
Why
Consumer lag is the most important metric to monitor when working with event streams. However, it is not available as a default metric in Azure Insights. Want to have this metric available as part of your monitoring solution? You can set it up with some custom code. In this blog we show you how.
What
Consumer lag refers to the number of events that still need to be processed by the consumers of a stream. Consumer lag will be 0 most of the time, as every event is consumed immediately. However, there are a few events that can cause that number to rise. When a consumer runs into errors, like a functional issue caused by an event or a technical issue like network connectivity, it'll stop consuming events, increasing the consumer lag.
The lag will also increase if events are published faster than the consumer can process them. In that case, the problem will resolve itself when events are published at a lower rate, and the consumer catches up again.
You can trigger an alert when the consumer lag exceeds 0 for an extended period, like 10 minutes. What the best alert trigger configuration is for you depends on your situation. Before we continue to the solution, let's clarify some terms:
Definitions
- Consumer groups enable multiple consumers to subscribe to the same event stream. Typically, a consumer group consists of multiple instances of the same application, that can be used for high availability and horizontal scaling.
- Partitions enable events to be processed in parallel. All events within a partition have a fixed order. Events in different partitions can be received out of order because they are processed in parallel. A consuming application can have multiple instances that can each read from multiple partitions.
- Namespace is a collection of event hubs/topics that can be managed together.
- Checkpoints records the sequence number of the last consumed event. This value is used to ensure that, in the event of a restart, only the events that have not been consumed yet are resent. Typically, checkpoints are stored as a file in BlobStorage.
How
The Azure SDK can retrieve the sequence number of the last enqueued event of a partition. With the CheckpointStore you can retrieve the sequence number of the checkpoint. Since both are simple counters you can calculate the difference and publish this as a custom metric in azure insights. In order to make it a metric you can monitor, you will have to collect the metric periodically, let’s say, every minute.
There are two ways to collect the consumer lag metric:
- Using the consumer application provides you with the Event Hub credentials, namespace, and consumer group. However, if something goes wrong and the consuming application shuts down, you'll no longer see if consumer lag rises because this information is not collected anymore. Use a separate process for monitoring to prevent this from happening.
- Alternatively, alert the application failing its health check or the consumer lag metric being missing. The code examples below are in Typescript for conciseness. But the same approach can be used with the other Event Hub SDKs, like for C#, Java, Python, Go.
Collecting the consumer lag
// initialize checkpointStore and eventHubClient
const consumerGroup = 'my consumer group';
const checkpointStore = ...
const eventHubClient = ...
// Send the consumer lag every minute
setInterval(async () => {
try {
await measureConsumerLag(consumerGroup, eventHubClient, checkpointStore);
} catch (error) {
logger.error(error, 'The Event Hub Consumer Lag could not be sent to Application Insights');
}
}, 60000);
export async function measureConsumerLag(
consumerGroup: string,
eventHubClient: EventHubConsumerClient,
checkpointStore: BlobCheckpointStore
): Promise<void> {
const partitionIds = await eventHubClient.getPartitionIds();
// Should return either 0 or 1 checkpoint per partition
const checkpoints = await checkpointStore.listCheckpoints(
eventHubClient.fullyQualifiedNamespace,
eventHubClient.eventHubName,
consumerGroup
);
const checkpointSequenceNumberByPartitionId = Object.fromEntries(
checkpoints.map(({ partitionId, sequenceNumber }): [string, number] => [partitionId, sequenceNumber])
);
await Promise.all(
partitionIds.map(async partitionId => {
const lastKnownSequenceNumber = checkpointSequenceNumberByPartitionId[partitionId] ?? 0;
const { lastEnqueuedSequenceNumber } = await eventHubClient.getPartitionProperties(partitionId);
const consumerLageMetric = {
eventHubName: eventHubClient.eventHubName,
consumerGroup,
partitionId,
namespace: eventHubClient.fullyQualifiedNamespace.split('.')[0],
// The consumerLag calculation
consumerLag: lastEnqueuedSequenceNumber - lastKnownSequenceNumber,
};
await trackEventHubConsumerLag(consumerLageMetric);
})
);
}
Sending the custom metric
import { defaultClient as appInsightsClient } from 'applicationinsights';
export interface ConsumerLagMetric {
eventHubName: string;
consumerGroup: string;
partitionId: string;
namespace: string;
consumerLag: number;
}
export async function trackEventHubConsumerLag({
eventHubName,
namespace,
consumerGroup,
partitionId,
consumerLag,
}: ConsumerLagMetric): Promise<void> {
await trackMetric({
name: 'Event Hub Consumer Lag',
value: consumerLag,
// Format property keys with a space, for readability in the Application Insights metrics dashboard
properties: {
'Event Hub': eventHubName,
'Partition Id': partitionId,
'Consumer Group': consumerGroup,
Namespace: namespace,
},
});
}
Viewing the custom metric
In the Application Insights console, you’ll find your custom metric, split the chart by "Consumer Group", which represents an application. Depending on the zoom level the chart will show multiple measurements per datapoint. Usethe aggregation "Max" to get the best line.
This chart shows 3 microservices where 1 service is stuck processing an event. Whenever new events are published the consumer lag will increase. The events are published in bursts, so the consumer lag will increase in distinct increments.
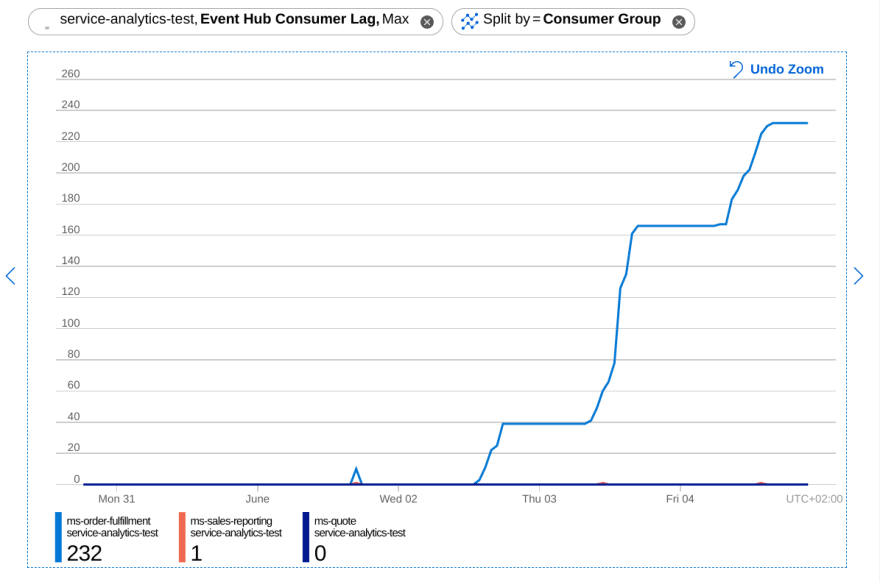
When an issue is solved, the consumer lag will drop quickly.
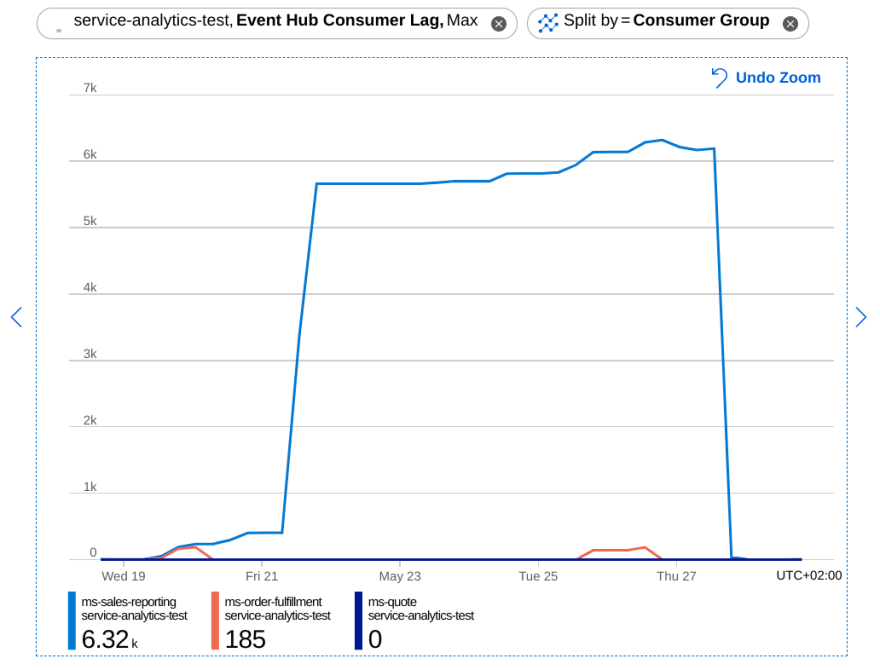
Conclusion
Consumer lag will quickly show any functional or technical issue with your event stream. By using the code examples from this blogpost, you can avoid having to dive into the SDKs yourself. Of course, you can adjust the metric collection to send the metric to the logs or to another metrics system like prometheus, datadog, or open telemetry.
After collecting the metric, the next step is to create metric based alerts to ensure you detect the issues before your customer does!
Written by
Ruben Oostinga
Our Ideas
Explore More Blogs




Contact