Blog
More Effective Machine Learning Production with MLOps

Machine Learning is slowly starting to mature as a field, but many businesses are still facing tough upfront challenges. While there are a huge (and increasing) amount of new algorithms, neural network architectures and libraries, practical deployments are still in the toddler phase.
However, there’s plenty of new hope for businesses looking to deploy Machine Learning. Just as DevOps revolutionised how software is developed and delivered, I want to showcase a similar solution here: the aptly named MLOps.
The Current State of ML
Machine Learning is a very new technology – one that is already bringing benefits for many – but, like any technology, there’s a familiar development story…
The current state of Machine Learning projects reminds me of the early days in software development - around 10-15 years ago - where we started introducing proper development processes. Looking back, I feel embarrassed about how we delivered software projects those days. As a software development community, we’ve made huge improvements regarding how we productise our code, use a GIT repository, CI/CD pipelines, proper testing on many different levels (unit, integration, E2E, mutation …) etc. In short, there have been a lot of key achievements made already, but still more to go.
It’s also very exciting to work in Data Science these days, as I’m sure we can achieve great improvements and push our domain forward using MLOps.
What is MLOps?
MLOps, which means “Machine Learning Operations” is a development practice similar to DevOps, but built from the ground up for Machine Learning best practices. Just as DevOps looks to provide regular, shorter releases, so too does MLOps look to enhance every step of the ML development lifecycle.
In fact, many factors from DevOps directly apply here. Most importantly, a focus on Continuous Integration/Continuous Delivery is applied directly to model generation, while regular deployment, diagnostics and further training can also be done on a frequent process, rather than waiting for one large upload at much slower intervals.
MLOps & Delivering ML-based Value
Like any solution, Machine Learning (ML) is measured by its success and value.
Some companies are asking about the newest and fanciest things, such as automated model retraining. The typical initial reaction to such a request is to take a step back and start with questions such as „can you easily repeat what your data scientist did yesterday ?”.
We somehow naturally expect that, if we have code versioning, continuous integration etc in our software projects, it’s automatically available for our models. This is one of the biggest misconceptions: that all we do is “just” train a model:

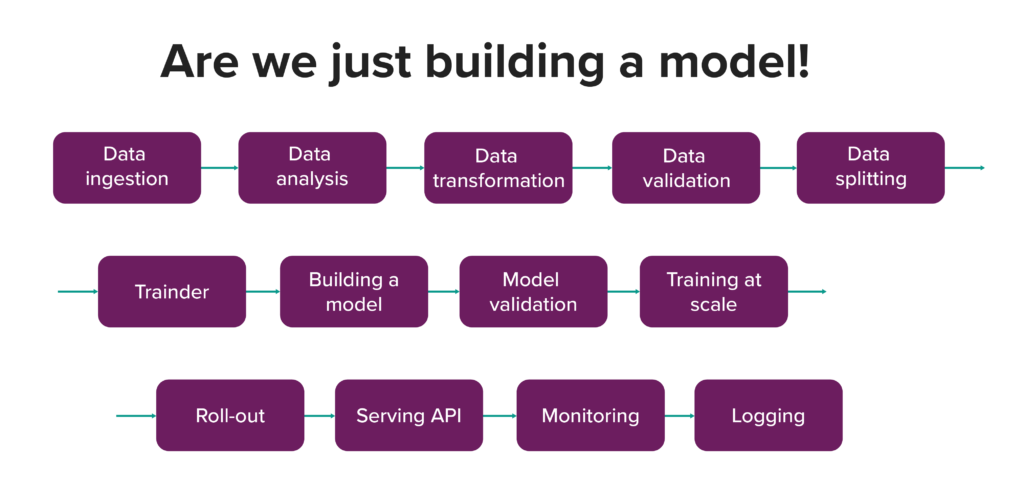
Expectations are one thing, but the reality is often different. A more popular real life scenario is talking to the CTO and hearing something along the lines of: “Hey, we hired a bunch of data scientist, they play all day with Jupyter notebooks on their local machines and, when it’s time to deploy it, we have no idea where the code is. Mostly, it’s not even checked in. They claim to do so much great stuff but we cannot get any business benefits out of it.”
If you are considering starting with MLOps I would first suggest to evaluating your level of maturity regarding both how you work on your models and how they are deployed to production environments.
Key Machine Learning Values
So, what do we want to achieve from Machine Learning? After all, this is the end goal that MLOps is striving to achieve more efficiently. For most businesses, we can determine values at three key levels or stages:
Repeatability - this means you have your work on the model automated enough that you can always repeat any experiment your data science team already performed.
Productisation - at this level, you should be able to automatically push the model to production, having automated not only the deployment, but also canary deployments, testing, fallbacks, monitoring etc…
Business Benefits - at this level, you should be able to measure the influence of each and every model version in temrs of business metrics. For example, when you deploy a new recommendation engine to a retail website, or to a small user group, you need to automatically see on the model repository that the conversion rate or sales figures were influenced by X% with this deployment.
We can find similar examples of all industrial corners:
- Does your manufacturing or production facility need to be optimised across numerous parameters? Automation can help manage large workloads that manual human activity can’t keep up with (and for the largest of operations across numerous plants, there’s Mesh Twin Learning)
- Is your financial company trying to stay on top of online fraud? Automation is important for learning about new challenges, updating to newer versions and staying ahead of the field. What’s more, you need to know if it worked!
- And so on. You get the idea…
In order to enable this, you also should consider both data management and the analysis of new datasets becoming available in the system. It’s good to be able to know if any new data is similar to what we already have, or they have different distribution, and if it could be worthwhile to re-train the model with it. [blog_post_contact_form ga_event_category="manufacturing_nordics" ga_event_label="blog-contact-form" header="Need help with Industry 4.0?" thank_you="Thank you! We'll be in touch!" button_text="send"]
Personas in the Process
One key challenge in the MLOps process comes from the many positions and hats involved in it. You need to be able to meet the needs of your Data Engineer, making sure that you can get, clean, version and maintain the datasets, which gets even more tricky with real-time event based systems. And that’s just the first person!
Next on the list is your Data Scientist, who sometimes is really more of a scientist than an engineer, to enable him or her to run experiments and test many hypotheses. Finally, you need someone to build the model into your product, making sure that your experiment results are also the same in the real world. This is where the ML Engineer comes in.
With this many people involved, the process needs to be as efficient and streamlined as possible, speaking of which…
Creating the MLOps Pipeline
There is a lot of existing tooling that can help with building an efficient MLOps pipeline. You can go the open source way, for example, and use tools such as Airflow, Kubeflow and Jenkins, paired with a few custom scripts of your own.
Likewise, all the major Cloud providers have their own set of DevOps tools, which can be extended by some open source components to build a full MLOps solution.
However, for this article, I want to showcase another option, which is to go with TensorFlow TFX: an end-to-end platform for deploying ML pipelines.
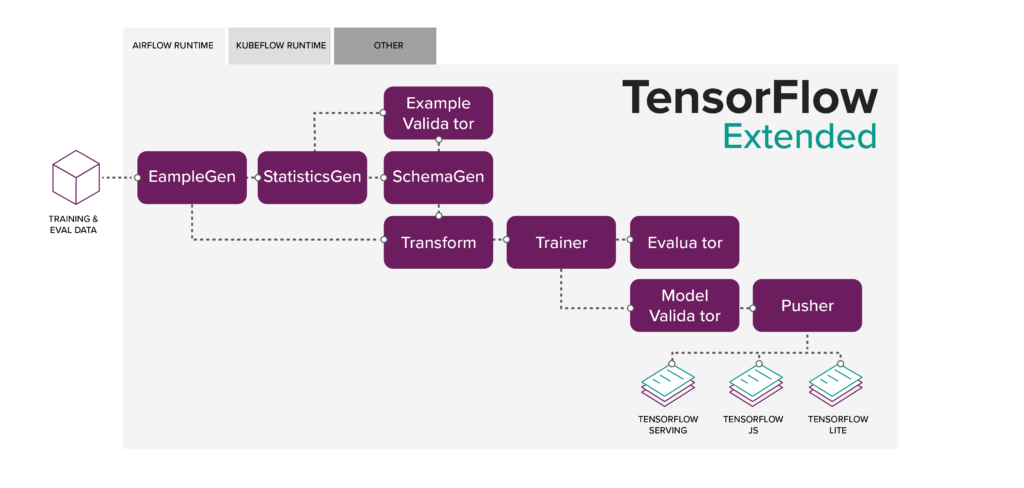
Its key strength is that, besides running on Google Cloud Platform (GCP) , you can use Apache Airflow or Kubeflow as runtime .
Another highly appreciated aspect here is the metadata store concept, which contains:
- Trained models (Models, Data & Evaluation metrics)
- Execution records (runtime configurations, as well as inputs + outputs)
- Lineage tracking across all executions (ie. To recurse back to all inputs of a specific artifact)
Also, on the picture above, you can see how every atomic operation is handled. You have a driver and publisher (if needed, they can be overwritten) which handle the fetching and storing of data in the metadata store, as well as an executor for writing the business logic of a certain step.
This enables the following use-cases:
- visualising the lineage of a specific model
- visualising a data specific model that was trained on a certain run (with sliced evaluation metrics, which you can see below)
- comparing multiple model runs
- comparing data statistics for different models
- carry-over states from models run some time ago
- reusing previously computed outputs.
My favourite is sliced evaluation metrics, where you can analyse how certain parts of the dataset are influencing your results.

Another one that we use a lot, especially in the early stages of a project, is the possibility to reuse previously computed outputs (as they are stored in the metadata store). With this approach, when you have a training job with multiple steps, typically taking several weeks in total, you don’t need to start over from scratch if anything fails.
Summary
So, where is MLOps most useful? If you are a single researcher working on your thesis or some small pet project, you don’t need to complicate your life with MLOps. If, however, you work with any kind of production system, I highly recommend you try it.
If you need any help in choosing a proper solution for you or you already decided for one and have some issues implementing it please contact us.
Business Perspective
Machine Learning doesn’t need to be a long development cycle. MLOps combines the best parts of DevOps and adapts it to the development, release and training of ML models to help gain immediate benefits and quicker releases for all important Machine Learning algorithms – all of which enables businesses to start implementing such advanced solutions faster than ever.
Written by
Xebia Author
Our Ideas
Explore More Blogs


From Spec to Code: Building Software with Spec Kit
This article walks through the full workflow, from installation to a working implementation, covering both greenfield projects and extending an...
Hidde de Smet, Emanuele Bartolesi


Contact