Blog
BigQuery Storage Write API: Ein praktischer Leitfaden mit Python und Protobuf


Echtzeitdaten sind der Schlüssel in der heutigen schnelllebigen Welt der Analytik. Mit der BigQuery Storage Write API können Sie Daten direkt in BigQuery-Tabellen streamen. In diesem Leitfaden werden wir mehrere praktische Beispiele für die BigQuery Storage Write API durchgehen. Sie werden sehen, wie Sie mit Hilfe von Python und Protobuf verschiedene Anforderungen an das Schreiben von Daten mit unterschiedlichen Übermittlungssemantiken erfüllen können.
Fangen wir an!
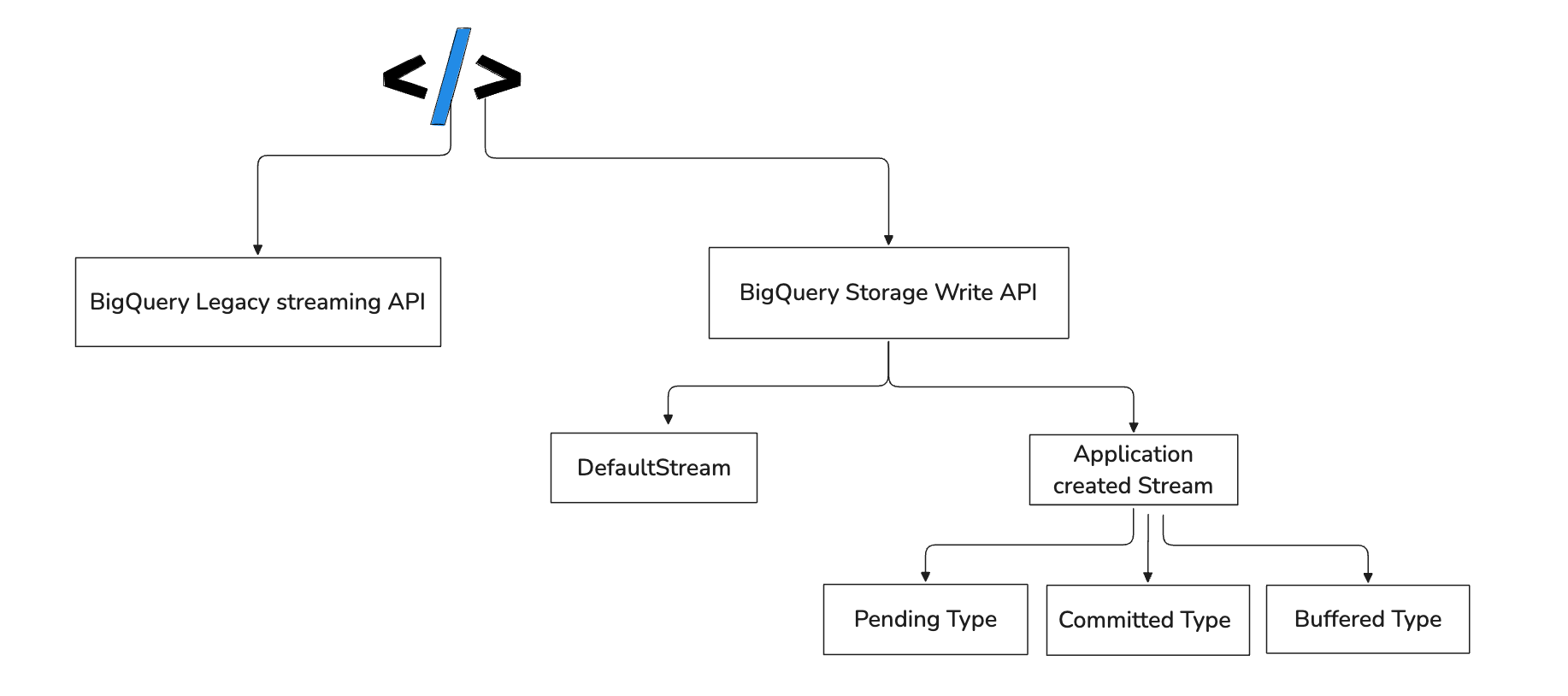
BigQuery Speicher-Schreib-API
Wenn Sie Daten nahezu in Echtzeit in BigQuery schreiben müssen, gibt es mehrere Möglichkeiten - die BigQuery Storage Write API ist eine davon. Die BigQuery Storage Write API ist eine kosteneffiziente Low-Level-Schnittstelle, mit der Sie Daten nahezu in Echtzeit in BigQuery schreiben können. Die API vereint Streaming Ingestion und Batch Loading über eine Schnittstelle mit niedriger Latenz und hohem Durchsatz.
Aus der Sicht eines Entwicklers geht es bei der Verwendung der BigQuery Storage Write API vor allem darum, Ihre Daten in einem Strom von Protobuf-Nachrichten an BigQuery zu senden. Sie beginnen mit der Erstellung einer Schreibsitzung und konvertieren dann Ihre Daten in das entsprechende Protobuf-Format, das zu Ihrem Tabellenschema passt. Jeder Schreibvorgang ist ein einfacher API-Aufruf, der ein Datenpaket sendet. Je nach Streaming-Typ entscheiden Sie dann, ob die Änderungen übertragen werden sollen oder nicht. In den folgenden Abschnitten werden wir uns mit den Details befassen. Darüber hinaus gibt es verschiedene Optionen, um Daten mit der Storage Write API in BigQuery zu schreiben. In diesem Leitfaden werden wir alle Optionen durchgehen.
Zwei Sätze über Protobuf
Protocol Buffers, oder kurz Protobuf, ist eine von Google entwickelte und gepflegte Methode zur Serialisierung strukturierter Daten. Betrachten Sie es als eine effizientere und streng typisierte Alternative zu Formaten wie JSON oder XML. Sie definieren Ihre Datenstruktur mithilfe einer speziellen Nachrichten-Definitionssprache (.proto-Dateien) und verwenden dann einen Compiler, um Code für verschiedene Programmiersprachen wie Python, Java oder C++ zu erzeugen. Mit diesem generierten Code können Sie ganz einfach Daten in Ihrer Sprache in Protobuf-Nachrichten kodieren und dekodieren. Im Vergleich zu Formaten wie XML oder JSON erzeugt Protobuf kleinere, schneller zu verarbeitende Nachrichten und ist ideal für leistungsabhängige, skalierbare Anwendungen.
Einrichtung und Voraussetzungen
Das Repository mit den Codebeispielen ist hier verfügbar. Sie können das Repository klonen und die Beispiele lokal ausführen, wenn Sie mitmachen möchten. Um die Erfahrung für Entwickler zu verbessern, gibt es ein devcontainer-Setup für dieses Repository mit den Befehlen just. Öffnen Sie also das Repository in devcontainer, und Sie werden mit allen Tools ausgestattet, die Sie benötigen.
Wenn Sie das Repository in devcontainer öffnen, führen Sie den folgenden Befehl aus, um die Umgebung einzurichten:
- Kopieren Sie
conf_example.yamlinconf.yamlund geben Sie die gcp-Projekt-ID und die bq-Datensatz-ID ein (falls der Datensatz nicht existiert, werden wir ihn in einem späteren Schritt erstellen).
just setup
- Installieren Sie die Projektabhängigkeiten
just install
- Anmeldung bei gcloud
just login
In den folgenden Beispielen werden wir die Datenpipeline des Lernmanagementsystems (LMS) mit dem folgenden ERD-Diagramm und den darin enthaltenen Entitäten simulieren.
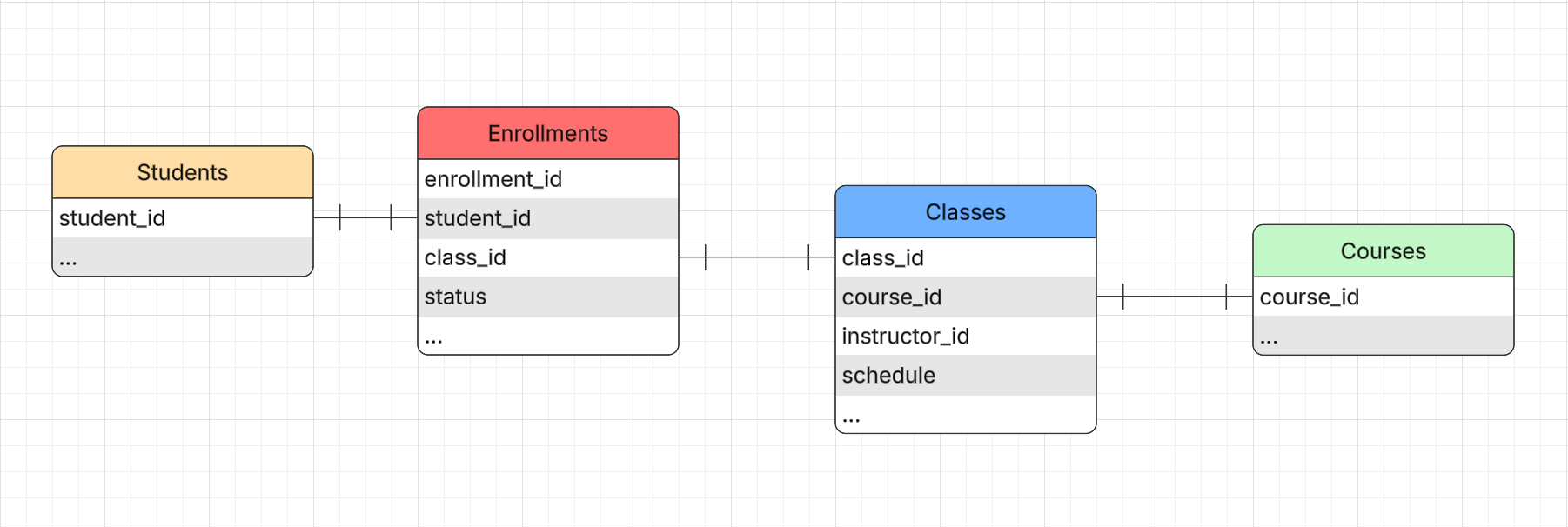 Jede Entität hat ihre eigene Tabelle in BigQuery, und das Schema der Tabellen ist im Ordner
Jede Entität hat ihre eigene Tabelle in BigQuery, und das Schema der Tabellen ist im Ordner misc/schemas in json-Dateien beschrieben. Lassen Sie uns also das Dataset und die Tabellen in BigQuery erstellen.
- Erstellen Sie das BigQuery-Dataset und die erforderlichen Tabellen (Das Skript durchläuft die Dateien im Ordner
misc/schemasund erstellt Tabellen im BigQuery-Dataset für jede json-Datei).
just bq_init
Sie können die folgenden 2 Schritte überspringen, da sich die Ergebnisse dieser Schritte bereits im Repository befinden. Diese Schritte sollen Ihnen zeigen, wie Sie Proto-Nachrichten und Python-Klassen aus den
.protoDateien erzeugen.
- Generieren Sie Proto-Nachrichten aus den Bigquery-Tabellenschemata (es werden die
.protoDateien im Ordnermisc/protofür jede Entität im Ordnerschemas/erstellt)
just generate_proto
- Kompilieren Sie die
.protoDateien in Python-Klassen (die Python-Klassen werden im Ordnersrc/bigquery_storage_write_api_examples/entities/abgelegt)
just compile_proto
Normalerweise werden die Proto-Dateien und die generierten Python-Klassen im Repository gespeichert und bei Bedarf für die aktualisierten Schemata neu generiert.
BigQuery Speicher-Schreib-API - Standard-Stream
Der Standard-Stream in der Speicher-Schreib-API wurde für Szenarien entwickelt, in denen ständig neue Daten eingehen. Wenn Sie in diesen Stream schreiben, stehen Ihre Daten sofort für Abfragen zur Verfügung, und das System garantiert die Bereitstellung von tabledata.insertall API umsteigen, werden Sie feststellen, dass dieser Default Stream ähnlich funktioniert, aber eine bessere Ausfallsicherheit, weniger Skalierungsprobleme und einen günstigeren Preis bietet.
Lassen Sie uns nun sehen, wie es aus der Code-Perspektive aussieht. In unserem LMS-Beispielsystem möchten wir die Daten der Studenten in die Tabelle Studenten in BigQuery schreiben und dabei den Standardstream verwenden. Den Quellcode finden Sie hier.
Zunächst müssen wir den Stream mit dem Client, den Tabelleninformationen, dem Proto-Nachrichtendeskriptor usw. initialisieren.
Initialisierung des Streams
def _init_stream(self):
# Initialize the client
self.write_client = BigQueryWriteClient()
# Create the table path
self.table_path = self.write_client.table_path(self.project_id, self.dataset_id, self.table_id)
# Create the stream name
self.stream_name = self.write_client.write_stream_path(
self.project_id, self.dataset_id, self.table_id, "_default"
)
# Create the proto descriptor
self.proto_descriptor: DescriptorProto = DescriptorProto()
RawStudents.DESCRIPTOR.CopyToProto(self.proto_descriptor)
# Create the proto schema
self.proto_schema = ProtoSchema(proto_descriptor=self.proto_descriptor)
# Create the proto data (template for the data to be written)
self.proto_data: AppendRowsRequest.ProtoData = AppendRowsRequest.ProtoData()
self.proto_data.writer_schema = self.proto_schema
# Create the request template
self.request_template = AppendRowsRequest()
self.request_template.write_stream = self.stream_name
self.request_template.proto_rows = self.proto_data
# Create the stream
self.append_rows_stream: AppendRowsStream = AppendRowsStream(self.write_client, self.request_template)
Sobald der Stream erstellt ist, können wir damit beginnen, die Daten in den Stream zu schreiben. Dazu müssen wir eine Anfrage erstellen:
Erstellen der Anfrage
def _request(self, students: list[dict]) -> AppendRowsRequest:
request = AppendRowsRequest()
proto_data = AppendRowsRequest.ProtoData()
proto_rows = ProtoRows()
for student in students:
raw_student = ParseDict(js_dict=student, message=RawStudents(), ignore_unknown_fields=True)
proto_rows.serialized_rows.append(raw_student.SerializeToString())
proto_data.rows = proto_rows
request.proto_rows = proto_data
return request
Danach können wir die Anfrage an den Stream senden:
Senden der Anfrage
def _write_students(self, request: AppendRowsRequest) -> AppendRowsResponse:
self.logger.debug("Sending a request to BigQuery")
response_future = self.append_rows_stream.send(request)
# if this doesn't raise an exception, all rows are considered successful
result = response_future.result()
self.logger.debug(f" Result: {result}")
return result
Wenn Sie den folgenden just Befehl ausführen, werden Sie sehen, dass 1.000 Zeilen gefälschter Studentendaten generiert und in die Tabelle students in BigQuery geschrieben werden.
just default_stream_example
Ergebnis
BigQuery Storage Write API - Ausstehender Typ Stream
Bei einem ausstehenden Stream-Typ werden alle Datensätze, die Sie schreiben, in einem Puffer gehalten, bis Sie sich entscheiden, den Stream zu bestätigen. Sobald Sie die Daten festschreiben, stehen alle zwischengespeicherten Daten für Abfragen zur Verfügung. BigQuery bietet auch einen Stream vom Typ Commit, bei dem die Daten sofort nach dem Schreiben verfügbar sind. Auf die Details von Streams vom Typ Commitment gehen wir etwas später ein.
Für dieses Beispiel werden wir 1.000 gefälschte Klassendaten erzeugen und in die Klassentabelle in BigQuery schreiben(Quellcode).
Der Initialisierungsteil ist fast derselbe wie im vorherigen Beispiel, abgesehen von einigen kleinen Unterschieden, so dass im Folgenden nur die relevanten Teile gezeigt werden.
def _init_stream(self):
... # same as in the previous example
self.write_stream.type_ = types.WriteStream.Type.PENDING
... # same as in the previous example
Wie im vorherigen Beispiel müssen wir eine Anfrage erstellen, um die Daten für den Stream zu schreiben. Allerdings müssen wir auch den Offset für jeden Eintrag in der Anfrage angeben. Offsets sind ganzzahlige Werte, die die Reihenfolge der Nachrichten innerhalb der Anfrage angeben. Wenn es ein Problem gibt - z.B. eine Netzwerkstörung oder eine Wiederholung - verwendet BigQuery Offsets, um zu wissen, welche Daten bereits empfangen wurden und welche noch fehlen. Bei mehreren Anfragen innerhalb desselben Streams müssen die Offsets aufeinander abgestimmt werden, damit die Reihenfolge der Nachrichten beibehalten wird.
def _request(self, courses: list[dict], offset: int) -> types.AppendRowsRequest:
... # same as in the previous example
request.offset = offset
... # same as in the previous example
return request
def run(self):
batches = ...
# The first request must always have an offset of 0.
offset = 0
for batch_index, batch in enumerate(batches):
request = self._request(batch, offset)
self._write_courses(request=request, batch_index=batch_index, batch_size=len(batch))
# Offset must equal the number of rows that were previously sent.
offset += len(batch)
# The input() is used to pause the execution of the script to allow you to check the data in the table.
input("Press Enter to continue...")
Führen Sie den folgenden just Befehl aus. Er erzeugt 1.000 gefälschte Kursdaten und sendet sie an die BigQuery-Tabelle. Es gibt eine Pause in der Ausführung, so dass Sie die Daten in der Tabelle überprüfen können, bevor der Stream übertragen wird.
just pending_type_stream_example
Ergebnis
BigQuery Storage Write API - Committed Type Stream
Der Stream vom Typ Commit macht jeden Datensatz, den Sie schreiben, sofort für den Verbrauch verfügbar. Das macht ihn perfekt für Streaming-Workloads, bei denen eine geringe Leselatenz entscheidend ist. Es stellt sich heraus, dass exactly-once Liefergarantien des Committed Streams.
Der Code für dieses Beispiel befindet sich hier und ist fast identisch mit dem vorherigen Beispiel, außer dass der Stream-Typ committed ist.
def _init_stream(self):
... # same as in the previous example
self.write_stream.type_ = types.WriteStream.Type.COMMITTED
... # same as in the previous example
Führen Sie den folgenden just Befehl aus. Er erzeugt 5 gefälschte Anmeldedaten und sendet sie an die BigQuery-Tabelle. Wie im vorherigen Beispiel verwenden Sie pause, um den Zustand der zugrunde liegenden BigQuery-Tabelle nach jedem API-Aufruf zu überprüfen.
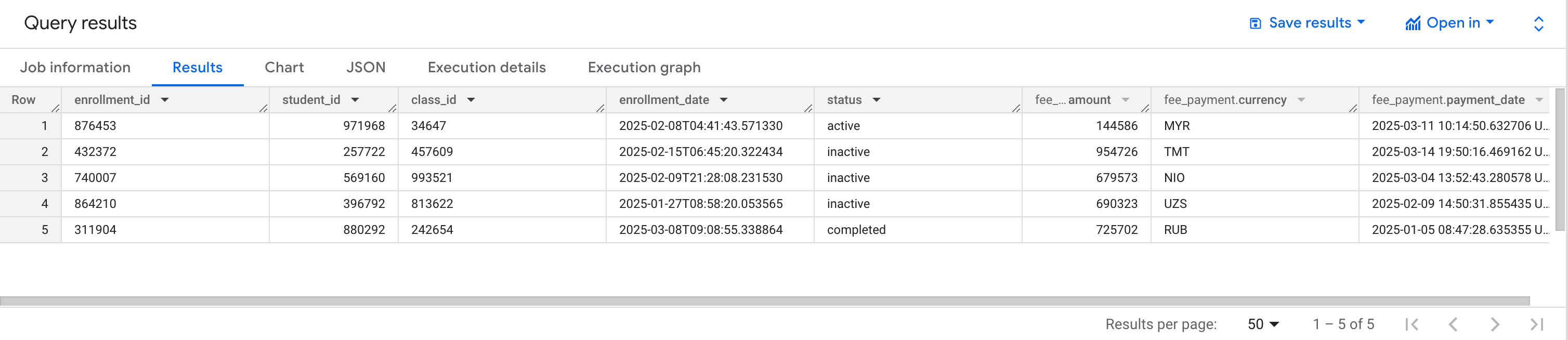
just committed_type_stream_example
Ergebnis
BigQuery Speicher-Schreib-API - gepufferter Typ Stream
Streams vom Typ gepuffert sind eine erweiterte Option, die hauptsächlich von Entwicklern von BigQuery-Konnektoren wie dem Apache Beam BigQuery I/O Connector verwendet werden soll. Bei diesem Streamtyp wird jede Zeile in einem Puffer gehalten, bis Sie den Stream leeren. Dann werden die gepufferten Zeilen einzeln übertragen. Im Wesentlichen erhalten Sie so die Kontrolle über die Übergabe auf Zeilenebene. Für die meisten Anwendungsfälle - vor allem, wenn Sie kleine Batches zusammen schreiben möchten - ist es jedoch einfacher und effektiver, den Commit-Typ zu verwenden und den Batch in einer Anfrage zu senden.
Den Code für dieses Beispiel finden Sie hier.
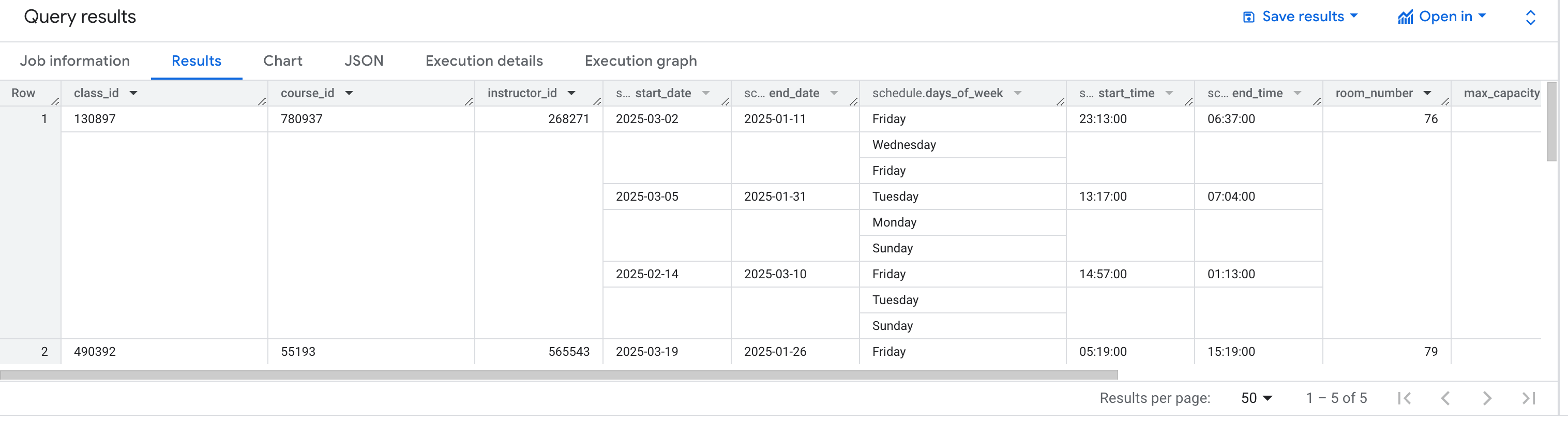
Der folgende just Befehl erzeugt 5 gefälschte Klassendaten und sendet sie an die BigQuery-Tabelle.
just buffered_type_stream_example
Ergebnis
Einpacken
Wir haben die BigQuery Storage Write API und ihre verschiedenen Stream-Typen - Standard, Pending, Commit und Buffered - kennengelernt. Sie haben gelernt, wie Sie mit Python und Protobuf sowohl Echtzeit- als auch Batch-Dateningestion erstellen können. Sie können den Code gerne anpassen, mit verschiedenen Optionen experimentieren und Ihre Ergebnisse mit anderen teilen. Und denken Sie daran, dass die BigQuery Storage Write API nicht die einzige Möglichkeit ist, in BigQuery Table zu schreiben - Google bietet weitere Optionen wie Pub/Sub, Dataflow und andere, die für unterschiedliche Arbeitslasten und Architekturen geeignet sind. Viel Spaß beim Programmieren!
Unsere Ideen
Weitere Blogs




Contact