Blog
Automatische Skalierung von Azure DevOps Pipelines-Agenten mit KEDA

1. Einführung
Wenn Unternehmen ihre DevOps-Praktiken skalieren, wird die Notwendigkeit einer effizienten Ressourcenverwaltung und Automatisierung immer wichtiger. Eine der größten Herausforderungen in groß angelegten CI/CD-Umgebungen ist die Verwaltung der Verfügbarkeit von Build-Agenten, insbesondere bei der Arbeit mit Hunderten von spezialisierten Pipelines, die benutzerdefinierte Tools und Konfigurationen erfordern.
In unserem Fall verwalten wir Hunderte von Sicherheitsscan-Pipelines, die regelmäßig ausgeführt werden müssen. Diese Pipelines erfordern einen komplexen Satz von Tools, die auf selbst gehosteten Azure DevOps-Agenten installiert sind. Die manuelle Verwaltung des Lebenszyklus dieser Agenten oder statische Konfigurationen können zu Ineffizienzen, Ressourcenverschwendung und erhöhten Kosten führen. Um diese Herausforderungen zu bewältigen, schlug unser Architekt die Verwendung von Kubernetes Ereignisgesteuerte Autoskalierung als automatische Skalierungslösung für unsere Azure DevOps Agent Pools.
In diesem Artikel erfahren Sie, wie sich KEDA mit Azure Kubernetes Dienst (AKS) Umgebung zur effizienten Verwaltung Azure DevOps Agent Pools. Wir gehen auf die Unterschiede zwischen den KEDA-Mechanismen ScaledObject und ScaledJob ein und stellen Ihnen Codebeispiele mit Konfigurationen zur Verfügung, mit denen Sie eine robuste, automatisch skalierende Lösung für Ihre Azure DevOps-Agenten implementieren können.
2. KEDA verstehen: Ein kurzer Überblick
2.1 Was genau ist KEDA?
KEDA (Kubernetes Event-Driven Autoscaling) ist ein Open-Source-Projekt die Kubernetes mit ereignisgesteuerten Funktionen ausstattet, so dass Anwendungen dynamisch auf der Grundlage von Ereignissen skaliert werden können und nicht nur anhand traditioneller CPU- oder Speichermetriken. Es handelt sich um eine leichtgewichtige Komponente, die sich nahtlos in Kubernetes integriert und die Skalierung von Workloads wie Builds oder Bereitstellungen erleichtert.
KEDA erweitert den Standard Kubernetes Horizontaler Pod Autoscaler (HPA) zur Unterstützung der Skalierung auf der Grundlage einer Vielzahl externer Metriken, wie z.B. der Länge von Warteschlangen in Messaging-Systemen (z.B. Azure Service Bus, RabbitMQ), Datenbankereignissen, HTTP-Anfragen und vielem mehr. Mit diesem ereignisgesteuerten Skalierungsmechanismus können Kubernetes-Workloads sofort auf Änderungen der Nachfrage reagieren und so sicherstellen, dass die Ressourcen effizient und kostengünstig genutzt werden.
2.2 Wie funktioniert KEDA?
KEDA arbeitet durch die Überwachung externer Ereignisquellen und Metriken, die durch Auslöser. Jeder Auslöser definiert ein bestimmtes Ereignis oder eine Kennzahl, die KEDA überwacht, um zu bestimmen, wann Ihre Kubernetes-Bereitstellungen oder -Jobs hoch- oder herunterskaliert werden sollen. Wenn ein Auslöseschwellenwert erreicht wird, passt KEDA die Anzahl der Replikate oder Jobs entsprechend an.
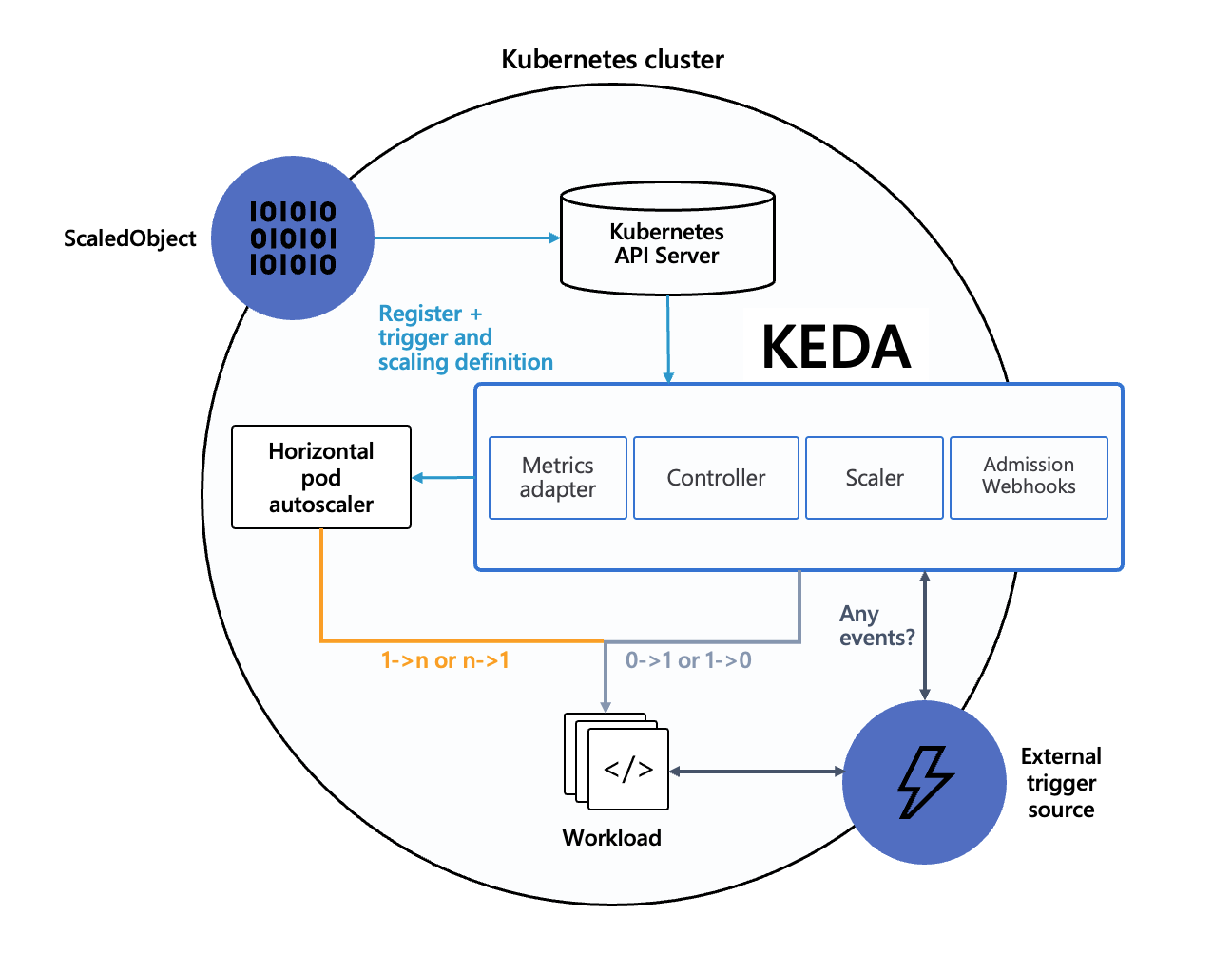
2.2.1 Kernkomponenten von KEDA
- KEDA Controller: verantwortlich für den Abgleich von benutzerdefinierten KEDA-Ressourcen wie ScaledObject und ScaledJob. Er überwacht diese Ressourcen und stellt sicher, dass der gewünschte Zustand im Kubernetes-Cluster wiedergegeben wird. Er verwaltet den Lebenszyklus von Skalierungsressourcen auf der Grundlage von im ScaledObject oder ScaledJob definierten Auslösern.
- Metrics Adapter: KEDA enthält einen integrierten Metrics Server, der die Kubernetes Metrics API erweitert. Er stellt dem Kubernetes Horizontal Pod Autoscaler (HPA) externe Metriken zur Verfügung und ermöglicht Skalierungsentscheidungen auf der Grundlage von benutzerdefinierten Metriken aus externen Ereignisquellen wie Message Queues, Datenbanken oder HTTP-Endpunkten.
- SkaliertesObjekt: Dieses Objekt definiert, wie ein Kubernetes-Einsatz oder ein zustandsabhängiges Set auf der Grundlage einer bestimmten Metrik oder eines Ereignisses skaliert werden soll. Es eignet sich für lang laufende Prozesse, die je nach Auslastung skaliert werden müssen.
- ScaledJob: Dieses Objekt ist für kurzlebige Jobs oder Stapelverarbeitungsaufgaben gedacht. Es erstellt Kubernetes-Jobs auf der Grundlage externer Ereignisse, z. B. einer Nachricht in einer Warteschlange, und skaliert die Anzahl der Jobs entsprechend der Nachfrage.
- Scaler: spezialisierte Komponenten, die mit externen Ereignisquellen oder Metriksystemen (z.B. Message Queues, Datenbanken) kommunizieren, um Metriken und Ereignisse abzurufen. Jede Art von Scaler ist für die Interaktion mit einem bestimmten externen Dienst zuständig.
- Auslöser definieren Sie die externen Ereignisquellen oder Metriken, die KEDA überwacht, um Skalierungsentscheidungen zu treffen. KEDA unterstützt über 40 verschiedene Auslöser, darunter: Message Queues (Azure Service Bus, RabbitMQ, Kafka), Datenbanken (Redis, PostgreSQL, MySQL), Überwachungssysteme (Prometheus, Azure Monitor, HTTP-Anfragen)
- Zulassung Webhooks: Validiert und mutiert KEDA-bezogene Ressourcen, bevor sie auf den Cluster angewendet werden.
2.3 Die wichtigsten Vorteile der Nutzung von KEDA
- Ereignisgesteuerte Skalierung: KEDA bietet die Möglichkeit, Kubernetes-Workloads auf der Grundlage realer Ereignisse und Metriken zu skalieren, z. B. die Anzahl der Nachrichten in einer Warteschlange oder die Länge eines Verarbeitungsrückstands.
- Flexible Trigger Unterstützung: KEDA unterstützt über 40 verschiedene Ereignisquellen, darunter Azure Monitor, Prometheus, Kafka, Redis und mehr, was es zu einer vielseitigen Wahl für verschiedene Anwendungsfälle macht.
- Nahtlos Integration mit Kubernetes: KEDA erweitert die nativen Kubernetes-Funktionen, ohne dass größere Änderungen an Ihrer bestehenden Architektur erforderlich sind. Es arbeitet mit dem Kubernetes Horizontal Pod Autoscaler (HPA) zusammen, um eine feinkörnige Kontrolle über das Skalierungsverhalten zu ermöglichen.
- Kosten Effizienz: Durch die Skalierung von Ressourcen auf der Grundlage des tatsächlichen Bedarfs trägt KEDA dazu bei, die mit einer Überversorgung verbundenen Kosten zu senken, insbesondere in Umgebungen mit schwankenden Arbeitslasten.
2.4 Beispielhafte Anwendungsfälle für KEDA
- CI/CD-Pipelines: Skalieren Sie Agenten automatisch als Reaktion auf Job-Warteschlangen, wie wir es mit Azure DevOps Agent Pools tun.
- Verarbeitung vonNachrichten : Skalieren Sie die Verbraucher dynamisch auf der Grundlage der Anzahl der Nachrichten in einer Warteschlange (z.B. Azure Service Bus, Kafka).
- Geplante Skalierung: Skalieren Sie auf der Grundlage geplanter Ereignisse, wie z. B. Batch-Verarbeitungsaufgaben oder Wartungsfenster, nach oben oder unten.
2.5 KEDA im Kontext von Azure DevOps Agent Pools
Für Szenarien wie mein eigenes, das ich in der Einleitung beschrieben habe, ermöglicht KEDA die dynamische Bereitstellung von Agenten auf der Grundlage der Anzahl der in der Warteschlange stehenden Aufträge in Azure DevOps. Indem Sie entweder eine SkaliertesObjekt oder ein ScaledJob Konfiguration kann KEDA den Agentenpool nach oben oder unten skalieren und so sicherstellen, dass Ressourcen verfügbar sind, wenn sie benötigt werden, und dass sie erhalten bleiben, wenn sie nicht benötigt werden.
3. ScaledObject vs. ScaledJob in KEDA
KEDA bietet zwei primäre Mechanismen zur Skalierung von Kubernetes-Workloads: ScaledObject und ScaledJob. Beide dienen unterschiedlichen Zwecken und haben einzigartige Eigenschaften, die sie für bestimmte Anwendungsfälle geeignet machen. In diesem Abschnitt werden wir die Unterschiede zwischen diesen beiden Mechanismen, ihre Anwendungsfälle und ihre Anwendung bei der Verwaltung von Azure DevOps Agent Pools untersuchen.
3.1 ScaledObject: Verwaltung lang laufender Workloads
Ein ScaledObject ist eine benutzerdefinierte KEDA-Ressource, die Kubernetes-Implementierungen, Stateful-Sets oder andere langlaufende Ressourcen auf der Grundlage externer Metriken oder Ereignisse skaliert. Es funktioniert durch die Integration mit dem Kubernetes Horizontal Pod Autoscaler (HPA), um die Anzahl der Replikate einer Zielressource basierend auf vordefinierten Auslösern anzupassen.
Wichtige Merkmale:
- Geeignet für lang laufende Prozesse: ScaledObjects sind ideal für Arbeitslasten, die kontinuierlich laufen und ihre Skalierung als Reaktion auf wechselnde Belastungen anpassen müssen. Beispiele hierfür sind Webanwendungen, APIs oder Hintergrunddienste.
- Skalierung in Echtzeit: Sie bieten Skalierungsfunktionen in Echtzeit, indem sie unter anderem Metriken wie Warteschlangenlänge, CPU-Auslastung oder benutzerdefinierte Metriken überwachen.
- Integration mit HPA: ScaledObjects ändert die Anzahl der Replikate von Deployments oder Stateful-Sets direkt über den nativen HPA-Mechanismus und sorgt so für eine nahtlose Integration mit den bestehenden Kubernetes-Autoskalierungsfunktionen.
- Objektanforderung: Die Konfiguration der Einsatzressource muss definiert werden, da sie die Anzahl der Replikate im Einsatz skaliert.
Beispiel für einen Anwendungsfall für Azure DevOps Agent Pools
In Szenarien, in denen Azure DevOps-Pipelines eine konstante oder vorhersehbare Anzahl von Aufträgen haben, kann ein ScaledObject verwendet werden, um die Anzahl der selbst gehosteten Agenten je nach Länge der Auftragswarteschlange zu erhöhen oder zu verringern. Auf diese Weise wird sichergestellt, dass immer genügend Agenten zur Verfügung stehen, um eingehende Aufträge zu bearbeiten, ohne dass die Ressourcen übermäßig beansprucht werden.
3.2 ScaledJob: Verwaltung kurzlebiger Batch-Workloads
Ein ScaledJob ist eine benutzerdefinierte KEDA-Ressource zur Erstellung und Verwaltung von Kubernetes-Jobs auf der Grundlage externer Ereignisse. Im Gegensatz zu ScaledObject, das lang laufende Prozesse skaliert, konzentriert sich ScaledJob auf kurzlebige Aufgaben, die unabhängig verarbeitet werden können.
Wesentliche Merkmale
- Am besten für Stapelverarbeitung geeignet: ScaledJobs sind ideal für Szenarien, in denen Aufgaben diskret und zustandslos sind, wie z.B. die Verarbeitung von Nachrichten aus einer Warteschlange oder die Ausführung von geplanten Aufträgen.
- Dynamische Auftragserstellung: Es erstellt dynamisch Kubernetes-Jobs, um Arbeitsspitzen zu bewältigen und sicherzustellen, dass jede Arbeitseinheit verarbeitet wird, sobald Ressourcen verfügbar sind.
- Automatische Bereinigung: Von ScaledJobs erstellte Aufträge werden nach Abschluss der Verarbeitung automatisch bereinigt, basierend auf dem konfigurierten successfulJobsHistoryLimit und failedJobsHistoryLimit.
Beispiel für einen Anwendungsfall für Azure DevOps Agent Pools
In Szenarien, in denen die Auftragslast sehr variabel oder sprunghaft ist und jeder Pipeline-Lauf als unabhängige Aufgabe betrachtet werden kann, können Sie mit einem ScaledJob dynamisch kurzlebige Agenten erstellen, die sich im Azure DevOps-Pool registrieren, die zugewiesene Aufgabe ausführen und sich wieder beenden. Dieser Ansatz ist besonders nützlich, wenn die Pipelines kurzlebig sind und keine dauerhaften Agenten erfordern.
3.3 Die Wahl zwischen ScaledObject und ScaledJob
Wenn Sie sich zwischen ScaledObject und ScaledJob für die Verwaltung von Azure DevOps Agent Pools entscheiden, sollten Sie die folgenden Faktoren berücksichtigen:
Arbeitsbelastung Typ
- Verwenden Sie ScaledObject, wenn die Agenten kontinuierlich laufen und einen stetigen Strom von Aufgaben verarbeiten müssen. Dies eignet sich für lang laufende Arbeitslasten, bei denen der Agent zwischen den Aufträgen nicht beendet wird.
- Verwenden Sie ScaledJob, wenn jeder Pipeline-Auftrag als unabhängige, kurzlebige Aufgabe behandelt werden kann. Bei diesem Ansatz wird für jeden Auftrag ein neuer Agent erstellt, was ideal für stoßweise oder Batch-Arbeitslasten ist.
Agent Lebenszyklus
- ScaledObject-Agenten bleiben auch dann aktiv, wenn keine Aufträge laufen. Dies ist nützlich, um die Latenzzeit beim Auftragsstart zu verringern.
- ScaledJob-Agenten werden für jeden Auftrag erstellt und vernichtet. Dadurch wird die Ressourcennutzung minimiert, wenn keine Aufträge in der Warteschlange stehen, aber es kann zu einer leichten Verzögerung beim Start neuer Aufträge kommen.
Optimierung der Ressourcen
- ScaledObject ist besser, wenn Sie eine minimale Anzahl von Agenten beibehalten müssen, um neue Aufträge schnell bearbeiten zu können.
- ScaledJob ist ressourceneffizienter für intermittierende oder unvorhersehbare Arbeitslasten, da es nur Agenten erstellt, wenn Aufträge vorhanden sind.
Wenn Sie die einzigartigen Funktionen und Möglichkeiten von ScaledObject und ScaledJob kennen, können Sie den richtigen Ansatz für Ihre spezifischen Anforderungen an den Azure DevOps Agent Pool wählen.
4. Voraussetzungen und Einrichtung für die Implementierung von KEDA mit Azure DevOps Agent Pools
Wir werden die notwendigen Voraussetzungen abdecken, einschließlich der Einrichtung von Azure Kubernetes Service (AKS) und Azure Container Registry (ACR) unter Verwendung von Terraform, sowie der Erstellung von Images für unsere Agenten mit Docker.
Für diesen Abschnitt benötigte Werkzeuge:
- Helm (Kubernetes-Paketmanager) - [Installationsanleitung]
- Azure CLI - [Installationsanleitung]
- Kubernetes Kommandozeile - [Installationsanleitung]
- Terraform (Infrastruktur als Code) - [Installationsanleitung]
- Docker Desktop - [Installationsanleitung]
4.1. Einrichten von Azure Kubernetes Service (AKS) und Azure Container Registry (ACR)
In unserem Beispiel verwenden wir die einfachste Konfiguration für unseren Kubernetes-Cluster, mit nur einem Knoten und ohne zusätzliche Netzwerk- oder Sicherheitskonfigurationen, da dies nur eine Vorstellung des Konzepts ist.
4.1.1. Terraform Konfiguration für AKS und ACR
Der nachfolgende Terraform-Code erstellt einige notwendige Ressourcen auf Ihrem Azure-Abonnement:
- Ressourcengruppe(azurerm_resource_group): Eine Ressourcengruppe, die alle Azure-Ressourcen enthält.
- Azure Container Registry(azurerm_container_registry): Die Registry zum Speichern von Docker-Images für Ihre Azure DevOps-Agenten.
- Azure Kubernetes Service (azurerm_kubernetes_cluster): Ein AKS-Cluster mit einem Standard-Knotenpool zur Bereitstellung Ihrer Workloads.
- Azure-Rollenzuweisung(azurerm_role_assignment): Erforderliche Rollenzuweisung, um sicherzustellen, dass der AKS-Cluster Images aus dem ACR abrufen kann.
Stellen Sie sicher, dass Ihr Terraform-Projekt die folgenden Dateien enthält:
├── main.tf
├── providers.tf
└── variables.tf (optional, if using variables)################
# providers.tf #
################
terraform {
required_version = ">=1.5"
required_providers {
azurerm = {
source = "hashicorp/azurerm"
version = "~>4.0"
}
azuread = {
source = "hashicorp/azuread"
version = "~>2.0"
}
}
}
provider "azurerm" {
features {
resource_group {
prevent_deletion_if_contains_resources = false
}
}
}
provider "azuread" {
# Azure AD provider can be used for advanced configuration if needed
}###########
# main.tf #
###########
resource "azurerm_resource_group" "build-agent-rg" {
name = "uks-build-agent-rg"
location = "UK South"
}
resource "azurerm_container_registry" "build-agent-registry" {
name = "uksbuildagentacrjdkedapoc"
resource_group_name = azurerm_resource_group.build-agent-rg.name
location = azurerm_resource_group.build-agent-rg.location
sku = "Basic"
admin_enabled = "true"
}
resource "azurerm_kubernetes_cluster" "build-agent-cluster" {
name = "uks-build-agent-aks"
location = azurerm_resource_group.build-agent-rg.location
resource_group_name = azurerm_resource_group.build-agent-rg.name
dns_prefix = "uks-build-agent-aks"
default_node_pool {
name = "default"
node_count = 1
vm_size = "Standard_D2_v2"
}
identity {
type = "SystemAssigned"
}
tags = {
Environment = "Test"
}
}
resource "azurerm_role_assignment" "acr-role-assignment" {
principal_id = azurerm_kubernetes_cluster.build-agent-cluster.kubelet_identity[0].object_id
role_definition_name = "AcrPull"
scope = azurerm_container_registry.build-agent-registry.id
skip_service_principal_aad_check = true
}Führen Sie die folgenden Befehle in Ihrem Terraform-Verzeichnis aus, um die Infrastruktur bereitzustellen:
# Initialize the Terraform working directory
terraform init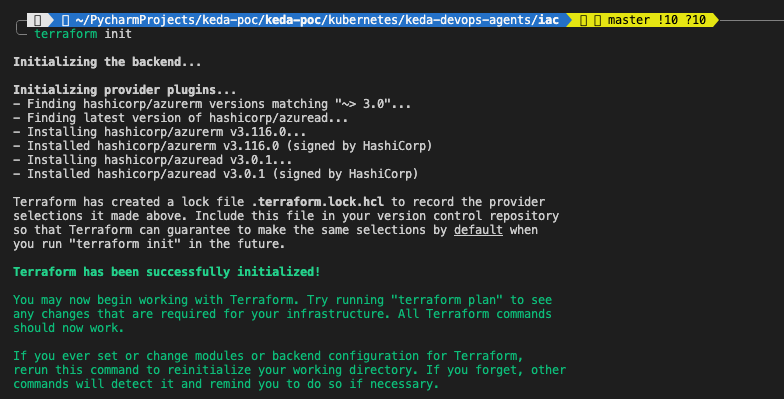
# Check plan configuration to be applied
terraform plan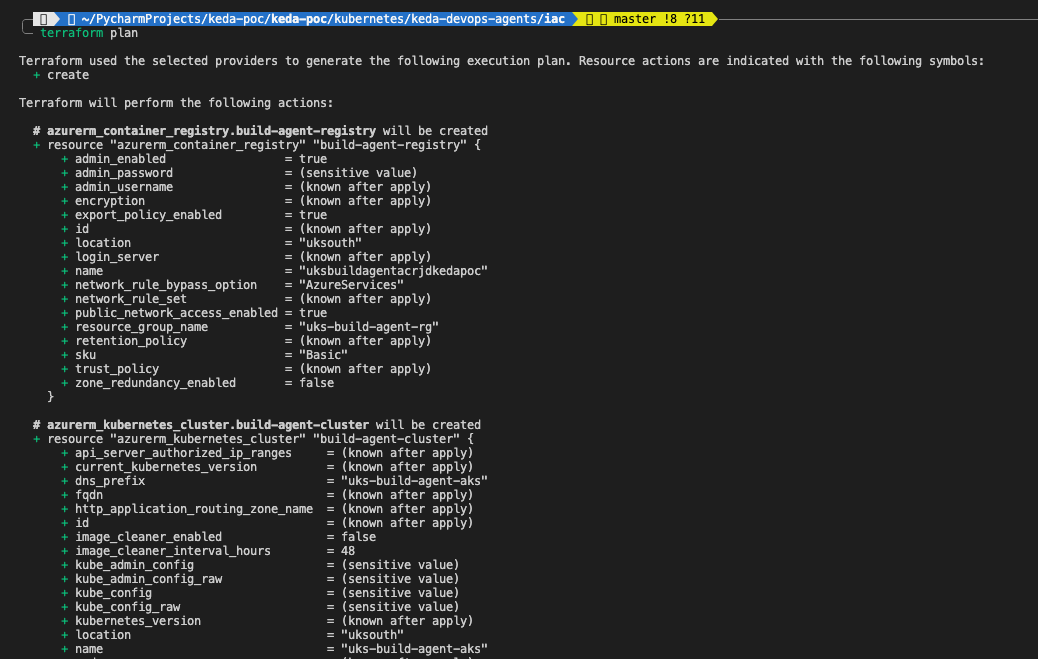
# Apply the Terraform configuration to create the resources
terraform apply -auto-approve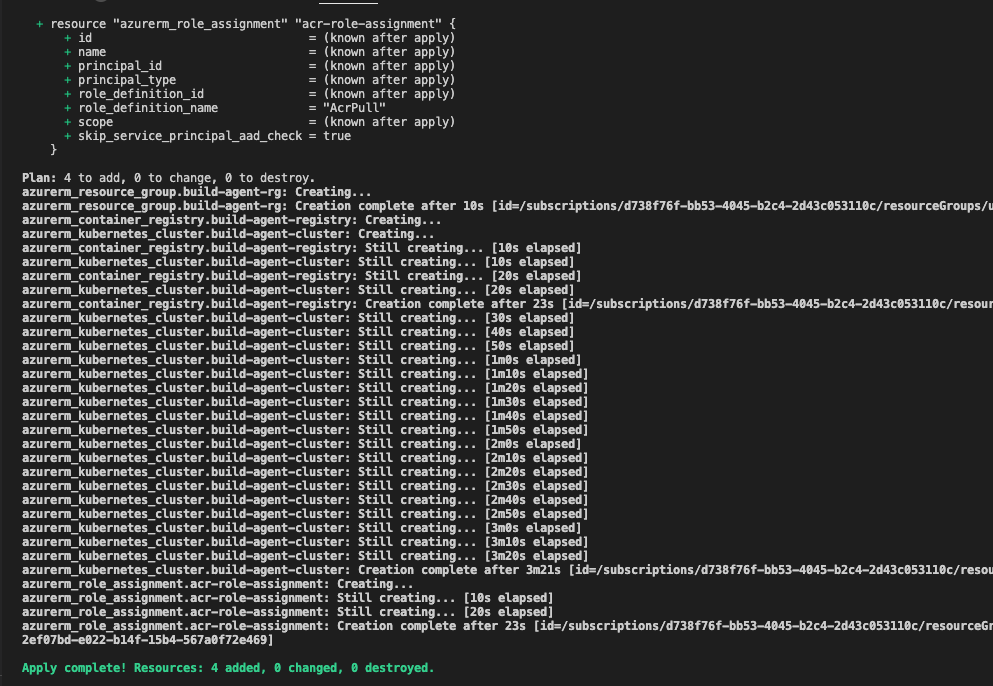
Wenn alle Befehle erfolgreich ausgeführt wurden, sollten wir in Azure alle benötigten Ressourcen erstellt haben.
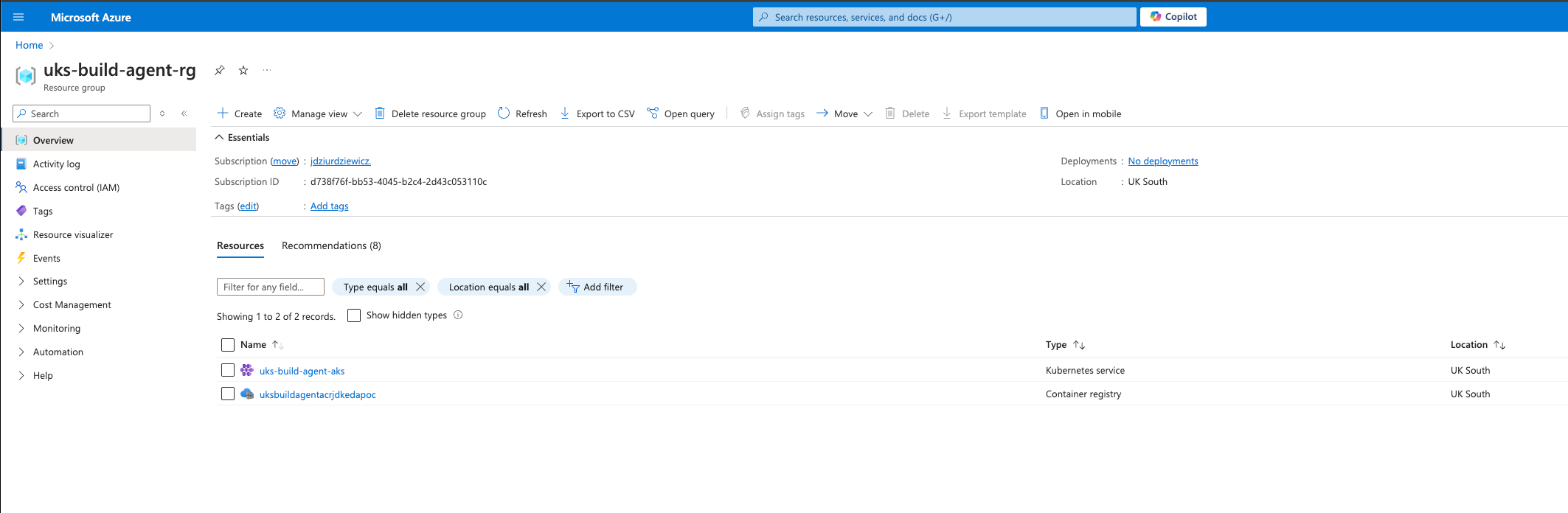
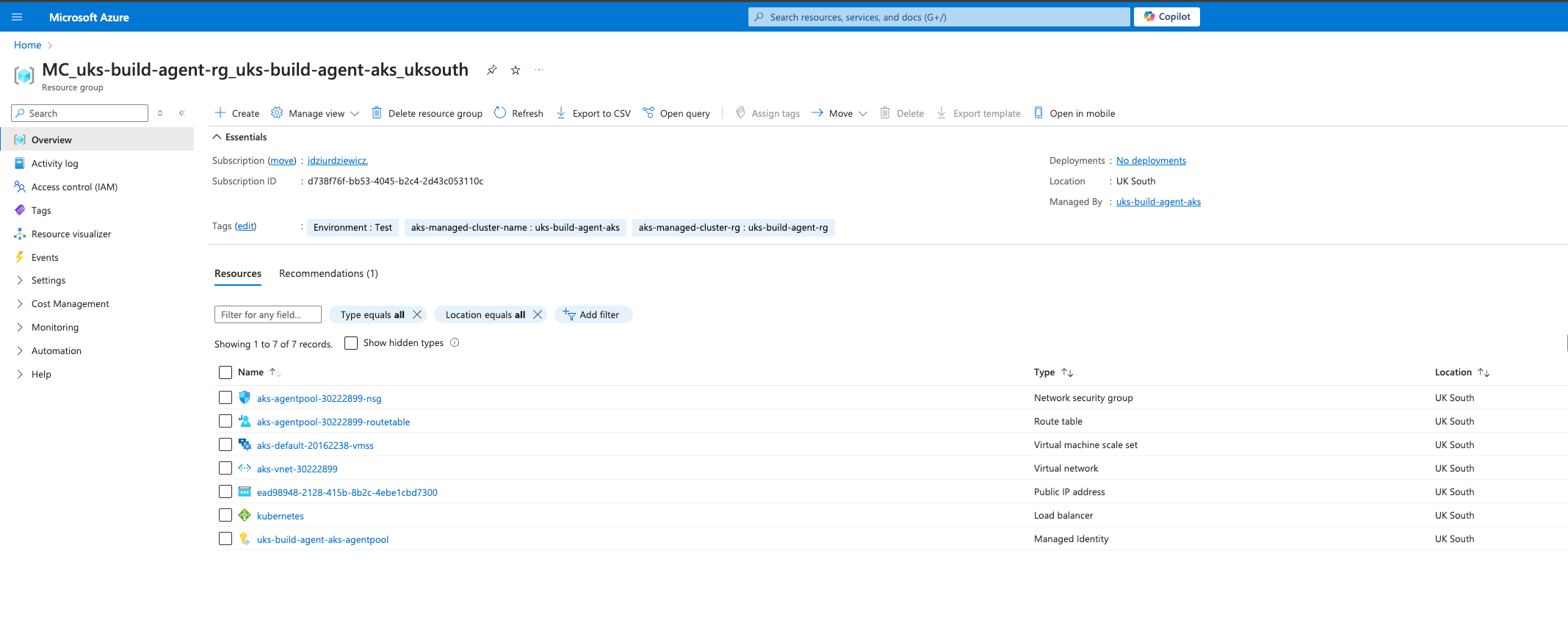
Nachdem der AKS-Cluster bereitgestellt wurde, lösen Sie den folgenden Vorgang aus, um Ihre lokale kubectl Client für die Interaktion mit einem Azure Kubernetes Service (AKS)-Cluster. Wenn Sie diesen Befehl ausführen, werden die AKS-Anmeldeinformationen abgerufen und in Ihren kubeconfig Datei, die es Ihnen ermöglicht, die kubectl Befehle zur Verwaltung des Clusters:
az aks get-credentials --resource-group uks-build-agent-rg --name uks-build-agent-aks4.1.2. Docker Image für Azure DevOps Agent
Der nächste Schritt wird die Vorbereitung der benutzerdefinierten Dockerdatei für unser Image, das von Kubernetes als Quell-Image für Container verwendet werden soll. Beispiele finden Sie direkt auf der Microsoft-Website, aber in unserem Fall werden wir Folgendes verwenden Bilddefinition von von Martin Lakov, zusammen mit bearbeiteten start.sh Skript, das die zusätzliche Flags zum Entfernen nicht benötigter Pipeline-Agenten und zum Beenden des Container-Prozesses nach Abschluss des Auftrags.
##############
# Dockerfile #
##############
FROM ubuntu:20.04
# Set DEBIAN_FRONTEND and TARGETARCH environment variables
ENV DEBIAN_FRONTEND=noninteractive
TARGETARCH=linux-x64
# Combine apt-get update, upgrade, package installation, Azure CLI installation, and PowerShell installation into one RUN command
RUN apt-get update &&
apt-get upgrade -y &&
apt-get install -y -qq --no-install-recommends
apt-transport-https
apt-utils
ca-certificates
curl
git
iputils-ping
jq
lsb-release
software-properties-common
wget &&
curl -sL https://aka.ms/InstallAzureCLIDeb | bash &&
wget -q https://github.com/PowerShell/PowerShell/releases/download/v7.1.5/powershell-7.1.5-linux-x64.tar.gz -O /tmp/powershell.tar.gz &&
mkdir -p /opt/microsoft/powershell/7 &&
tar zxf /tmp/powershell.tar.gz -C /opt/microsoft/powershell/7 &&
ln -s /opt/microsoft/powershell/7/pwsh /usr/bin/pwsh &&
rm -rf /var/lib/apt/lists/* /tmp/powershell.tar.gz
# Set working directory
WORKDIR /azp
# Copy the startup script and ensure it's executable
COPY --chmod=755 ./start.sh .
# Set the entry point
ENTRYPOINT [ "./start.sh" ]############
# start.sh #
############
#!/bin/bash
set -e
if [ -z "$AZP_URL" ]; then
echo 1>&2 "error: missing AZP_URL environment variable"
exit 1
fi
if [ -z "$AZP_TOKEN_FILE" ]; then
if [ -z "$AZP_TOKEN" ]; then
echo 1>&2 "error: missing AZP_TOKEN environment variable"
exit 1
fi
AZP_TOKEN_FILE=/azp/.token
echo -n $AZP_TOKEN > "$AZP_TOKEN_FILE"
fi
unset AZP_TOKEN
if [ -n "$AZP_WORK" ]; then
mkdir -p "$AZP_WORK"
fi
export AGENT_ALLOW_RUNASROOT="1"
cleanup() {
if [ -e config.sh ]; then
print_header "Cleanup. Removing Azure Pipelines agent..."
# If the agent has some running jobs, the configuration removal process will fail.
# So, give it some time to finish the job.
while true; do
./config.sh remove --unattended --auth PAT --token $(cat "$AZP_TOKEN_FILE") && break
echo "Retrying in 30 seconds..."
sleep 30
done
fi
}
print_header() {
lightcyan='33[1;36m'
nocolor='33[0m'
echo -e "${lightcyan}$1${nocolor}"
}
# Let the agent ignore the token env variables
export VSO_AGENT_IGNORE=AZP_TOKEN,AZP_TOKEN_FILE
print_header "1. Determining matching Azure Pipelines agent..."
AZP_AGENT_PACKAGES=$(curl -LsS
-u user:$(cat "$AZP_TOKEN_FILE")
-H 'Accept:application/json;'
"$AZP_URL/_apis/distributedtask/packages/agent?platform=$TARGETARCH&top=1")
AZP_AGENT_PACKAGE_LATEST_URL=$(echo "$AZP_AGENT_PACKAGES" | jq -r '.value[0].downloadUrl')
if [ -z "$AZP_AGENT_PACKAGE_LATEST_URL" -o "$AZP_AGENT_PACKAGE_LATEST_URL" == "null" ]; then
echo 1>&2 "error: could not determine a matching Azure Pipelines agent"
echo 1>&2 "check that account '$AZP_URL' is correct and the token is valid for that account"
exit 1
fi
print_header "2. Downloading and extracting Azure Pipelines agent..."
curl -LsS $AZP_AGENT_PACKAGE_LATEST_URL | tar -xz & wait $!
source ./env.sh
print_header "3. Configuring Azure Pipelines agent..."
./config.sh --unattended
--agent "${AZP_AGENT_NAME:-$(hostname)}"
--url "$AZP_URL"
--auth PAT
--token $(cat "$AZP_TOKEN_FILE")
--pool "${AZP_POOL:-Default}"
--work "${AZP_WORK:-_work}"
--replace
--acceptTeeEula & wait $!
print_header "4. Running Azure Pipelines agent..."
trap 'cleanup; exit 0' EXIT
trap 'cleanup; exit 130' INT
trap 'cleanup; exit 143' TERM
chmod +x ./run.sh
# To be aware of TERM and INT signals call run.sh
# Running it with the --once flag at the end will shut down the agent after the build is executed
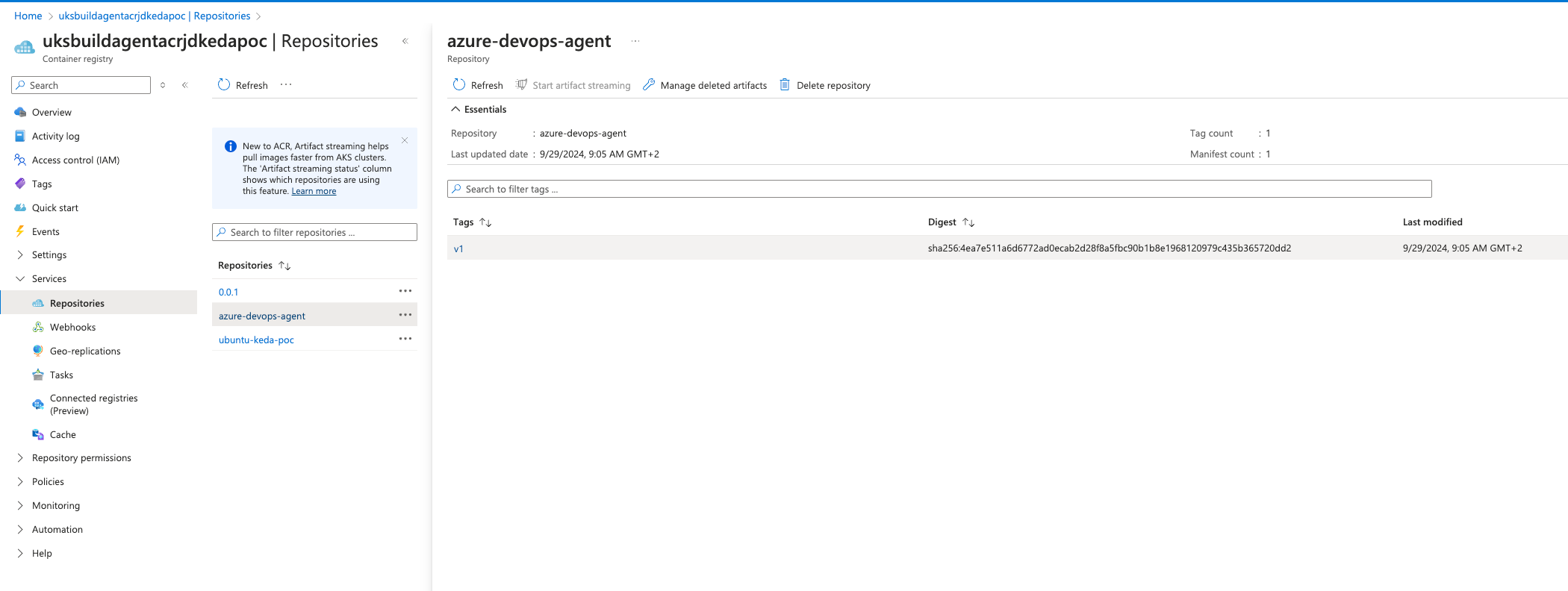
./run.sh "$@" --once & wait $!Build-Image und schieben Sie es zu unserer Azure Container Registry.
# Build the Docker image
docker build -t uksbuildagentacrjdkedapoc.azurecr.io/azure-devops-agent:v1 .
# If you are using machine with ARM architecture CPU for build, check platform compatibility, and add according one to --platform param
kubectl get nodes -o wide
docker build --platform="linux/amd64" -t uksbuildagentacrjdkedapoc.azurecr.io/azure-devops-agent:v1 .
# Additionally you can test our build by running the container, before pushing it to ACR (You can get values for envs from the container registry in the portal)
docker run -e AZP_URL= -e AZP_TOKEN= -e AZP_AGENT_NAME= -e AZP_POOL= <image>
# Log in to ACR (credential can be found under Settings/Access keys tab in Azure Container Registry)
az acr login --name uksbuildagentacrjdkedapoc
# Push the image to ACR
docker push uksbuildagentacrjdkedapoc.azurecr.io/azure-devops-agent:v1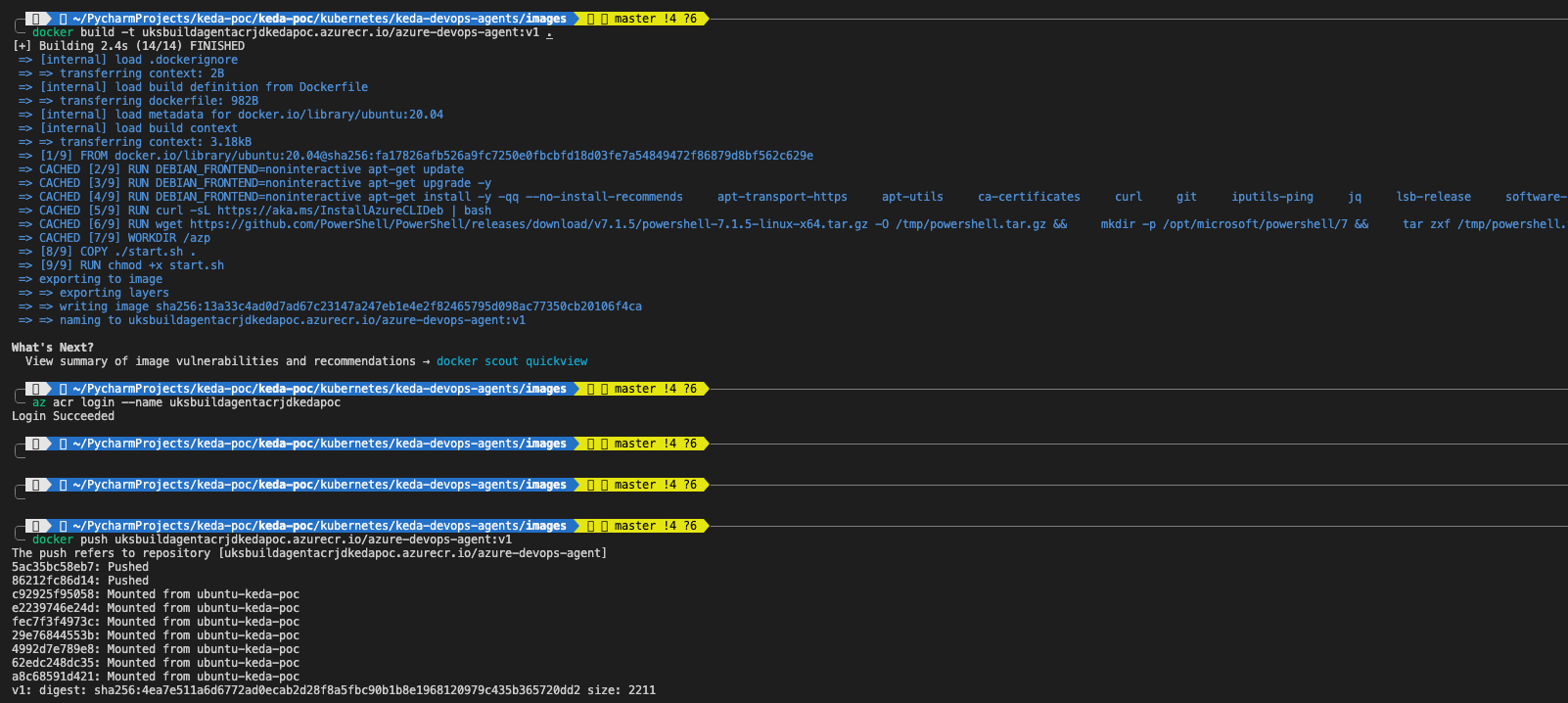
4.2. KEDA zum AKS-Cluster hinzufügen
KEDA kann als eine Erweiterung für Kubernetes betrachtet werden und ist keine eingebaute Funktion, daher müssen wir es installieren. In den folgenden Schritten werden wir Helm verwenden, um alles in einem Setup zu haben (alle für die Installation erforderlichen Manifeste finden Sie auf der KEDA-Website und können direkt ohne Helm angewendet werden).
Fügen Sie das KEDA Helm-Repository hinzu:
helm repo add kedacore https://kedacore.github.io/charts<br>helm repo updateInstallieren Sie KEDA mit Helm (Dadurch wird KEDA in Ihrem Kubernetes-Cluster unter dem Verzeichnis keda Namespace):
helm install keda kedacore/keda --namespace keda --create-namespace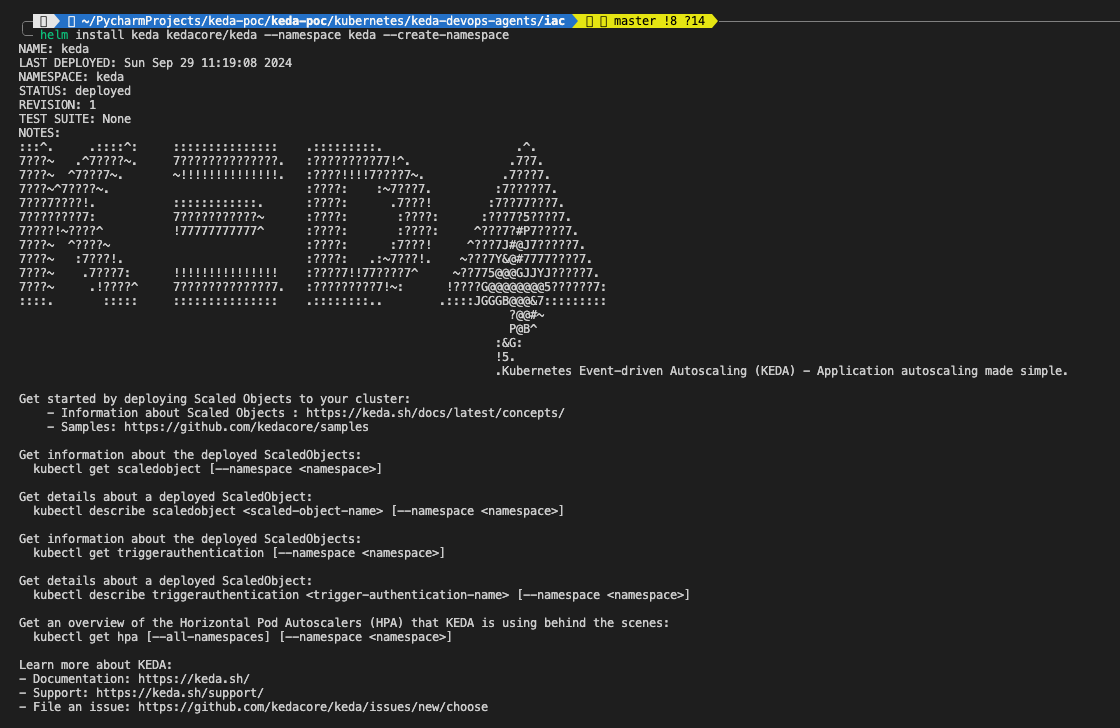
Überprüfen Sie die Installation, indem Sie kontrollieren, ob die KEDA-Komponenten installiert sind und laufen:
kubectl get all -n kedaWenn keine Fehler festgestellt wurden, haben wir erfolgreich die grundlegenden Komponenten eingerichtet, die für die Implementierung der KEDA-basierten automatischen Skalierung für Azure DevOps Agent Pools erforderlich sind. Sie haben jetzt einen AKS-Cluster mit einem angeschlossenen ACR und KEDA für die Verwaltung der Skalierung installiert.
5. Implementierung von KEDA ScaledJob für Azure DevOps Agent Pools
In diesem Abschnitt werden wir KEDA so konfigurieren, dass Azure DevOps-Agenten mithilfe der ScaledJob-Ressource dynamisch skaliert werden. Obwohl eine Bereitstellung bei der Verwendung von ScaledJob nicht unbedingt erforderlich ist, werden wir sie dennoch nutzen, da wir sonst keine ungenutzten Agenten haben und Azure-Pipeline-Jobs nicht in die Warteschlange eines leeren Agent Pools gestellt werden können.
5.1. Konfigurieren Sie den Azure DevOps Agent Pool und das persönliche Zugriffstoken
Bevor wir damit beginnen, Konfigurationen auf unseren neu erstellten AKS-Cluster anzuwenden, ist es wichtig, die Azure DevOps-Umgebung einzurichten. Wir müssen einen selbst gehosteten Agentenpool auf Organisationsebene erstellen und ein Personal Access Token (PAT) generieren.
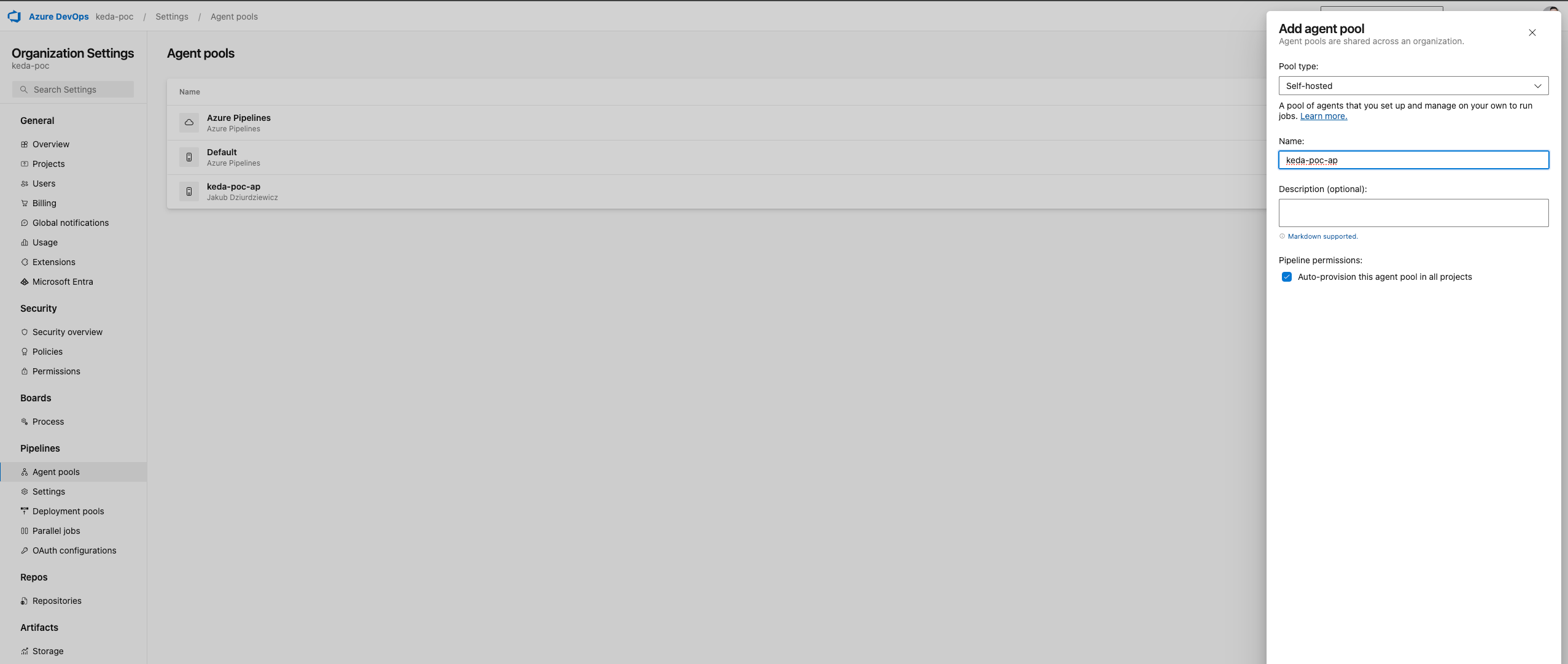
5.1.1. Azure DevOps Agent Pool & persönliches Zugriffstoken erstellen
Bevor Sie Azure DevOps-Agenten auf Ihrem AKS-Cluster konfigurieren, müssen Sie einen Agentenpool erstellen. Dieser Pool dient als Zielort, an dem sich Ihre selbst gehosteten Agenten registrieren und Aufträge ausführen, was eine bessere Kontrolle und Verwaltung der Ressourcen ermöglicht.
Detaillierte Schritte zur Erstellung eines Agent Pools finden Sie direkt auf der Microsoft-Website: Configuring Agent Pools
Denken Sie daran:
- Erstellen Sie sie als Organisationsebene
- Legen Sie es als selbstgehosteten Typ fest
- Behalten Sie den Namen und die Kennung des Agentenpools (wir werden sie später in den K8s-Manifesten verwenden)
5.1.2. Persönliches Zugangstoken erstellen
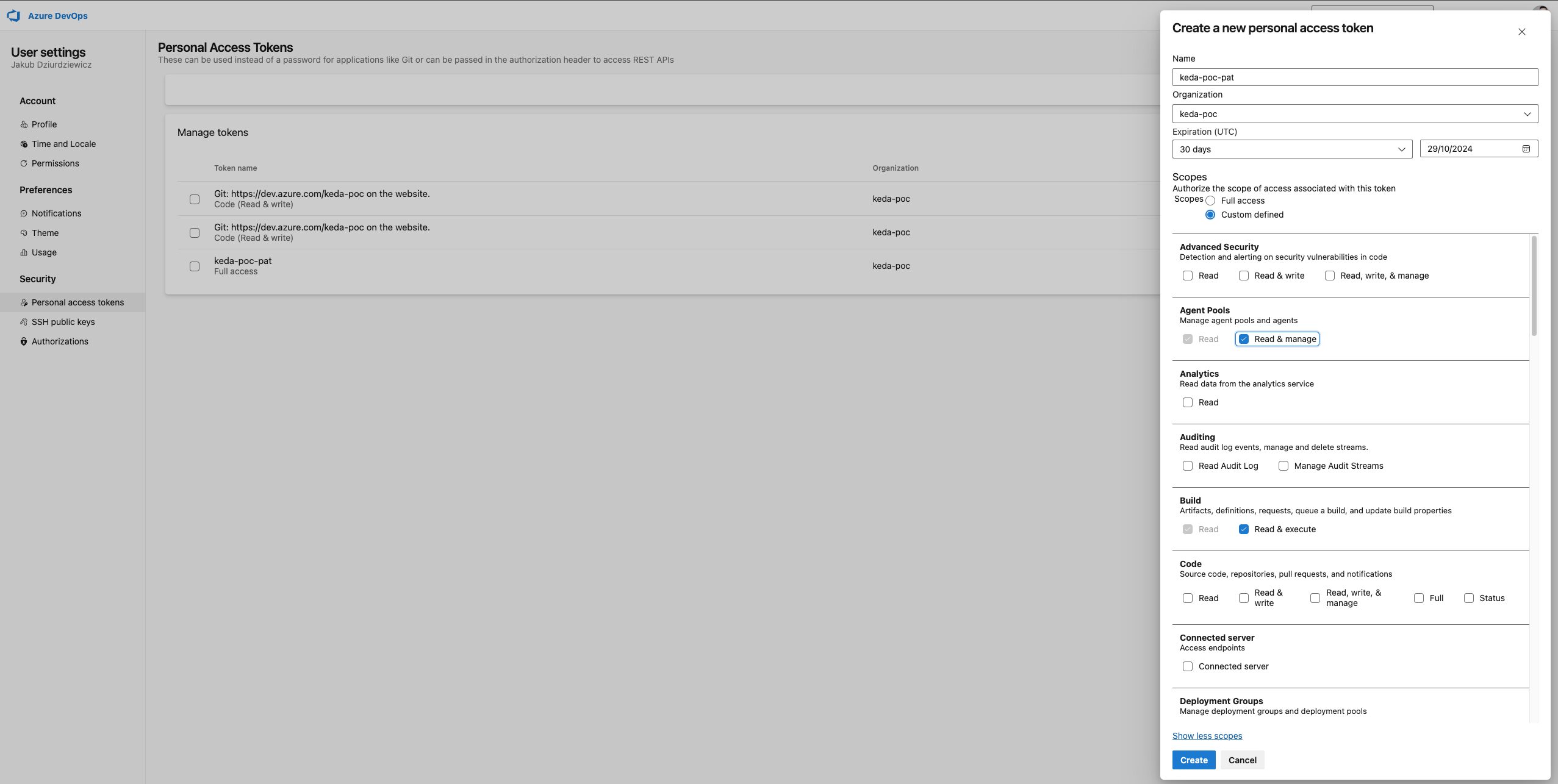
Damit sich Ihre selbst gehosteten Agenten authentifizieren und mit Azure DevOps verbinden können, müssen Sie ein Personal Access Token (PAT) erstellen. Dieses Token bietet sicheren Zugang zu Ihrem Unternehmen und Ihrem Agentenpool und stellt sicher, dass die Agenten effektiv mit den Azure DevOps-Diensten kommunizieren können.
Ähnlich wie bei den Agent Pools werde ich das Rad nicht neu erfinden und Sie einfach auf die Microsoft-Website weiterleiten: Configuring Personal Access Tokens.
Denken Sie daran:
- Kopieren Sie PAT an einen sicheren Ort, da es nicht mehr sichtbar sein wird.
- Legen Sie die Berechtigungen gemäß dem "least privilege" Prinzip fest, indem Sie nur die notwendigen Bereiche auswählen:
- Agentenpools (Lesen & Verwalten): Erforderlich, damit sich der Agent im Pool registrieren kann und damit KEDA die Poolgröße verwalten kann.
- Build (Lesen & Ausführen): Erforderlich, wenn der Agent auf Build-Pipelines zugreifen muss.
- Projekt und Team (Lesen): Erforderlich, damit der Agent Projektinformationen lesen kann, z.B. Pipeline-Definitionen.
- Benutzerprofil (Lesen): Erforderlich, damit der Agent sich authentifizieren und auf Benutzerprofilinformationen zugreifen kann.
Sobald das PAT generiert ist, müssen wir es in das base64-Format kodieren, was mit dem folgenden Befehl geschehen kann:
echo -n "your-pat-token" | base645.2. Konfigurieren Sie ScaledJob und die Bereitstellung
Lassen Sie uns zunächst Secret definieren, das unser Azure DevOps PAT aufbewahren und erstellen wird.
###############
# secret.yaml #
###############
apiVersion: v1
kind: Secret
metadata:
name: azdevops
data:
AZP_TOKEN: <base64-encoded-ADOPAT> # Replace with your base64 encoded PATkubectl apply -f secret.yamlJetzt können wir zu Deployment, die sicherstellt, dass immer mindestens ein Agent im Pool verfügbar ist. Diese Bereitstellung verwendet die benutzerdefinierte Docker Bild die wir bereits besprochen haben und die die benutzerdefinierte start.sh Skript für die Einrichtung und Ausführung des Agenten.
###################
# deployment.yaml #
###################
apiVersion: apps/v1
kind: Deployment
metadata:
name: azdevops-deployment
namespace: default
labels:
app: azdevops-agent
spec:
replicas: 1 # Keep at least one agent running at all times
selector:
matchLabels:
app: azdevops-agent
template:
metadata:
labels:
app: azdevops-agent
spec:
containers:
- name: azdevops-agent
image: uksbuildagentacrjdkedapoc.azurecr.io/azure-devops-agent:v1
env:
- name: AZP_URL
value: "https://dev.azure.com/<organization>"
- name: AZP_POOL
value: "<agent-pool-name>"
- name: AZP_TOKEN
valueFrom:
secretKeyRef:
name: azdevops
key: AZP_TOKENkubectl apply -f deployment.yamlAm Ende konfigurieren wir die ScaledJob Ressource, die dynamisch zusätzliche Agenten auf Basis der Azure DevOps Pipelines-Arbeitslast erstellt.
#########################
# keda-scaled-jobs.yaml #
#########################
apiVersion: keda.sh/v1alpha1
kind: ScaledJob
metadata:
name: azdevops-scaledjob
namespace: default
spec:
jobTargetRef:
template:
spec:
containers:
- name: azure-devops-agent
image: uksbuildagentacrjdkedapoc.azurecr.io/azure-devops-agent:v1
imagePullPolicy: Always
env:
- name: AZP_URL
value: "https://dev.azure.com/<organization>"
- name: AZP_POOL
value: "<agent-pool-name>"
- name: AZP_TOKEN
valueFrom:
secretKeyRef:
name: azdevops
key: AZP_TOKEN
pollingInterval: 10 # Check for new jobs every 10 seconds
maxReplicaCount: 10 # Maximum number of agents to be created by this ScaledJob
successfulJobsHistoryLimit: 5 # Number of successful jobs to retain
FailedJobsHistoryLimit: 5 # Number of failed jobs to retain
scalingStrategy:
strategy: "default"
triggers:
- type: azure-pipelines
metadata:
poolID: "<pool-id>"
organizationURLFromEnv: "AZP_URL"
personalAccessTokenFromEnv: "AZP_TOKEN"kubectl apply -f keda-scaled-jobs.yamlÜberprüfen Sie, ob alle Kubernetes-Ressourcen korrekt erstellt wurden
kubectl get secret
kubectl get all
kubectl get scaledjob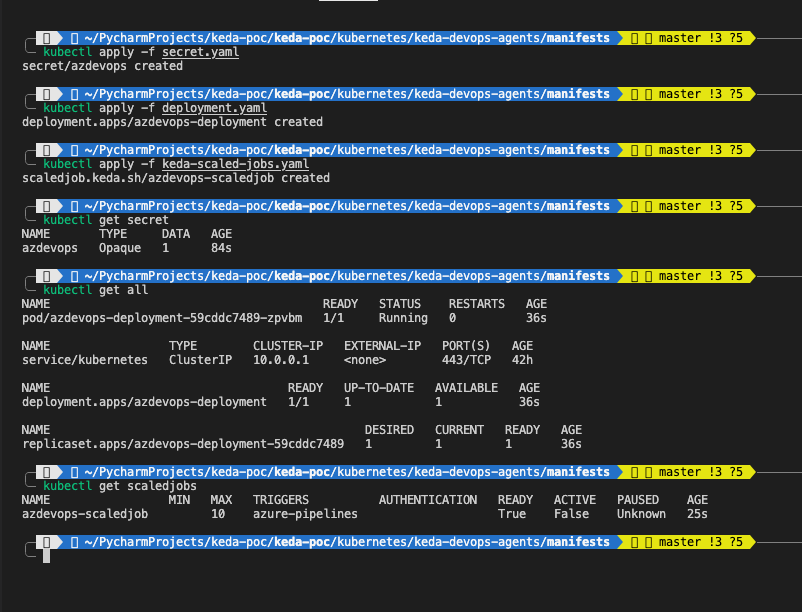
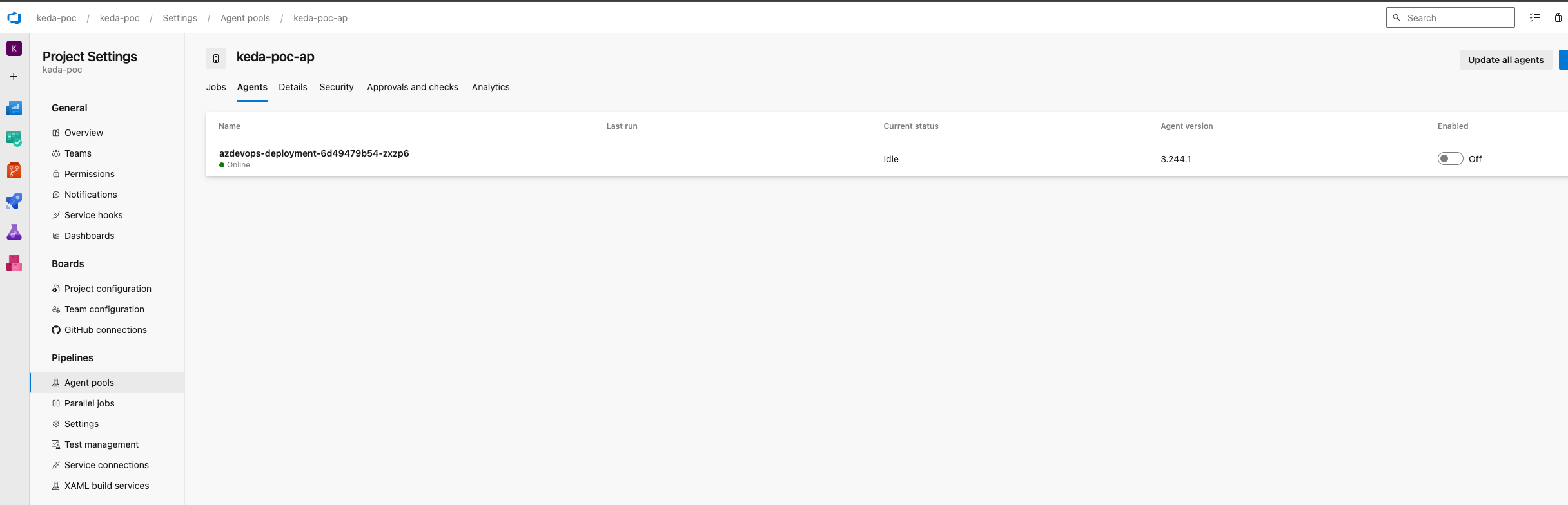
Überprüfen Sie in Azure DevOps, ob unser einzelner, veralteter Agent korrekt registriert wurde und deaktivieren Sie ihn.
Nach der Konfiguration des Agentenpools und der Bereitstellung eines Agenten ist es wichtig, zu überprüfen, ob der Agent korrekt in Azure DevOps registriert wurde und ihn zu deaktivieren. Azure DevOps verlangt, dass mindestens ein Agent im Agentenpool vorhanden ist, um Fehler bei der Einreihung von Aufträgen in die Warteschlange zu vermeiden -- Wenn kein Agent im Pool verfügbar ist, zeigt Azure DevOps einen Fehler an, wenn es versucht, Pipeline-Aufträge in die Warteschlange einzureihen. Dies kann zu Problemen führen, da KEDA skaliert Agenten je nach Bedarf und in unserem Fall wird ScaledJob keine Ressourcen erzeugen, bis der Auftrag erfolgreich in die Warteschlange des Pools aufgenommen wurde. Indem Sie den Agenten deaktivieren, stellen Sie sicher, dass er nicht versehentlich zur Verarbeitung von Pipeline-Aufträgen verwendet wird und keine Systemressourcen verbraucht. Das ist wichtig, denn dieser Agent ist als Workaround gedacht, um Fehler zu vermeiden, und nicht als Arbeitsagent, der Arbeitslasten verarbeiten soll.
5.3. Zeit, es zu testen!
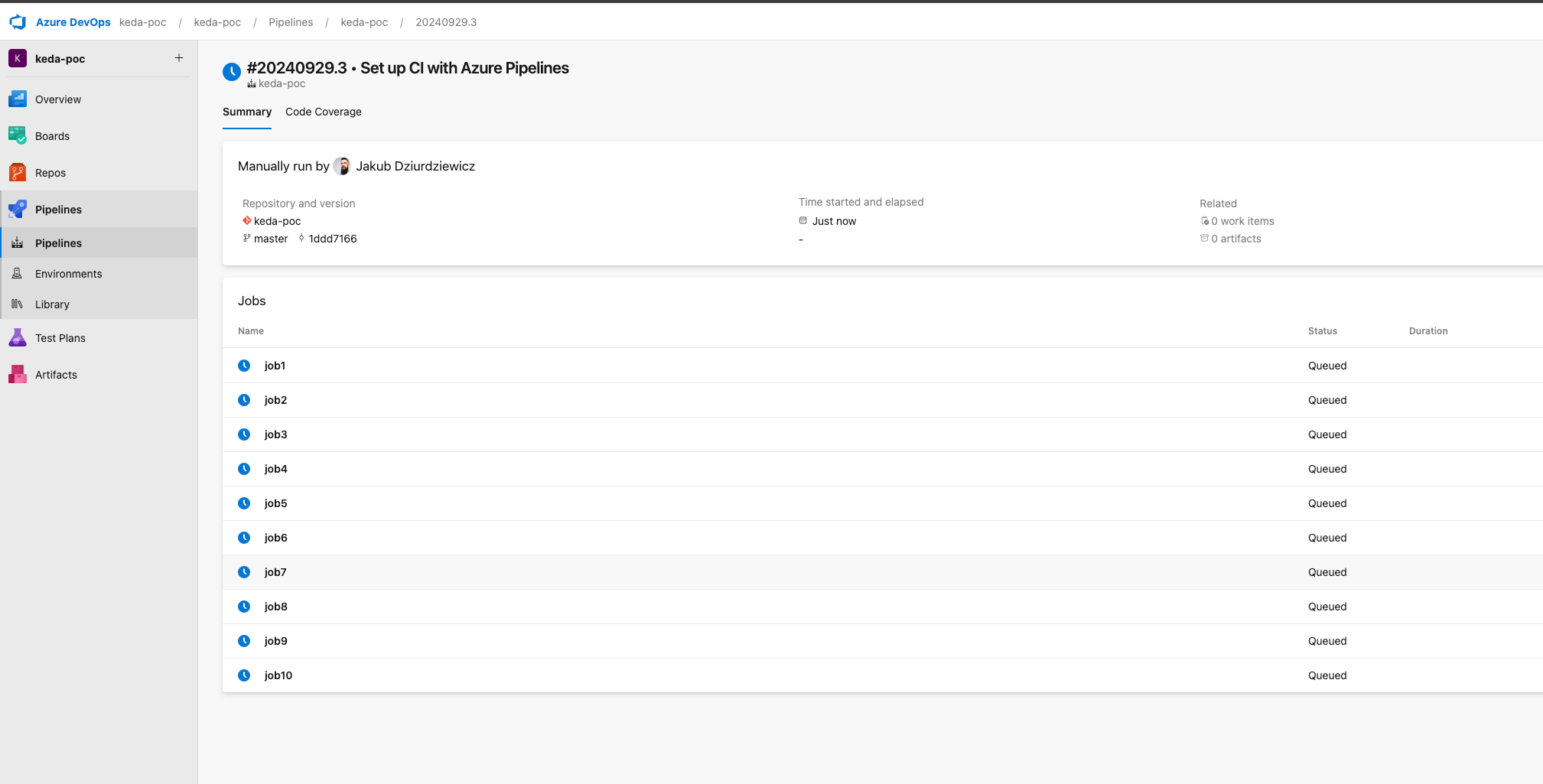
Jetzt ist es endlich an der Zeit, zu überprüfen, wie sich unser Setup in der Praxis verhält. Wenn alles wie vorgesehen funktioniert, wird KEDA die Azure DevOps-Warteschlange regelmäßig auf der Grundlage des konfigurierten Intervalls auf neue Aufträge überprüfen. Um dies zu testen, können Sie eine Pipeline in Ihrer Azure DevOps mit dem unten stehenden Code, der 10 gleichzeitige Aufträge initiiert, die jeweils ein PowerShell-Skript mit Schleifenoperationen ausführen. Führen Sie diese Pipeline aus, um zu beobachten, wie KEDA die Agenten als Reaktion auf die Schwankungen der Arbeitslast dynamisch skaliert.
##################
# load-test.yaml #
##################
trigger: none
pool: <pool-name>
jobs:
- job: job1
steps:
- task: PowerShell@2
displayName: loop1
inputs:
targetType: 'inline'
script: |
for($i=1;$i -le 15;$i++)
{
Start-Sleep -Seconds 60
}
- job: job2
steps:
- task: PowerShell@2
displayName: loop2
inputs:
targetType: 'inline'
script: |
for($i=1;$i -le 15;$i++)
{
Start-Sleep -Seconds 60
}
- job: job3
steps:
- task: PowerShell@2
displayName: loop2
inputs:
targetType: 'inline'
script: |
for($i=1;$i -le 15;$i++)
{
Start-Sleep -Seconds 60
}
- job: job4
steps:
- task: PowerShell@2
displayName: loop2
inputs:
targetType: 'inline'
script: |
for($i=1;$i -le 15;$i++)
{
Start-Sleep -Seconds 60
}
- job: job5
steps:
- task: PowerShell@2
displayName: loop2
inputs:
targetType: 'inline'
script: |
for($i=1;$i -le 15;$i++)
{
Start-Sleep -Seconds 60
}
- job: job6
steps:
- task: PowerShell@2
displayName: loop2
inputs:
targetType: 'inline'
script: |
for($i=1;$i -le 15;$i++)
{
Start-Sleep -Seconds 60
}
- job: job7
steps:
- task: PowerShell@2
displayName: loop2
inputs:
targetType: 'inline'
script: |
for($i=1;$i -le 15;$i++)
{
Start-Sleep -Seconds 60
}
- job: job8
steps:
- task: PowerShell@2
displayName: loop2
inputs:
targetType: 'inline'
script: |
for($i=1;$i -le 15;$i++)
{
Start-Sleep -Seconds 60
}
- job: job9
steps:
- task: PowerShell@2
displayName: loop2
inputs:
targetType: 'inline'
script: |
for($i=1;$i -le 15;$i++)
{
Start-Sleep -Seconds 60
}
- job: job10
steps:
- task: PowerShell@2
displayName: loop2
inputs:
targetType: 'inline'
script: |
for($i=1;$i -le 15;$i++)
{
Start-Sleep -Seconds 60
}Gleichzeitige Aufträge stehen in der Warteschlange
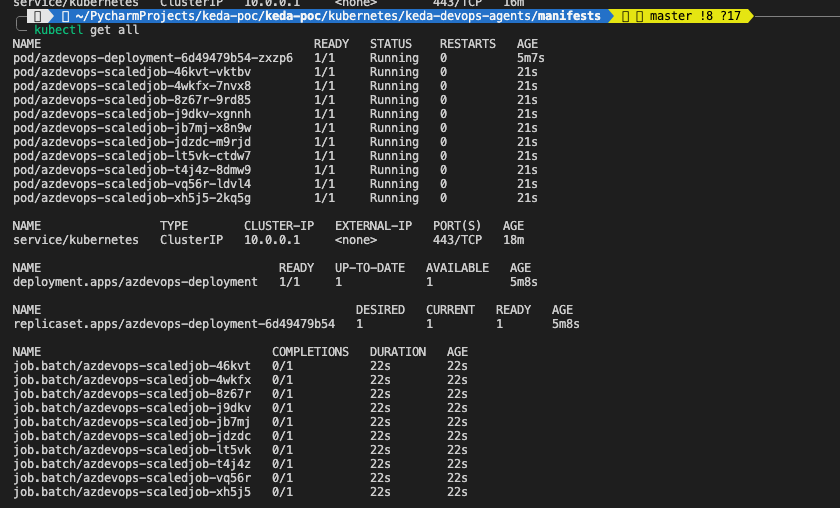
Kubernetes-Pods werden je nach Auslastung der Jobs erzeugt
Es werden neue Agenten hinzugefügt
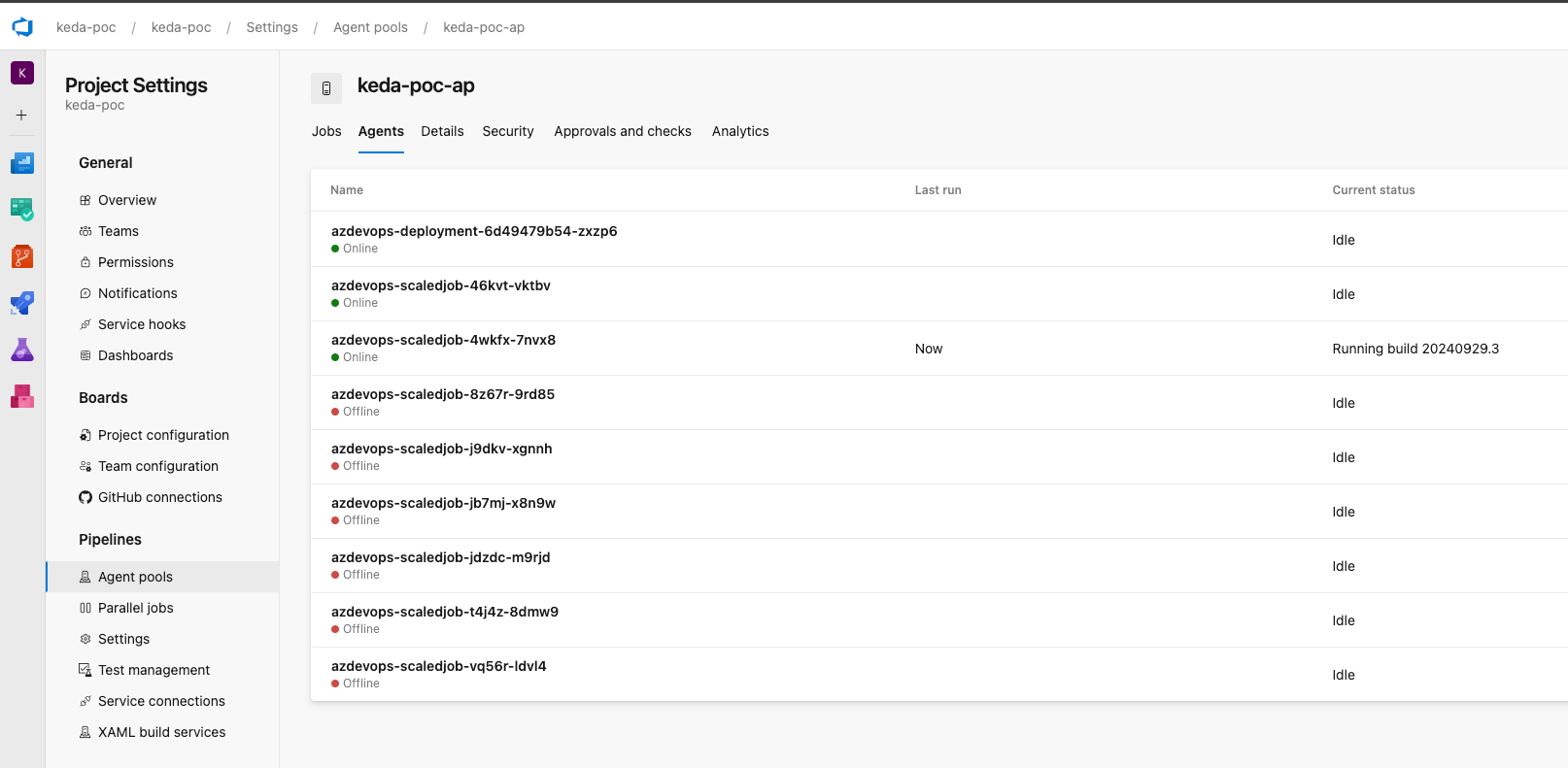
Und das ist alles, Leute! KEDA hat eine entsprechende Anzahl von Agenten für die in der Warteschlange stehenden Aufträge erzeugt. Jetzt hat jeder Auftrag seinen eigenen Agenten, auf dem er ausgeführt wird (dies kann angepasst werden), und nach Abschluss des Auftrags wird der Agent wie folgt entfernt erfolgreiche/fehlgeschlagene Konfiguration der Grenzwerte in unseren K8s-Manifesten.
6. Tipps für KEDA und die automatische Skalierung von Azure DevOps Agent Pools
Die automatische Skalierung von Azure DevOps Agent Pools mit KEDA erfordert eine sorgfältige Planung und Konfiguration, um eine effiziente Ressourcennutzung, geringere Latenzzeiten und einen reibungslosen CI/CD-Betrieb sicherzustellen. Im Folgenden finden Sie einige Hinweise, die Sie bei der Implementierung dieser Lösung beachten sollten:
- Abgebrochene Aufträge: Wenn ein Auftrag in der Pipeline abgebrochen wird, läuft der Agent/Pod noch weiter und wird nicht gelöscht, als ob der Auftrag abgeschlossen worden wäre. Dies ist ein bekanntes Problem mit KEDA.
- Vorgefertigte Images verwenden: Erstellen Sie benutzerdefinierte Docker-Images für Ihre Agenten, die alle erforderlichen Tools und Abhängigkeiten enthalten. Dadurch wird die Initialisierungszeit verkürzt, so dass sich Agenten schneller bei Azure DevOps registrieren und ohne Verzögerung mit der Verarbeitung von Aufträgen beginnen können.
- Minimieren Sie Startup-Skripte: Vereinfachen und optimieren Sie die start.sh Skript, das Sie im vorherigen Teil dieses Artikels kennengelernt haben, um die Zeit zu verkürzen, die Agenten benötigen, um sich zu registrieren und verfügbar zu werden. Entfernen Sie unnötige Befehle oder überflüssige Operationen, die den Prozess verlangsamen können.
- Getrennte Agentenpools für unterschiedliche Arbeitslasten: Verwenden Sie verschiedene Agentenpools für verschiedene Arbeitslasten, wie Build, Release oder spezielle Aufträge wie Sicherheitsscans. So können Sie Ressourcen isolieren und die Skalierung effizienter verwalten.
- Passen Sie die Poolgröße auf der Grundlage historischer Daten an: Überwachen Sie Ihre Pipeline-Ausführungsmuster und passen Sie die ScaledJob-Konfiguration auf der Grundlage historischer Daten zur Auftragsauslastung an.
- Wenden Sie immer das Prinzip der geringsten Privilegien an. Weisen Sie nur die PAT-Bereiche zu, die für Ihre Automatisierung notwendig sind.
- Regelmäßige Rotation der PATs minimiert das Risiko eines unbefugten Zugriffs, wenn ein Token kompromittiert wird, und gewährleistet die Einhaltung bewährter Sicherheitsverfahren. Außerdem werden die Auswirkungen einer versehentlichen Offenlegung reduziert, so dass Ihre Azure DevOps-Umgebung sicher bleibt.
- Wenn Sie die Verwendung eines PAT vermeiden möchten, sollten Sie in Azure DevOps eine Dienstverbindung mit einem Dienstprinzipal oder einer verwalteten Identität erstellen, die detailliertere Berechtigungen und Sicherheit bieten (nicht in diesem Artikel behandelt).
- Verwenden Sie benutzerdefinierte Metriken für eine präzise Skalierung: Dazu müssen Sie zum Beispiel eine benutzerdefinierte Azure Monitor-Metrik einrichten, die die Warteschlangen von Aufträgen, einschließlich Abbrüchen, genau verfolgt.
7. Schlussfolgerung
Die automatische Skalierung von Azure DevOps Agent Pools mit KEDA bietet eine dynamische und effiziente Lösung für die Verwaltung von Build- und Bereitstellungsressourcen in einer Kubernetes-Umgebung. Durch die Nutzung von KEDAs SkaliertesObjekt und/oder ScaledJob Ressourcen können Sie sicherstellen, dass Ihre Azure DevOps-Agenten automatisch auf der Grundlage des Echtzeitbedarfs skaliert werden, wodurch die Kosten gesenkt und die Bearbeitungszeiten für Aufträge verbessert werden.
In diesem Artikel behandeln wir:
- Eine Einführung in KEDA und seine Rolle bei der ereignisgesteuerten Skalierung für Kubernetes.
- Unterschiede zwischen ScaledObject und ScaledJob und wie sie sich auf Azure DevOps Agent Pools beziehen.
- Schrittweise Einrichtung und Konfiguration von AKS und ACR mit Terraform.
- Erstellen und Bereitstellen eines benutzerdefinierten Docker-Images mit einem start.sh Skript für die Initialisierung des Agenten.
- Implementierung einer Lösung mit ScaledJob zur Optimierung der Verfügbarkeit und Skalierbarkeit von Agenten.
Es gibt noch weitere Themen, auf die wir eingehen können, wie z.B. die Einrichtung von Lösungen auf der Basis von ScaledObject, Sicherheit, Überwachung, Ersetzen von K8s durch Alternativen und vieles mehr. Vielleicht werde ich in den nächsten Artikeln etwas darüber schreiben.
Ich hoffe, Sie fanden dies aufschlussreich!
Kuba Dziurdziewicz
Verfasst von
Kuba Dziurdziewicz
Once an experienced developer with demonstrated history of working in different industries, now DevOps Engineer that continues his road to professional growth.
Unsere Ideen
Weitere Blogs




Contact