Blog
UV: The Engineering Secrets Behind Python's Speed King

UV: The Engineering Secrets Behind Python’s Speed King
Python packaging has long been a bottleneck for developers. Slow installations, complex dependency resolution, and fragmented tools. UV, the new package manager from Astral (creators of Ruff), changes this by completely rethinking Python packaging from the ground up.
This blog is inspired by a talk Charlie Marsh gave at Janestreet.
Understanding Traditional Python Package Managers
Python package managers like pip perform three core functions: 1. They resolve dependencies (figure out which package versions work together) 2. Download packages 3. Install packages into isolated environments.
Under the hood, these tools face fundamental challenges because: - They're written in Python and require Python to run, creating circular dependencies. - They use slow algorithms for dependency resolution. - They perform redundant I/O operations during installation. - They rely on sequential processing despite modern multi-core hardware.
This architecture leads to the slow performance Python developers know too well, where simple operations like creating a virtual environment or installing packages can take seconds or even minutes for complex projects.
UV's Architectural Innovations
UV rethinks this entire stack from first principles, making several key innovations that results in a 10-100x speed up over traditional tools like pip or poetry. Lets go through the engineering secrets behind these innovations and highlight why UV is faster then the established tools.
1. Breaking the Python Dependency Cycle
Unlike traditional Python package managers, UV doesn't require Python to be installed beforehand. Built as a static Rust binary, UV dynamically locates Python interpreters only when needed.
UV manages virtual environments through direct filesystem operations rather than relying on Python's venv module. When creating a venv/ directory, UV uses a clever optimization: instead of copying Python binaries (which would waste disk space), it creates hard links. A hard link is a filesystem feature where multiple directory entries point to the same underlying data blocks on disk. Resulting in zero copy overhead.
Pyproject.toml files are parsed natively in Rust, Python subprocesses are only used when absolutely necessary for legacy setup.py files (as a fall-back mechanism). The conventional approach used by pip and other tools involves launching a Python interpreter just to read basic project information. When you install a package, the tool first takes hundreds of milliseconds starting Python, then loads various modules to parse your pyproject.toml or setup.py. UV reads and interprets pyproject.toml files using Rust's optimized parsing libraries, eliminating the Python startup time and reducing metadata processing to microseconds.
 *time to parse a simple pyproject.toml file with numpy as only dependency. UV using Rust parsing libraries vs. Python parsing.
*time to parse a simple pyproject.toml file with numpy as only dependency. UV using Rust parsing libraries vs. Python parsing.
Most importantly, UV delivers consistent results across all environments. The same pyproject.toml file will result in identical outcomes, whether you're running it on Windows, Linux, or macOS.
2. SAT-Solving Dependency Resolution
Python's lack of multi-version support transforms dependency resolution into an NP-hard problem, where finding compatible versions scales exponentially as projects grow more complex. Traditional tools handle this through backtracking, essentially guessing and checking combinations until one works. UV instead uses a Conflict-Driven Clause Learning (CDCL) SAT solver, technology borrowed from hardware verification systems that mathematically proves whether a solution exists. Explaining how CDCL SAT solving exactly works is out of scope for this blog, but we will try to explain it at a high level.
UV's dependency resolver models the problem mathematically, treating each possible package version as a variable that can be either included or excluded. The constraints between packages (like "this package needs that other package at version 2.0 or higher") become logical rules that must all be satisfied simultaneously.
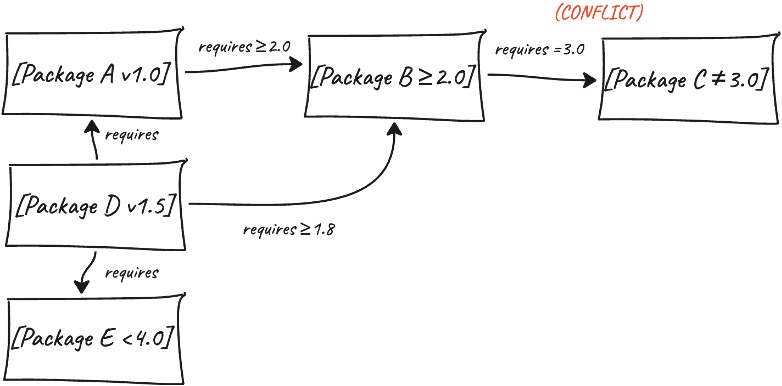
As the solver evaluates possible combinations, it identifies and records any conflicts it encounters. When it finds that certain package versions can't work together, it uses this information to immediately eliminate millions of other invalid combinations without testing each one individually. This approach is fundamentally different from traditional methods that try versions one at a time and backtrack when they hit problems.
For platform-specific requirements, UV employs specialized data structures called Algebraic Decision Diagrams. These efficiently track and combine conditions like "only install on Linux" or "requires Python 3.10+" to ensure the solution works correctly across different environments. So if we take the graph above, and add system specific requirements. When UV tries to solve this graph it can then skip certain tracks based on the system we run UV on. Let’s assume we run it on Linux:
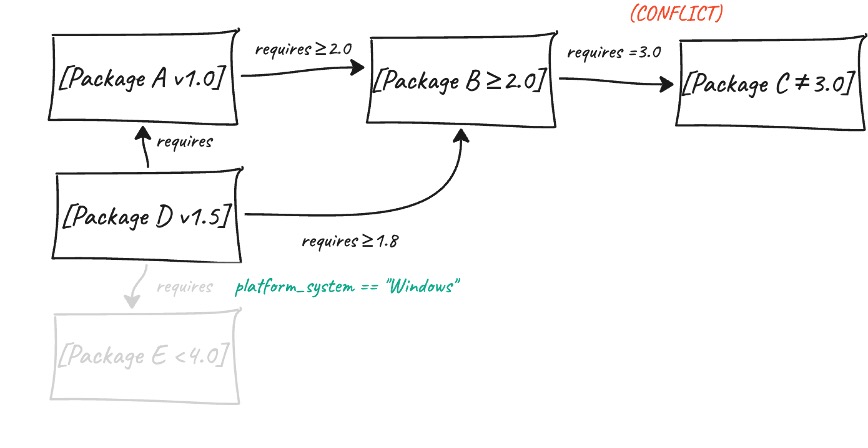
The solver either finds a complete set of compatible versions that satisfies all constraints or conclusively proves that no such combination exists, unlike other tools that might give up after trying a limited number of possibilities.
3. Installation Optimizations
Once UV's resolver determines the combination of package versions, it shifts into an optimized installation phase designed to minimize I/O operations. Rather than downloading entire wheel files just to inspect their metadata, a common inefficiency in traditional package managers, UV makes HTTP range requests to fetch only the few kilobytes of package metadata it needs, skipping the remaining 99% of a large wheel file like PyTorch. A HTTP range request adds a header to the GET request specifying the required bytes; RANGE bytes=START-END.
UV's global cache system delivers the isolation benefits of separate installations without the storage overhead or write latency of actual copies. All extracted wheel contents are stored in an optimized structure at ~/.cache/uv/wheels/. When installing packages into a virtual environment, it creates hard links that point to the cached files while making them appear in the new environment.
UV achieves near-instantaneous package metadata access O(1) complexity by eliminating slow parsing and conversion steps. Compared to traditional methods that process entire datasets from scratch, UV's approach makes package information available immediately in the perfect format for use. UV loads package metadata through a technique called zero-copy deserialization using .rkyv files. Instead of parsing text-based formats like JSON, which requires slowly converting strings into data structures, UV stores metadata in a specialized binary format that perfectly matches how the information will be used in memory. When UV needs this data, it simply tells the operating system to map the file directly into the program's memory space, no parsing or conversion needed.
These optimizations are particularly impactful for large packages. Installing something like PyTorch with UV typically takes seconds rather than minutes because it only downloads what's actually needed and avoids redundant disk operations.
4. Parallel Execution
UV maximizes hardware utilization through a layered parallel architecture. At the I/O level, UV leverages Rust's async Tokio runtime to handle network and disk operations without blocking. This allows multiple HTTP requests for package metadata to happen simultaneously while overlapping downloads with extraction.
For CPU-intensive tasks, UV employs the Rayon thread pool to parallelize work across all available cores. Dependency graph resolution, which would normally be a sequential process in other package managers, becomes a parallel operation where different branches of the dependency tree can be analyzed simultaneously. File operations like package installation also benefit from this approach, with multiple files being processed in parallel rather than one at a time.
At the memory level, UV uses lock-free data structures that enable concurrent access to its cache without traditional mutex bottlenecks. Instead of blocking threads with mutexes, UV leverages atomic pointers with built-in versioning. Each CPU core gets its own copy of the cache line. When a thread updates cached package data, it creates a modified copy and uses a single atomic compare-and-swap operation to publish the change, while readers always see either the old or new consistent state without waiting.
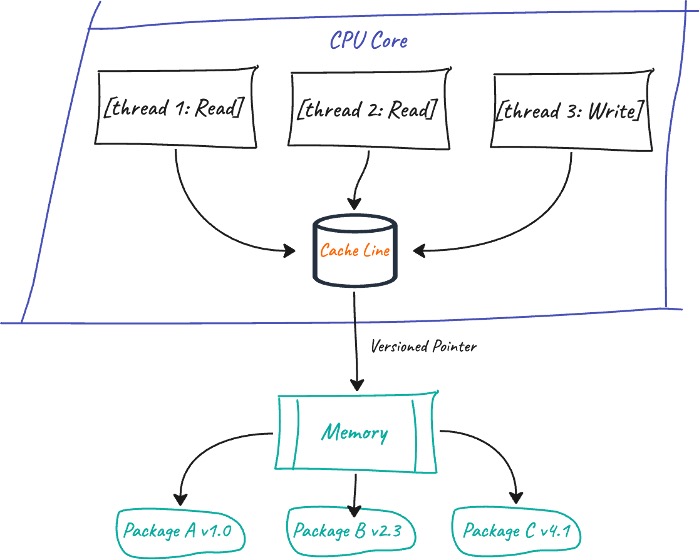
Virtual environment updates happen atomically, ensuring consistency while allowing multiple threads to work with the environment data safely.
Transforming Developer Workflows
The cumulative effect of these innovations is more than just faster benchmarks. UV fundamentally changes how developers interact with Python packaging:
- Virtual environments become disposable - creating one takes milliseconds, enabling workflows like per-feature-branch isolation.
- Dependency resolution is predictable - no more "works on my machine" inconsistencies.
- CI pipelines accelerate - jobs that took minutes now complete in seconds.
- Disk space is conserved - hard links eliminate redundant copies of package files.
By removing friction from these foundational operations, UV lets developers focus on writing code rather than managing their environment. The speed improvements aren't incremental - they enable workflows that were previously impractical.
Inspired to try UV? Astral’s official documentation makes it easy to get started with integrating UV into your Python projects.

Written by
Xebia Author
Our Ideas
Explore More Blogs




Contact