
Introduction
In the world of data engineering, we're constantly looking for ways to make our data more accessible and easier to work with. Three exciting technologies in this space are DuckDB, MotherDuck, and Unity Catalog.
- DuckDB is an in-process SQL OLAP database management system. It's designed to be fast, reliable, and easy to use. It's often called the "SQLite for analytics."
- MotherDuck is a serverless data warehouse based on DuckDB. It allows you to query data in the cloud and on your local machine as if it were in a single database.
- Unity Catalog is a unified governance solution for data and AI assets on the Databricks Lakehouse Platform. It provides centralized access control, auditing, lineage, and data discovery capabilities across Databricks workspaces.
This blog post will explore how to bridge these technologies, specifically focusing on reading data from a DuckLake (a data lake managed by MotherDuck/DuckDB) using Databricks Unity Catalog. We rely on the BYO (bring your own) bucket offering from Motherduck which enables users to supply their own bucket for data storage.
In this blog post, we will show how to read data from DuckLake using Unity Catalog.
Prerequisites
Prerequisites: An S3 bucket mounted on both Databricks and MotherDuck:
- For mounting your S3 bucket on Databricks, see this Databricks guide.
- For mounting your S3 bucket on MotherDuck, see this MotherDuck guide.

Prefer following updates via RRS?
Our custom feed includes only product, tech, and thought-leadership posts — no marketing or sales content.
Reading from DuckLake using Unity Catalog
First, we will create a new database with DuckLake as the data catalog.
-- Create a new database in ducklake
CREATE DATABASE ducklake_webinar_demo (
TYPE DUCKLAKE,
DATA_PATH 's3://motherduck-webinar-demo/ducklake_webinar_demo'
);
Next, we will generate some data for our newly created database using the TPC-H DuckDB extension:
USE memory;
CALL dbgen(sf = 0.1);
Next we store the generated lineitem data in the database:
USE ducklake_webinar_demo;
CREATE TABLE lineitem AS SELECT * FROM memory.lineitem
Since we are using S3 for the storage of our data, we can see the Parquet files stored on the bucket:
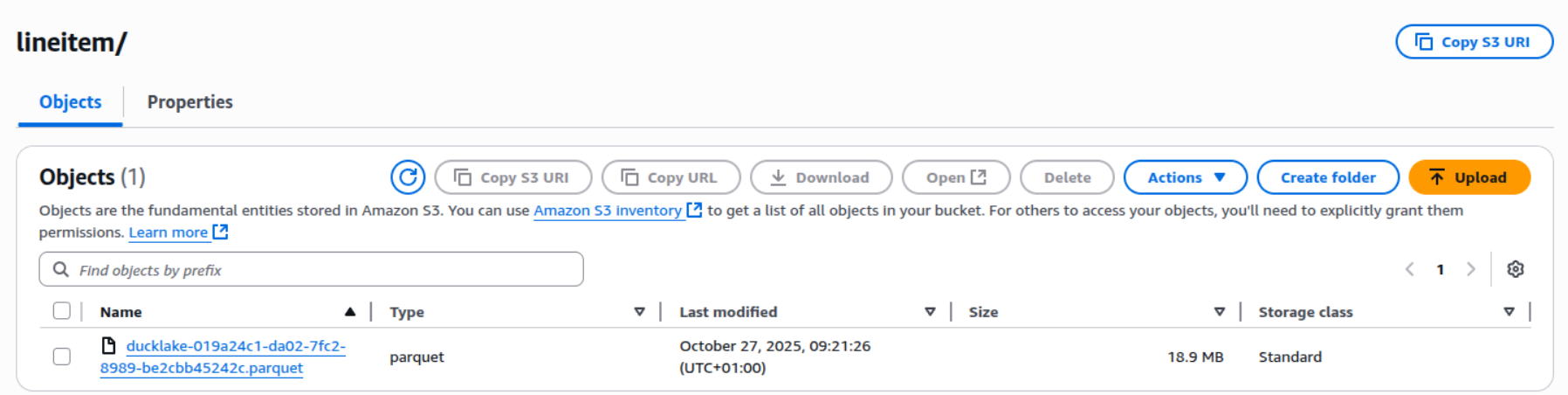
Since DuckLake just writes plain Parquet, we can mount this data as an external table in Unity Catalog by running the following command in our Databricks environment:
CREATE TABLE IF NOT EXISTS lineitem
USING PARQUET
LOCATION 's3://motherduck-webinar-demo/ducklake_webinar_demo/main/lineitem'
We are now able to read the data written by MotherDuck in Databricks using Unity Catalog:
Select count(*) from lineitem;
There is, however, a challenge with this method. DuckLake handles deletes by creating a new Parquet "delete file" containing the row indices to be removed, then registering this file in the metadata tables. This process creates a new snapshot, and the original data files are not immediately modified, allowing for time travel to past versions of the table. More info on the delete file can be found here.
When we run the following command:
-- Lets find some ids to delete
DELETE FROM ducklake_webinar_demo.main.lineitem where l_orderkey % 2 = 0;
We can see the delete file created in the s3 bucket:
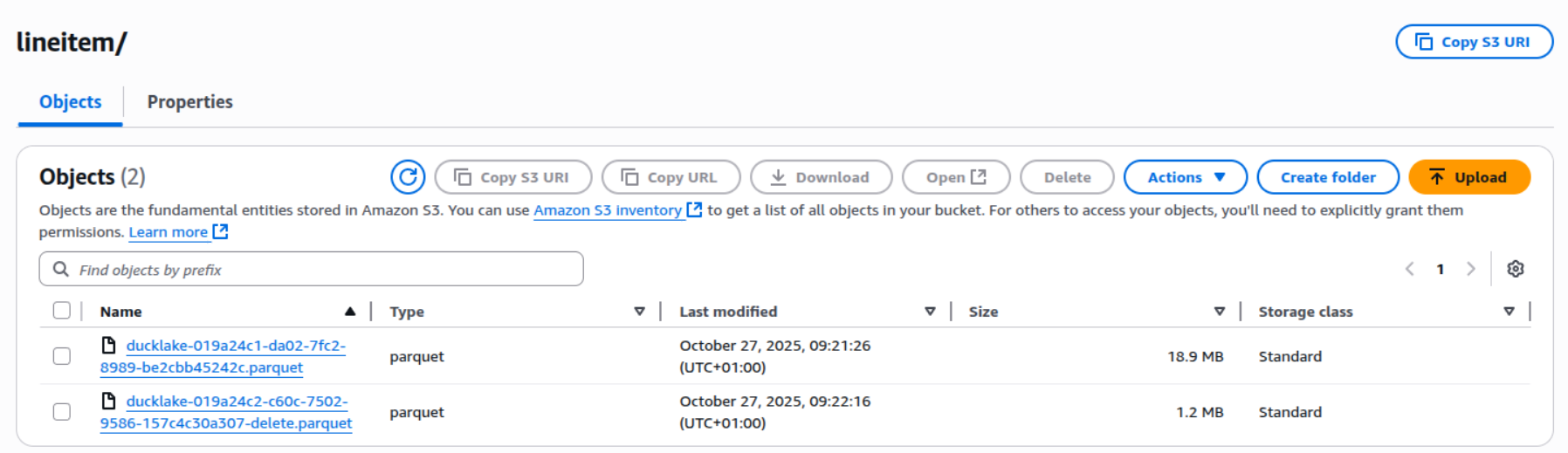
This, however, poses a challenge because Unity Catalog does not take the delete file into consideration when it reads the Parquet file, resulting in it not registering the deleted rows.
A quick workaround for this is to rewrite the data in DuckLake by running the following commands:
CALL ducklake_rewrite_data_files('ducklake_webinar_demo', delete_threshold=0.0);
CALL ducklake_expire_snapshots('ducklake_webinar_demo', older_than => now());
CALL ducklake_cleanup_old_files(
'ducklake_webinar_demo',
cleanup_all => true
);
These commands do the following:
- ducklake_rewrite_data_files - This rewrites your data such that DuckLake does not require processing all delete files to perform a read operation over the table.
- ducklake_expire_snapshots - DuckLake enables time travel by keeping track of snapshots. This command will expire all snapshots, making the underlying Parquet files ready for deletion.
- ducklake_cleanup_old_files - This cleans up any files that are not part of a snapshot or are orphaned.
If we now load the data, we can see that we have the correct amount. Moreover, the Parquet files have been rewritten on the S3 bucket:
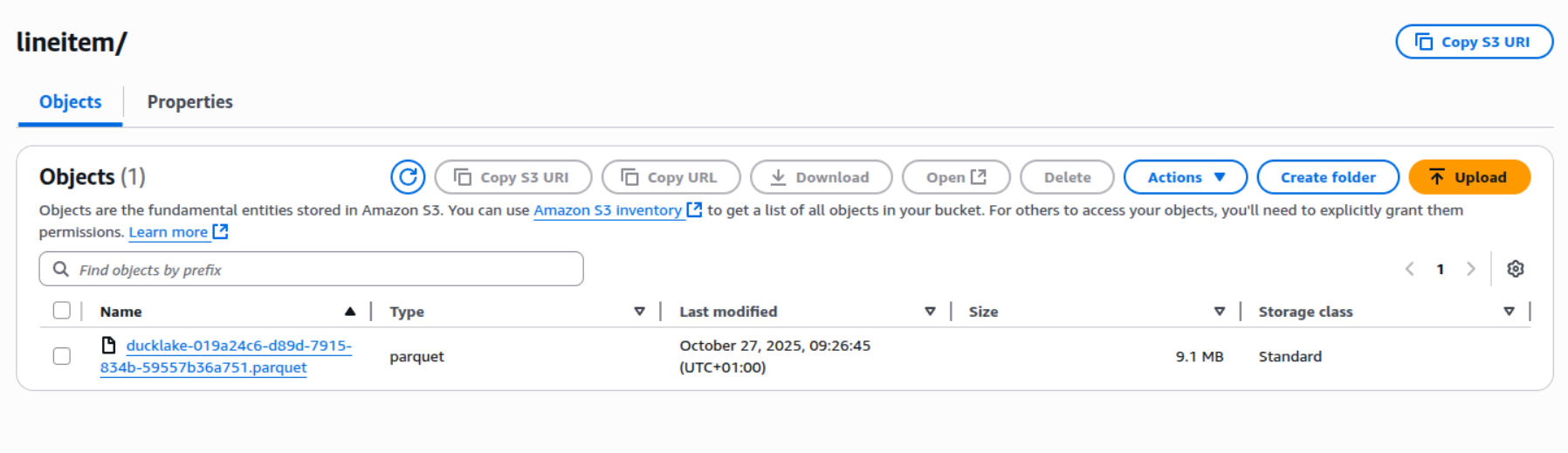
These methods could be added to a dbt post-hook macro so that Unity Catalog can read the tables. There are, however, downsides to this method. Using this method, we will lose all the time-travel functionality that DuckLake offers, and it adds approximately 15 seconds to your run time per dbt model (depending on the structure and size of your data).
If your goal is to just read data from DuckLake using Spark, then there is a better option available based on the DuckDB JDBC driver.
Written by
Diederik Greveling




Contact