Open Polymer Prediction Challenge: Analysis of the Winning Approach
The NeurIPS Open Polymer Prediction Challenge 2025 attracted over 2,240 teams competing to predict five polymer properties from SMILES representations: glass transition temperature (Tg), thermal conductivity (Tc), density (De), fractional free volume (FFV), and radius of gyration (Rg). We analyzed the winning solution by James Day and identified several key insights that challenge current research trends while demonstrating the continued effectiveness of classical machine learning techniques.
Key Takeaways
Property-specific models remain superior for limited data: Despite the research community's push toward general-purpose foundation models, property-specific models proved more effective when working with constrained datasets.
Ensemble methods continue to excel: This traditional machine learning technique delivered exceptional performance, reinforcing its value in modern competitions.
External data demands careful curation: As discussed in The challenges of molecular property datasets, integrating external data sources requires meticulous preprocessing to address inconsistencies and noise.
General-purpose BERT outperformed domain-specific models: ModernBERT exceeded the performance of chemistry-specific models, though polyBERT embeddings were retained as valuable tabular features.
Strategic 3D model selection: The winning solution employed Uni-Mol-2-84M as its 3D model. This choice is particularly interesting given that Praski et al. demonstrated superior performance from graph transformer models like R-MAT on molecular property prediction tasks, especially for drug-related properties. R-MAT models offer easy implementation and reduced memory requirements, making the Uni-Mol-2 choice worth examining.
Architecture Overview

The winning approach generated property-specific predictions using ensembles of ModernBERT, AutoGluon, and Uni-Mol-2 models through a multi-stage pipeline:
- Initial training on externally labeled datasets
- BERT model retraining on a pseudolabeled PI1M subset
- Extensive feature engineering for tabular models
- Post-processing adjustment for glass transition temperature predictions to compensate for distribution shift between training and leaderboard datasets
Data Strategy

Dataset Composition and Augmentation
Model validation relied on 5-fold cross-validation using the competition's original training data. The training data was substantially augmented with external datasets and locally executed MD simulations. The winner identified significant data quality challenges and a distribution shift between the training and leaderboard datasets.
Addressing Distribution Shift
Investigation revealed a pronounced distribution shift in glass transition temperature (Tg) between training and leaderboard datasets.
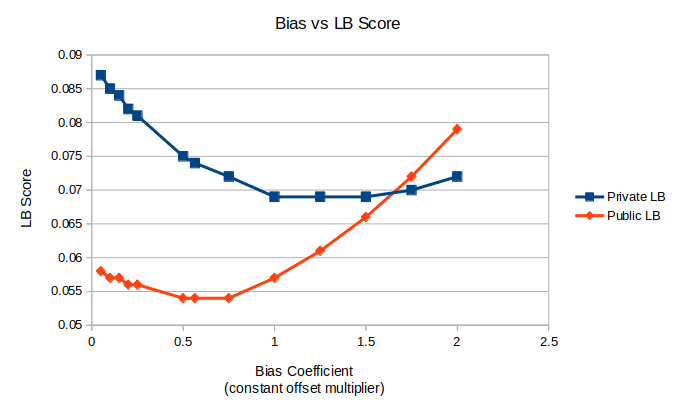 The lower bound (LB) score is the wMAE metric used in the competition. The Bias Coefficient is a factor that is multiplied with the standard deviation of the glass transition predictions, this product is then added to the original Tg predictions.
The lower bound (LB) score is the wMAE metric used in the competition. The Bias Coefficient is a factor that is multiplied with the standard deviation of the glass transition predictions, this product is then added to the original Tg predictions.
To correct this systematic bias, predictions underwent post-processing: submission_df["Tg"] += (submission_df["Tg"].std() * 0.5644)
External Data Sources
The solution incorporated several external datasets:
These datasets presented multiple challenges: random label noise, non-linear relationships with ground truth, constant bias factors, and out-of-distribution outliers.
Data Cleaning Methodology
Three general strategies were applied across all datasets:
Label rescaling via isotonic regression: An isotonic regression model transformed raw labels by learning to predict ensemble predictions from the original training data. This approach effectively corrected for constant bias factors and non-linear relationships with ground truth. Final labels often represented Optuna-tuned weighted averages of raw and rescaled values to minimize overfitting.
Error-based filtering: The ensembles' predictions were used to identify samples exceeding an error threshold, which were discarded. Thresholds were defined as ratios of sample error to mean absolute error from ensemble testing on the host dataset, ensuring consistent threshold ranges across properties and facilitating Optuna hyperparameter search.
Sample weighting: Optuna tuned per-dataset sample weights, enabling models to discount lower-quality training examples appropriately.
Dataset-specific interventions included:
RadonPy: Manual inspection identified and removed outliers, particularly thermal conductivity values exceeding 0.402 that appeared inconsistent with ensemble predictions. Optuna frequently favored this filtered version during hyperparameter tuning.
MD Simulations: Rather than applying general cleaning strategies, the solution implemented model stacking. An ensemble of 41 XGBoost models predicted simulation results, and these predictions served as supplemental features for AutoGluon. This approach allowed second-level models to learn arbitrary non-linear relationships in potentially noisy simulation data. The tabular models achieved a CV wMAE improvement of approximately 0.0005 compared to excluding simulation results entirely.
Optuna included general cleaning strategies and the RadonPy filter rule as hyperparameters, confirming their value through optimization.
Deduplication Strategy
Dataset augmentation introduced duplicate polymers identified by converting SMILES to canonical form. Optuna determined optimal sampling weights for duplicates, with lower-weighted entries removed.
To prevent validation set leakage, Tanimoto similarity scores were computed for all training-test monomer pairs. Training examples with similarity scores exceeding 0.99 to any test monomer were excluded to eliminate near-duplicates.
MD Simulation Data Generation
Molecular dynamics simulations were executed for 1,000 hypothetical polymers from PI1M through a four-stage pipeline:
-
Configuration Selection: A LightGBM classification model predicted optimal configuration choice between two strategies:
-
Fast but unstable: psi4's Hartree-Fock geometry optimization (~1 hour per polymer, 50% failure rate)
- Slow and stable: b97-3c based optimization (~5 hours per polymer)
Classification features included RDKit molecular descriptors, backbone versus sidechain characteristics, and conformers from ETKDGv3 generation with MMFFOptimization.
-
RadonPy Processing:
-
Confirmation search execution
- Automatic degree of polymerization adjustment to maintain ~600 atoms per chain, independent of monomer size
- Charge assignment
-
Amorphous cell generation
-
Equilibrium Simulation: LAMMPS computed equilibrium simulations with settings specifically tuned for representative density predictions.
-
Property Extraction: Custom logic estimated FFV, density, Rg, and all available RDKit 3D molecular descriptors.
BERT Implementation

Model Selection
The solution achieved optimal results with ModernBERT-base, a general-purpose foundation model, rather than chemistry-specific alternatives. Both ChemBERTa and polyBERT underperformed relative to ModernBERT-base. Among general-purpose BERT variants, ModernBERT outperformed alternatives like DeBERTa. Given ModernBERT's extensive training on coding data and strong coding task performance, CodeBERT was evaluated and performed comparably. Larger models failed to deliver improvements given the limited fine-tuning data available.
Pretraining on PI1M
The solution implemented a two-stage pretraining approach:
Stage 1: An ensemble of BERT, Uni-Mol, AutoGluon, and D-MPNN models generated property predictions for 50,000 PI1M polymers.
Stage 2: BERT models were pretrained on a pairwise comparison classification task, predicting which polymer exhibited higher or lower property values in each pair. Polymer pairs with similar property values were excluded. The objective functioned as a multi-task classifier, simultaneously predicting relationships across all five properties. This additional pretraining stage consistently improved performance over third-party foundation models.
Fine-tuning Protocol
The fine-tuning process followed standard BERT practices:
- AdamW optimizer
- No frozen layers
- One-cycle learning rate schedule with linear annealing
- Automatic mixed precision
- Gradient norm clipping at 1.0
- Optuna-tuned learning rate, batch size, and epoch count
The limited training data necessitated differentiated learning rates: the backbone learning rate was set one order of magnitude lower than the regression head learning rate. The choice of No Frozen Layers surprised me given the limited training data, but the differentiated learning rates likely mitigated overfitting and training instability.
Data Augmentation
Both pretraining and fine-tuning employed Chem.MolToSmiles(..., canonical=False, doRandom=True, isomericSmiles=True) to generate 10 non-canonical SMILES per molecule, expanding training data tenfold. At inference, 50 predictions per SMILES were generated and aggregated using the median as the final prediction.
Tabular Modeling
Framework and Feature Selection
AutoGluon served as the tabular modeling framework, with Optuna selecting optimal features for each property.
Feature Engineering
The feature set encompassed diverse molecular representations:
Molecular descriptors and fingerprints:
- All RDKit-supported 2D and graph-based molecular descriptors
- Morgan fingerprints
- Atom pair fingerprints
- Topological torsion fingerprints
- MACCS keys
Graph and structural features:
- NetworkX-based graph features
- Backbone and sidechain features
- Gasteiger charge statistics
- Element composition and bond type ratios
Model-derived features:
- Predictions from 41 XGBoost models trained on MD simulation results (FFV, density, Rg predictions, and 3D structure descriptors)
- Embeddings from polyBERT models pretrained on PI1M
Model Comparison
Alternative frameworks, including XGBoost, LightGBM, and TabM, underwent extensive hyperparameter tuning with approximately 20× the computational budget allocated to AutoGluon. Despite this additional optimization effort, AutoGluon maintained superior performance.
3D Molecular Modeling
Uni-Mol 2 84M was selected primarily for implementation efficiency. The model required no feature engineering or custom training loops, streamlining the development process. GPU memory constraints (24GB) emerged when processing larger molecules exceeding 130 atoms, particularly affecting FFV training data. Consequently, Uni-Mol 2 84M was excluded from the FFV prediction ensemble.
Unsuccessful Approaches
The following strategies failed to improve performance:
- Graph Neural Networks, specifically D-MPNN
- GMM-based data augmentation from public notebooks
- Chemistry-specific embedding models
Acknowledgements
We thank James Day for openly sharing the code, solution notebook, and detailed writeup that enabled this analysis.
Credits for banner image: Lone Thomasky & Bits&Bäume / Distorted Lake Trees / Licenced by CC-BY 4.0
Written by

Jetze Schuurmans
Machine Learning Engineer
Jetze is a well-rounded Machine Learning Engineer, who is as comfortable solving Data Science use cases as he is productionizing them in the cloud. His expertise includes: AI4Science, MLOps, and GenAI. As a researcher, he has published papers on: Computer Vision and Natural Language Processing and Machine Learning in general.
Contact