Blog
How to update your repository from a gitlab pipeline

Did you ever ran into the scenario where you wanted to update files in a repository from your pipeline? I did, a couple of times actually!
Updating documentation
In one of my previous blogs I wrote on how you can manage diagrams as code. Well as a human you sometimes forget to update images that you might be using in your README. So, updating these images during the CI process will help you with that.
Building containers
There are several scenarios where you might want to do this. For example, you are building a container and you want to deploy this in your environment. The approaches that I often is that you tag the container as latest and trigger a redeployment.
The problem with this approach is that you might already have a cached container on your host. With the result that you deploy the previous version. And what if you need to roll back to the previous version, for whatever reason? Or you want to know what version was running at a specific moment?
You can solve this by pointing to the actual digest of the container. This will always deploy the given version, or it will rollback. And if you need to do a manual rollback? You can revert the digest to the previous value. And as a bonus you can use your git history as an audit log.
If you want to know how you can update your CloudFormation templates. We created a tool called cru that can help you with that!
Creating a commit from CI on GitLab.
To get this to work, you do need to do some configuration. You will need to generate a SSH Key pair:
ssh-keygen -t ed25519 -C "<comment>"
You can add the public key in your repository under Settings and then Repository. In the Deploy keys section you can add your public key. Please make sure you grant write permissions to this key.
Under Settings and then CI/CD you will have the section Variables. Here you will need to create a File type variable called DEPLOY_SSH_KEY as value use the private key.
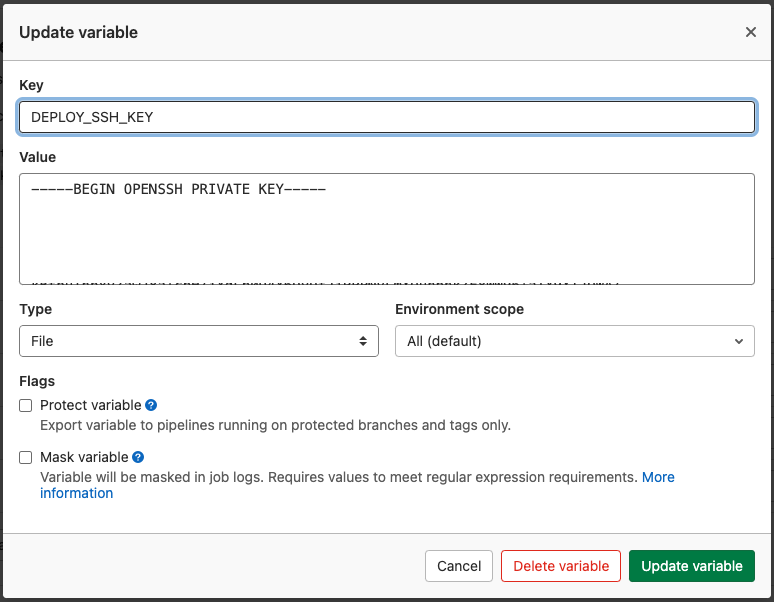
The private key will be available on the runner as a file. The location of the file is available as the DEPLOY_SSH_KEY environment variable.
Before you can commit you first need to:
- Configure the SSH client.
- Configure the git user.
- Configure the git remote.
- Commit and push the changes if there are any
To make it a bit easier I placed all those actions in the following bash script:
#!/usr/bin/env bash
failed () { echo "Failed:" >&2 "$@" && exit 1; }
GIT_USER=$1
GIT_EMAIL=$2
GIT_COMMIT_MESSAGE=$3
[[ -z "${CI_SERVER_HOST}" ]] && failed "The environment variable CI_SERVER_HOST is not set, this is needed to configure git and ssh to be enable to write back to the repository."
[[ -z "${CI_COMMIT_REF_NAME}" ]] && failed "The environment variable CI_COMMIT_REF_NAME is not set, this is needed to configure git and ssh to be enable to write back to the repository."
[[ -z "${DEPLOY_SSH_KEY}" ]] && failed "The environment variable DEPLOY_SSH_KEY is not set, this is needed to configure git to be enable to write back to the repository."
[[ ! -f "${DEPLOY_SSH_KEY}" ]] && failed "The ${DEPLOY_SSH_KEY} is not available on the filesystem, this is needed to configure git to be enable to write back to the repository."
[[ -z "${GIT_USER}" ]] && failed "Please use: ./commit-changes.sh '<USER NAME>' '<EMAIL>' '<COMMIT MESSAGE>'"
[[ -z "${GIT_EMAIL}" ]] && failed "Please use: ./commit-changes.sh '<USER NAME>' '<EMAIL>' '<COMMIT MESSAGE>'"
[[ -z "${GIT_COMMIT_MESSAGE}" ]] && failed "Please use: ./commit-changes.sh '<USER NAME>' '<EMAIL>' '<COMMIT MESSAGE>'"
run_function () {
GREEN='�33[1;32m'
RED='�33[1;31m'
NC='�33[0m' # No Color
echo -n "Running $1 "
ERROR=$( $1 2>&1 )
[ $? -eq 0 ] && echo -e "[ ${GREEN}DONE${NC} ]" || (echo -e "[ ${RED}FAILED${NC} ]" && failed "Unexpected error occurred: ${ERROR}")
}
configure_git_client() {
git config user.name "${GIT_USER}"
git config user.email "${GIT_EMAIL}"
}
cleanup_ssh_client() {
rm -rf ~/.ssh
mkdir ~/.ssh
}
configure_ssh_client() {
local KNOWN_HOSTS=~/.ssh/known_hosts
local CONFIG_FILE=~/.ssh/config
ssh-keyscan $CI_SERVER_HOST > $KNOWN_HOSTS
chmod 0644 $KNOWN_HOSTS
echo "Host $CI_SERVER_HOST" > $CONFIG_FILE
echo " IdentityFile $DEPLOY_SSH_KEY" >> $CONFIG_FILE
chmod 0600 "$DEPLOY_SSH_KEY"
}
configure_git_remote () {
git remote remove update 2>/dev/null || echo "update remote was not present yet"
git remote add update git@$CI_SERVER_HOST:$CI_PROJECT_PATH.git
}
commit_and_push_changes () {
git fetch update
git branch -D $CI_COMMIT_REF_NAME || echo "branch does not exist"
git switch -c $CI_COMMIT_REF_NAME update/$CI_COMMIT_REF_NAME
git diff --quiet && git diff --staged --quiet || (git commit -am "${GIT_COMMIT_MESSAGE}" && git push --set-upstream update $CI_COMMIT_REF_NAME)
}
run_function "configure_git_client"
run_function "cleanup_ssh_client"
run_function "configure_ssh_client"
run_function "configure_git_remote"
run_function "commit_and_push_changes"
You can use it as followed:
./commit-changes.sh "GitLag CI" "noreply@acme.com" "chore: my commit message"
Conclusion
Committing from the a GitLab pipeline works the same as you would from your own machine. The difference is that you need to configure your runners everytime and you need to grant the access to do so.
Photo by Jill Burrow
Written by

Joris Conijn
Joris is the AWS Practise CTO of the Xebia Cloud service line and has been working with the AWS cloud since 2009 and focussing on building event-driven architectures. While working with the cloud from (almost) the start, he has seen most of the services being launched. Joris strongly believes in automation and infrastructure as code and is open to learning new things and experimenting with them because that is the way to learn and grow.
Our Ideas
Explore More Blogs




Contact