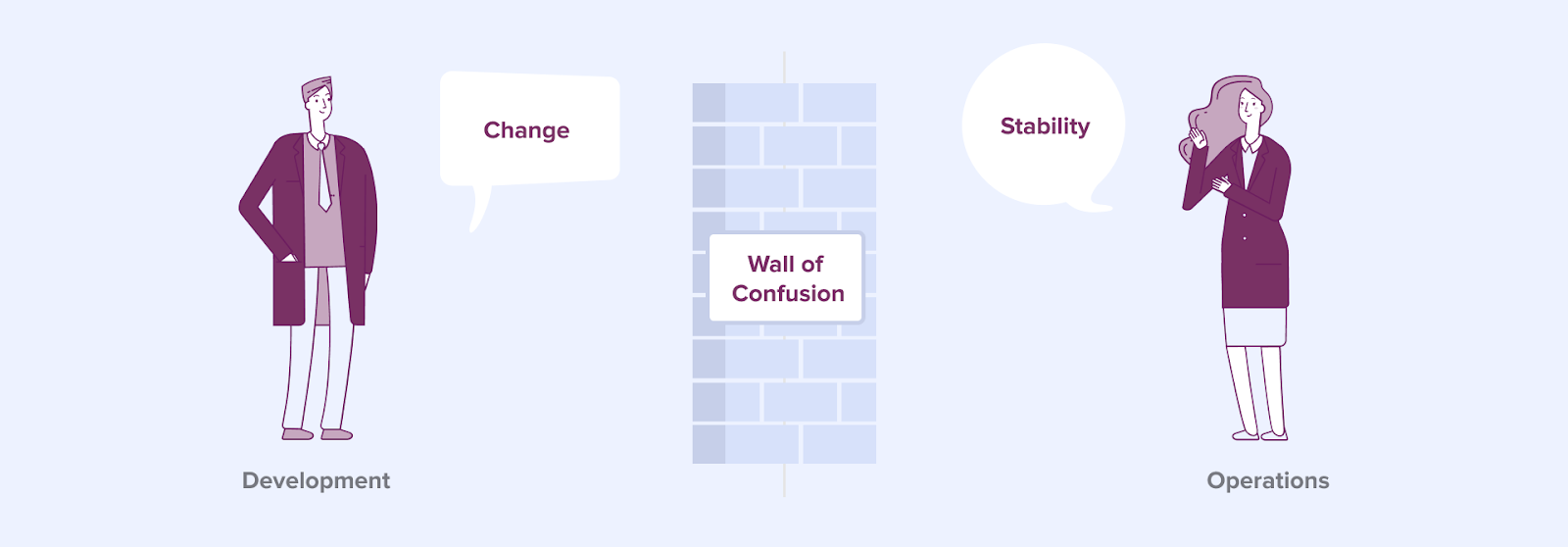
Abbildung 2
Die DevOps-Gemeinschaft ist der Meinung, dass Unternehmen diese Mauer der Verwirrung zwischen Entwicklung (Dev) und Betrieb (Ops) durchbrechen müssen. Wir sehen, dass diese "Mauer der Verwirrung" auch in der Welt der Datenwissenschaft gilt. Data Scientists konzentrieren sich hauptsächlich auf die Entwicklung fortgeschrittener Analysemodelle. Die Überführung fortgeschrittener Analysemodelle in die 'Produktion' und der Betrieb eines in Produktion befindlichen Modells ist nicht Teil ihrer formalen Rolle im Unternehmen. Wie bereits erwähnt, verfügt der durchschnittliche Data Scientist nur über begrenzte Fähigkeiten für diese beiden Tätigkeiten.
Die DevOps Agile Skills Association (DASA) hat 6 Prinzipien definiert, die von einer Organisation, die DevOps einführen möchte, befolgt werden sollten [2]. Diese Prinzipien sind in Abbildung 3 dargestellt.
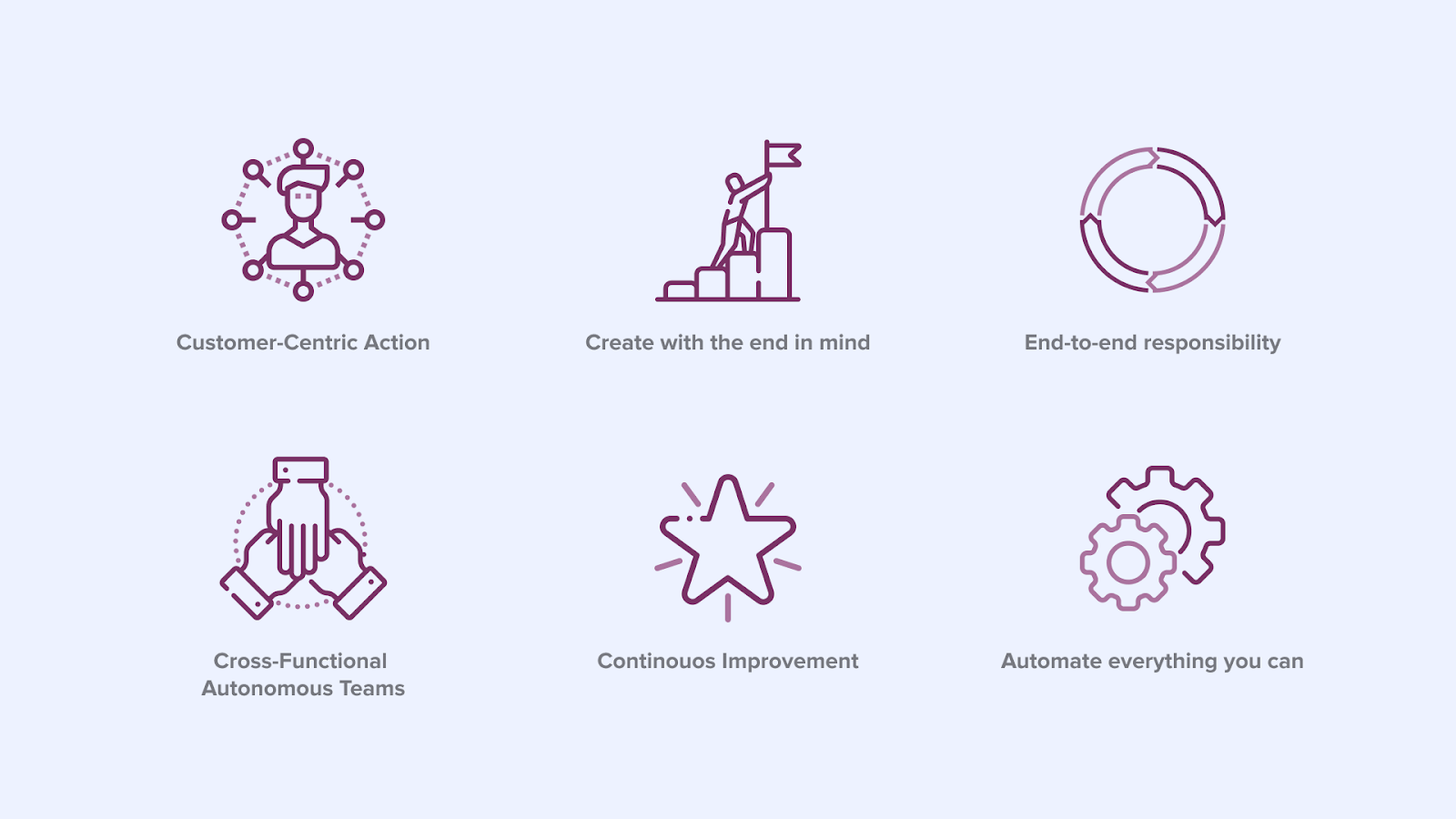
Abbildung 3
Ein Unternehmen, das diese 6 Prinzipien anwendet, wird schneller Geschäftswert liefern usw. (weitere Informationen über die Vorteile der Einführung von DevOps finden Sie unter [4]). Für unseren Anwendungsfall: die Überwindung der Verwirrung zwischen Data Science und dem Betrieb von Datenanwendungen in einem Unternehmen, sind die Prinzipien 3 und 4 am wichtigsten. Auf die Details gehen wir später ein. Zunächst werden die Details der beiden Welten in der Praxis erörtert.
Aktueller Stand der Praxis
Für viele Unternehmen ist 'Advanced Analytics' (also nicht 'traditionelle BI') relativ neu. Nach bewährten Verfahren führen diese Unternehmen Advanced Analytics isoliert ein, in einer so genannten 'Laborumgebung'. Eine solche Laborumgebung weist spezifische Eigenschaften auf, die sich von einer normalen Softwareentwicklungsumgebung in großen Unternehmen unterscheiden. Wir bezeichnen dieses letzte Setting als 'Factory Setting'. Beide Umgebungen haben unterschiedliche Ziele und sind nicht aufeinander abgestimmt. In diesem Fall ist die fortschrittliche Analysefunktion völlig vom Rest des Unternehmens abgekoppelt. Dies ist eine weitere sogenannte Wall of Confusion, wie in Abbildung 4 dargestellt.

Abbildung 4
Die Folgen einer solchen Mauer sind bekannt und in der DevOps-Community weit verbreitet [4]. Zum Beispiel lange Vorlaufzeiten für die Freigabe fortschrittlicher Analysemodelle, viele Iterationen und Übergaben zwischen Data Scientists und Data (Platform) Engineers usw... Dies führt zu einer langsamen Entscheidungsfindung und langsamen Anpassung Ihres Unternehmens auf der Grundlage Ihrer Daten. DevOps (und seine Prinzipien) helfen dabei, beide Welten zusammenzubringen, so wie es bei der Anwendungsentwicklung der Fall war. Deshalb sagen wir:
| Unternehmen errichten oft eine "Mauer der Verwirrung", wenn sie eine fortschrittliche Analysekapazität in ihrer Organisation aufbauen. Diese Mauer der Verwirrung muss durchbrochen werden, um das Ziel zu erreichen, ein datengesteuertes Unternehmen zu werden. |
Eine Daten- und Analyseabteilung in einem großen Unternehmen steht also vor denselben Herausforderungen wie eine 'traditionelle' Anwendungsentwicklungsabteilung. Und sie machen die gleichen Fehler, die die meisten IT-Organisationen bei der Entwicklung von Anwendungen in der Vergangenheit gemacht haben (übrigens haben viele Organisationen immer noch damit zu kämpfen). Lassen Sie uns das genauer erklären, indem wir auf die Labor- und die Werkseinstellung zoomen.
Eigenschaften einer Laboreinstellung im Vergleich zu einer Werkseinstellung
Eine Laborumgebung und eine Fabrikumgebung unterscheiden sich enorm. Tabelle 1 zeigt die wichtigsten Unterschiede zwischen den beiden Einrichtungen.
| Labor Einstellung | Werkseinstellung |
| Volle Freiheit bei der Konfiguration ihrer persönlichen Entwicklungsumgebung. Zum Beispiel: - Neue Bibliotheken können nach Bedarf installiert werden; - Mehrere Versionen von Softwarepaketen können verwendet werden; - Alle Cloud-Dienste können auf persönlicher Basis genutzt werden; - Keine Beschränkungen hinsichtlich der Ressourcen. |
Die Produktionsumgebung hat eine vordefinierte Konfiguration. Zum Beispiel: - Nicht jede Bibliothek darf verwendet werden; - Nur eine Version einer Bibliothek ist verfügbar; - Nur genehmigte Cloud-Dienste sind aktiviert; - Die Ressourcen sind begrenzt. |
| Persönlicher Zugang zu vielen Datenquellen | Begrenzter Zugriff auf Datenquellen über nicht-personenbezogene Konten |
| Keine oder eingeschränkte Compliance-Richtlinien | Strenge Richtlinien zur Einhaltung von VorschriftenEingebettete OrganisationskontrollenVerpflichtende Organisationsintegrationen |
| Kein obligatorischer Lebenszyklus-Management-Prozess (LCM) | Der vorgeschriebene Prozess für das Lebenszyklusmanagement (LCM) muss mit Tests, Validierungen usw. eingehalten werden. |
| Voller Zugriff auf die lokale Laufzeit | Kein manueller / Benutzerzugriff auf Produktions-Workloads |
Tabelle 1 zeigt, dass Data Scientists viel Freiheit bei der Konfiguration ihrer (oft persönlichen) Laborumgebung haben. Diese Freiheit ist bei Produktionsumgebungen in einer Fabrikumgebung nicht gegeben. Ein funktionierendes fortgeschrittenes Analysemodell in einer Laborumgebung ist also keine Garantie dafür, dass dieses Modell auch in der Produktionsumgebung erfolgreich läuft. Aufgrund des unterschiedlichen Charakters der Labor- und der Fabrikumgebung kann die Anfrage eines Data Scientist an den Data Engineer, ein fortgeschrittenes Analysemodell zu produzieren, eine ziemlich arbeitsintensive Tätigkeit mit vielen Iterationen und Übergaben sein. Wenn wir dann noch berücksichtigen, dass es im Bereich Daten & Analytik nur eine begrenzte Anzahl von Data Engineers / Data Platform Engineers gibt und dass es potenziell viele Data Scientists gibt, die Anfragen für mehrere Geschäftsteams bearbeiten, ist es keine Überraschung, dass dieses Setup auch für ein großes Unternehmen nicht skalierbar ist.
Daten & Analytik unter Anwendung von DevOps-Prinzipien
Die Übernahme der DevOps-Prinzipien im Bereich Daten & Analytik bedeutet, die Silos der Labor- und Fabrikumgebung aufzubrechen. Ein professioneller Daten- und Analysebereich sollte eine ausgereifte Entwicklungsumgebung für Data Scientists bereitstellen, die ihnen die Freiheit der Laborumgebung bietet, in der jedoch kein persönlicher Zugriff auf Datenquellen erforderlich ist und in der die vorgeschriebenen LCM-Prozesse und Compliance-Richtlinien bereits out-of-the-box implementiert sind. In einer solchen Situation werden die Data Scientists in den Unternehmensteams entlastet und können die End-to-End-Verantwortung (DevOps-Prinzip 3) für die Erstellung ihrer fortschrittlichen Analysemodelle übernehmen.
Das von der Data & Analytics-Domäne bereitgestellte Self-Service-Modell gibt den Geschäftsteams auch die Möglichkeit, autonom zu arbeiten. Allerdings wird erwartet, dass die Unternehmensteams in ihre Fähigkeiten investieren, um die bereitgestellte Self-Service-Schnittstelle zu verstehen und mit ihr arbeiten zu können. Dies betrifft nicht nur die Schnittstelle für die Entwicklung von Modellen, sondern auch die Tools für den Betrieb ihrer Modelle (DevOps-Grundsatz 4).
Schließlich sollten die Ergebnisse der geschäftsspezifisch entwickelten fortgeschrittenen Analysemodelle (die als Data & Insight Applications bezeichnet werden) auch von dem jeweiligen Geschäftsteam konsumiert werden können. Idealerweise sollten nicht nur die Data & Insight Applications des eigenen Unternehmens, sondern auch die Data & Insight Applications anderer Unternehmensteams konsumierbar sein. Das Serviceportfolio des Bereichs Data & Analytics sollte also beides über ein Self-Service-Modell ermöglichen.
Bereich Serviceportfolio Daten & Analytik
Aus der Sicht des Bereichs Daten & Analyse gibt es 2 Arten von Kunden: Schöpfer und Konsumenten von Insights (siehe Abbildung 6). Beide Typen haben unterschiedliche Bedürfnisse und müssen unterstützt werden. Dies sind die wichtigsten Dienstleistungen, die der Bereich Daten & Analytik für andere Geschäftsbereiche bereitstellen sollte:
- Erstellung von Einblicken und zusammengesetzten Datensätzen
- Eine Self-Service-Umgebung zur Bereitstellung von Daten für Analysen
- Eine Self-Service-Umgebung zum Erstellen und Ausführen fortschrittlicher Analysemodelle
- Eine Self-Service-Umgebung zur Erstellung und Ausführung von Dashboards
- Eine Self-Service-Umgebung zum Veröffentlichen oder Integrieren von erweiterten Analysemodellergebnissen
- Eine Selbstbedienungsschnittstelle zur Überwachung und Bedienung ihrer fortschrittlichen Analysemodelle
- Nutzung von Daten und Einblicken
- Die Fähigkeit, verfügbare Daten und Erkenntnisse zu erkunden
- Die Fähigkeit, Insight-Anwendungen zu konsumieren und zu nutzen
- Die Fähigkeit, zusammengesetzte, vorverarbeitete Datensätze zu konsumieren und zu verwenden
- Möglichkeit des Zugriffs auf vordefinierte Dashboards (Managementinformationen / Serviceberichte / Leistungsberichte usw.)
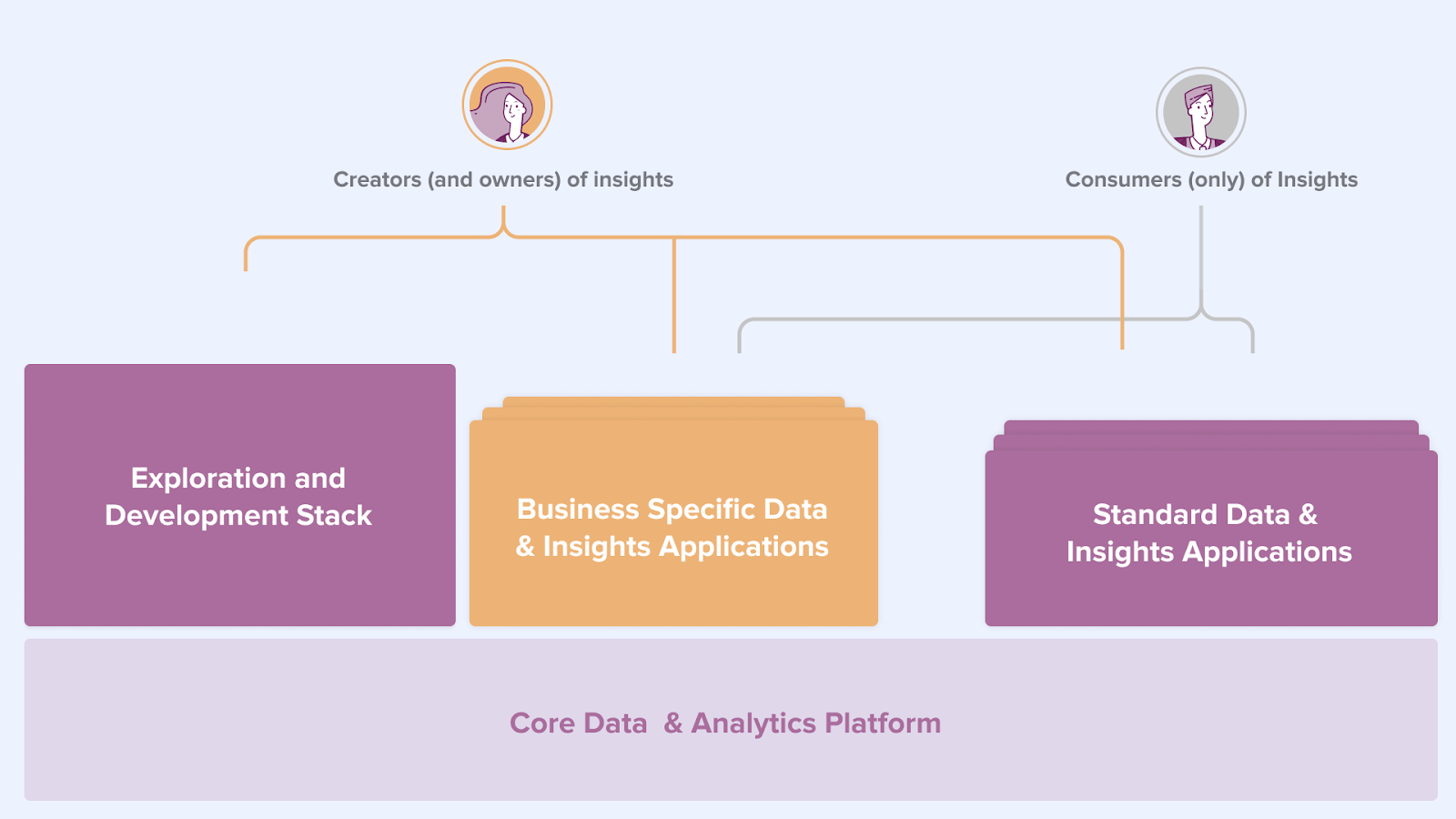
Abbildung 6
Erwartungen Geschäfts- und Produktteams, die Daten und Analysen nutzen
Damit ein Daten- und Analysebereich erfolgreich sein und seine Dienste anbieten kann, muss er mit Daten aus anderen Geschäftsbereichen versorgt werden. In einer datengesteuerten Organisation ist es also zwingend erforderlich, dass die Geschäftsbereiche der Daten- und Analyseabteilung Daten zur Verfügung stellen. Für viele Unternehmen ist dies eine Herausforderung, da die Anforderung "Teilen Sie Ihre relevanten Daten" in der Praxis keine hohe Priorität genießt. Diese Denkweise sollte sich ändern. Erinnern Sie sich daran, dass der Bereich Daten & Analytik den folgenden Service anbieten wird: Eine Self-Service-Umgebung, in der Daten für Analysen zur Verfügung gestellt werden. Aus dieser Perspektive sollte es also kein Hindernis mehr sein, relevante Daten für Analytics freizugeben.
Neben dieser wesentlichen Voraussetzung für die gemeinsame Nutzung von Daten müssen die Geschäftsteams auch Zeit in das Verständnis der (Self-Service-)Umgebung und der Dienste investieren, die für die Überwachung und den Betrieb ihrer Data & Insights-Anwendungen bereitgestellt werden.
Abschließende Bemerkungen
Die isolierte Laborumgebung, in der viele Unternehmen ihre Data-Science-Kapazitäten betreiben, muss durch eine professionelle Data & Analytics-Domäne in Kombination mit ausgereiften Geschäfts- und Produktteams ersetzt werden, die die Data-Science-Funktionen übernehmen. Die Data & Analytics-Domäne wird benutzerfreundliche Self-Service-Dienste für die Nutzung und Erstellung von Daten und Insights bereitstellen. Auf diese Weise werden Data Scientists entlastet und können die End-to-End-Verantwortung für ihre Modelle übernehmen.
Möchten Sie mehr erfahren? Sehen Sie sich DevOps für Data Science an
Referenzen
[1] Data Science - John D. Kelleher und Brendan Tierney
[2] DASA Whitepaper: devopsagileskills.org/dasa-devops-principles/
[3] Geschichte von DevOps von Patrick Debois: Die (kurze) Geschichte von DevOps
[4] DORA: devops-research.com/research.html
Verfasst von
Marco Lormans
Unsere Ideen
Weitere Blogs




Contact