Blog
How to make your web application more secure by using Static Application Security Testing (PART 1 of 5 in Application Security Testing series)

During this blog series we are going to look at different types of Application Security Testing (AST), Software Composition Analysis (SCA) and secret scanning. They are used to identify security vulnerabilities in applications. You can use them to test applications manually and/or via automation by integrating them in a CI/CD pipeline. I will start with a brief explanation about how they work and what their advantages and disadvantages are. After the explanation we will get our hands dirty and try out some tools manually. In the last blog of this series I will show you how you can use the tools in a CI/CD pipeline.
A small disclaimer before we go any further. If you expect that running these kind of tools will solve all your security problems, you will be disappointed. To use these tools effectively it is very important to establish a culture where everybody feels responsible for security. This also entails that DevOps teams and security teams have to work together to get the best results.
To demonstrate how the Application Security Testing tools work, I created a small and simple vulnerable Java Spring Boot Application. The source code for this application can be found here: vulnerable app.
In this first blog we will explore a type of Application Security Testing called Static Application Security Testing (SAST). In upcoming blog posts we will look at Dynamic Application Security Testing (DAST), Interactive Application Security Testing (IAST), Software Composition Analysis (SCA), secret scanning and how we can use these types of testing tools in a CI/CD pipeline.
[caption id="attachment_58560" align="alignnone" width="1024"]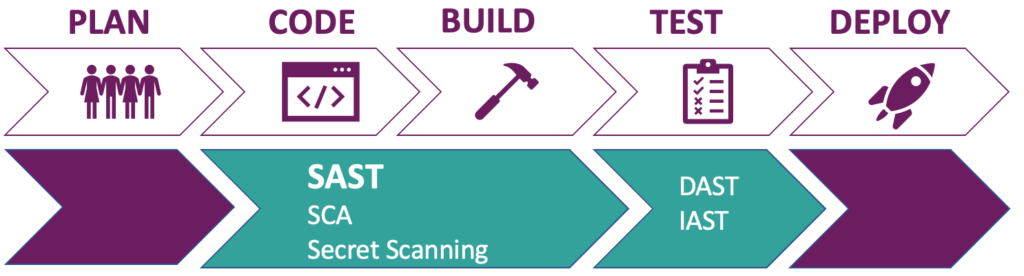 Figure 1: SAST and other forms of AST during CI/CD stages[/caption]
Figure 1: SAST and other forms of AST during CI/CD stages[/caption]
First a bit of theory about Static Application Security Testing. From now on I will refer to Static Application Security Testing as SAST. SAST tools can scan for security vulnerabilities without executing the code. Depending on the tool it can either analyze source code, byte code or binaries. SAST scanning can take place during the code phase for example via your local Command Line Interface (CLI) and/or Integrated Development Environment (IDE). And in the Continuous Integration (CI) environment during the build stage.
From a high level perspective SAST works like the process displayed by figure 2. Models are extracted from the source code, byte code or binaries. These models can be intermediate representations such as a symbol table, abstract syntax tree, control flow graph or call graph. Next they are analyzed by various types of analysis methods such as data-flow analysis, pattern matching and control flow analysis. During the analysis phase rules are applied to determine if a security vulnerability is present. The analysis phase results in a report with the found security vulnerabilities.
[caption id="attachment_58561" align="alignnone" width="1016"]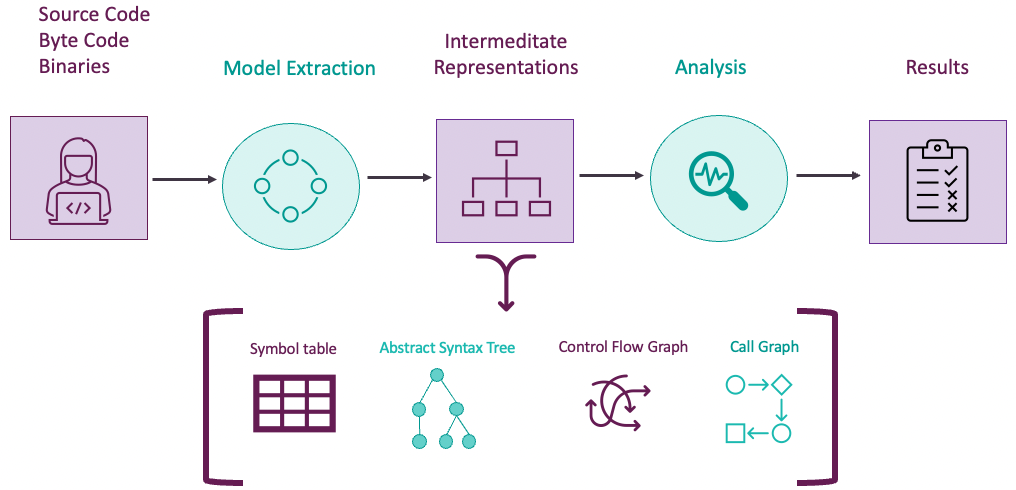 Figure 2: High level overview of how SAST works[/caption]
Figure 2: High level overview of how SAST works[/caption]
What all SAST tools have in common is that they use rules to find vulnerabilities. These rules are language specific. So, it is important that the tool you choose, has good support for the programming languages that are being used. SAST has some advantages and disadvantages:
Advantages
- Fast
- Find vulnerabilities early in the software development lifecycle (even in IDE)
- High code coverage
- Gives the location of the detected vulnerable code
- Can find syntax violations, dangerous patterns, programming errors and code standard violations
Disadvantages
- High chance of generating a lot of false positives
- High quality rules for specific languages necessary to avoid false negatives
- Bad at finding logical vulnerabilities because of missing context
- Cannot find runtime vulnerabilities
To get the best results it is very important to finetune the SAST tool of your choice. Otherwise, there is a high chance that you will be flooded with findings. Do not start with dozens of different rules on a large code base but start with a few rules that cover the highest risk in your context. The security department will be able to help with this!
Now that’s out of the way, let’s get practical and use an open-source SAST tool called Semgrep to scan our vulnerable Java application. Semgrep analyses source code and supports a wide range of programming languages. If you are interested in how it works checkout: Semgrep Engine Overview.
A big advantage of Semgrep is, that it is very easy to create your own rules. Semgrep also has a large community that helps creating rules. For simplicity I will use the CLI version of Semgrep. You can download Semgrep for free here: Semgrep.
As mentioned before SAST tools work with language specific rules. The same applies to Semgrep. Because this is a demonstration with a small application, I will ignore my own advice and use all the rules Semgrep thinks are relevant by using auto config mode. Semgrep will analyse the code and identify the used programming languages. Once Semgrep is done with the identification, it will download the corresponding rules from the Semgrep registery and scan the application. The registry contains all official Semgrep rules. You can find it here: Semgrep registry. To run Semgrep in auto config mode use the following command on our vulnerable app source code in the Command Line Interface:
semgrep --config auto <path to source code of our vulnerable app>
If you want to run specific rules, replace the “auto” part by the remote rule set or a local rule (yaml file). For more information about this, see Semgrep running rules.
The results of the auto config scan of our vulnerable application are displayed in figure 3.
[caption id="attachment_58562" align="alignnone" width="802"] Figure 3: Semgrep results with automatic config applied[/caption]
Figure 3: Semgrep results with automatic config applied[/caption]
Semgrep found 3 security issues. All issues are located in the PostController.java. There seems to be a problem with the way SQL is handled in this controller. When we resolve the line numbers 24, 27 and 45, we discover that Semgrep complains about the following two operations in the PostController: /posts and /post/{id}. Let’s review the findings and look at the code.
The code of the /posts operation is displayed here:
[caption id="attachment_58563" align="alignnone" width="870"]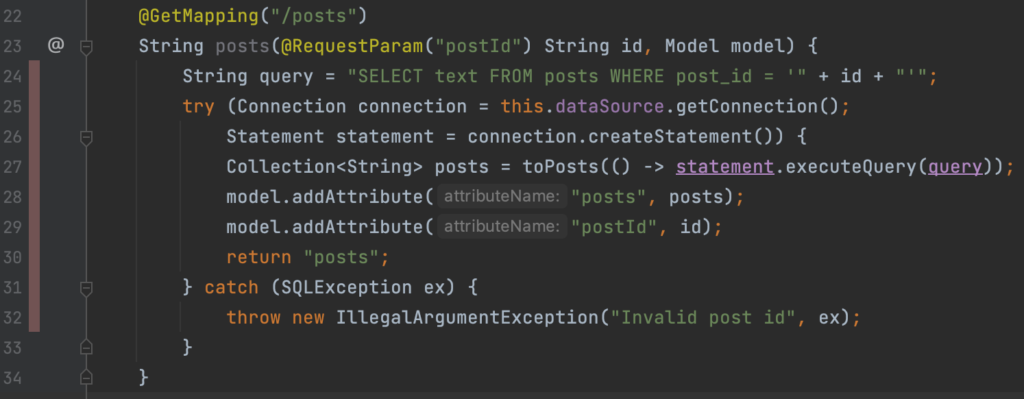 Figure 4: /posts GET operation in PostController.java[/caption]
Figure 4: /posts GET operation in PostController.java[/caption]
Semgrep tells us that it detected a formatted ‘String’ in a SQL statement and that it could lead to SQL injection. Which in this case is certainly true. This security vulnerability allows a remote attacker to compromise the database that is used by this application.
The problem arises because of the way the SQL query is build and executed. At line 24 a SQL query is built by concatenating unvalidated user input of type ‘String’ (the id) into a ‘String’ called query. This gives the user control over the format of the ‘String’ and thus the SQL query. This ‘String’ called query is than executed by statement.executeQuery at line 27. As the documentation states, Statement is only meant to be used for simple SQL queries with no parameters.
This is a classic example of SQL Injection. You can verify this by running the application and exploit the SQL injection at the /posts?postId endpoint. Navigate to the source code in your Command Line Interface and execute the following command: java -jar vulnapp-0.0.1-SNAPSHOT.jar
Now browse to "http://localhost:8080/posts?postId=1' union select password from users --". The password of the first user in the users table is displayed on the page next to the results of all posts related to the id of 1 as shown in figure 4.
[caption id="attachment_58565" align="alignnone" width="722"]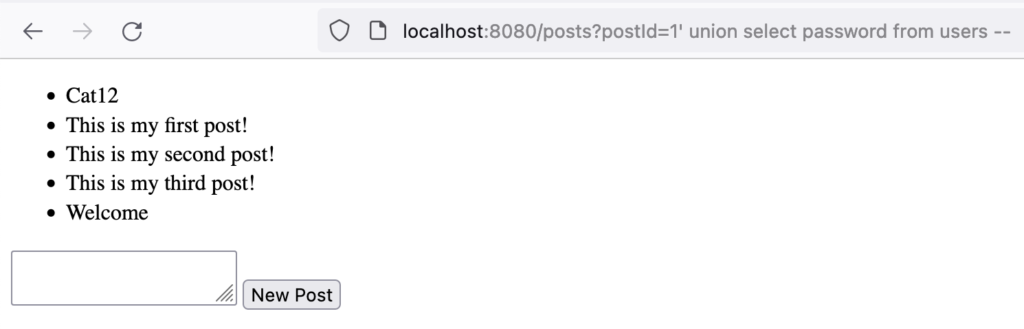 Figure 5: SQL Injection via postId query parameter in PostController.java[/caption]
Figure 5: SQL Injection via postId query parameter in PostController.java[/caption]
Due to Semgrep we are aware of a SQL injection vulnerability in our code. Semgrep even mentions how we can remediate this issue. We should use Prepared Statements instead of Statement. I am not going into detail about how this works, but you can look at the implementation of a prepared statement in the addPost method on line 58-67 in the PostController.java and for documentation click here. As a bonus a prepared statement also reduces the execution time and thus improves the performance of our application! This covers two of the three findings, the finding of line 24 and 27.
The last finding Semgrep found was the same kind of issue as on line 24. It is located at the /post/{id} operation at line 45 and the code is displayed in figure 6. Once again, we are concatenating user input into a ‘String’ called query and execute this unsafely, right?
[caption id="attachment_58564" align="alignnone" width="751"]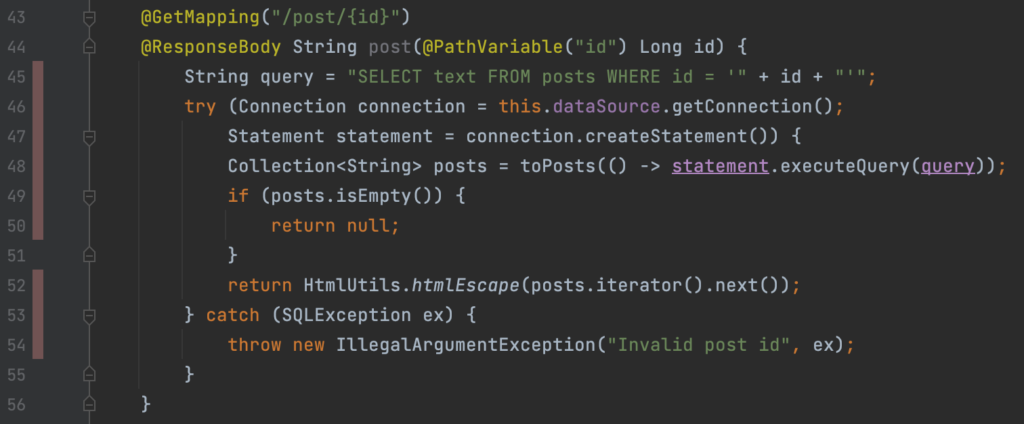 Figure 6: /posts/{id} operation in PostController.java[/caption]
Figure 6: /posts/{id} operation in PostController.java[/caption]
Wrong, this query is not executed at all. Like they say: “The devil is in the details”. On line 44 we explicitly ask for an id of type ‘Long’. A payload like “http://localhost:8080/post/1' union select h2version() --“ will be rejected by the application because “1' union select h2version() --“ does not resolve to type ‘Long’. Since we cannot inject strings, but only numbers. It is not possible to exploit this code. A small side note, if it was possible to exploit, we would have to URL encode the payload “1' union select h2version() –“ and sent it via a web proxy like Burp. Because the browser automatically URL decodes the payload, it will result in a faulty URL.
So now the question rises, is this a false positive? I guess it depends on your definition of false positive. Concatenating user input into a SQL query is most certainly a recipe for disaster and should be avoided. If somebody changes the type ‘Long’ into ‘String’, the application will be vulnerable to SQL injection. Eventhough there is currently no vulnerability to exploit, I would still advise to use a prepared statement and at the very least add a comment about the importance of type ‘Long’. So, in my opinion this is not a false positive. But I would give the fix for this finding a lower priority than the other SQL injection.
Like I mentioned before you can also use Semgrep in your CI pipeline. In the last blog of this series I will show you how. If you can’t wait, checkout the documentation at Semgrep in CI. Also, Semgrep is not the only SAST tool out there. For a comprehensive list of tools checkout AppSecMap.
This concludes the blog about SAST. Don’t miss the next one, where we will use Dynamic Application Security Testing (DAST) to look if we missed any vulnerabilities in the vulnerable app.
Written by
Maarten Plat
Our Ideas
Explore More Blogs




Contact