Nur wenige Branchen stehen vor so einzigartigen Herausforderungen wie der eCommerce-Sektor, in dem Unternehmen das hohe Volumen und die Nachfrage nach ihren digitalen Lösungen bewältigen und gleichzeitig die hohen Erwartungen der Kunden erfüllen müssen. Ist es möglich, einen Service zu entwickeln, der alle diese Kriterien erfüllt und gleichzeitig eine praktikable, kosteneffiziente Lösung bietet?
Eines der größeren Probleme im eCommerce ist vielleicht die starke Fluktuation der Aktivitäten. Online-Shops haben tagsüber hohe Besucherzahlen, die nachts jedoch deutlich abnehmen. Bei Sonderverkäufen und anderen aktiven Zeiten kann sich dies jedoch völlig ändern. Jede Onlinelösung muss sich an diese Anforderungen anpassen, doch wenn Sie Ihre eigenen Server für Spitzenkapazitäten vorhalten, führt dies zu vielen Ausfallzeiten und ungenutzten Ressourcen, die dennoch Geld kosten.
Darüber hinaus brauchen die Benutzer auch ein zufriedenstellendes, reibungsloses Erlebnis. Wenn Kunden z.B. bei der Suche oder beim Filtern von Produkten warten müssen, können sie ungeduldig werden und ihren beabsichtigten Kauf nicht abschließen.
Vor diesem Hintergrund war unser Ziel einfach. Wir wollten die aktuellen Grenzen der Branche überprüfen und herausfinden, wie praktikabel es ist, diese gängigen Funktionen mit Serverless Services und DynamoDB in der Cloud zu implementieren. Jede Antwort, die wir geben, musste außerdem skalierbar sein - eine wichtige Voraussetzung für eCommerce-Lösungen. Also beschlossen wir, eine Anwendung zu erstellen, die einem einfachen Webshop ähnelt, der mit dem Serverless-Ansatz aufgebaut ist und alle seine Vorteile nutzt.
Erste Schritte
Um diese Anforderungen zu erfüllen, haben wir uns entschieden, unsere Anwendung mit Lambda und DynamoDB zu implementieren. Dabei handelt es sich um vollständig verwaltete Dienste, die von AWS (Amazon Web Services) bereitgestellt werden, so dass die Integration zwischen ihnen problemlos möglich war und wir uns besser auf die Geschäftslogik und die Implementierung konzentrieren konnten.
AWS Lambda ist eine Funktion als Service, mit der wir Code ausführen können, ohne Server bereitstellen und verwalten zu müssen. Unsere Lösung bestand aus zwei Lambda-Funktionen: eine zum Abrufen von Produkten aus der Datenbank und eine zweite zum Kaufen von Produkten. Letztere war im Wesentlichen für die Aktualisierung der Tabelle mit zusätzlicher Validierung zuständig.
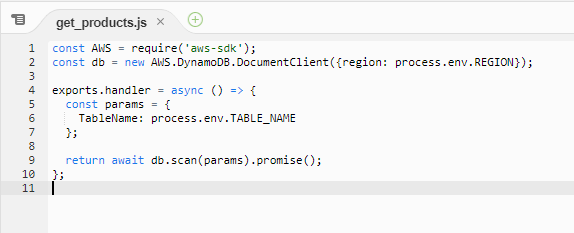
Als Datenbankservice haben wir uns für DynamoDB entschieden, weil es ein vollständig verwalteter Service ist und eine nahtlose und schnelle Skalierbarkeit bietet. Da es sich um einen AWS-Service handelt, konnten wir außerdem das AWS SDK für node.js in Lambda verwenden, um mit ihm zu kommunizieren. Unten sehen Sie, wie einfach es ist, eine solche Kommunikation zwischen Lambda und DynamoDB zu implementieren, was in unserem Fall nur 10 Zeilen Code erforderte.
Sobald die Geschäftslogik unserer Anwendung fertig war, musste sie den Endbenutzern zugänglich gemacht werden. Zu diesem Zweck entschieden wir uns für einen weiteren vollständig verwalteten AWS-Service - API Gateway - der die einfache Erstellung, Veröffentlichung und Pflege von APIs (Application Programming Interface) ermöglicht. In wenigen Minuten konnten wir einen Endpunkt erstellen, der eine Verbindung zu unseren Lambda-Funktionen herstellt und deren Funktionen, wie z. B. die Abfrage von Produkten, zugänglich macht.
Das API Gateway selbst löst unsere Sicherheitsbedenken jedoch nicht, so dass wir einen Mechanismus zur Authentifizierung und Autorisierung unserer Benutzer anwenden mussten. Zu diesem Zweck haben wir AWS Cognito verwendet, mit dem wir einen Authentifizierungsmechanismus erstellen können, der Anmeldungen mit sozialen Identitätsanbietern, SAML und OAuth2 unterstützt. In unserer Anwendung haben wir eine einfache Anmeldefunktion mit unserer eigenen Benutzerbasis, dem so genannten User Pool, in Cognito implementiert und in das API Gateway integriert, indem wir einen Authorizer erstellt und ihn bei der Endpunktkonfiguration als Autorisierung ausgewählt haben.
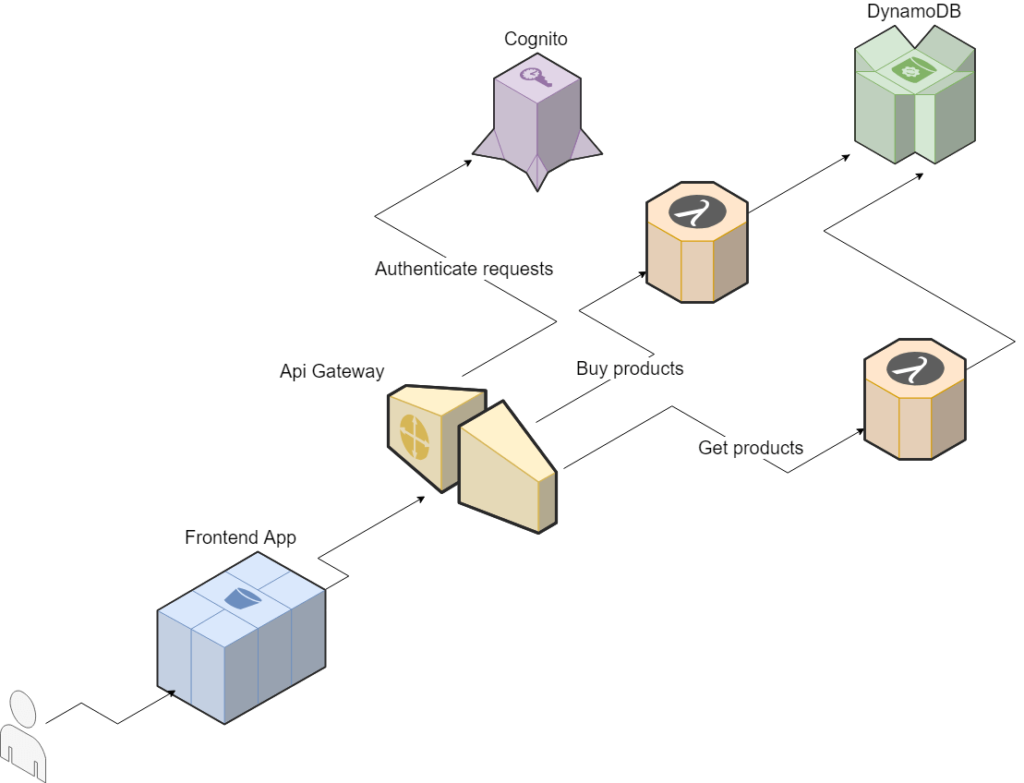
Um die Kommunikation mit unserem Backend zu ermöglichen, haben wir außerdem eine einfache Frontend-Anwendung in Angular erstellt und sie mit Hilfe des statischen Website-Hostings S3 bucket gehostet. S3 ist ein Objektspeicherdienst, der hohe Skalierbarkeit und Verfügbarkeit sowie Sicherheit für die Daten bietet, die wir darin speichern. Außerdem ist S3 sehr kosteneffizient. Wenn wir zum Beispiel 10.000 Benutzer haben, von denen jeder etwa 100 Anfragen pro Tag stellt, kostet uns das nur etwa 1 $.
Damit haben wir dann ein Konto erstellt, mit dem wir unsere API aufrufen können:

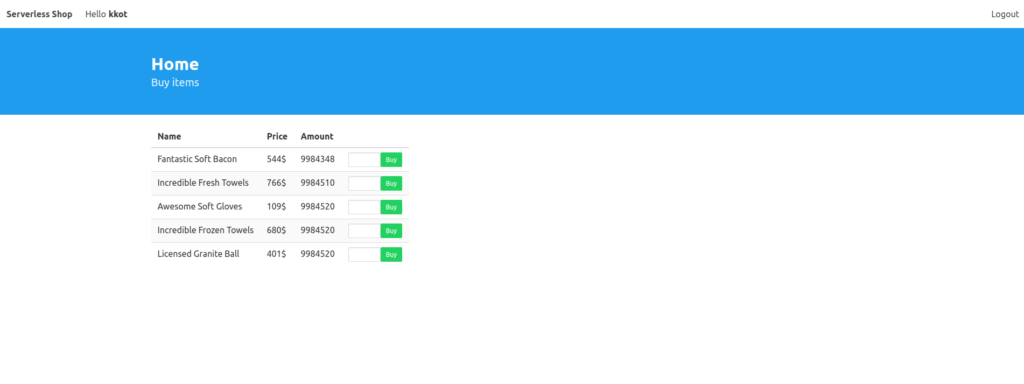
Nachdem dieses Konto erstellt wurde, konnten wir uns anmelden und einen Bildschirm mit einer Liste von Produkten sehen, die alle mit der Option zum Kauf versehen waren. Das Einzige, was wir hier tun müssen, ist, die Anzahl der Produkte, die wir kaufen möchten, einzugeben und auf die Schaltfläche "Kaufen" zu klicken.
Infrastruktur als Code & Der Automatisierungsprozess
Wir haben uns für Infrastructure as Code mit Hilfe von Terraform-Skripten entschieden. Dadurch haben wir die volle Kontrolle über unsere Umgebung auf AWS und können alle Änderungen, die wir vornehmen, planen und überprüfen. Bei der Verwendung von Lambda-Funktionen gibt es keine echte Versionskontrolle für den von uns geschriebenen Code, aber da wir alles in Terraform aufbewahren, einschließlich des Funktionscodes, haben wir auch darüber die Kontrolle.
Außerdem ist der gesamte Bereitstellungsprozess vollständig automatisiert, so dass die Bereitstellung der gesamten Infrastruktur eine Sache von nur zwei oder drei Befehlen ist. Daher müssen Sie sich nicht mehr manuell in die AWS-Konsole einloggen, um beispielsweise Endpunkte in API Gateway zu aktualisieren. Außerdem sparen wir dank der Automatisierung selbst bei einer einfachen Lösung wie der unseren Zeit und Energie und erhöhen gleichzeitig die Produktivität.
Darüber hinaus haben wir ein Bash-Skript erstellt, um die Frontend-Anwendung mit den richtigen Umgebungsvariablen zu erstellen, z. B. der URL zur API oder der ID des Cognito-Benutzerpools, und sie dann im S3-Bucket bereitzustellen.
Backend-Implementierung
Da sich der gesamte JavaScript-Code, der für die Funktionalität unserer Anwendung verantwortlich ist, in Lambda-Funktionen befindet, war es sehr wichtig, dass er so schnell wie möglich ausgeführt wird. Die wichtigste Lambda-Funktion war diejenige, die für den Kauf von Produkten zuständig war. Hierfür mussten wir zusätzliche Arbeit leisten, z. B. überprüfen, ob der Kauf eines bestimmten Artikels überhaupt möglich ist. Glücklicherweise konnten wir dies kurz halten, denn der benötigte Code umfasste nur 26 Zeilen, während die Funktion selbst nicht mehr als 500 Byte groß war.
Ein weiterer Schlüsselfaktor für unseren Erfolg war die blitzschnelle Ausführung der Lambda-Funktion. Das gilt auch für den ersten Start, den sogenannten 'Kaltstart'. Dieser schnelle Start wirkte sich stark auf die Funktion aus und senkte die erforderliche Laufzeit und den Speicher, den wir ihr zuweisen mussten.
Ebenso ist es wichtig zu wissen, dass Lambda nicht nur die Speichernutzung erhöht, sondern auch die verwendete CPU-Leistung proportional ansteigt. Wir haben einige Tests durchgeführt, um die Unterschiede in der Ausführungszeit für verschiedene Speichergrößen zu ermitteln:
| 128 MB | 1024 MB | 2048 MB | |
|---|---|---|---|
| Kaltstart | 850-1100 ms | 100-120 ms | 80-110 ms |
| Nächste Ausführungen | 13-50 ms | 8-40 ms | 6-35 ms |
Wie Sie sehen können, konnte ein Kaltstart bei 128 MB Speicher über 1 Sekunde dauern, was für unsere Bedürfnisse inakzeptabel war, auch wenn die nächsten Ausführungen innerhalb einer zufriedenstellenden Zeit begannen. Wir strebten eine Kaltstart-Ausführungszeit von etwa 100 ms an, was mit 1024 MB zugewiesenem Speicher möglich war.
Leistungstests
Um die Leistung unserer API zu testen, haben wir ein Skript in NodeJS geschrieben, das über einen bestimmten Zeitraum hinweg jede Sekunde eine angemessene Anzahl von Anfragen sendet. Dieses Skript wurde durch eine Datei konfiguriert, die in den S3-Bucket hochgeladen wurde und neben anderen Informationen auch die gewählten Zeiten für den Start dieser Tests enthielt.
Wir haben uns entschieden, dieses Skript von einer EC2-Instanz auf AWS auszuführen. Dazu haben wir ein Tool namens Packer verwendet, um das AMI (Amazon Machine Images) zu erstellen und zu konfigurieren. Nach dem Starten einer Instanz aus dem erstellten AMI wurde das Testskript automatisch ausgeführt, d.h. es lud die Konfigurationsdatei von S3 herunter und wartete darauf, Anfragen zu senden. Da wir mehr als eine dieser Instanzen wollten, haben wir auch ein Terraform-Skript geschrieben, um eine bestimmte Anzahl von Testinstanzen zu starten.
Bei unseren ersten Tests haben wir 10 t2.micro-Instanzen laufen lassen, die jeweils bis zu 2.000 Anfragen pro Sekunde gesendet haben, und wir hatten bei jeder Anfrage eine Erfolgsquote zwischen 90% und 100%. Leider waren diese Ergebnisse verfälscht, weil wir die Zeit, in der die Antworten zurückkamen, nicht berücksichtigt hatten, was manchmal bis zu 5 Minuten dauerte. Wie sich herausstellte, waren die von uns verwendeten Instanzen zu langsam, um mit dem gleichzeitigen Senden und Empfangen so vieler Anfragen Schritt zu halten. Nachdem wir festgestellt hatten, dass die Leistung und die Bandbreite der Instanzen einen großen Einfluss auf unsere Tests haben, beschlossen wir, deutlich stärkere Instanzen zu verwenden. Von diesem Moment an beschlossen wir, unsere Tests auf 100 c4.xlarge-Instanzen laufen zu lassen. Dadurch stellten unsere Tests den Stand der aktuellen Verkäufe viel realistischer dar.
Die folgenden AWS-Einstellungen wurden in unseren Tests verwendet:
| DynamoDB-Kapazität | Lambda Gleichzeitigkeit | Lambda-Speicher | Lambda-Zeitüberschreitung |
|---|---|---|---|
| 10000 | 10000 | 1024 MB | 30s |
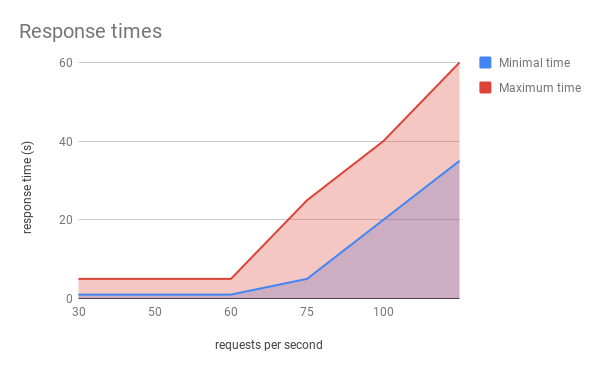
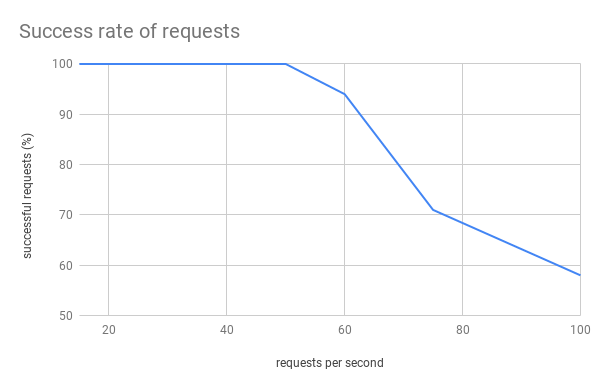
Wir begannen die Tests mit 15 RPS (Anfragen pro Sekunde, was in etwa mit 15 Personen, die gleichzeitig Produkte kaufen, übersetzt werden kann) von jeder der 100 Instanzen und erhöhten diesen Wert mit jedem Test, bis wir 100 RPS erreichten. Wir konnten 50 RPS mit einer Antwortzeit von bis zu 3 Sekunden erreichen, was bedeutet, dass wir 5.000 Anfragen in Echtzeit bearbeiten konnten, was genau unser Ziel war!
Bei 55-60 RPS begannen jedoch Probleme aufzutreten, da die Antwortzeit auf bis zu 20 Sekunden anstieg und die Erfolgsquote der Anfragen auf etwa 96 % fiel. Je mehr Anfragen pro Sekunde gestellt wurden, desto mehr Anfragen schlugen fehl, und auch die Antwortzeit wurde länger. Bei 100 RPS hatten wir Antwortzeiten von bis zu 1 Minute, bei einer Erfolgsquote von etwa 55 %.
Der Teil unserer Lösung, der uns einschränkte, war DynamoDB. Obwohl die maximale Schreibkapazität, die wir erreichten, etwa 4.700 Einheiten betrug, führte die Art und Weise, wie DynamoDB die Speicherung von Daten in Partitionen auflöst, dazu, dass unsere Anfragen gedrosselt wurden. DynamoDB selbst ist in der Lage, einen viel höheren Datenverkehr zu bewältigen, aber dazu wäre eine Optimierung der Partitionsschlüssel erforderlich, z. B. die Aufteilung eines Objekts in viele verschiedene Schlüssel, dann wäre die Partitionierung kein so großes Hindernis.
Kosten
Um die Kosten für den Betrieb unserer Serverless-Lösung mehr oder weniger mit einer Anwendung zu vergleichen, die vollständig auf EC2-Instanzen läuft, haben wir eine einfache Anwendung in einem NodeJS-Webframework namens Express geschrieben. Wir haben diese Anwendung schnell mit Elastic Beanstalk bereitgestellt.
Bei unseren Schätzungen haben wir Fälle wie den Black Friday berücksichtigt, also haben wir die Kosten für den Betrieb einer stark ausgelasteten App für 24 Stunden berechnet. Da unser Serverless-Projekt 5.000 RPS bewältigen konnte, haben wir die EC2-Kosten für die gleiche Last berechnet.
Eine Lambda-basierte Lösung für 432 Millionen Anfragen (5.000 RPS) würde uns etwa 800 $ kosten.
Unsere Elastic Beanstalk-App wurde ursprünglich mit 2 m4.4xlarge-Instanzen hinter einem Load Balancer erstellt, die jeweils 150 RPS bewältigten. Da jede Instanz 75 RPS bewältigt, benötigten wir 67 Instanzen, um Ergebnisse zu erzielen, die denen unseres Serverless-Projekts (5.000 RPS) entsprechen.
Bei 67 Instanzen, die zu $0,888 pro Stunde in 24 Stunden arbeiten, würden die Gesamtkosten pro Tag also $1.427 betragen.
Natürlich wurden unsere Berechnungen für Anwendungen mit einer konstanten Last über einen vollen 24-Stunden-Zeitraum durchgeführt, was kein sehr realistischer Fall ist, aber es dient dazu, den Unterschied in den potenziellen Kosten zu veranschaulichen.
Gelernte Lektionen
Zunächst einmal haben wir erfahren, wie viele Anfragen pro Sekunde unsere Anwendung in Echtzeit bewältigen kann, nämlich 5.000, und dass wir auf dem besten Weg sind, noch mehr zu erreichen, sobald wir die Partitionierung in DynamoDB gelöst haben. Eine Möglichkeit, dies zu erreichen, könnte darin bestehen, die Schreibkapazität in unserer Datenbank zu erhöhen und Produkte so aufzuteilen, dass ein Produkt Datensätze in mehreren Partitionen hat.
Eine weitere Lektion, die wir dabei gelernt haben, ist, wie skalierbar Lambda-Funktionen sind. Grundsätzlich kann Lambda sofort 3.000 gleichzeitige Zugriffe bereitstellen, aber dann wird es mit einer Rate von 500 zusätzlichen gleichzeitigen Zugriffen pro Minute skaliert, bis zu unserem Limit (der Standardwert ist 1.000).
Wir haben auch festgestellt, wie schnell und angenehm die Implementierung von Serverless-Lösungen sein kann. Dank der Nutzung der leicht verfügbaren AWS-Services müssen wir das Rad nicht neu erfinden, wenn es um Dinge wie die Authentifizierung geht - stattdessen haben wir dies mit Cognito gelöst. Stattdessen können wir uns auf die Geschäftslogik unserer Anwendung konzentrieren und müssen uns nicht um die Implementierung von Dingen wie der automatischen Skalierung kümmern.
Um es vorwegzunehmen, unsere API hat 5.000 RPS in Echtzeit verarbeitet, was ein großartiges Ergebnis ist! Das gibt uns eine schnelle, sofortige Skalierbarkeit, wobei wir immer nur für die Ressourcen zahlen, die wir zu einem bestimmten Zeitpunkt benötigen, während wir bei Bedarf immer noch Zugang zu mehr Rechenleistung und Verarbeitung haben.
Geschäftsperspektive
Der eCommerce-Sektor steht vor zahlreichen schwierigen Herausforderungen, aber durch die Umstellung auf eine Serverless-Lösung können Unternehmen eine erschwingliche Lösung erhalten, die sich schnell mit der Nachfrage vergrößern und verkleinern lässt, wodurch verschwendete Ressourcen und Ausgaben während der Ausfallzeiten vermieden werden und gleichzeitig sichergestellt wird, dass Sie in der Lage sind, größere Volumenspitzen zu bewältigen, wenn diese auftreten.
Verfasst von
Xebia Author
Unsere Ideen
Weitere Blogs



Contact