Blog
Zentralisierte Überwachung für Datenpipelines: Die Kombination von Azure Data Factory Diagnostics mit Databricks Systemtabellen

Einführung
Die Überwachung von Datenpipelines ist unerlässlich, um die Zuverlässigkeit sicherzustellen, Probleme zu beheben und die Leistung im Laufe der Zeit zu verfolgen. Bei Xebia implementieren wir häufig eine Datenplattformarchitektur, die wie folgt aussieht:
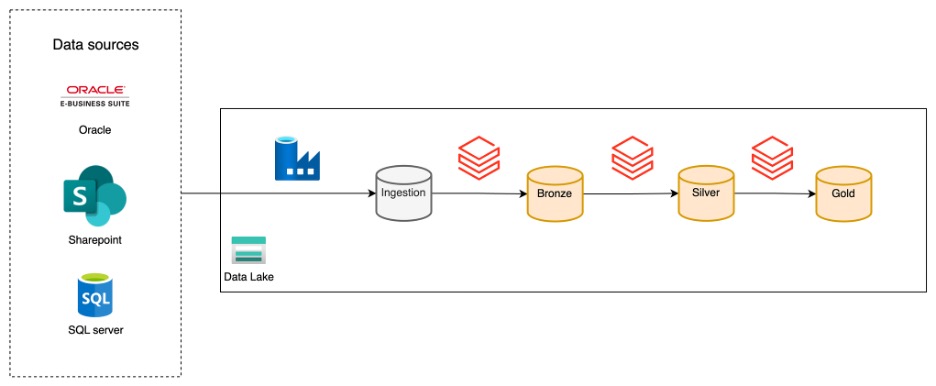
In diesem Setup ist Azure Data Factory (ADF) für die Aufnahme von Daten aus einer Vielzahl von Quellen in ein Speicherkonto zuständig, während Databricks sich um die Umwandlung dieser Daten und ihre Bereitstellung für Endbenutzer kümmert. Durch diese klare Trennung kann jedes Tool seine Stärken ausspielen: ADF zeichnet sich durch Konnektivität und Ingestion aus, während Databricks bei der Transformation und Analyse leistungsstark ist.
Trotz dieser Vorteile ist die Überwachung oft fragmentiert. ADF ermöglicht die Überwachung einzelner Pipeline-Läufe, und Databricks bietet Workflow-Analysen über Systemtabellen, aber es gibt keinen einzigen Ort, an dem Sie eine End-to-End-Ansicht des Datenflusses erhalten. Das macht es schwierig, den gesamten Weg der Daten zu verfolgen und Probleme schnell zu erkennen.
Dieser Artikel zeigt, wie Sie diese Lücke schließen können, indem Sie ADF-Diagnoseeinstellungen mit Databricks-Systemtabellen kombinieren. Das folgende Beispiel zeigt, wie Sie eine zentrale Übersicht erstellen, um die Menge der eingelesenen Daten und die End-to-End-Laufzeit für einen bestimmten Anwendungsfall zu analysieren. Das Setup kann jedoch leicht an Ihren spezifischen Informationsbedarf angepasst werden.
Voraussetzungen
Stellen Sie sicher, dass Sie alles haben, was Sie brauchen:
- Eine Azure Data Factory-Instanz mit laufenden Pipelines
- Ein Speicherkonto
- Ein Databricks-Arbeitsbereich, der mit demselben Speicherkonto verbunden ist
- Databricks Systemtabellen aktiviert
Azure Data Factory Diagnose-Einstellungen
Die Diagnoseeinstellungen von Azure Data Factory ermöglichen den Export von Pipeline-Laufprotokollen und Metriken in ein Speicherkonto, Log Analytics oder Event Hub.
Der erste Schritt besteht darin, die Diagnoseeinstellungen in ein Speicherkonto zu exportieren, auf das Databricks Zugriff hat. Gehen Sie im Azure Portal zu Ihrer ADF-Instanz, wählen Sie Diagnoseeinstellungen und fügen Sie eine neue Diagnoseeinstellung hinzu. Wählen Sie in den Kategorien die gewünschten Einstellungen aus. Für dieses Beispiel exportieren Sie die Pipeline-Läufe und die Aktivitätsläufe.
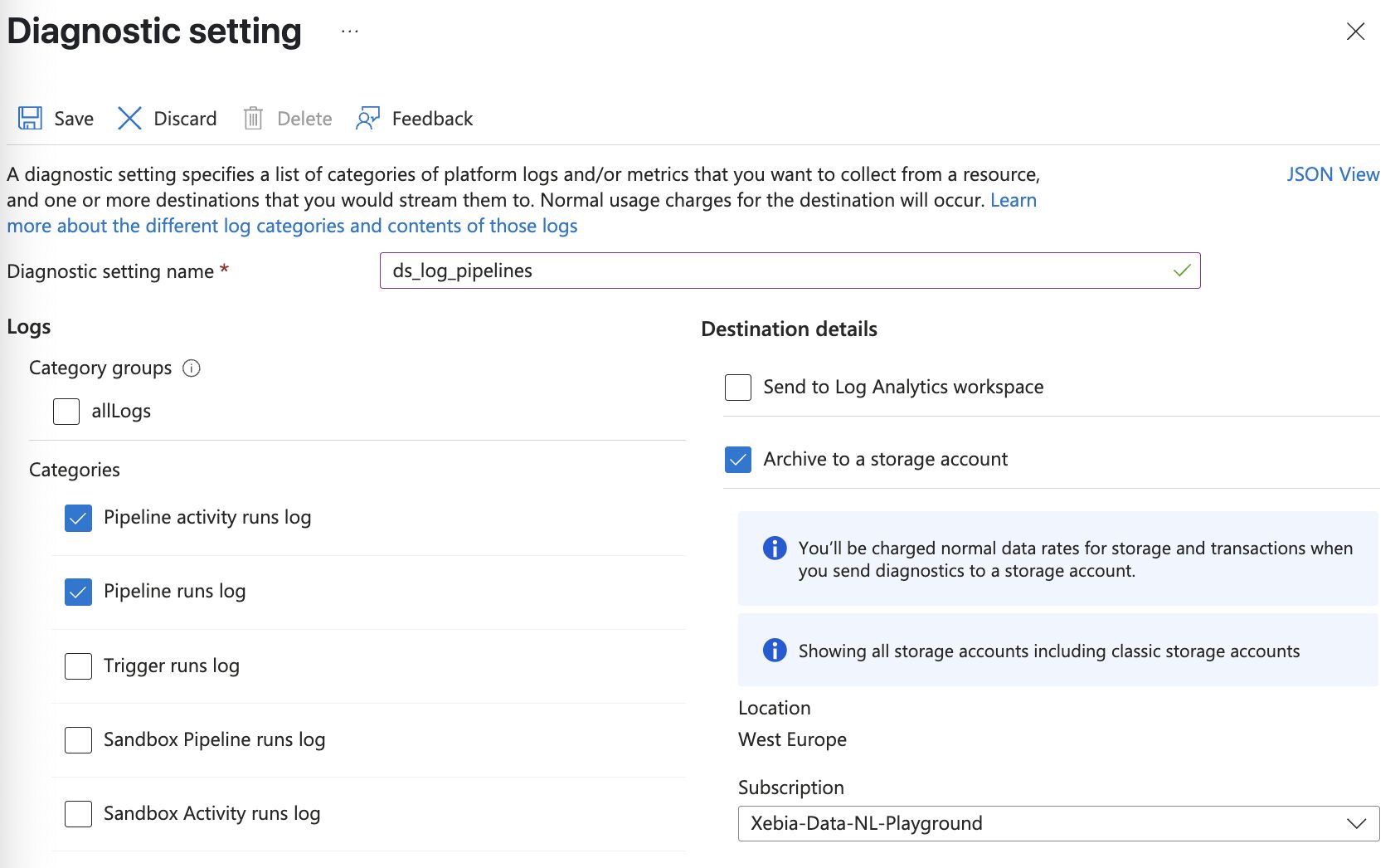
Sobald diese Funktion aktiviert ist, schreibt ADF Protokolle in Ihr Speicherkonto. Die Struktur des Protokollordners wird von Azure festgelegt und kann nicht geändert werden. ADF erstellt einen Container pro ausgewählter Kategorie.
Beachten Sie, dass es bis zu 15 Minuten dauern kann, bis die Protokolle erscheinen.
ADF-Protokolle in Databricks einlesen
Um ADF-Protokolle zusammen mit Databricks-Workflow-Daten zu analysieren, nehmen Sie die Protokolle in Databricks auf. Eine Möglichkeit, dies zu tun, ist die Verwendung der
Die Schritte, um dies zu erreichen, sind:
- Identifizieren Sie den Speicherpfad: Suchen Sie den Container und den Ordner in Ihrem Speicherkonto, in den ADF die Diagnoseprotokolle schreibt.
- Konfigurieren Sie Databricks Autoloader: Richten Sie Autoloader ein, um den Speicherpfad für neue Protokolldateien zu überwachen.
- Workflow erstellen: Planen Sie den Autoloader in einen Workflow mit der Häufigkeit ein, mit der Sie die Prüftabelle aktualisieren möchten.
Wiederholen Sie diese Schritte für jede Kategorie von Diagnoseeinstellungen, die Sie im vorherigen Schritt ausgewählt haben.
Hier ist ein Beispiel für einen PySpark-Codeausschnitt, um ADF-Protokolle mit Autoloader zu importieren:
# Define path variables
container = "insights-logs-pipelineruns"
storage_account = ""
subscription_id = ""
adf_resource_group = ""
adf_name = ""
# Define path
path = f"abfss://{container}@{storage_account}.dfs.core.windows.net/resourceId=/SUBSCRIPTIONS/{subscription_id}/RESOURCEGROUPS/{adf_resource_group.upper()}/PROVIDERS/MICROSOFT.DATAFACTORY/FACTORIES/{adf_name.upper()}/"
checkpoint_path = f"abfss://{container}@{storage_account}.dfs.core.windows.net/_checkpoints/"
# Write logs to etl_audit.adf_pipeline_runs
df = spark.readStream.format("cloudFiles")
.option("cloudFiles.format", "json")
.option("cloudFiles.schemaLocation", checkpoint_path)
.option("cloudFiles.partitionColumns", "")
.option("pathGlobFilter", "*.json")
.option("cloudFiles.inferSchema", "true")
.load(path)
.writeStream
.option("checkpointLocation", checkpoint_path)
.trigger(availableNow=True)
.option("mergeSchema", "true")
.toTable(f"etl_audit.adf_pipeline_runs")
Nach diesen Schritten fragen Sie die Protokolle von Databricks ab, indem Sie die Daten aus der Tabelle adf_pipeline_runs auswählen.
Kombinieren von ADF Log Kategorien
Da die Protokolle in Databricks verfügbar sind, besteht der nächste Schritt darin, die Informationen aus den Protokollen zu extrahieren. Um zum Beispiel die Menge der pro Anwendungsfall aufgenommenen Daten zu sehen, verwenden Sie die folgende Abfrage.
Beachten Sie, dass diese Abfrage für diesen speziellen Informationsbedarf erstellt wurde, aber Sie können so viele Informationen in die Prüfungstabelle aufnehmen, wie Sie benötigen.
-- Filter ADF pipeline runs for succeeded or failed operations
with adf_pipeline_filtered as (
select
runId,
pipelineName,
start as startTime,
end as endTime,
status,
get_json_object(properties, '$.Annotations[1]') AS tableName, -- Extract table name from annotations
get_json_object(properties, '$.Annotations[2]') AS useCase -- Extract use case from annotations
from
etl_audit.adf_pipeline_runs
where
operationName ilike '%Succeeded'
or operationName ilike '%Failed'
)
-- Filter ADF activity runs for succeeded or failed operations
, adf_activity_filtered as (
select
pipelineRunId,
get_json_object(properties, '$.Output.rowsRead') AS rowsRead, -- Extract rows read
get_json_object(properties, '$.Output.rowsCopied') AS rowsCopied, -- Extract rows copied
row_number() over (partition by pipelineRunId order by activityRetryCount desc) as rn -- Only take latest retry of copy activity
from
etl_audit.adf_activity_runs
where
operationName ilike '%Succeeded'
or operationName ilike '%Failed'
)
-- Combine pipeline and activity data, joining on run ID and selecting only the latest retry of the an activity per pipeline run
, adf_combined as (
select
"ADF" as source,
pf.useCase,
pf.pipelineName,
pf.startTime,
pf.endTime,
pf.status,
af.rowsRead,
af.rowsCopied,
pf.tableName
from
adf_pipeline_filtered pf
left join adf_activity_filtered af on pf.runId = af.pipelineRunId
where
af.rn = 1
)

Databricks Systemtabellen hinzufügen
Databricks Systemtabellen liefern detaillierte Informationen über Workflow-Läufe, Job-Status und mehr. Fragen Sie diese Tabellen ab, um die relevanten Details für Ihr Monitoring Dashboard zu extrahieren.
- Erstellen Sie eine Ansicht zur Auswahl der Schlüsselspalten (z.B. Job-ID, Laufstatus, Start-/Endzeit)
- Verbinden Sie diese Ansicht mit der Ansicht ADF-Protokolle, um eine zentralisierte, durchgängige Überwachungstabelle zu erstellen
- Passen Sie die endgültige Ansicht an die Bedürfnisse Ihres Unternehmens an (fügen Sie Spalten, Filter usw. hinzu).
Um einen vollständigen Überblick über die Laufzeit für einen Anwendungsfall zu erhalten, führen Sie die ADF-Audit-Tabelle mit dieser Abfrage mit der Databricks-Systemtabelle zusammen:
Diese Abfrage knüpft an die vorherige Abfrage an. Sie können sie also einfach anhängen, um eine einzige, einheitliche SQL-Anweisung zu erstellen.
-- Select Databricks jobs
, adb_job as (
select
*,
row_number() over (partition by workspace_id, job_id order by change_time desc) as rn -- As this is an SCD2 table, we only take the most recent version of the job.
from system.lakeflow.jobs
qualify rn = 1
)
-- Select Databricks job run details
, adb_job_run as (
select
job_id,
period_start_time as startTime,
period_end_time as endTime,
result_state as status -- Job run status (e.g., Succeeded, Failed)
from system.lakeflow.job_run_timeline
)
-- Combine job and run info, align columns with ADF data
, adb_combined as (
select
"DATABRICKS" as source,
coalesce(job.tags.use_case, null) as useCase,
job.name as pipelineName,
run.startTime,
run.endTime,
run.status,
null as rowsRead, -- Not applicable for Databricks jobs
null as rowsCopied, -- Not applicable for Databricks jobs
null as tableName -- Not applicable for Databricks jobs
from adb_job job
left join adb_job_run run on job.job_id = run.job_id
)
-- Union ADF and Databricks results for a centralized view
, combined as (
select * from adf_combined
union all
select * from adb_combined
)
-- Final selection, ordered by most recent runs
select *
from combined
order by startTime desc
So erhalten Sie ein Ergebnis, in dem Sie die aufgenommenen Daten und die End-to-End-Laufzeit des Anwendungsfalls leicht erkennen können.

Zusammenfassung
In diesem Artikel wird eine Lösung gezeigt, wie Sie die ADF-Diagnoseeinstellungen mit Databricks Systemtabellen zu einer zentralisierten Audit-Tabelle kombinieren können, mit der Sie Ihre Datenpipelines an einem einzigen Ort überwachen und analysieren können.
Mit dieser Einrichtung können Sie eine Vielzahl von Fragen beantworten und viele Szenarien unterstützen, wie z.B.:
- Analysieren Sie Veränderungen im Laufe der Zeit in den geladenen Zeilen für eine bestimmte Tabelle oder einen Anwendungsfall
- Verfolgen Sie die Gesamtlaufzeiten und Leistungstrends ganzer Datenpipelines
- Identifizieren Sie Engpässe oder Ausfälle in der gesamten Pipeline, von der Aufnahme bis zur Umwandlung
- Korrelieren Sie die Schritte der Aufnahme und Umwandlung für eine bessere Fehlerbehebung und Ursachenanalyse.
- Aktivieren Sie die Berichterstattung auf der Grundlage benutzerdefinierter Metriken oder Schwellenwerte.
Beschränkungen & Tipps
- Systemtabellen: Stellen Sie sicher, dass Systemtabellen in Ihrem Databricks-Arbeitsbereich aktiviert sind (verfügbar in Premium und höher).
- Protokollvolumen: ADF-Diagnoseprotokolle können schnell anwachsen. Richten Sie für Ihr Speicherkonto Aufbewahrungsrichtlinien oder eine Lebenszyklusverwaltung ein.
- Schemaänderungen: Wenn sich die Struktur Ihrer Pipelines oder Arbeitsabläufe ändert, aktualisieren Sie Ihre Ansichten entsprechend, um fehlende Daten zu vermeiden.
- Infrastruktur als Code: Sie können ADF-Diagnoseeinstellungen über Terraform für automatisierte, wiederholbare Implementierungen einrichten.
- Datenvisualisierung: Wenn Sie die endgültige Prüftabelle in einem Datenvisualisierungstool (oder sogar in einem Databricks-Dashboard) anzeigen, können auch technisch nicht versierte Beteiligte leicht erkennen, wann eine Aktualisierung ihrer Daten zu erwarten ist.
Verfasst von
Rik Adegeest
Rik is a dedicated Data Engineer with a passion for applying data to solve complex problems and create scalable, reliable, and high-performing solutions. With a strong foundation in programming and a commitment to continuous improvement, Rik thrives on challenging projects that offer opportunities for optimization and innovation.




Contact