
How to create unique content with Large Language Models
Do you sometimes struggle with creating content? Do you fall victim to repetition? Whether it’s a blog/manual/podcast you’re trying to produce, Large Language Models can help you to create unique content if you use them correctly. In this post, I’ll combine GPT-4, GPT-3.5, DALL-E, Azure Machine Learning and Azure AI Speech (formerly Cognitive Services) to create fresh daily content.
A self-guided meditation is usually an audio file where a narrator helps you focus on a topic. If you’ve ever tried meditation, you’ve probably used a mobile app like Calm or Headspace. These apps offer great content for self-guided meditations, but their offering is limited. This limitation is especially apparent if you like a specific style of meditation. I don’t mind repetition, but if the same audio file is played twice, I become too aware of it to be effective. Surely, in the age of AI, I don’t have to depend on humans to create my guided meditation. So, I set out to make an application to spin up a fresh session every day and upload it to YouTube. I had only two rules for myself: 1. No manual steps. I want everything to be automated. 2. A unique meditation is uploaded to YouTube every day.
Creating this type of content consists of multiple steps, perhaps more than you would imagine. Most of these steps use Artificial Intelligence and usually take some time to process. I’m building this in an Azure Durable Function to deal with these long-running processes. The code for this application can be found in my GitHub repository.
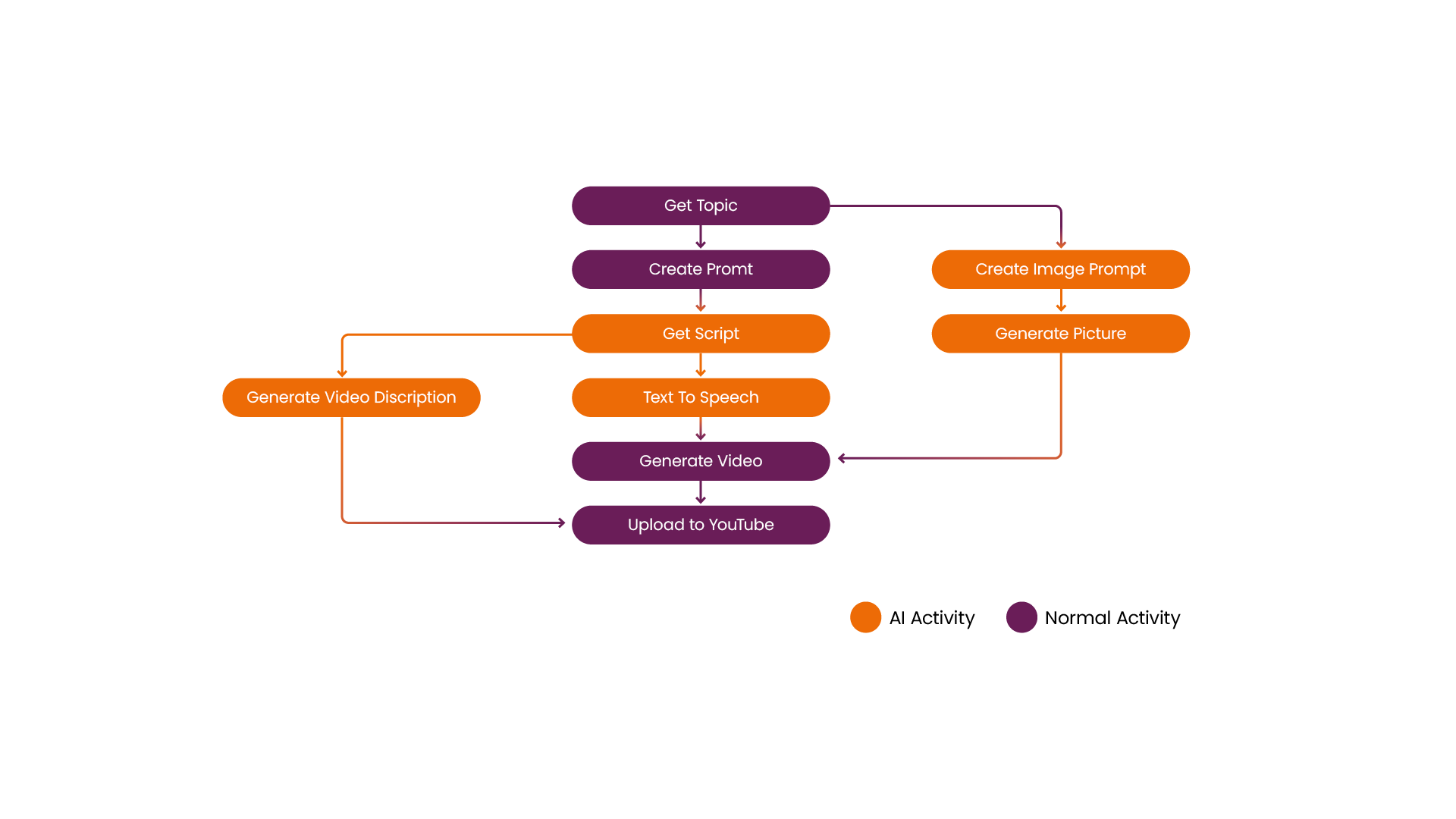
Figure 1: Flow
From topic to prompt
The first thing we need is a meditation instructor to create the script. Instead of relying on a human, we can ask a Large Language Model (LLM) to be our instructor. For our LLM, I’ve selected GPT-4. While we would get decent results with GPT-3.5 (and much faster, too!), GPT-4 seems more ‘creative’ in the content it generates, which is perfect if I need it to create long, unique scripts with little input. Later in this project, I’ll use GPT-3.5 for more straightforward tasks. It’s always important to take a moment to think about which model to use. Creativity is great, but GPT-4 costs roughly 20 times more than GPT-3.5! To get our script, I created a prompt explaining what I expect from the LLM. This text is called a system prompt and will ground the rest of our conversation with the model. Here’s an example of the prompt. The full version can be found in the repository:
You are a friendly meditation instructor. You're going to write a script for our next guided meditation.
You can advise your student to sit, with their hands folded in their lap. They could sit on the ground, on a chair or a pillow. Maybe they want to lie down.
Make sure to add breaks often, which can be between 5 and 40 seconds, depending on what feels natural. Indicate a break in this format: <BREAK10> for 10 seconds, <BREAK40> for 40 seconds.
The students love it when you start them out focusing on their breath. Help them breathe in through their nose and out through their mouth. Repeat this exercise a few times. Add a few-second break between the breaths.
After a few repetitions, we can focus on something else. The user will supply you with the topic.
Please don't use the word "namaste". Don't add a break at the end of the script. Address the student as friend, student, but not plural. You can use the word "you" to address the student. We're aiming for a 10 minute session, but don't mention that to the student. Aim for around 1000 words.My system prompt includes a few key things: 1. Giving the AI a role and some personality (i.e. a friendly meditation instructor). 2. It provides a few hints about the format of the meditation. 3. Instructions to add breaks. 4. Readies the AI to act on the user prompt. 5. Things to avoid.
The above is a very short prompt; through experience, I’ve learned that you spend about as much text to instruct the LLM what not to do as what you want it to do. And those cases (e.g. “don’t mention the meditation time to the user”) only come out once you’re further in the process. Don’t be afraid to experiment with your prompts. However, it’s good to use professional tooling because prompt engineering is more than just stringing some words together. I used a new Azure Machine Learning feature called Prompt Flow to make my prompt. Prompt Flow is a tool that allows you to iterate through prompts and measure their effectiveness easily. It’s currently in preview but is worth a look. Not only does it allow you to create variants of prompts for manual testing, but it also allows for automated evaluation of the results of an LLM. You can score the results on how well they address the prompt, user input, or any other metric you can think of. I focused on how many words the LLM produces to evaluate my prompt. I would rather have a more extended meditation session, with more room to relax, than a fast one that doesn’t get the point across.
Creating the script
With our prompt in hand, we can start asking GPT-4 to create our script. You can use GPT-4 through the OpenAI APIs or Azure OpenAI Service. The API specification is the same, but since the rest of my application runs on Azure, I prefer Azure OpenAI. It keeps all the billing in one place and offers extra features, like finetuning models, setting custom content filtering options, and more. I mentioned that our system prompt grounds the rest of the conversation. In this case, the conversation will be a short one. I supply a system prompt and then follow up with a user message. The user message will contain the topic of the meditation. When we submit this ‘chat’ to the API, the LLM will respond with our meditation script. It might seem strange that we need to submit this as a chat, but GPT-4 is not accessible through the Completion API (which will be deprecated in 2024). The code snippet below shows how a typical chat is built up in C#. Every message has a role: System, User, or Assistant. The System message contains our system prompt, the User message contains the topic and the LLM will respond with the Assistant message. Because we gave very few limitations in our system prompt, our topic can be a single word or an entire paragraph.
var prompt = await File.ReadAllTextAsync("Prompts/script-prompt.txt");
Response response = await this.openAiClient.GetChatCompletionsAsync(
“gpt-4”,
new ChatCompletionsOptions
{
Messages =
{
// Add the system prompt.
new ChatMessage(ChatRole.System, prompt),
// Add the user prompt containing the topic.
new ChatMessage(ChatRole.User, createScriptContext.Topic)
},
Temperature = 0.8f,
MaxTokens = 5000
});
When you interact with the chat API, you can tweak several settings. The most critical settings for my scenario are the maximum amount of tokens and the “temperature”. The maximum token amount tells the LLM how much text can be returned. Tokenisation could be an entirely separate article, so let’s keep it simple: 1 token is not a fixed length and can be a single character, a syllable, or a word. This can make it difficult if you need your content to be a specific length. The Temperature setting introduces more randomness to the response. Set it to 0 and the model will only respond with the most likely tokens. It will react with almost identical messages for the same input if you run it multiple times. Set the temperature to 1, and the responses will be wildly different to downright unpredictable. Because I want to generate unique content without changing my system prompt every time, I set a relatively high temperature of 0.8. A high temperature allows the LLM to take any topic we provide, ranging from mindful to very silly, and turn it into a perfectly calming meditation.
Text to speech
We must transform this text into audio to make this a true self-guided meditation. There are a lot of text-to-speech applications out there, and I wanted one that sounded realistic enough to meditate on without being bothered by a computer voice. I settled on Azure AI Speech (recently renamed from Azure Cognitive Speech). Azure AI Speech hosts many speech-related features, including text-to-speech. The two main reasons I chose this service are that it’s part of Azure, keeping all my resources/billing/access management in one place, and also because it supports Speech Synthesis Markup Language (SSML). This W3C standard for text-to-speech is beneficial for our type of content. You may have noticed in the prompt to GPT-4 we asked it to include breaks. SSML supports adding breaks in text-to-speech, which is excellent for meditations. You don’t want someone droning in your ear continuously. SSML allows you to define the voice, choosing different languages and accents, as well as the style of the voice. Not all of the voices support different styles, I ended up with an American English voice that supported the “hopeful” style, which matches the style that I like during this type of content. It’s also worth noting that because SSML is a widely used standard, you can even ask GPT-4 to generate a script in SSML! This shows just how versatile GPT-4 is. While the results were good, in my testing with Prompt Flow I’ve noticed that it will reduce the overall duration of the meditation, even when you allow it to generate the maximum amount of tokens. So instead, I had the LLM indicate breaks differently and turned it into SSML with some basic string formatting. Now that I have some SSML, I can feed this to Azure AI Speech to get my audio!
var speechConfig = SpeechConfig.FromSubscription(this.key, this.region);
speechConfig.SetSpeechSynthesisOutputFormat(SpeechSynthesisOutputFormat.Riff16Khz16BitMonoPcm);
// Set the audio config to null. otherwise it will try to use the default audio device.
// Pretty sure Azure data centers don’t have a default audio device.
using var speechSynthesizer = new SpeechSynthesizer(speechConfig, null);
var result = await speechSynthesizer.SpeakSsmlAsync(createNarrationContext.Script);
Add some background music
At this point, I thought I was done. I created a script and turned it into audio. But while listening to the audio, something was missing. The breaks go on for a long time (anything over 5 seconds is long), and I wondered if the session was over or if the software failed to produce a good result. But soon, I realized that the silence was just too distracting. To counter this, I wanted to add some background sounds. I found some royalty-free nature sounds online that were a perfect fit. After some quality time with the excellent NAudio NuGet package and a deep dive into wave formats, I merged the narration with the background audio. This resulted in a perfect mix of a hopeful voice guiding you through the meditation and soothing nature sounds to fill the gaps.
Create Video
One of the goals I set for myself was to upload the results to YouTube. I wasn’t quite sure if YouTube would allow an audio file to be uploaded, or at least a video file that was completely black, so I set out to add an image to the video track. Of course, I don’t want to manually pick an image, nor do I want the same old image for every video I upload, so it’s time for more artificial intelligence. Just in time, Microsoft released DALL-E as part of the Azure OpenAI service. DALL-E takes a text prompt and turns it into an image. Like with most AI tools, it’s easy to get a good result, but difficult to get a great result. So, instead of creating a generic prompt, I asked GPT-4 to create the prompt for DALL-E instead. I supply the topic of the meditation, as well as this new system prompt just like I did to generate the script, and out rolls a prompt for DALL-E. I try not to limit the response too much, instead, I add some tips and tricks for using DALL-E.
Create a prompt for a square image. The prompt will be sent to an AI algorithm that creates an image. Only reply with the prompt.
The prompt should be for a colourful and calming image for a meditation session. The user will supply you with the topic. Here’s some tips:
- Start with the character before the landscape, if there are characters involved, so you can get the body morphology right before filling the rest.
- The prompt should mention what’s shown, as well as the colours and the mood.
- Adding an adjective like “gorgeous”, “stunning” or “breathtaking” can make a big difference.
Figure 1: DALL-E prompt: A serene monk meditating under an ancient, sprawling tree, thoughts materializing as vibrant butterflies fluttering away, set against a backdrop of a breathtaking sunset, in the style of surrealism.
Publish to YouTube
I won’t go into detail on how to upload videos to YouTube through a cloud application, but every video needs a video title and description. The original topic of a meditation session might not be suitable for a title, and it’s usually not very descriptive, either. To automate the generation of this metadata, I decided to use GPT-3.5 Turbo. We don’t need the creativity of the more advanced GPT-4, and with its low cost and increased generation speed, GPT-3.5 Turbo is a welcome addition to this application. I created two simple prompts to create a title and description. If I were to generate videos at scale, I would invest more time combining the title and description into one call to the API to save cost. The input for the LLM is my prompt, plus the topic of the meditation session; I also added the entire meditation script we got from GPT-4. All Large Language Models benefit from more context, and GPT-3.5 can use this script to create a comprehensive description. In this step, I also prompt the model to always end the description with the same line: “This content was created by Artificial Intelligence, and reviewed by humans.” Let’s talk about why that’s necessary.
Time For Some Human Intervention
I set out on this mission to remove any manual actions, but I’ve applied artificial intelligence in almost every step of the process to create content for humans to enjoy. LLMs are exceptionally talented at producing some unexpected or even scary results. So it’s time for a disclaimer: You are responsible for its output. Large Language Models are amazing, and will even seem like magic sometimes. Yet it doesn’t “know” anything; it’s just generating the most likely text, given your input as context. For this reason, it is a human’s job (that’s you, dear reader) to verify the output of the models you use. In Azure Durable Functions, you can build this step in as an activity that won’t be complete until you’ve sent the all-clear. But in my case, I upload the video to YouTube as private, and I listen to every single one before hitting that publish button. The benefit: I can now meditate every day.
In conclusion
Combining Large Language Models with text-to-speech and image generation can turn a single word into captivating audio or video content, I hope you will try to apply these applications of artificial intelligence yourself! While building this application, I would call a URL in my function with the topic of the meditation. While great for testing, I didn’t make this application with the idea of doing anything by hand. So, Who decides on these topics? Well, Artificial intelligence, of course.

Figure 3: Wait, it's all AI? Always has been.
Meditation: Body Scan Meditation for Deep Bodily Awareness
This article is part of XPRT. Magazine #15 Download here

Written by
Matthijs van der Veer
Matthijs is a consultant at Xebia, with a strong focus on Generative AI. He loves helping people achieve more in the cloud.




Contact