Blog
adfPy: ein intuitiver Weg zum Aufbau von Datenpipelines mit Azure Data Factory

In einem früheren Beitrag haben wir uns angesehen, wie Sie Azure Data Factory (ADF)-Ressourcen dynamisch generieren können. Bei diesem Ansatz gingen wir von YAML-Dateien aus, die die Konfiguration enthielten, um ADF-Pipelines mithilfe eines benutzerdefinierten Python-Skripts mit Jinja2-Templating zu erzeugen. Das funktionierte zwar, war aber immer noch etwas umständlich und brachte einige Probleme in Bezug auf den Entwicklungsfluss mit sich. In diesem Beitrag zeigen wir, wie adfPy, ein Open-Source-Projekt, die meisten dieser Probleme löst und darauf abzielt, die Entwicklungserfahrung von ADF viel ähnlicher zu machen als die von Apache Airflow.
Rekapitulieren Sie: Warum wollen wir das tun?
Die dynamische Generierung von Datenpipelines ist etwas, das viele von uns irgendwann bei der Arbeit mit einem Pipeline-Orchestrierungstool, sei es Azure Data Factory oder ein anderes, nutzen möchten. Es reduziert den Arbeitsaufwand für das Hinzufügen neuer Datenpipelines (z.B. für das Hinzufügen neuer Pipelines für die Aufnahme von Datenquellen) und sorgt dafür, dass sich alle Pipelines ähnlich verhalten. Außerdem ist die von uns vorgeschlagene Konfiguration für technisch nicht versierte Personen einfacher zu verstehen und zu handhaben. Wie in unserem letzten Beitrag werden wir uns ein relativ einfaches Beispiel ansehen:
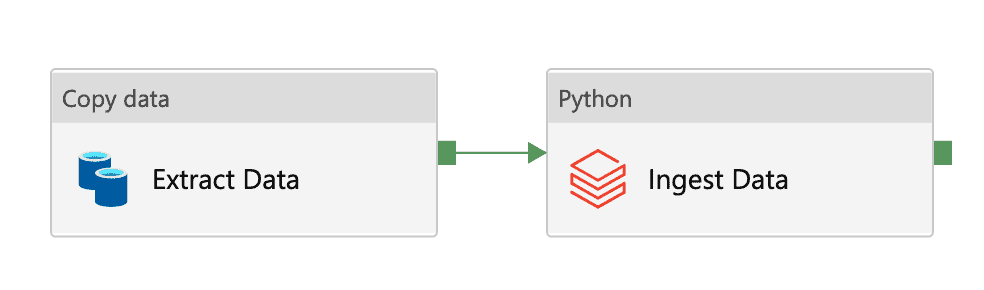
In Worten: Diese Pipeline führt die folgenden Schritte aus:
- Holen Sie die Daten aus der Quelldatenbank
- Platzieren Sie die Daten in der Landezone
- Ingest der Daten in unseren Data Lake unter Verwendung der bereitgestellten Schemainformationen
Die Konfiguration hierfür ist YAML und sieht wie folgt aus:
meta:
name: my_data
trigger:
frequency: "@daily"
dataFlowSettings:
source:
dataset: source
landing:
dataset: landing
path: "dbfs:/landing"
ingested:
dataset: ingested
path: "dbfs:/datalake"
dataDefinitions:
tables:
- table: my_table
schema: my_schema
database: my_database
target:
uniqueIdColumns:
- id
database: target_database
table: target_table
columns:
- source:
name: id
type: VARCHAR2(3)
target:
name: id
type: string
nullable: false
- source:
name: value
type: VARCHAR2(4)
target:
name: value
type: string
nullable: trueAnhand dieser Informationen möchten wir die ADF-Pipeline programmatisch erstellen können. Ich wiederhole noch einmal die Anforderungen aus unserem letzten Blogpost:
- Die Konfiguration von Pipelines wird in der Versionskontrolle in einem leicht lesbaren Format gespeichert. Für den Rahmen dieses Blogposts beschränken wir uns auf YAML, aber Sie können jedes beliebige Dateiformat verwenden.
- Die Erstellung und Entfernung von Pipelines sollte auf der Grundlage der in Punkt 1 genannten Konfiguration automatisiert werden.
- Das Aktualisieren von Pipelines sollte einfach sein. Anstatt N Pipelines ändern zu müssen, möchten wir die Vorlage ändern können, was sich dann automatisch in den Pipelines niederschlägt.
Einführung in adfPy
adfPy ist ein quelloffenes Python-Paket, das Ihnen die Interaktion mit Azure Data Factory auf elegante, pythonische Weise ermöglicht. Es enthält auch Werkzeuge, die eine zuverlässige Bereitstellung Ihrer ADF-Ressourcen für ADF (einschließlich der Entfernung) gewährleisten. Die Syntax wurde so weit wie möglich an die von Apache Airflow angelehnt, da dies saubere Pipeline-Definitionen im Code ermöglicht.
Azure Data Factory Python SDK
Azure verfügt über ein Python-SDK für ADF. Es ist jedoch recht ausführlich und nicht sehr angenehm zu bedienen. Um die oben beschriebene Pipeline zu erstellen, wäre der erforderliche Code folgender:
import os
import pathlib
from datetime import datetime
import yaml
from azure.identity import ClientSecretCredential
from azure.mgmt.datafactory import DataFactoryManagementClient
from azure.mgmt.datafactory.models import (
BlobSink,
OracleSource,
CopyActivity,
DatasetReference,
DatabricksSparkPythonActivity,
PipelineResource,
PipelineReference,
ActivityDependency,
ScheduleTrigger,
ScheduleTriggerRecurrence,
TriggerResource,
TriggerPipelineReference
)
def load_yaml(path):
with open(path, 'r') as file:
return yaml.safe_load(file)
config = load_yaml(f"{pathlib.Path(__file__).parent}/pipeline_config.yml")
dataFlowSettings = config["dataFlowSettings"]
dsin_ref = DatasetReference(reference_name=dataFlowSettings["source"]["dataset"])
dsOut_ref = DatasetReference(reference_name=dataFlowSettings["landing"]["dataset"])
extract = CopyActivity(name='Extract data',
inputs=[dsin_ref],
outputs=[dsOut_ref],
source=OracleSource(),
sink=BlobSink())
ingestion_parameters = [
"--source_path",
dataFlowSettings['landing']['path'],
"--data_schema",
config["dataDefinitions"]['tables'],
"--target_path",
dataFlowSettings['ingested']['path']
]
ingest = DatabricksSparkPythonActivity(
name="Ingest Data",
python_file="my_ingestion_script.py",
parameters=ingestion_parameters,
depends_on=[ActivityDependency(activity="Extract data", dependency_conditions=["Succeeded"])])
subscription_id = os.environ["AZURE_SUBSCRIPTION_ID"]
resource_group = os.environ["AZURE_RESOURCE_GROUP_NAME"]
data_factory = os.environ["AZURE_DATA_FACTORY_NAME"]
credentials = ClientSecretCredential(
client_id=os.environ["AZURE_SERVICE_PRINCIPAL_CLIENT_ID"],
client_secret=os.environ["AZURE_SERVICE_PRINCIPAL_SECRET"],
tenant_id=os.environ["AZURE_TENANT_ID"],
)
adf_client = DataFactoryManagementClient(credentials, subscription_id)
pipeline = PipelineResource(activities=[extract, ingest])
trigger_scheduler_recurrence = ScheduleTriggerRecurrence(frequency="Day",
interval=1,
start_time=datetime.now(),
time_zone="UTC")
trigger = TriggerResource(
properties=ScheduleTrigger(recurrence=trigger_scheduler_recurrence,
pipelines=[TriggerPipelineReference(
pipeline_reference=PipelineReference(
reference_name=f"{config['meta']['name']}-native"))],
)
)
pipeline_create_output = adf_client.pipelines.create_or_update(resource_group,
data_factory,
f"{config['meta']['name']}-native",
pipeline)
trigger_create_output = adf_client.triggers.create_or_update(resource_group,
data_factory,
f"{config['meta']['name']}-native-trigger",
trigger)
Und selbst wenn Sie diesen Code haben, werden keine Ressourcen gelöscht, wenn Sie den Code aus Ihrer Codebasis entfernen. Um all diese Funktionen kümmert sich adfPy, wie wir weiter unten zeigen werden.
Definieren Sie Ihre Pipeline
Um genau die gleiche Pipeline mit adfPy zu definieren, würde der Code wie folgt aussehen:
import pathlib
import yaml
from azure.mgmt.datafactory.models import BlobSink, OracleSource
from adfpy.activities.execution import AdfCopyActivity, AdfDatabricksSparkPythonActivity
from adfpy.pipeline import AdfPipeline
def load_yaml(path):
with open(path, 'r') as file:
return yaml.safe_load(file)
config = load_yaml(f"{pathlib.Path(__file__).parent}/pipeline_config.yml")
dataFlowSettings = config["dataFlowSettings"]
extract = AdfCopyActivity(
name="Extract data",
input_dataset_name=dataFlowSettings["source"]["dataset"],
output_dataset_name=dataFlowSettings["landing"]["dataset"],
source_type=OracleSource,
sink_type=BlobSink,
)
ingestion_parameters = [
"--source_path",
dataFlowSettings['landing']['path'],
"--data_schema",
config["dataDefinitions"]['tables'],
"--target_path",
dataFlowSettings['ingested']['path']
]
ingest = AdfDatabricksSparkPythonActivity(name="Ingest Data",
python_file="my_ingestion_script.py",
parameters=ingestion_parameters)
extract >> ingest
pipeline = AdfPipeline(name=config["meta"]["name"],
activities=[extract, ingest],
schedule=config["meta"]["trigger"]["schedule"])Hier gibt es ein paar interessante Dinge:
- Der Auslöser wird nun direkt aus der YAML geholt und sofort mit der Pipeline verbunden.
- Abhängigkeiten zwischen Aufgaben lassen sich ganz einfach mit den Bitshift-Operatoren (
>>oder<<) herstellen, ähnlich wie bei Apache Airflow. - Hier gibt es keine Vermischung von Pipeline-Definition und Bereitstellungslogik. Für die Bereitstellung der adfPy-Pipeline würden Sie die
CLI verwenden (siehe unten). Dies macht auch die Integration der Bereitstellung in eine CI/CD-Pipeline erheblich einfacher. - adfPy entfernt einen Großteil der internen Klassenhierarchie des Azure SDK, um das meiste davon für den Pipeline-Entwickler zu verschleiern. Das macht das Leben (und den Code) wesentlich einfacher zu lesen und zu schreiben.
- Aus Gründen der Transparenz werden alle adfPy-Ressourcen nach nativen SDK-Entitäten mit dem Präfix
Adfbenannt. Auf diese Weise ist es immer einfach zu verstehen, welche ADF-Ressource durch eine adfPy-Ressource erstellt wird.
Einsetzen Ihrer Pipeline
Sobald Sie Ihre adfPy-Ressourcen definiert haben, müssen Sie sie in ADF bereitstellen. Dazu können Sie das mitgelieferte deploy CLI verwenden:
adfpy-deploy --path my_pipelines/Dies bewirkt mehrere Dinge:
- Analysiert alle adfPy-Ressourcen, die im angegebenen Pfad gefunden werden (in diesem Fall
my_pipelines). - Für jede Ressource: Erstellen oder aktualisieren Sie die entsprechende native ADF-Ressource.
- Alle Ressourcen, die in ADF gefunden werden und nicht im angegebenen Pfad enthalten sind, werden gelöscht. Dies ist ein optionales Verhalten, das dazu dient, Ihre Codebasis als einzige Quelle der Wahrheit zu nutzen und ein Abdriften zu vermeiden. Sie können diese Funktion deaktivieren oder weiter konfigurieren, um Ihrem Anwendungsfall gerecht zu werden.
Es ist erwähnenswert, dass Sie den GIT-Modus nicht mehr verwenden können, wenn Sie entweder das native Azure SDK oder adfPy zur Bereitstellung/Verwaltung Ihrer ADF-Ressourcen auf diese Weise verwenden. Das bedeutet, dass Sie den Live-Modus im Azure-Portal verwenden werden. Unserer Meinung nach ist dies nicht unbedingt problematisch, da die Verwaltung Ihrer Ressourcen in den Code verlagert wird, was die Arbeit mit dem Programm sehr viel einfacher macht.
adfPy anpassen
Obwohl adfPy darauf abzielt, "batterieunabhängig" zu sein, sind wir uns bewusst, dass wir nicht alle Anwendungsfälle abdecken können. Darüber hinaus ist es unserer Meinung nach eher eine Stärke als eine Schwäche, wenn Benutzer (Pipeline-)Komponenten hinzufügen und anpassen können, um sie besser an ihre Anwendungsfälle anzupassen. Zu diesem Zweck unterstützen wir die Anpassung und Erweiterung von adfPy in vollem Umfang. Um eine benutzerdefinierte Aktivität hinzuzufügen, erweitern Sie einfach die Klasse
Vorbehalte
Bei der Verwendung von adfPy gibt es ein paar Dinge zu beachten:
- Derzeit ist eine begrenzte Anzahl von Aktivitäten implementiert. Es ist jedoch relativ einfach, adfPy um Ihre eigenen Aktivitäten zu erweitern, und in Zukunft werden weitere hinzukommen.
- Im Moment wird nur der Typ ScheduledTrigger als Trigger unterstützt. Die Unterstützung für andere Trigger-Typen ist auf der Roadmap.
- Ressourcen wie Datensätze und/oder verknüpfte Dienste sind derzeit nicht in adfPy enthalten.
Fazit
adfPy ist eine pythonische, elegante Schnittstelle für die Arbeit mit Azure Data Factory. In diesem Beitrag haben wir uns eine relativ einfache ETL-Pipeline mit nur 2 Aktivitäten angesehen. Wir haben den Code des nativen SDK dem von adfPy gegenübergestellt. adfPy ist nicht für alle Umgebungen und Anwendungsfälle geeignet und kann die "no-code" Schnittstelle von ADF zur Entwicklung von ETL-Flows nicht ersetzen. Es kann jedoch als ein sehr leistungsfähiger Code-first-Ansatz für die Entwicklung und Verwaltung von Datenpipelines in ADF verwendet werden, was mit anderen Ansätzen wesentlich schwieriger ist.
Wenn Sie mehr über adfPy erfahren möchten, werfen Sie einen Blick in die Dokumentation oder das Repo und wenden Sie sich an uns, um mehr zu erfahren!




Contact