Blog
CI/CD in der dbt Cloud mit GitHub-Aktionen: Automatisierung der Bereitstellung mehrerer Umgebungen

Dbt rationalisiert den Arbeitsablauf bei der Entwicklung von Analysen und deckt alle Schritte von der Entwicklung und den Tests bis hin zur Dokumentation und der Bereitstellung ab, und zwar auf eine nicht-intrusive Weise. Das bedeutet, dass Sie mit minimalem Aufwand Dokumentationen erstellen, Tests durchführen und Änderungen bereitstellen und diese einfach pflegen können.
In meinem letzten Blogbeitrag habe ich beschrieben, wie Sie mehrere BigQuery-Projekte mit einem dbt Cloud-Projekt verwalten , aber die Einrichtung der Verteilungspipeline haben wir auf einen späteren Zeitpunkt verschoben. Dieser Moment ist jetzt gekommen! In diesem Beitrag führe ich Sie durch die Einrichtung einer automatisierten Deployment-Pipeline, die kontinuierlich Integrationstests durchführt und Änderungen (CI/CD) bereitstellt, einschließlich mehrerer Umgebungen und CI/CD-Builds, sobald Pull Requests im Code-Repository geöffnet werden. Wenn Sie Ihre Umgebung auf diese Weise einrichten, können Sie Änderungen so oft Sie wollen freigeben und sich so die Arbeit erleichtern.
Erstellen Sie einen Auftrag zur Erstellung der preprod Umgebung täglich
Der erste Schritt bei der Einrichtung unserer CI/CD-Pipeline in dbt Cloud besteht darin, einen Job zu erstellen, der täglich ausgeführt wird. Auf diese Weise stellen wir sicher, dass wir mit den aktuellsten Transformationen entwickeln, ohne zu viele Ressourcen zu gefährden.
Um den Auftrag zu erstellen, navigieren wir zur Registerkarte Aufträge unter dem Eintrag Verteilen in der oberen Leiste und klicken auf die Schaltfläche Auftrag erstellen Schaltfläche.
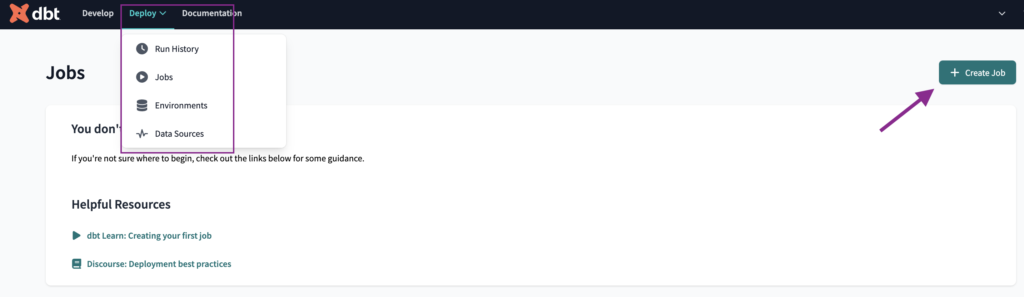
Wir werden den Auftrag benennen als Erstelle vorproduziert und wählen die preprod Umgebung aus.
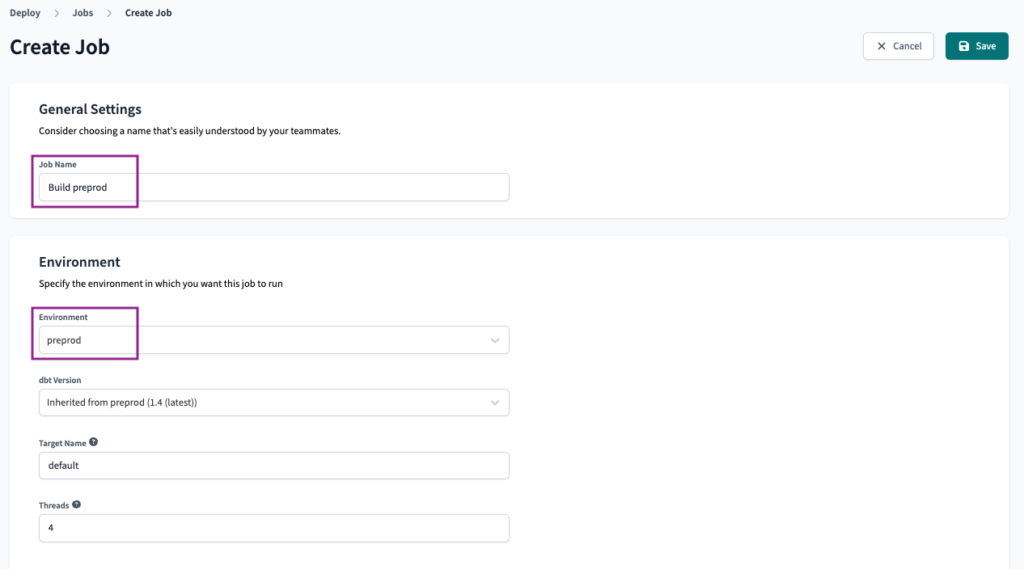
Wir werden die Ausführungseinstellungen als Standard mit dem Befehl dbt build. Sie können dies je nach Ihren Anforderungen bearbeiten.
Für die Auslöser setzen wir die Option Zeitplan so ein, dass er täglich am Morgen ausgeführt wird.
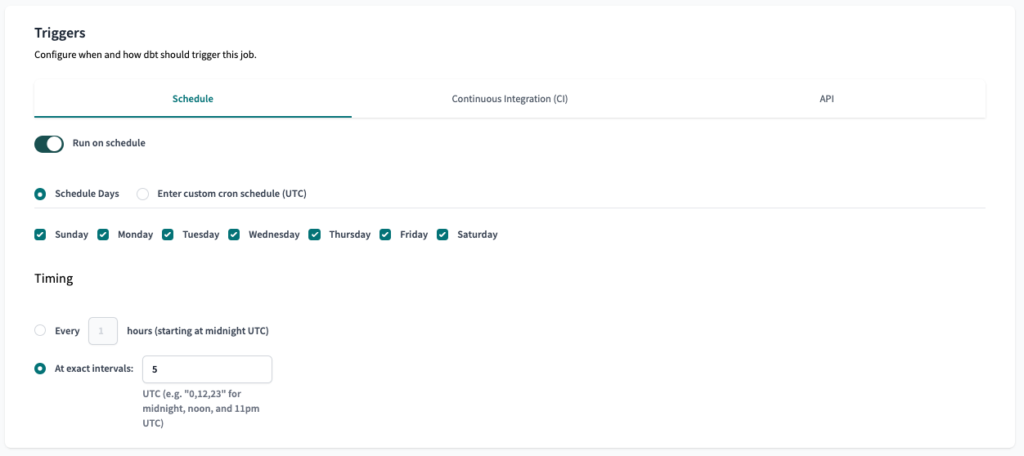
Der erste Schritt unserer Konfiguration ist getan, Sie müssen nur noch Speichern Sie den Auftrag und er wird täglich ausgeführt.
Erstellen Sie einen Auftrag zur Erstellung der geänderten Modelle auf der preprod Umgebung bei jedem PR
Als nächstes erstellen wir einen Job, der ausgelöst wird, sobald ein Pull Request geöffnet wird. Dieser Job sollte die notwendigen Tests und Validierungen durchführen, um sicherzustellen, dass die Codeänderungen für die Zusammenführung mit dem Hauptzweig bereit sind. Der Job erstellt nur die geänderten Modelle und die von ihnen abhängigen nachgelagerten Modelle.
In diesem Fall gehen wir davon aus, dass Sie GitHub als Code-Repository verwenden, aber andere Dienste wie GitLab und Azure DevOps werden ebenfalls unterstützt.
Wir nennen den Auftrag " CI preprod" und wählen die preprod Umgebung.
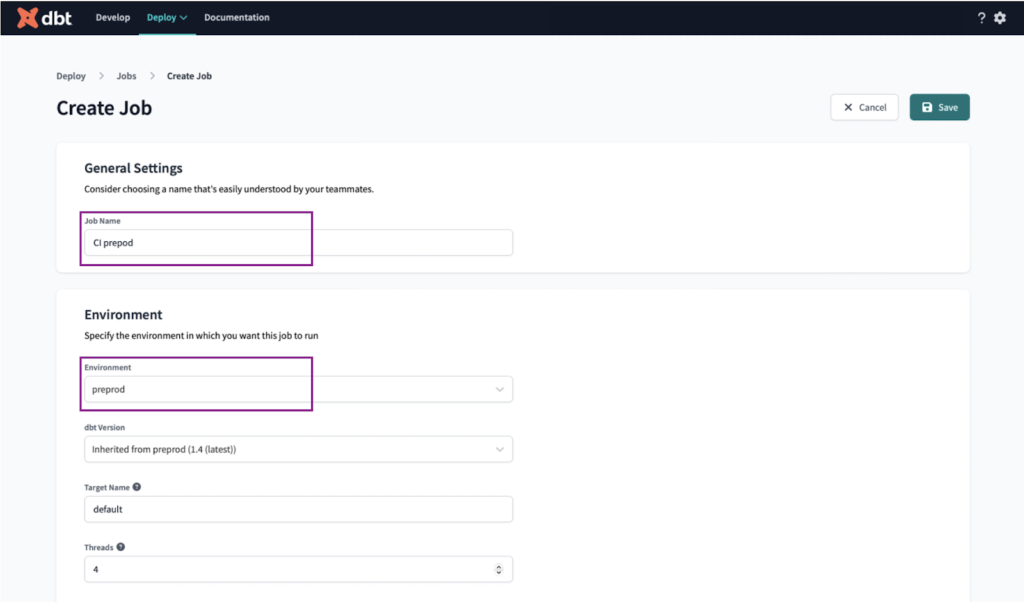
In den Ausführungseinstellungen stellen wir Folgendes ein:
- Setzen Sie "Auf vorherigen Ausführungsstatus zurücksetzen?" auf die Option "Vorläufigen Zustand erstellen". Dadurch wird sichergestellt, dass unser CI-Job nicht ausgelöst wird, wenn es Probleme mit der Umgebung gibt.
- Setzen Sie die Befehle auf
dbt build --select state:modified+
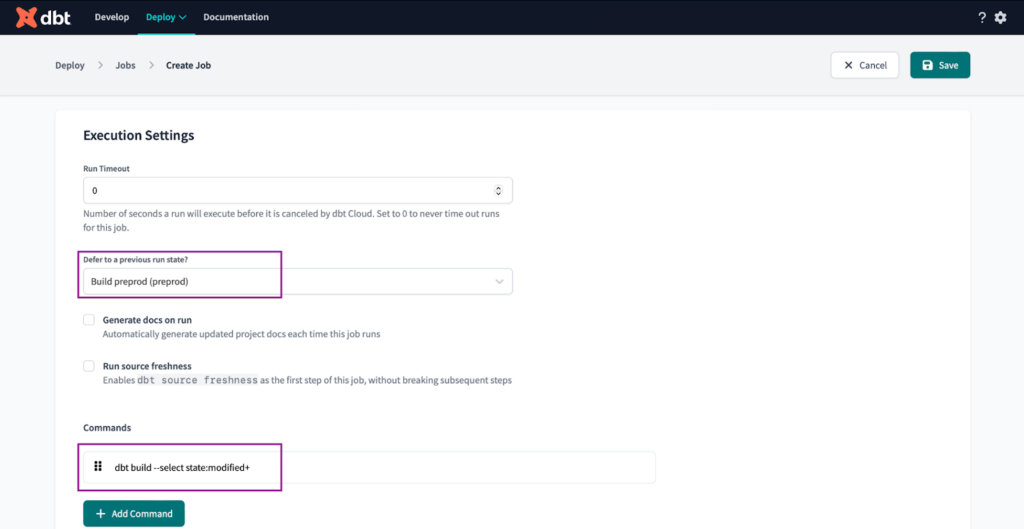
Wir führen diesen Befehl aus, um nur die geänderten Modelle und ihre abhängigen nachgelagerten Modelle zu erstellen, die durch das '+'-Symbol am Ende des Befehls gekennzeichnet sind.
Sie fragen sich vielleicht, warum wir diesen CI/CD-Build-Prozess anwenden, anstatt das gesamte Projekt zu bauen. Dafür gibt es einige Hauptgründe:
✅ Die Erstellung der modifizierten Modelle und der damit verbundenen nachgelagerten Modelle ist genau richtig. Es werden nur die notwendigen Modelle ausgeführt, um alle durch die Änderungen verursachten Probleme zu erkennen.
❌ Bauen Sie die modifizierten Modelle mit den zugehörigen vor- und nachgelagerten Modellen, indem Sie "dbt build --select +state:modified+" ausführen (beachten Sie das zusätzliche '+' vor Zustand ) könnte eine Option sein, aber wir ziehen es vor, die preprod Umgebung täglich zu aktualisieren, damit wir nicht bei jedem CI-Lauf neue Daten benötigen.
Die Erstellung des gesamten Projekts ist zu schwer, eine Verschwendung von Ressourcen und wahrscheinlich zeitaufwändig.
Nur geänderte Modelle zu erstellen ist unzureichend, da es Probleme in nachgelagerten Modellen nicht erkennt.
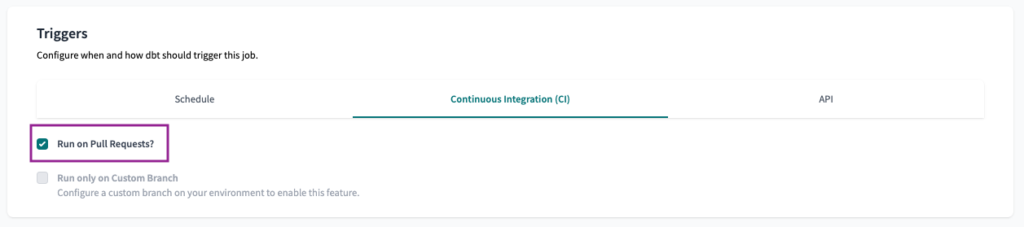
Und schließlich, um die Kontinuierliche Integration (CI) Trigger zu setzen, müssen wir nur noch die Option Bei Pull Request ausführen? ankreuzen.
Hinweis: Um den CI-Trigger zu aktivieren, müssen Sie Ihr dbt Cloud-Projekt entweder mit GitHub, GitLab oder Azure DevOps verbinden.
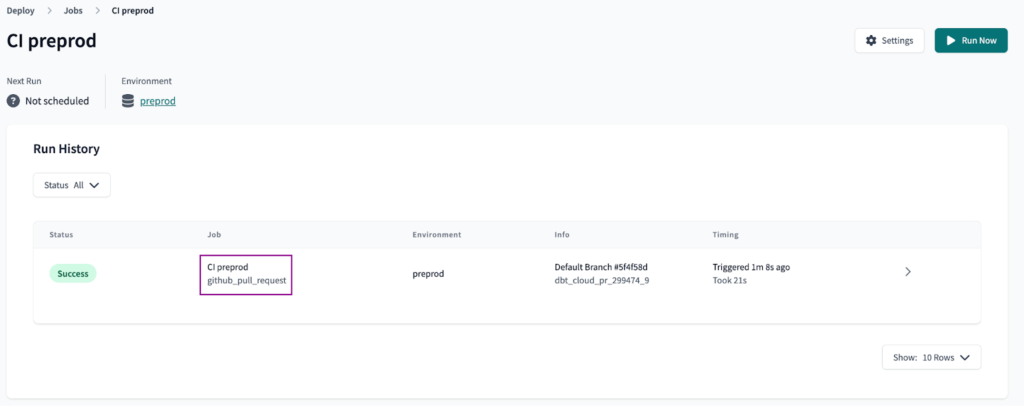
Sobald der Auslöser festgelegt ist, Speichern den Job und erstellen Sie einen Pull Request, um zu überprüfen, ob der CI-Job funktioniert. Jeder neue oder aktualisierte Pull Request sollte einen Joblauf in der dbt Cloud-Umgebung auslösen.
Erstellen Sie einen Auftrag zur Erstellung der prod Umgebung
Als Nächstes legen wir den Job so fest, dass er die prod Umgebung. Das Ziel ist es, einen Job zu haben, der die Produktionsumgebung nach einem Zeitplan ausführt und der ausgeführt wird, sobald ein Pull Request zusammengeführt wird.
Für die letzte Option gibt es keine nativen Optionen von dbt, also müssen wir eine GitHub-Aktion festlegen, um den Job über die dbt Cloud API auszuführen. Dasselbe kann auch mit Azure DevOps oder GitLab gemacht werden, aber für diesen Artikel konzentrieren wir uns auf GitHub.
Als Erstes erstellen wir einen neuen Auftrag und nennen ihn Build prod und wählen prod als Umgebung aus.
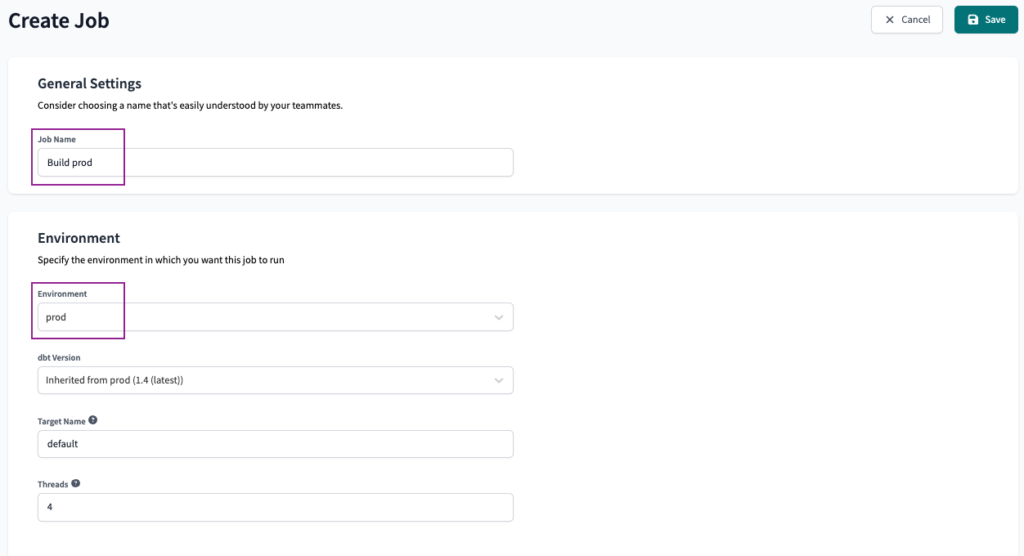
Wir werden die Ausführungseinstellungen als Standard beibehalten, mit nur der dbt build Befehl.
Für den Auslöser Schedule setzen wir außerdem die Option Zeitplan so ein, dass er täglich am Morgen ausgeführt wird.
Die Auftragskonfiguration auf der dbt-Seite ist abgeschlossen, jetzt beginnt die Einrichtung, die eine größere Herausforderung darstellt. Wir werden eine GitHub-Aktion einrichten, um die dbt Cloud API aufzurufen, sobald der PR zusammengeführt ist.
Einrichten einer GitHub-Aktion
Um die GitHub-Aktion einzurichten, benötigen wir zunächst einige Informationen von dbt: Konto-ID, Job-ID, Projekt-ID und API-Schlüssel .
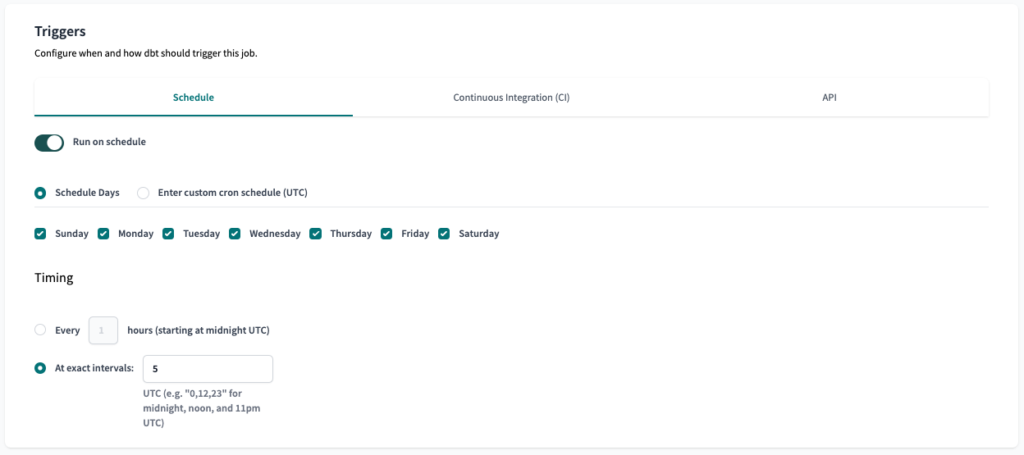
Für die ersten beiden navigieren wir zur Registerkarte API in der Auftragskonfiguration. Dort finden wir die Konto-ID und Job-Id . Wir müssen diese Werte speichern, um sie später zu verwenden.
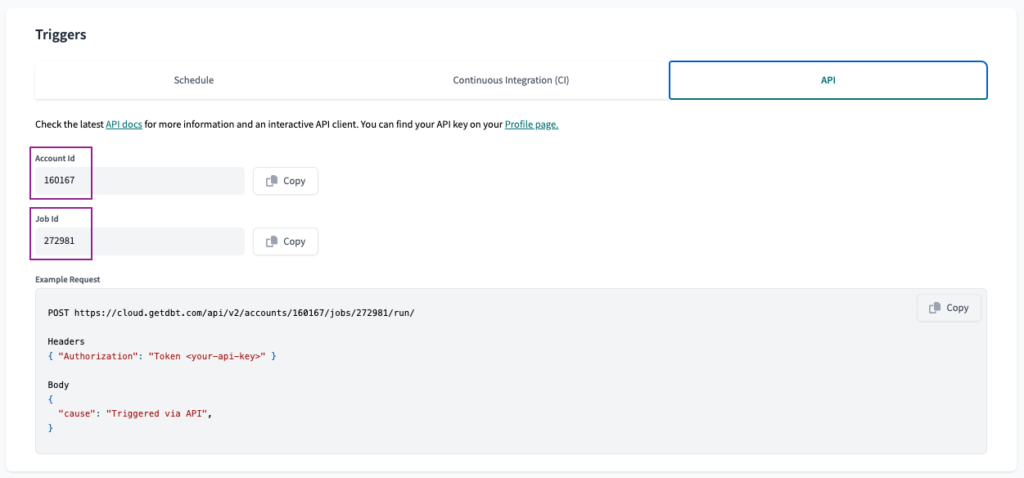
Auf derselben Seite suchen wir nach der URL. Dort finden wir die Projekt-ID .

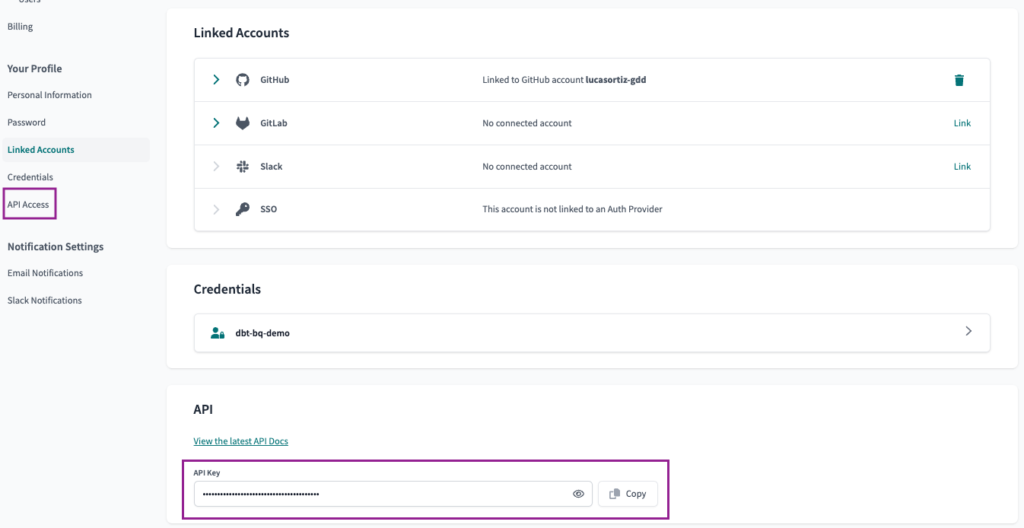
Zum Schluss navigieren wir zur Seite API-Zugang Seite unter dem Menüpunkt Kontoeinstellungen Option. Dort finden wir die API-Schlüssel Wert.
Wenn Sie alle vier Parameter kennen, können Sie unser GitHub-Repository aufrufen und die Aktion einrichten.
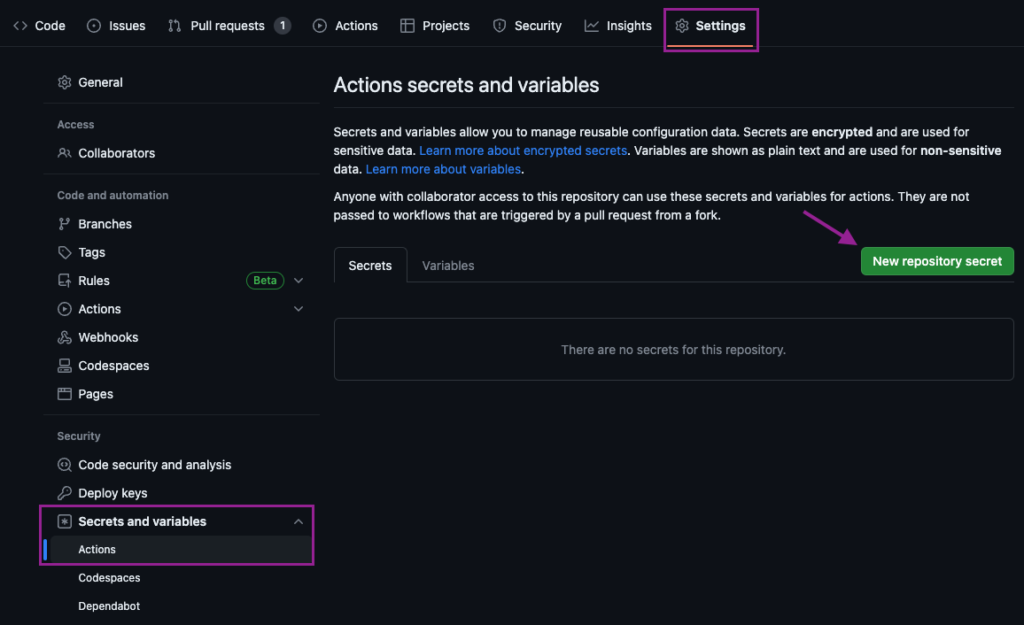
Sobald das Repository geöffnet ist, navigieren wir zu Einstellungen > Geheimnisse und Variablen > Aktionen. Wir erstellen ein Neues Repository secret und benennen es DBT_API_KEY und setzen es als den API-Schlüssel Wert, den wir von dbt kopiert haben.
Sobald er eingestellt ist, navigieren wir zum Menüpunkt Variablen und legen Sie die anderen drei Werte als Variablen fest. Da diese Werte nicht sensibel sind, ist es nicht nötig, sie als geheim zu kennzeichnen.
DBT_ACCOUNT_IDDBT_JOB_IDDBT_PROJECT_ID
Jetzt sind nur noch zwei Schritte nötig, um unsere Einrichtung abzuschließen: Fügen Sie ein Python-Skript hinzu, das die API aufruft, und legen Sie die GitHub-Aktion fest, mit der das Skript ausgeführt werden soll. Wir führen beides auf dem dbt aus Entwickeln Sie IDE.
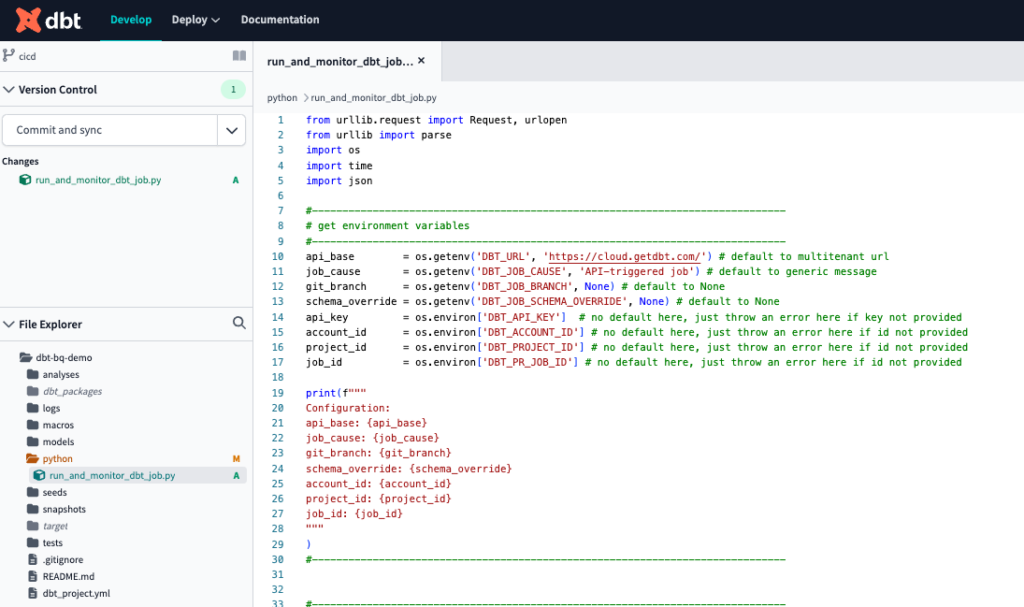
Sobald es geöffnet ist, erstellen wir zunächst einen neuen Ordner namens python . Dort können wir alle unsere Python-Skripte zentralisieren. In diesem Ordner erstellen wir eine Datei namens run_and_monitor_dbt_job.py . Kopieren Sie den Inhalt aus diesem gist in die neue Datei ein. Dieses Skript enthält alles, was Sie brauchen, um die dbt Cloud API aufzurufen. Die erforderlichen Eingaben werden im nächsten Schritt als Umgebungsvariablen eingegeben.
Das Endergebnis sollte wie folgt aussehen.
Der nächste Schritt ist schließlich die GitHub-Aktion festzulegen.
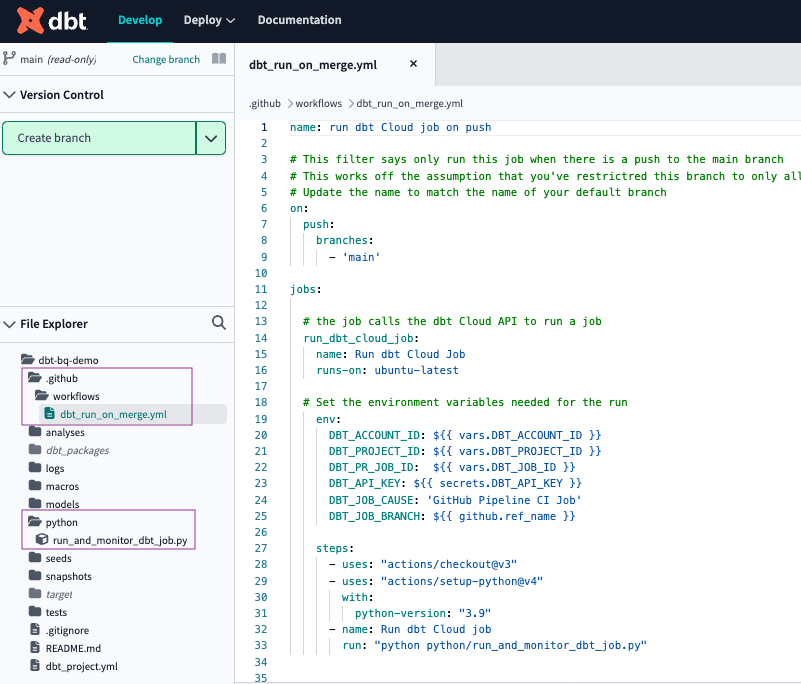
Wir erstellen zunächst einen Ordner namens .github , mit einem Unterordner namens workflows und eine Datei namens dbt_run_on_merge.yml . Kopieren Sie den folgenden Code und fügen Sie ihn in die neue Datei ein. Da er mit der Datei Geheimnisse und Variablen , müssen Sie sie nicht bearbeiten.
name: run dbt Cloud job on push
# This filter says only run this job when there is a push to the main branch
# This works off the assumption that you've restricted this branch to only all PRs to push to the default branch
# Update the name to match the name of your default branch
on:
push:
branches:
- 'main'
jobs:
# the job calls the dbt Cloud API to run a job
run_dbt_cloud_job:
name: Run dbt Cloud Job
runs-on: ubuntu-latest
# Set the environment variables needed for the run
env:
DBT_ACCOUNT_ID: ${{ vars.DBT_ACCOUNT_ID }}
DBT_PROJECT_ID: ${{ vars.DBT_PROJECT_ID }}
DBT_PR_JOB_ID: ${{ vars.DBT_JOB_ID }}
DBT_API_KEY: ${{ secrets.DBT_API_KEY }}
DBT_JOB_CAUSE: 'GitHub Pipeline CI Job'
DBT_JOB_BRANCH: ${{ github.ref_name }}
steps:
- uses: "actions/checkout@v3"
- uses: "actions/setup-python@v4"
with:
python-version: "3.9"
- name: Run dbt Cloud job
run: "python python/run_and_monitor_dbt_job.py"
So sollte Ihr Projekt schließlich mit den neuen Ordnern und Dateien aussehen.
Jetzt müssen wir nur noch einen Pull Request mit unseren neuen Änderungen erstellen, ihn zusammenführen und darauf warten, dass die Magie geschieht!
Sie können überprüfen, ob der Lauf erfolgreich war, sowohl auf GitHub, unter dem Aktionen als auch auf dbt, unter der Registerkarte Aufträge Registerkarte.
GitHub-Aktionen
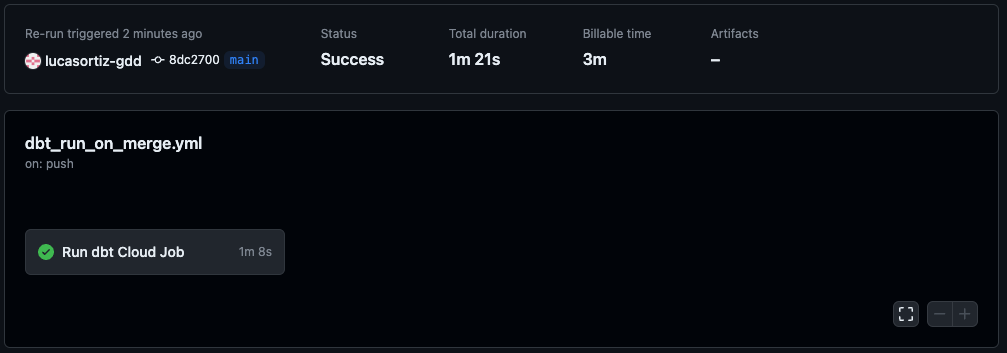
dbt Jobs

Fazit
Als Analytics Engineers können wir unsere Arbeit durch die Implementierung einer CI/CD-Pipeline erheblich vereinfachen. Mit dieser Pipeline müssen wir uns nicht mehr um den manuellen Aufwand kümmern, der für die Bereitstellung und das Testen erforderlich ist. Der CI-Job erkennt Fehler oder Probleme, die im Code auftreten können, und ermöglicht es uns, mit Zuversicht in verschiedenen Umgebungen zu arbeiten. Sobald ein Pull Request zusammengeführt wird, wird diese Automatisierung automatisch ausgelöst, so dass wir mehr Zeit haben, uns auf unsere Hauptaufgabe, die Datenmodellierung und -analyse, zu konzentrieren.
Verfasst von
Lucas Ortiz
I've always been fascinated by technology and problem-solving. Great challenges are what keep me motivated, I rarely accept that a task can’t be done, it’s only a matter of finding new paths to solve the puzzle.




Contact