
Airflow ist ein Scheduler für Workflows wie Datenpipelines, ähnlich wie Luigi und Oozie. Es ist in Python geschrieben und wir von GoDataDriven haben in den letzten Monaten dazu beigetragen.
Dieses Lernprogramm basiert lose auf dem Airflow-Tutorial in der offiziellen Dokumentation. Es führt Sie durch die Grundlagen der Einrichtung von Airflow und der Erstellung eines Airflow-Workflows und gibt Ihnen einige praktische Tipps. Eine (möglicherweise) aktuellere Version dieses Blogs finden Sie in meinem Git Repo.
1. Einrichtung
Die Einrichtung einer Grundkonfiguration von Airflow ist ziemlich einfach. Nach der Installation des Python-Pakets benötigen wir eine Datenbank, um einige Daten zu speichern und die zentralen Airflow-Dienste zu starten.
Sie können diesen Abschnitt überspringen, wenn Airflow bereits eingerichtet ist. Vergewissern Sie sich, dass Sie die Befehle von airflow ausführen können, wissen, wo Sie Ihre DAGs ablegen und Zugriff auf die Web-Benutzeroberfläche haben.
Luftstrom installieren
Airflow kann mit pip über eine einfache pip install apache-airflow installiert werden. Verwenden Sie entweder eine separate virtuelle Python-Umgebung oder installieren Sie es in Ihrer Standard-Python-Umgebung.
So verwenden Sie die virtuelle Umgebung von conda, wie sie in environment.yml aus meinem Git-Repository definiert ist:
- Installieren Sie miniconda.
- Stellen Sie sicher, dass conda auf Ihrem Weg liegt:
$ which conda
~/miniconda3/bin/conda- Erstellen Sie die virtuelle Umgebung unter
environment.yml:
$ conda env create -f environment.yml- Aktivieren Sie die virtuelle Umgebung:
$ source activate airflow-tutorialSie sollten jetzt eine (fast) funktionierende Airflow-Installation haben.
Alternativ können Sie Airflow auch selbst installieren, indem Sie den Befehl ausführen:
$ pip install apache-airflowAirflow wurde früher als airflow verpackt, aber seit Version 1.8.1 wird es als apache-airflow verpackt. Stellen Sie sicher, dass Sie alle zusätzlichen Pakete mit dem richtigen Python-Paket installieren: Verwenden Sie z.B. apache- weglassen, wird eine alte Version von Airflow neben Ihrer aktuellen Version installiert, was zu großen Problemen führen kann.
Sie können auf Probleme stoßen, wenn Sie nicht die richtigen Binärdateien oder Python-Pakete für bestimmte Backends oder Operatoren installiert haben. Wenn Sie bei der Installation zusätzlicher Airflow-Pakete die Unterstützung für z.B. PostgreSQL angeben, stellen Sie sicher, dass die Datenbank installiert ist; führen Sie ein brew install postgresql oder apt-get install postgresql vor dem pip install apache-airflow[postgres] aus. Ähnlich verhält es sich bei Fehlern mit HiveOperator: Führen Sie ein pip install apache-airflow[hive] aus und stellen Sie sicher, dass Sie Hive verwenden können.
Luftstrom ausführen
Bevor Sie Airflow verwenden können, müssen Sie seine Datenbank initialisieren. Die Datenbank enthält Informationen über historische und laufende Workflows, Verbindungen zu externen Datenquellen, die Benutzerverwaltung usw. Sobald die Datenbank eingerichtet ist, kann über einen Webserver auf die Benutzeroberfläche von Airflow zugegriffen und die Workflows können gestartet werden.
Die Standarddatenbank ist eine SQLite-Datenbank, die für dieses Tutorial gut geeignet ist. In einer Produktionsumgebung werden Sie wahrscheinlich etwas wie MySQL oder PostgreSQL verwenden. Sie sollten eine Sicherungskopie erstellen, da diese Datenbank den Status aller mit Airflow verbundenen Daten speichert.
Airflow verwendet das in der Umgebungsvariablen AIRFLOW_HOME festgelegte Verzeichnis, um seine Konfiguration und unsere SQlite-Datenbank zu speichern. Dieses Verzeichnis wird nach Ihrem ersten Airflow-Befehl verwendet. Wenn Sie die Umgebungsvariable AIRFLOW_HOME nicht setzen, erstellt Airflow das Verzeichnis ~/airflow/, in dem es seine Dateien ablegt.
Setzen Sie die Umgebungsvariable AIRFLOW_HOME z.B. auf Ihr aktuelles Verzeichnis $(pwd):
# change the default location ~/airflow if you want:
$ export AIRFLOW_HOME="$(pwd)"oder ein anderes geeignetes Verzeichnis.
Als nächstes initialisieren Sie die Datenbank:
$ airflow initdbStarten Sie nun den Webserver und gehen Sie zu localhost:8080, um die Benutzeroberfläche zu überprüfen:
$ airflow webserver --port 8080Es sollte in etwa so aussehen:
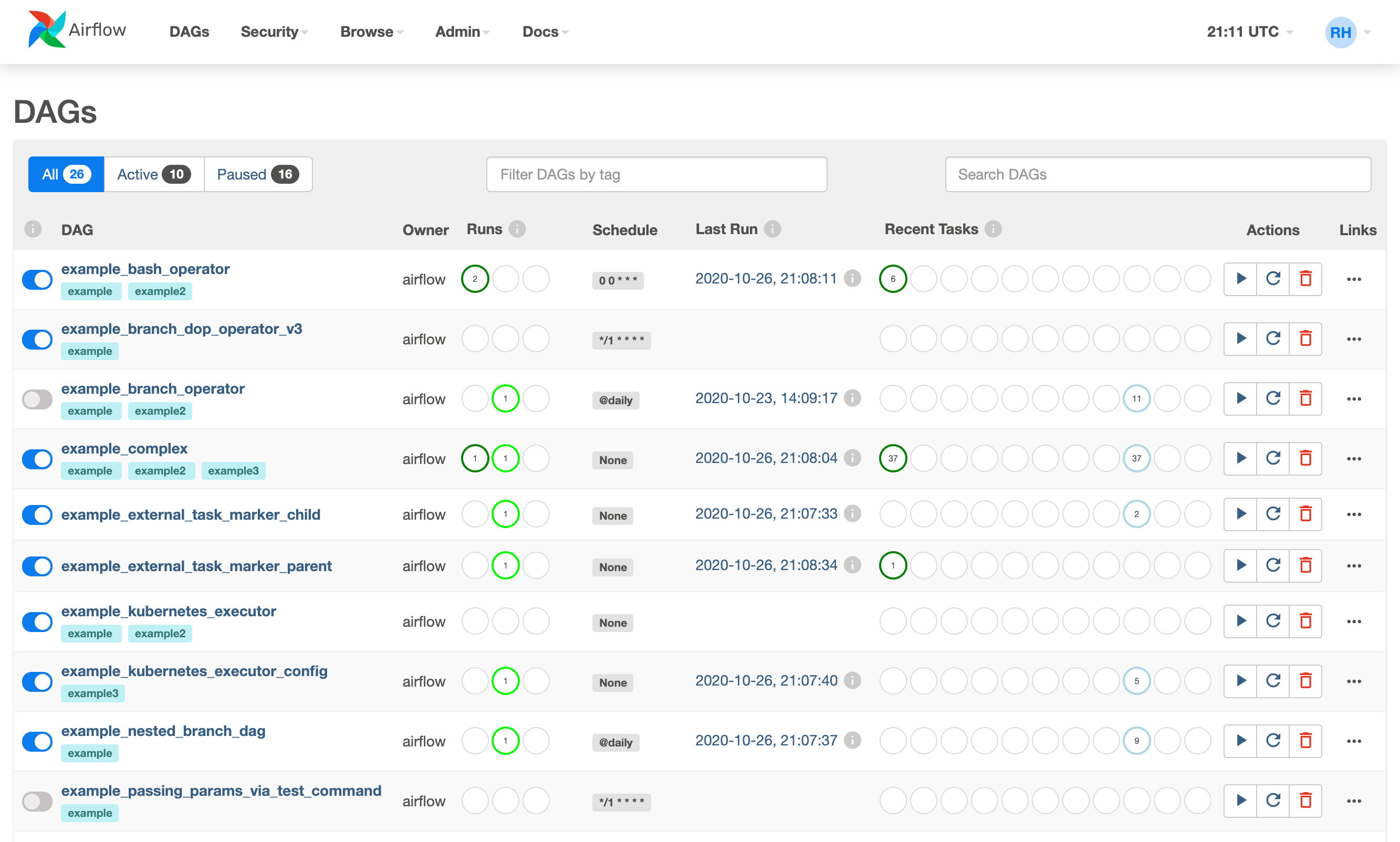
Wenn der Webserver läuft, können Sie Workflows von einem neuen Terminalfenster aus starten. Öffnen Sie ein neues Terminal, aktivieren Sie die virtuelle Umgebung und setzen Sie die Umgebungsvariable AIRFLOW_HOME auch für dieses Terminal:
$ source activate airflow-tutorial
$ export AIRFLOW_HOME="$(pwd)"Vergewissern Sie sich, dass Sie sich in demselben Verzeichnis befinden wie zuvor, wenn Sie $(pwd) verwenden.
Führen Sie ein mitgeliefertes Beispiel aus:
$ airflow run example_bash_operator runme_0 2017-07-01Und überprüfen Sie in der Web-Benutzeroberfläche, ob er ausgeführt wurde, indem Sie auf Durchsuchen -> Task-Instanzen gehen.
Damit sind alle Einstellungen, die Sie für dieses Lernprogramm benötigen, abgeschlossen.
Tipps
- Sowohl Python 2 als auch 3 werden von Airflow unterstützt. Einige der weniger häufig verwendeten Teile (z.B. die Operatoren in
contrib) unterstützen jedoch möglicherweise nicht Python 3. - Weitere Informationen zur Konfiguration finden Sie in den Abschnitten über Konfiguration und Sicherheit in der Airflow-Dokumentation.
- Prüfen Sie das Airflow-Repository auf
upstartundsystemdVorlagen. - Airflow protokolliert umfangreich, wählen Sie also Ihren Protokollordner sorgfältig aus.
- Stellen Sie die Zeitzone Ihres Produktionsrechners auf ein: Airflow nimmt an, dass es sich um UTC handelt.
Lernen Sie Spark oder Python in nur einem Tag
Entwickeln Sie Ihre Data Science-Fähigkeiten. **Online**, unter Anleitung am 23. oder 26. März 2020, 09:00 - 17:00 CET.
2. Arbeitsabläufe
Wir erstellen einen Workflow, indem wir Aktionen als gerichteten azyklischen Graph (DAG) in Python angeben. Die Aufgaben eines Workflows bilden einen Graphen. Der Graph ist gerichtet, weil die Aufgaben geordnet sind, und wir wollen nicht in einer ewigen Schleife stecken bleiben, also muss der Graph auch azyklisch sein. Die Abbildung unten zeigt ein Beispiel für eine DAG: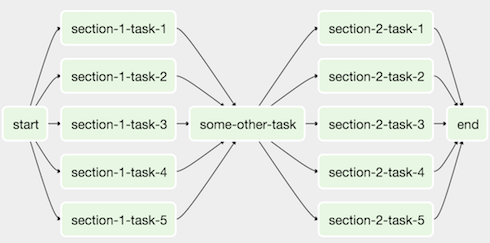 Die DAG dieses Tutorials ist ein wenig einfacher. Sie wird aus den folgenden Aufgaben bestehen:
Die DAG dieses Tutorials ist ein wenig einfacher. Sie wird aus den folgenden Aufgaben bestehen:
- drucken
'hello' - 5 Sekunden warten
- drucken
'world
Eine DAG-Datei erstellen
Gehen Sie zu dem Ordner, den Sie als IhrenAIRFLOW_HOME und suchen Sie den Ordner DAGs, der sich im Unterordner dags/ (wenn Sie es nicht finden können, überprüfen Sie die Einstellung dags_folder in $AIRFLOW_HOME/airflow.cfg). Erstellen Sie eine Python-Datei mit dem Namen airflow_tutorial.py, die Ihre DAG enthalten wird. Ihr Workflow wird automatisch ausgewählt und für die Ausführung geplant.
Zunächst konfigurieren wir Einstellungen, die von allen unseren Aufgaben gemeinsam genutzt werden. Einstellungen für Aufgaben können beim Erstellen als Argumente übergeben werden, aber wir können auch ein Wörterbuch mit Standardwerten an die DAG übergeben. Auf diese Weise können wir die Standardargumente für alle Aufgaben in unserer DAG gemeinsam nutzen und z.B. den Eigentümer und das Startdatum unserer DAG festlegen.
Fügen Sie den folgenden Import und das Wörterbuch zu airflow_tutorial.py hinzu, um den Eigentümer, die Startzeit und die Wiederholungseinstellungen festzulegen, die von unseren Aufgaben gemeinsam genutzt werden:
Gemeinsame Einstellungen konfigurieren
import datetime as dt
default_args = {
'owner': 'me',
'start_date': dt.datetime(2017, 6, 1),
'retries': 1,
'retry_delay': dt.timedelta(minutes=5),
}'me' gehört, dass der Workflow seit dem 1. Juni 2017 gültig ist, dass er keine E-Mails senden soll und dass er den Workflow einmal wiederholen darf, wenn er mit einer Verzögerung von 5 Minuten fehlschlägt. Weitere gängige Standardargumente sind die E-Mail-Einstellungen bei Fehlschlägen und die Endzeit.
Erstellen Sie die DAG
Jetzt erstellen wir ein DAG-Objekt, das unsere Aufgaben enthalten wird. Nennen Sie esairflow_tutorial_v01 und geben Sie default_args ein:
from airflow import DAG
with DAG('airflow_tutorial_v01',
default_args=default_args,
schedule_interval='0 0 * * *',
) as dag:scheduleinterval='0 0 ' haben wir einen Lauf zu jeder Stunde 0 festgelegt; der DAG wird jeden Tag um 00:00 Uhr ausgeführt. Siehe <a href="Crontab.guru _*">crontab.guru für Hilfe bei der Entschlüsselung von Cron-Zeitplanausdrücken. Alternativ können Sie auch Zeichenfolgen wie code>'@daily'< /code und code>'@hourly'</code verwenden.
Wir haben einen Kontextmanager verwendet, um eine DAG zu erstellen (neu seit 1.8). Alle Aufgaben für die DAG sollten eingerückt sein, um anzuzeigen, dass sie Teil dieser DAG sind. Ohne diesen Kontextmanager müssten Sie den Parameter dag für jede Ihrer Aufgaben festlegen.
Airflow generiert DAG-Läufe aus der start_date mit der angegebenen schedule_interval. Sobald eine DAG aktiv ist, prüft Airflow kontinuierlich in der Datenbank, ob alle DAG-Läufe seit der start_date erfolgreich durchgeführt wurden. Fehlende DAG-Läufe werden automatisch eingeplant. Wenn Sie am 2016-01-04 eine DAG mit einem start_date am 2016-01-01 und einem täglichen schedule_interval initialisieren, plant Airflow DAG-Läufe für alle Tage zwischen 2016-01-01 und 2016-01-04.
Ein Lauf beginnt , nachdem die Zeit für den Lauf verstrichen ist. Die Zeit, für die der Workflow läuft, wird schedule_interval irgendwo in der Workflow-Logik zu Ihrer execution_date hinzufügen.
Da Airflow alle (geplanten) DAG-Läufe in seiner Datenbank speichert, sollten Sie die start_date und schedule_interval einer DAG nicht ändern. Erhöhen Sie stattdessen die Versionsnummer der DAG (z.B. airflow_tutorial_v02) und vermeiden Sie die Ausführung unnötiger Aufgaben, indem Sie die Weboberfläche oder die Befehlszeilentools verwenden
Zeitzonen und insbesondere die Sommerzeit können zu Problemen bei der Zeitplanung führen, also halten Sie Ihr Airflow-Gerät in UTC. Sie möchten keine Stunde auslassen, weil die Sommerzeit beginnt (oder endet).
Erstellen Sie die Aufgaben
Aufgaben werden durch Operatoren dargestellt, die entweder eine Aktion ausführen, Daten übertragen oder feststellen, ob etwas getan wurde. Beispiele für Aktionen sind die Ausführung eines Bash-Skripts oder der Aufruf einer Python-Funktion, für Übertragungen das Kopieren von Tabellen zwischen Datenbanken oder das Hochladen einer Datei und für Sensoren die Überprüfung, ob eine Datei existiert oder Daten zu einer Datenbank hinzugefügt wurden. Wir erstellen einen Arbeitsablauf, der aus drei Aufgaben besteht: Wir drucken 'hallo', warten 10 Sekunden und drucken schließlich 'world'. Die ersten beiden Aufgaben werden mit demBashOperator und die letzte mit dem PythonOperator erledigt. Geben Sie jedem Operator eine eindeutige Aufgaben-ID und eine Aufgabe:
from airflow.operators.bash_operator import BashOperator
from airflow.operators.python_operator import PythonOperator</code
def print_world():
print('world')
print_hello = BashOperator(task_id='print_hello',
bash_command='echo "hello"')
sleep = BashOperator(task_id='sleep',
bash_command='sleep 5')
print_world = PythonOperator(task_id='print_world',
python_callable=print_world)BashOperator übergeben können und dass die PythonOperator nach einer Python-Funktion fragt, die aufgerufen werden kann.
Abhängigkeiten in Vorgängen werden hinzugefügt, indem Sie andere Vorgänge als vorgelagert (oder nachgelagert) festlegen. Verknüpfen Sie die Vorgänge in einer Kette, so dass sleep wird ausgeführt, nachdem print_hello und wird gefolgt von print_world; print_hello -> sleep -> print_world:
print_hello >> sleep >> print_worldimport datetime as dt
from airflow import DAG
from airflow.operators.bash_operator import BashOperator
from airflow.operators.python_operator import PythonOperator
def print_world():
print('world')
default_args = {
'owner': 'me',
'start_date': dt.datetime(2017, 6, 1),
'retries': 1,
'retry_delay': dt.timedelta(minutes=5),
}
with DAG('airflow_tutorial_v01',
default_args=default_args,
schedule_interval='0 * * * *',
) as dag:
print_hello = BashOperator(task_id='print_hello',
bash_command='echo "hello"')
sleep = BashOperator(task_id='sleep',
bash_command='sleep 5')
print_world = PythonOperator(task_id='print_world',
python_callable=print_world)
print_hello >> sleep >> print_worldTesten Sie die DAG
Prüfen Sie zunächst, ob die DAG-Datei gültigen Python-Code enthält, indem Sie die Datei mit Python ausführen:$ python airflow_tutorial.pyexecution_date mit airflow test manuell testen:
$ airflow test airflow_tutorial_v01 print_world 2017-07-01Aktivieren Sie die DAG
Jetzt, da Sie sicher sind, dass Ihre DAG funktioniert, können wir sie automatisch ausführen lassen! Dazu muss der Scheduler eingeschaltet sein. Der Scheduler überwacht alle Tasks und alle DAGs und löst die Task-Instanzen aus, deren Abhängigkeiten erfüllt sind. Öffnen Sie ein neues Terminal, aktivieren Sie die virtuelle Umgebung und setzen Sie die UmgebungsvariableAIRFLOW_HOME für dieses Terminal, und geben Sie ein
$ airflow schedulerairflow_tutorial_v01 in der Liste der DAGs mit einem An/Aus-Schalter daneben sehen. Schalten Sie den DAG in der Web-Benutzeroberfläche ein und lehnen Sie sich zurück, während Airflow mit dem Backfilling der DAG-Läufe beginnt!
Tipps
- Machen Sie Ihre DAGs idempotent: eine erneute Ausführung sollte die gleichen Ergebnisse liefern.
- Verwenden Sie die cron-Schreibweise für
schedule_intervalanstelle von@dailyund@hourly.@dailyund@hourlylaufen immer nach Mitternacht bzw. nach der vollen Stunde, unabhängig von der angegebenen Stunde/Minute. - Verwalten Sie Ihre Verbindungen und Geheimnisse mit den Verbindungen und/oder Variablen.
3. Übungen
Sie kennen jetzt die Grundlagen der Einrichtung von Airflow, der Erstellung einer DAG und des Einschaltens; Zeit, tiefer zu gehen!- Ändern Sie das Intervall auf alle 30 Minuten.
- Verwenden Sie einen Sensor, um eine Verzögerung von 5 Minuten vor dem Start hinzuzufügen.
- Implementieren Sie eine Schablone für
BashOperator: Drucken Sieexecution_dateanstelle von'hello'(sehen Sie sich das Original-Tutorial und die Beispiel-DAG an). - Verwenden Sie die Schablone für die
PythonOperator: Drucken Sie dieexecution_datemit einer Stunde, die in der Funktionprint_world()hinzugefügt wurde (sehen Sie sich die Dokumentation derPythonOperatoran).
4. Ressourcen
- Das offizielle Airflow-Tutorial: zeigt ein wenig tiefer gehende Magie bei der Vorlagenerstellung.
- ETL-Best Practices mit Airflow: gute Best Practices, die Sie bei der Verwendung von Airflow beachten sollten.
- Luftströmung: Tipps, Tricks und Fallstricke: weitere Erklärungen, die Ihnen helfen, die Luftströmung zu verstehen.
- Whirl: Schnelle, iterative lokale Entwicklung und Prüfung von Apache Airflow-Workflows
Lernen Sie Apache Airflow von den Besten
Wir bieten einen ausführlichen Apache Airflow-Kurs an, in dem Sie die Interna, die Terminologie und die besten Praktiken bei der Arbeit mit Airflow kennenlernen und praktische Erfahrungen beim Schreiben und Verwalten von Datenpipelines sammeln können.Verfasst von
Henk Griffioen
Unsere Ideen
Weitere Blogs




Contact