
Teachings from the old world
When I started my career in IT as a software tester, the first mantra that was drilled into my brain was “the earlier you find an issue, the cheaper it is to fix”. For a long time, this, and the “quality is free” mantra, have been the foundation and justification for the world of Quality Assurance.
However, over the last 20 years the world of software development has drastically changed with Agile, DevOps, CI/CD, cloud, etc. All these approaches and techniques have radically increased the speed of delivery and the quality of the product.
This raises the question: is testing everything as early as possible still the best approach towards software quality or have alternative approaches become viable nowadays?.
Winds of Change
Most of us will be familiar with the decades-old Boehm's curve (see figure 1) claiming that fixes in production are a multitude more expensive than fixing issues during development. This picture is used to justify an almost frantic focus on testing as much as possible, as early as possible. Even nowadays it is still often used to make strategic quality choices, but does that still make sense in the modern landscape of software development?
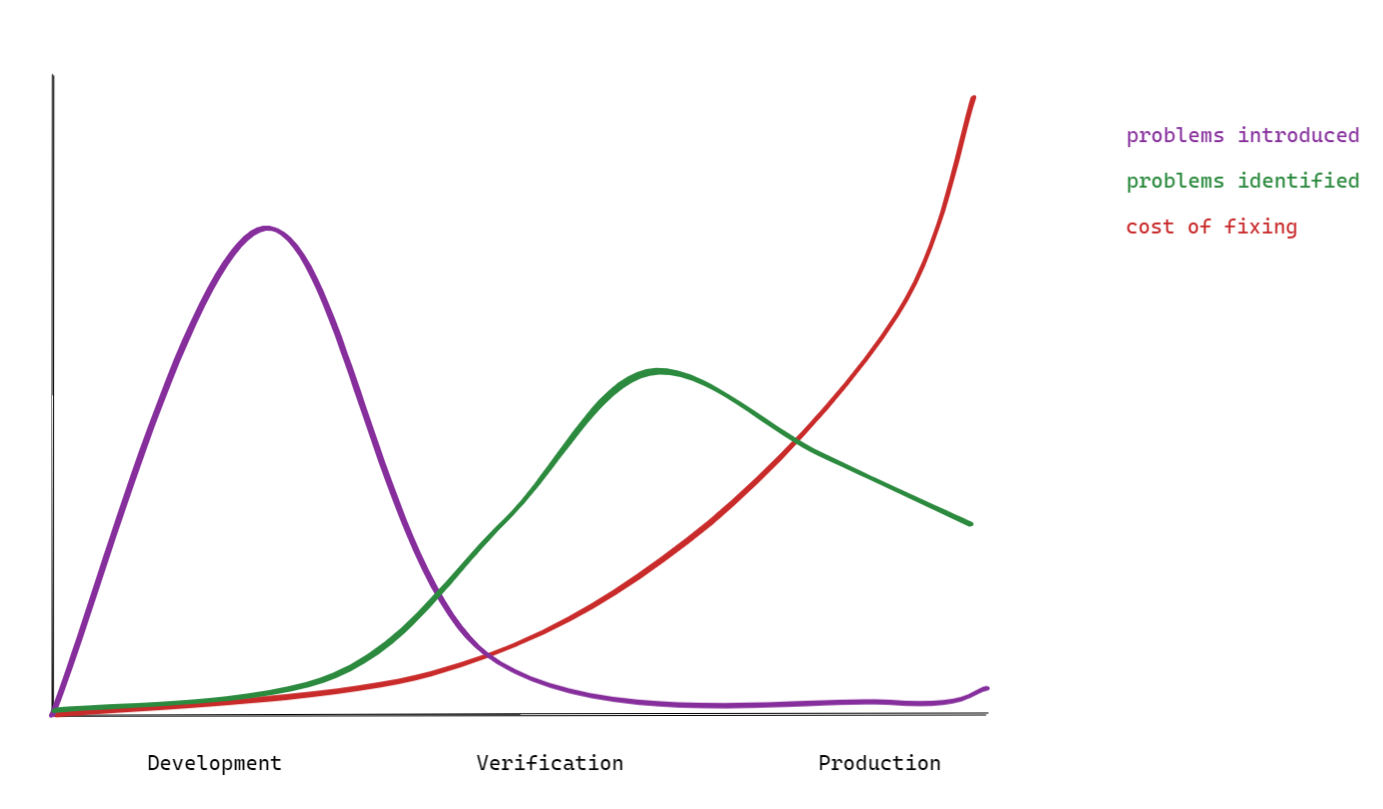
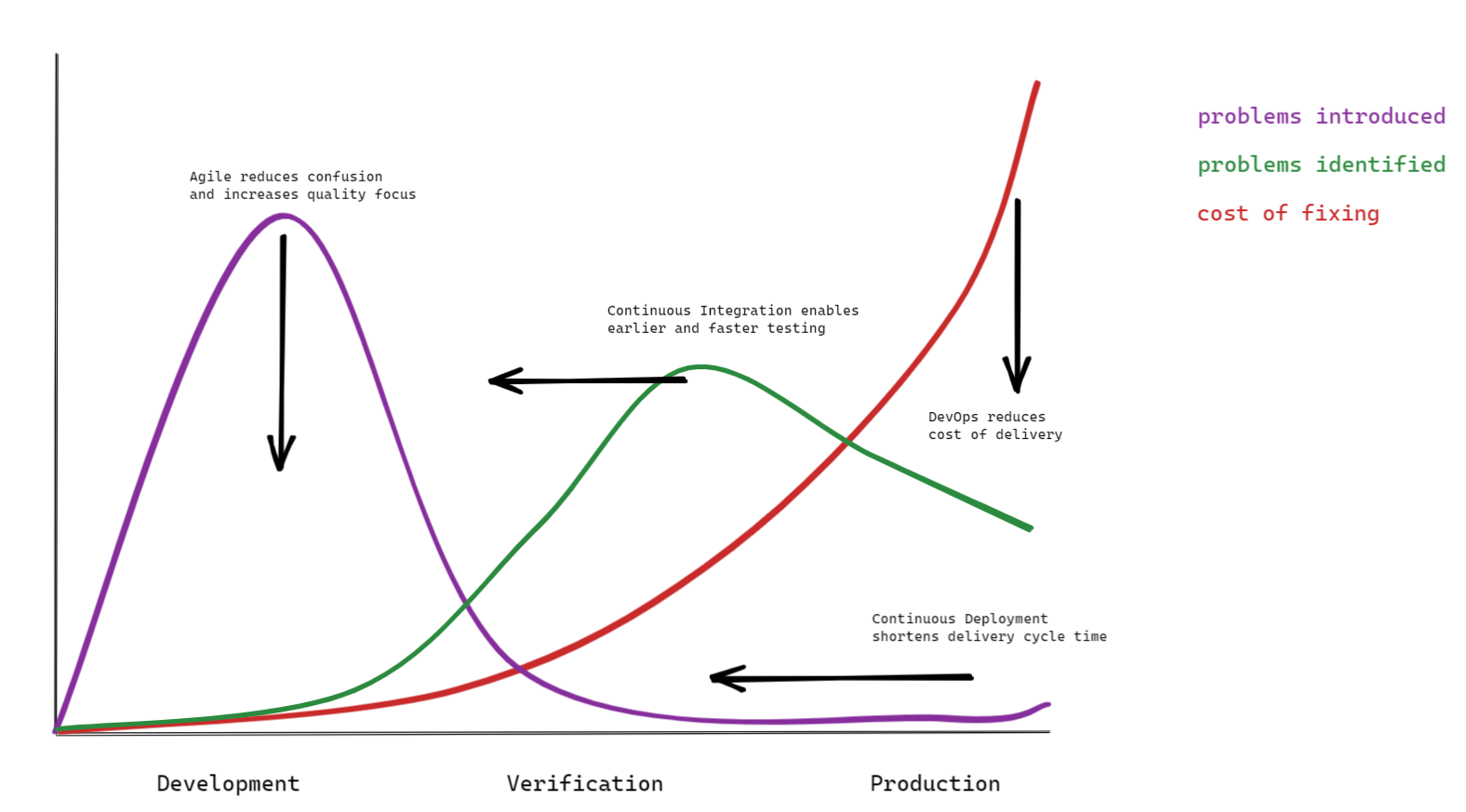
To answer that question let's first look at the way we do software development nowadays and how it affects Boehm's curve (see figure 2):
- Agile brought us more aligned requirements (causing fewer flaws), and more effective software development (causing fewer bugs). This reduced the ‘problems introduced’ peak in the development phase.
- Continuous Integration automated the process of merging code and testing the result. This allowed for bugs to be identified earlier and faster.
- DevOps gave teams deployment autonomy and independence, resulting in, amongst others, a less cumbersome, and therefore cheaper, deployment process.
- Continuous Delivery provided deployment capabilities to the teams, making deployment faster and more consistent.
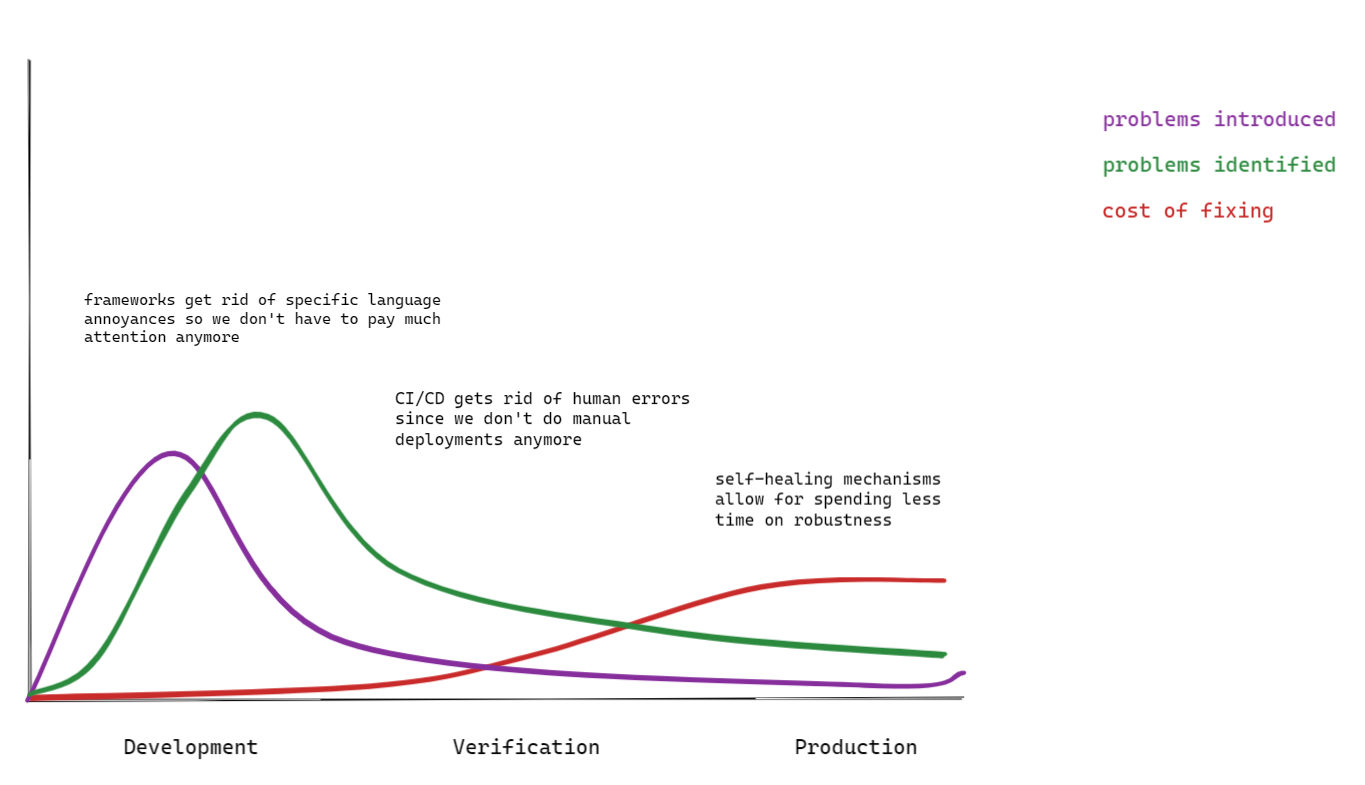
When we overlay the effects of modern software development on the classic figure, we get a graph that tells a very different story (see figure 3). With increased levels of quality, higher levels of automation, and reduced deployment cycle times, the cost of fixing in production is likely still higher than fixing in development, but the difference is no longer an order of magnitude.
A new strategy based on old concepts
Clearly modern software development approaches challenge the ‘early fixing is always better’ statement. How does that impact our approach towards quality?
Nowadays, development teams can deploy to production faster, cheaper, and easier than they could to a testing environment 10 years ago. With all this increased speed and flexibility, we have arrived at the point where there can be such a thing as ‘too much quality’. In the original LEAN model this was called ‘extra processing’ and nowadays we would call it gold-plated engineering.
Fixing issues when they become a problem in production should therefore be considered a realistic option in your quality assurance strategy. The chance and impact of a part of your application not functioning as intended should be a driver for making that decision. In the end, time is limited, so you should decide to spend it on more quality or more functionality.
Of course, fixing stuff late still costs more time than preventing it, but when you can almost instantly deploy to production you can start to think differently about incidents.
Start measuring failure
Ultimately you want to be as close as possible to the quality your customers expect from you; anything on top of that is factually extra-processing. This approach is also the basis of Google's SRE approach; customer desires (SLA) are converted into measurable indicators (SLI) and thresholds (SLO) define the behavior of development teams. As long as teams stay below the threshold, they can spend time on new features. However, when the service objective becomes threatened, development will have to spend their time on fixing problems and getting back into the ‘safe zone’.
The concept of a threshold can be used to shape the optimal quality strategy. One implementation could be keeping track of a quality budget burn-down chart (see figure 4). Teams state how comfortable they are with spending time on incidents, maintenance, and quality improvements and start tracking actual time spent. After a while, it will become clear whether they are in the ‘too much safety’ or ‘too little reliability’ zone.
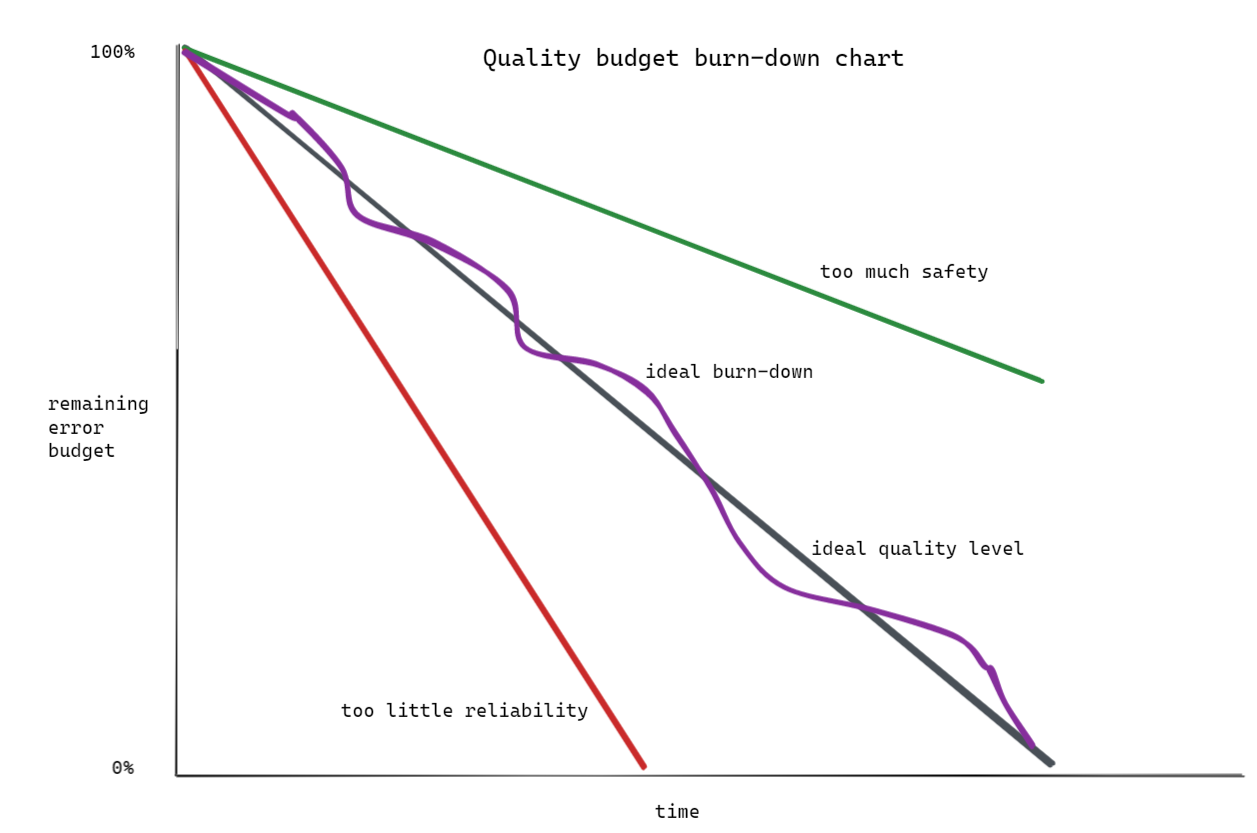
This approach does require a paradigm shift. It is no longer sufficient to just know what can go wrong or what is broken; it becomes more important to really understand how to act if something goes wrong. But this is, in fact, also an aspect of quality. Quality is not only about prevention, but also just as much about getting into the mindset that things break all the time, to accept that, and to train how to respond to incidents.
Embrace Incidents!
The shift-left hype in software development caused a mindset of preventing all issues, all the time without thinking about the required quality level. It is time to flip the script and restore the balance. Organizations should start specifying what quality is needed and align their quality strategies accordingly. With the speeds that modern software development can provide, production failures are no longer always a bad thing. Accepting incidents as part of your strategy towards deviations might be a more effective use of your valuable time.
Written by

Dave van Stein
Process hacker, compliance archeologist and anthropologist, ivory tower basher, DepSevOcs pragmatist, mapping enthousiast, complexity reducer, intention sketcher. LEGO® SERIOUS PLAY® Facilitator.
Our Ideas
Explore More Blogs


From Spec to Code: Building Software with Spec Kit
This article walks through the full workflow, from installation to a working implementation, covering both greenfield projects and extending an...
Hidde de Smet, Emanuele Bartolesi


Contact