Blog
Die Fabrik in Azure Data Factory einsetzen: Dynamisch generierte Pipelines

Azure Data Factory (ADF) ist ein häufig verwendeter, verwalteter Azure-Dienst, mit dem Benutzer (Daten-)Pipelines definieren können. Diese Pipelines variieren in ihrer Komplexität von einer sehr einfachen Logik zum Abrufen von Daten bis hin zu komplizierten Pipelines, die einen erheblichen Aufwand bei der Erstellung und Pflege erfordern. Eine der Herausforderungen, auf die wir häufig stoßen, ist die dynamische Generierung von ADF-Entitäten (z.B. Pipelines, Trigger, Datensätze). In diesem Beitrag werfen wir einen Blick auf einige der Optionen, die wir in verschiedenen Umgebungen gesehen haben, und vergleichen sie, um zu sehen, welcher Ansatz für Sie am sinnvollsten ist.
Warum brauchen wir dynamisch generierte Pipelines?
Bevor wir darauf eingehen, wie wir dieses Problem angegangen sind, ist es wichtig zu erklären, warum wir diese dynamisch generierten Pipelines wollen und was genau wir mit diesem Begriff meinen. In ADF werden alle Pipelines in Azure Resource Manager (ARM) Vorlagen gespeichert. Diese Vorlagen sind in JSON geschrieben und können entweder manuell geschrieben werden (was ziemlich mühsam ist) oder über die Azure-Benutzeroberfläche extrahiert werden. Wenn Sie in irgendeiner Weise mit Azure interagieren, besteht die Wahrscheinlichkeit, dass Ihr Befehl (egal ob es sich um einen Az Cli- oder Azure Powershell-Befehl handelt) in einen REST-Aufruf übersetzt wird, der wiederum die ARM-Vorlagen erstellt.
ARM-Vorlagen sind zwar leistungsstark, erfordern aber umfangreiche Kenntnisse von Azure (Komponenten). Wir möchten unsere Pipelines mit etwas steuern, das auch ohne ADF-Kenntnisse leicht zu verstehen ist. Ein gutes Beispiel ist YAML;
meta:
name: my_data
trigger:
frequency: daily
dataFlowSettings:
source:
dataset: source_dataset
landing:
dataset: landing_dataset
path: "dbfs:/landing"
ingested:
dataset: ingested_dataset
path: "dbfs:/datalake"
dataDefinitions:
tables:
- table: my_table
schema: my_schema
database: my_database
target:
uniqueIdColumns:
- id
database: target_database
table: target_table
columns:
- source:
name: id
type: VARCHAR2(3)
target:
name: id
type: string
nullable: false
- source:
name: value
type: VARCHAR2(4)
target:
name: value
type: string
nullable: trueDiese YAML enthält die notwendigen Informationen, um eine Reihe von Schritten in ADF durchzuführen:
- Holen Sie die Daten aus der Quelldatenbank
- Platzieren Sie die Daten in der Landezone
- Ingest der Daten in unseren Data Lake unter Verwendung der bereitgestellten Schemainformationen
Darüber hinaus erfordert die YAML-Datei wenig bis gar keine ADF-Kenntnisse, so dass auch technisch weniger versierte Mitarbeiter diese Art der Konfiguration vornehmen können. Dies kann vor allem in Unternehmen hilfreich sein, in denen diese technisch weniger versierten Mitarbeiter über das größte Fachwissen verfügen, das bei der Dateneingabe von unschätzbarem Wert ist.
Abgesehen davon, dass das Schreiben von ARM-Vorlagen keinen Spaß macht, sehen wir auch oft, dass sich viele Pipelines sehr ähnlich sind. Da wir im Grunde unseres Herzens Programmierer sind, weckt dies unser Interesse, denn es deutet darauf hin, dass wir eine einzelne Pipeline irgendwie parametrisieren und diese Pipeline mit anderen Parametern wiederverwenden können. Das ist es, was wir mit dynamisch generierten Pipelines meinen: Anstatt für jede Pipeline eine maßgeschneiderte, benutzerdefinierte Pipeline zu benötigen, verwenden wir Pipelines wieder und parametrisieren sie mit jeder erforderlichen datenquellenspezifischen Konfiguration.
ADF bietet zwar Unterstützung für Pipeline-Vorlagen, aber diese sind in ihrer Funktionalität etwas eingeschränkt. Wenn Sie eine neue Pipeline-Instanz mit einer bestimmten Pipeline-Vorlage erstellen, legt ADF eine vollständige Kopie der Vorlage an. Das bedeutet, dass bei einer Änderung der Vorlage alle Änderungen manuell in die Pipeline-Instanz übernommen werden müssen. Leider gibt es keinen klaren und offensichtlichen Mechanismus, um die Synchronisierung zwischen Vorlage und Instanz zu gewährleisten. Das würde bedeuten, dass Sie, wenn eine Vorlage aus irgendeinem Grund geändert werden muss und Sie diese Änderungen in den Pipeline-Instanzen wiederfinden möchten, alle Pipeline-Instanzen neu erstellen müssten.
Was wollen wir erreichen?
Was wir wollen, ist:
- Die Konfiguration von Pipelines wird in der Versionskontrolle in einem leicht lesbaren Format gespeichert. Für den Rahmen dieses Blogposts beschränken wir uns auf YAML, aber Sie können jedes beliebige Dateiformat verwenden.
- Die Erstellung und Entfernung von Pipelines sollte auf der Grundlage der in Punkt 1 genannten Konfiguration automatisiert werden.
- Das Aktualisieren von Pipelines sollte einfach sein. Anstatt N Pipelines ändern zu müssen, möchten wir die Vorlage ändern können, was sich dann automatisch in den Pipelines niederschlägt.
Was sind unsere Optionen?
Obwohl der Bedarf an dynamisch generierten Pipelines weit verbreitet ist, gibt es mehr als einen Weg, dies zu erreichen. Jeder dieser Ansätze hat gute und schlechte Seiten, und welche Option für Sie die richtige ist, hängt von Ihrer Situation ab. Um die Diskussion zu strukturieren, haben wir die Optionen in zwei Kategorien unterteilt:
- Templating Options Hier erfahren Sie, wie die Pipeline-Konfiguration aus Dateien gelesen und zur dynamischen Erstellung der ADF-Pipelines verwendet wird.
- Bereitstellungsoptionen Sobald die Pipelines gerendert wurden, gibt es auch noch eine Reihe von Möglichkeiten, die erstellten Pipelines tatsächlich in ADF bereitzustellen. Diese Wahl hat Auswirkungen und verdient daher besondere Aufmerksamkeit.
Optionen für Vorlagen
Wir werden Jinja2 für die Schablonenerstellung intensiv nutzen. Jinja ist eine sehr schöne Template-Engine, mit der wir Werte in Dokumentvorlagen einfügen können, um das endgültige Dokument zu erstellen.
Unser Ziel ist es, YAML zu nehmen und zusammen mit vorbereiteten Jinja-templated ARM-Vorlagen die entsprechenden ARM-Vorlagen zu generieren. Das Jinja-Rendering selbst ist sehr einfach. In Pseudo-Python sieht es in etwa so aus:
for config_file in path:
# load the yaml
config = load_yaml_config(config_file)
# render the jinja template with the config from yaml
with open(jinja_template) as file:
template = Template(file.read())
rendered_template = template.render(**config)
# write out the final document (e.g. ARM template)
with open(target_path) as target:
target.write(rendered_template)Hierfür gibt es zwei Hauptoptionen, was die Vorlage anbelangt
Option 1: Vollständige Pipeline-Vorlagen
Der erste und vielleicht naheliegendste Ansatz besteht darin, jede einzelne Pipeline unabhängig zu rendern. Das bedeutet eine 1-zu-1-Zuordnung von jeder YAML-Konfigurationsdatei zu jeder ADF-Pipeline. Der Vorteil dieses Ansatzes besteht darin, dass durch die Trennung der einzelnen Pipelines in ADF diese leichter einzeln zu überwachen sind. Als Beispiel verwenden wir die oben gezeigte YAML und kombinieren sie mit einer Jinja-templated Pipeline, um eine vollständig gerenderte ADF-Pipeline zu erstellen. Es handelt sich um eine einfache, aber relevante Pipeline, die Daten aus einer Oracle-Datenbank abruft, diese in einer Landing Zone speichert und dann einen Databricks-Job auslöst, um die Daten in den Data Lake aufzunehmen.
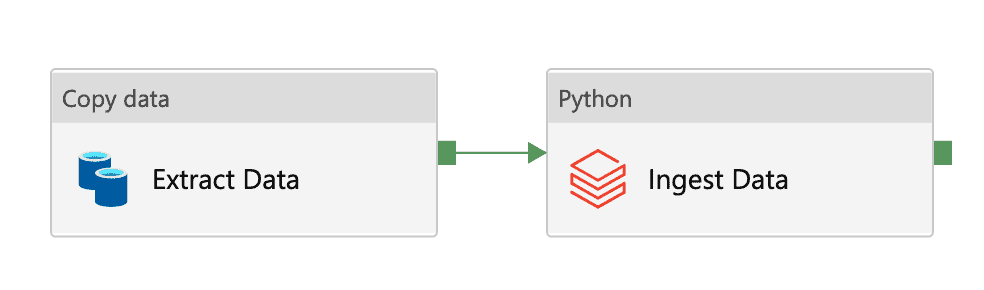
Bitte beachten Sie, dass wir aufgrund der Ausführlichkeit der ARM-Vorlagen Teile, die für diesen Blogpost nicht relevant sind, weggelassen haben. Es ist daher nicht zu erwarten, dass diese Beispiele in ADF sofort funktionieren.
{
"name": "{{ meta['name'] }}_pipeline",
"properties": {
"activities": [
{
"name": "Extract Data",
"type": "Copy",
"typeProperties": {
"source": {
"type": "OracleSource",
"oracleReaderQuery": {
"value": "@variables('Query')",
"type": "Expression"
},
"queryTimeout": "02:00:00"
},
},
"inputs": [
{
"referenceName": "{{ dataFlowSettings['source']['dataset'] }}",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "{{ dataFlowSettings['landing']['dataset'] }}",
"type": "DatasetReference"
}
]
},
{
"name": "Ingest Data",
"type": "DatabricksSparkPython",
"dependsOn": [
{
"activity": "Extract Data",
"dependencyConditions": [
"Succeeded"
]
}
],
"typeProperties": {
"pythonFile": "dbfs:/my_ingestion_script.py",
"parameters": [
"--source_path",
" dataFlowSettings['landing']['path'] ",
"--data_schema",
"{{ dataDefinitions['tables'] }}"
"--target_path",
"{{ dataFlowSettings['ingested']['path'] }}",
]
}
}
]
}
}Wenn wir diese Jinja-templated ADF Pipeline mit der gezeigten YAML kombinieren, erhalten wir die folgende "endgültige" ARM-Vorlage für unsere ADF-Pipeline:
{
"name": "my_data_pipeline",
"properties": {
"activities": [
{
"name": "Extract Data",
"type": "Copy",
"typeProperties": {
"source": {
"type": "OracleSource",
"oracleReaderQuery": {
"value": "@variables('Query')",
"type": "Expression"
},
"queryTimeout": "02:00:00"
},
},
"inputs": [
{
"referenceName": "source_dataset",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "landing_dataset",
"type": "DatasetReference"
}
]
},
{
"name": "Ingest Data",
"type": "DatabricksSparkPython",
"dependsOn": [
{
"activity": "Extract Data",
"dependencyConditions": [
"Succeeded"
]
}
],
"typeProperties": {
"pythonFile": "dbfs:/my_ingestion_script.py",
"parameters": [
"--data_path",
"dbfs:/landing",
"--data_schema",
"[{'table':'my_table','schema':'my_schema','database':'my_database','target':{'uniqueIdColumns':['id'],'database':'target_database','table':'target_table'},'columns':[{'source':{'name':'id','type':'VARCHAR2(3)'},'target':{'name':'id','type':'string','nullable':false}},{'source':{'name':'value','type':'VARCHAR2(4)'},'target':{'name':'value','type':'string','nullable':true}}]}]"
"--target_path",
"dbfs:/datalake",
]
}
}
]
}
}Während die eigentliche Ersetzung trivial ist, ist sie sehr leistungsstark, wenn Sie mit vielen verschiedenen Datenquellen arbeiten, die alle ähnliche (oder vielleicht sogar identische) Schritte erfordern. Anstatt alle Datensätze in einer Pipeline zu bündeln (was die Behandlung von Fehlern und die Wiederholung von Versuchen erschwert), erhalten Sie auf diese Weise eine separate Pipeline für jede Datenquelle, die Sie konfigurieren. In diesem Beispiel verwenden wir eine ADF-Ressource Pipeline, aber dieselbe Logik und derselbe Ansatz können natürlich auch auf andere ADF-Ressourcentypen angewendet werden (z.B. Datensätze, Trigger usw.). Dies führt uns zu der anderen Option...
Option 2: Nur Trigger-Templating
Eine etwas versteckte Funktion in ADF ist die Möglichkeit, Trigger zu parametrisieren. Trigger werden normalerweise verwendet, um festzulegen, welches Ereignis zu einem Pipeline-Lauf führen soll. Die Parametrisierung von Triggern ist insofern versteckt, als sie nicht angezeigt wird, wenn Sie einen Trigger über die Benutzeroberfläche 'Verwalten' erstellen. Sie wird jedoch angezeigt, wenn Sie einen Trigger direkt über die Benutzeroberfläche 'Autor' der Pipeline erstellen(wenn Ihre Pipeline Parameter hat)
Mit dieser "versteckten" Funktion könnte man eine einzige Pipeline erstellen, die über ADF-Pipeline-Parameter konfigurierbar ist. Die Werte für diese Parameter werden in den ADF-Triggern festgelegt. Der Templating-Mechanismus ähnelt dem, der für die oben beschriebene vollständige Pipeline-Templating-Option verwendet wird, bedeutet aber, dass Sie eine einzige ADF-Pipeline haben, die Parameter zur Unterscheidung zwischen Datensätzen benötigt. Das macht die Überwachung etwas anders, da Sie vom Triggernamen und nicht vom Pipeline-Namen abhängig sind.
{
"name": "{{ meta['name']}}_trigger",
"properties": {
"annotations": [],
"runtimeState": "Stopped",
"pipelines": [
{
"pipelineReference": {
"referenceName": "singleton_pipeline",
"type": "PipelineReference"
},
"parameters": {
"source_dataset": "{{ dataFlowSettings['source']['dataset']}}",
"landing_dataset": "{{ dataFlowSettings['landing']['dataset'] }}",
"landing_path": "{{ dataFlowSettings['landing']['path'] }}",
"ingested_path": "{{ dataFlowSettings['landing']['path'] }}",
"data_schema": "{{ dataDefinitions['tables'] }}"
}
}
],
"type": "ScheduleTrigger",
"typeProperties": {
"recurrence": {
"frequency": "Minute",
"interval": 15,
"startTime": "2021-12-10T12:04:00Z",
"timeZone": "UTC"
}
}
}
}Der Hauptunterschied besteht darin, wie die YAML-Konfiguration übergeben wird. Das Rendering ist einfaches Jinja. In diesem Fall werden die Werte jedoch in einen Trigger gerendert, der die Werte dann als Parameter an eine Singleton-Pipeline weitergibt. Diese Pipeline verwendet dann diese Parameter, um die gewünschte Logik auszuführen.
Optionen für den Einsatz
Sobald wir unsere ARM Pipelines/Trigger erstellt haben, müssen wir sie in ADF übertragen (leider können Sie dieses Rendering nicht innerhalb von ADF durchführen). Hierfür haben wir 2 Ansätze identifiziert, obwohl es zweifellos mehr gibt.
Option 1: Terraform
Eine Möglichkeit zur Bereitstellung der Pipelines nach der Erstellung der Vorlagen ist die Verwendung von Terraform. Terraform ist ein beliebtes Infrastructure-as-Code-Tool, mit dem Entwickler deklarative Konfigurationen für die Bereitstellung und Verwaltung ihrer Infrastruktur schreiben können. Es gibt auch eine gute Unterstützung für verschiedene Azure-Dienste, einschließlich Azure Data Factory. Der Code für eine einzelne Pipeline würde etwa so aussehen:
resource "azurerm_data_factory_pipeline" "test" {
name = "acctest%d"
resource_group_name = azurerm_resource_group.test.name
data_factory_name = azurerm_data_factory.test.name
activities_json = <<JSON
[
{
"name": "Append variable1",
"type": "AppendVariable",
"dependsOn": [],
"userProperties": [],
"typeProperties": {
"variableName": "bob",
"value": "something"
}
}
]
JSON
}Terraform verwendet den Status, um seine Sicht auf die Welt zu speichern und vergleicht sie mit dem, was auf Azure vorhanden ist. Das bedeutet auch, dass es sich um alle CRUD-Operationen auf Ihren ADF-Ressourcen kümmert, so dass Sie Pipelines nicht manuell entfernen/erstellen müssen.
Option 2: Pre-Commit-Haken
Der größte Nachteil der Verwendung von Terraform für die Bereitstellung Ihrer Vorlagen-Pipelines ist, dass Sie dadurch gezwungen sind, den ADF-Live-Modus zu verwenden. Während dies für einige Anwendungsfälle akzeptabel sein mag, kann die Git-Unterstützung in vielen Situationen sehr nützlich sein. Eine Möglichkeit, diese Einschränkung zu umgehen, besteht darin, die Templating-Funktionalität vor jeder Übertragung auszuführen. Da wir Ingenieure sind und gerne automatisieren, kann dies dann in einen Pre-Commit-Hook eingefügt werden. Das Rendering der Vorlagen kann als eine Art "Kompilierungsschritt" betrachtet werden. Indem wir es in einen Pre-Commit-Hook integrieren, erhalten wir ein paar schöne Dinge:
- Wir behalten das Git-Backing für ADF bei, so dass ADF-Ressourcen versioniert werden können.
- Wir brauchen keinen magischen Hack, bei dem eine CI/CD-Pipeline unabhängig in jedes Repository pushen muss.
- Das Rendering der Pipeline ist immer noch automatisiert und kann vom Benutzer nicht versehentlich vergessen werden.
Ihr Pre-Commit-Skript könnte in etwa so aussehen:
python render_adf_resources.py
git --no-pager diff --name-only adf_resources
git add adf_resourcesDer größte Nachteil dieses Ansatzes ist, dass es im Allgemeinen als schlechte Praxis gilt, den Inhalt eines Git-Commits über einen Pre-Commit-Hook zu ändern. Das bedeutet, dass Ihr Git-Konfigurations-Setup Ihren Commit bearbeitet, nachdem Sie ihn erstellt haben, was zu fragwürdigen Ergebnissen führen kann. In diesem Fall sind zwar nur die Verzeichnisse betroffen, die direkt von ADF verwendet werden, aber der Punkt ist trotzdem gültig.
Welche Option ist also der "Gewinner"?
Das kommt darauf an! :-) Jede Option hat Vor- und Nachteile, und Sie müssen die für Sie wichtigsten Funktionen abwägen. Wir hoffen, dass dieser Blogpost Sie bei dieser Entscheidung unterstützt und inspiriert und sind gespannt auf Ihre eigenen kreativen Lösungen für dieses Problem.
Unsere Ideen
Weitere Blogs




Contact