Blog
How to build a maintainable and highly available Azure Landing Zone

This is how we design, build, deploy, and maintain a Multi-Region Azure Landing Zone. We do this while delivering the Landing Zone like a Platform as a Product. In this article, you will find some tips and tricks to make the setup of your landing zone a bit easier.
What is an Azure Landing Zone?
An Azure Landing Zone is a pre-configured environment within Microsoft Azure designed to provide a secure and scalable foundation for your cloud workloads. Its architecture is modular and scalable, allowing you to apply configurations and controls consistently across your resources. It uses subscriptions to isolate and scale application and platform resources (What is an Azure landing zone?).
Every Landing Zone we build is based on the Cloud Adoption Framework (CAF). Microsoft created the cloud adoption framework to bring cloud adoption for Azure customers. It helps to achieve the best business outcome for cloud adoption. The CAF is a set of best practices for setting up Azure Infrastructure. It follows key design principles across eight design areas to enable application migration, modernization, and innovation at scale.
There are two main types of landing zones:
- Platform Landing Zones: These provide shared services (like identity, connectivity, and management) to applications in workload landing zones. Central teams manage them to improve operational efficiency. The platform Landing Zone is called a Hub
- Workload Landing Zones: These are environments deployed for the workloads. The workload landing zone is called a spoke.
Azure Resource Structure
Azure provides four levels of management: management groups, subscriptions, resource groups, and resources. The following diagram shows the relationship between these levels.
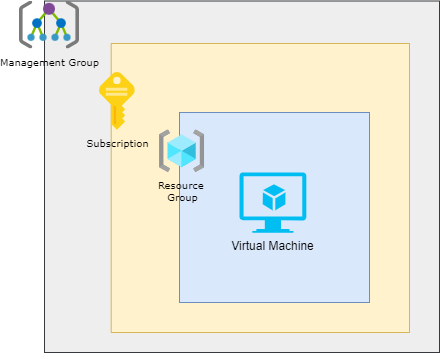
Management groups help you manage access, policy, and compliance for multiple subscriptions. All subscriptions in a management group automatically inherit these settings applied to the management group.
Subscriptions logically associate user accounts with the resources. Organizations can use management groups, subscriptions, and resource groups to manage costs and the resources users, teams, and projects create. Each subscription has limits or quotas on the number of resources that can be created and used.
Resource groups are logical containers in which you can deploy and manage Azure resources such as virtual machines, web apps, databases, and storage accounts.
Resources are instances of services that you can create in a resource group, such as virtual machines, storage, and SQL databases.
Landing Zone Design Area's
We have defined nine core design areas when designing, building, and maintaining an Azure Landing Zone.
- Platform Landing Zone / Hub Design
- Infrastructure as Code
- Zero Trust Architecture
- Multi-Region
- Monitoring
- Alerting
- Networking
- Policies and Guardrails
- Architectural Decisions Records (ADR)
Platform Landing Zone Design
The Platform Landing Zones or Hub consists of three parts (identity, connectivity, and management) and provides shared services for all application workloads. Most of the hub resources are deployed in every region to ensure that if one region fails, it will not affect the whole landing zone.
The management part of the Hub contains all Azure resources for managing the Azure Landing Zone. For example, there are central log analytics workspaces for all central log metrics and (audit) or resources. The management part also contains a central automation account.
The connectivity part of the hub contains all Azure resources needed for connectivity. Here is where we find the Virtual WAN and all the Virtual Hubs, as well as the firewalls connected to those hubs and, of course, the express route circuits and Peer to Site and Site to Site Gateways. The DNS private zones are also deployed in the connectivity part. They are the most crucial part of the Landing Zone and make the traffic secure and operational.
The identity part is where your Entra ID or Domain Controllers are located.

Infrastructure As Code
Infrastructure as Code or IaC is one of the core principles of a Landing Zone. We deploy every Azure resource using infrastructure as code. We do this for the following reasons:
Resource Consistency:
Imagine deploying fifteen firewall rules across two regions, West Europe (WE) and North Europe (NE). Manually applying these rules increases the risk of human error, potentially leading to inconsistent firewall configurations between the regions. Using Infrastructure as Code (IaC) ensures that the rules are consistently deployed across both regions.
Scalability or ease of deployment:
Consider deploying five virtual machines. Which approach is more scalable and manageable, manually setting up each VM or using Infrastructure as Code (IaC) to deploy all five? We will always choose the latter. With IaC, you can define the VM once and deploy it multiple times. By using IaC, you ensure each instance is identical, and you reduce the risk of errors.
Version Control:
We place the IaC configuration in a Version Control system like GIT. We do this so we can keep track of changes that are being made and also because we want to be able to review each other's work, especially when we are deploying or changing something in production. Version control also allows you to test changes on a separate environment like Sandbox before applying them to production. We achieve all these benefits by combining Version Control and IaC.
Terraform
We build almost every Azure Landing Zone using Terraform as the IaC framework. We won’t go into detail why, but these are the main reasons:
- Easy to understand
- Can automate beyond cloud resources
- Findable talent in the market
However, it is important to note that we use Terraform in a very opinionated way. For example, we split Terraform code into Modules, Templates, and Solutions. This opinionated approach ensures that each piece of the infrastructure is modular and reusable. By splitting Terraform into Modules, Templates, and Solutions, we maintain a clean separation of concerns, improve scalability, and streamline upgrades.
Modules:
Modules are predefined, opinionated resource definitions. An example could be a Virtual Machine (VM). However, not every resource definition needs to be a module. If your module doesn’t provide meaningful abstraction or opinionation, it shouldn’t exist. Avoid creating thin wrappers, as they add unnecessary complexity. Additionally, modules should not consume other modules, known as nested modules, because keeping the module structure flat simplifies code management and reduces the complexity of making changes.
What is a thin wrapper in Terraform? A thin wrapper is a module that adds little to no value. It allows you to pass all settings as variables without adding any internal logic or abstraction. Essentially, it only lightly wraps a resource definition, which is why it’s called a “thin wrapper.”
Every module is a separate repository and has an example. We use this example to test the module or like a quickstart for those looking to consume it. Whenever we create or update a module, our pipeline releases a new version. When consuming modules in templates or solutions, a version number is supplied. This number corresponds to one of the release modules. This allows us to manage and control when and how we upgrade the modules we use. More details on this will be covered in the Layered deployment section.
Templates:
Templates are a combination of modules and resource definitions. They represent frequently used deployment patterns. An example of this is a Virtual Machine with backup agents, and more if needed. Templates are like modules; they should not consume templates again, so making code changes stays simple.
Templates are just like modules placed inside separate repositories and versioned when created or modified.
Solutions:
Solutions represent deployable Azure Resources for a specific project.
They do this by consuming either modules or templates or calling resource definitions directly.
Combining these three groups will create a structure like the image below. You can see that modules consume resource definitions. The template can consume modules and resource definitions. And lastly, solutions can consist of resource definitions, modules, and templates.

Terraform State
Terraform uses the state file (terraform.tfstate) to keep track of the resources it manages. It acts as a source of truth for the infrastructure, storing information about the current state of the managed infrastructure. The state file ensures that Terraform has an accurate and consistent view of the infrastructure, essential for making correct updates and changes. The state file helps Terraform understand resource dependencies, ensuring that resources are created, updated, or destroyed in the correct order. Every deployment Terraform locks the state file, allowing only the planned changed to be applied and preventing two deployments at the same time. The state file is stored remotely in an Azure Storage Account; this way, the state file can be used by all the team members, enabling collaborative workflows.
However, the state file can contain sensitive information (e.g., resource IDs, secrets). Proper security measures, like encryption and limited access to the storage account, must be taken to protect it.
{
backend "azurerm" {
container_name = "tfstate"
key = "vm.terraform.tfstate"
resource_group_name = "rg-state-prod-we-001"
storage_account_name = "mystorageaccount"
subscription_id = "12345678-aa99-bb88-55cc-098765432123"
}
required_version = "~> 1.1, <= 1.8.1"
required_providers {
azurerm = {
source = "hashicorp/azurerm"
version = "3.92.0"
}
}
}Zero Trust Architecture
This principle advocates a security approach where services within the cloud don't automatically trust users or other services, regardless of their network or location. Instead, it emphasizes continuous verification and authentication, granting access on a need-to-know basis. Organizations implementing Zero Trust Architecture fortify their security posture, effectively mitigating unauthorized access and data breach risks. Key aspects of this principle include:
Continuous Verification:
The Zero Trust Architecture implemented in the Landing Zone ensures that every access request is continuously verified, regardless of the user's location or network. This involves multiple authentication and authorization layers, including user identity verification, device health checks, and contextual information such as location and behavior patterns.
Least Privilege Access:
Access to resources within the Landing Zone follows the principle of least privilege. Users are granted the minimum necessary privileges to perform their assigned tasks, and access rights are continuously evaluated and adjusted based on changing requirements or roles. This minimizes the attack surface and mitigates the potential impact of compromised accounts.
Micro-Segmentation:
The Landing Zone implements micro-segmentation to create security boundaries within the environment. By dividing the network into smaller segments, each with access controls, traffic can be effectively controlled and isolated. This approach limits lateral movement in the event of a security breach, reducing the impact on the overall system.
Management groups
Several default management groups are deployed for both types of the landing zone. The Platform landing zone is available under the "Azure Platform Services" management group, and each of the three parts of the landing zone has its management group.
A management group, "Landing Zone," is created for the workload landing zone. Below these groups, a management group per geographical region, such as "EMEA", is deployed. A management group per Azure region is deployed to provide maximum flexibility, like in West Europe. If needed, you can distinguish between production and nonproduction per Azure Region.
Subscriptions
Each part of the landing zone has its subscription. This goes for the three parts of the platform landing zone as well as the workload landing zone. Subscriptions are not shared between workloads, in line with the zero trust principles. With a landing zone in multiple regions each region will get its own subscription to host the workload. This segmentation also helps in case of regional disaster. Only the affected region will be unavailable, not the entire landing zone.
Of course there are also global resources like the Virtual WAN. Global resource will be deployed only once. These resources still require a subscription and a resource group. To deploy, simply select the subscription of your choice to deploy these resources.
Multi-region
When setting up a landing zone, it is essential to consider the number of regions needed. Do you have an application that requires 24x7 uptime? Do you have users around the globe? Are there special requirements for data storage? Are there complaint regulations? Answering these questions will give you more insight into the regions you need.
Next to the number of regions, it is also important to verify the resources you want to use. Not every Azure Region contains the same resources, so select a region where the needed resources are available. And last but not least, think about the capacity you need. A popular region is, for example, West Europe; it could happen that because of the high demand, capacity runs low, so you can maybe select a less popular region that also meets your needs.
Monitoring
Monitoring is an essential part of both landing zones. Without it, you cannot see what is happening in your landscape. All resources we deploy will also get diagnostic settings. For the workload landing zone, each workload gets its own log analytics workspace, which can be used to monitor the workload closely. Remember, we use isolation in the landing zone, so a shared log analytics workspace for multiple workloads will cause some issues with sharing data.
However, every region has a log analytics workspace in the platform landing zone. These log analytics workspaces are connected to Sentinel, the SIEM tool in Azure that detects threats and suspicious activity. To ensure we can also use Sentinel for all the workloads, all the log analysis workspaces for the applications are connected to the central ones. This allows Sentinel to detect activity throughout the whole landing zone. You can read more about Sentinel here: What is Microsoft Sentinel?
Alerting
Alerts are essential to monitoring; they actively trigger you when something happens. Creating alerts can be a lot of work. The question "What are we going to fire an alert on?" is common. You can use the Azure Monitor Baseline Alerts (AMBA) to kickstart implementing alerts in the landing zone. This GitHub repository contains a lot of policies that deploy alerts for a lot of resources in Azure. You can find it here: Azure Monitor Baseline Alerts.
The AMBA policies will trigger when a new resource is deployed, and alerts are automatically created. For example, for every express route circuit, you will get alerts to monitor the drop-off of packages. And when you connect those alerts to, for example, an action group that posts a message in a Slack channel or Teams chat, you have a good starting point. Of course, be a bit careful; the policies might deploy alerts that trigger and notify too often, so you need to tweak and tune it until you are satisfied with when and how often the alerts trigger.
Networking
Hub and Spoke Network Architecture
The Hub and Spoke Network Architecture forms the backbone of the Landing Zone, facilitating a structured and scalable network design. The Landing Zone Hub is a central point of connectivity for both the spokes and the remote locations. In a Hub and Spoke architecture, all traffic leaving the spoke will go through the hub. Inside the Hub, all traffic is constantly monitored and verified. This way, only trusted traffic can leave and enter the spoke.
It is easy to compare the hub and spoke model with an airfield. The Hub is the central hall, and the spokes are the planes. To board a different plane, you must traverse the central hall to reach the other plane. You may go through customs but must show your boarding pass again when boarding the other aircraft.
Using a Hub and Spoke model makes it easier to manage core resources centrally, which is also cost-efficient. Using different spokes for different workloads improves security, as each spoke has its own access control set. By default, spokes cannot communicate with each other; we can allow this when needed. Lastly, this model keeps your Landing Zone scalable. The architecture can grow as more spokes are added to support different workloads or teams without changing the core structure.
Virtual WAN
If you have an Azure landing zone, you might need a connection between multiple regions and remote locations. To make the connection between all those resources more accessible to maintain, you can use a Virtual Wan. Inside that virtual wan, you need to create virtual hubs. It is best practice to create a virtual hub for the Azure region. Each network created in that region is connected (or peered) to the virtual hub. The Virtual WAN uses BGP to promote the routes of all the networks connected to the virtual hubs. The Virtual WAN uses this Routing Intent settings to propagate the routes to the connected virtual networks. Because all the traffic between spokes traverses the hub and all the networks are connected, traffic can flow between spokes without any problems.
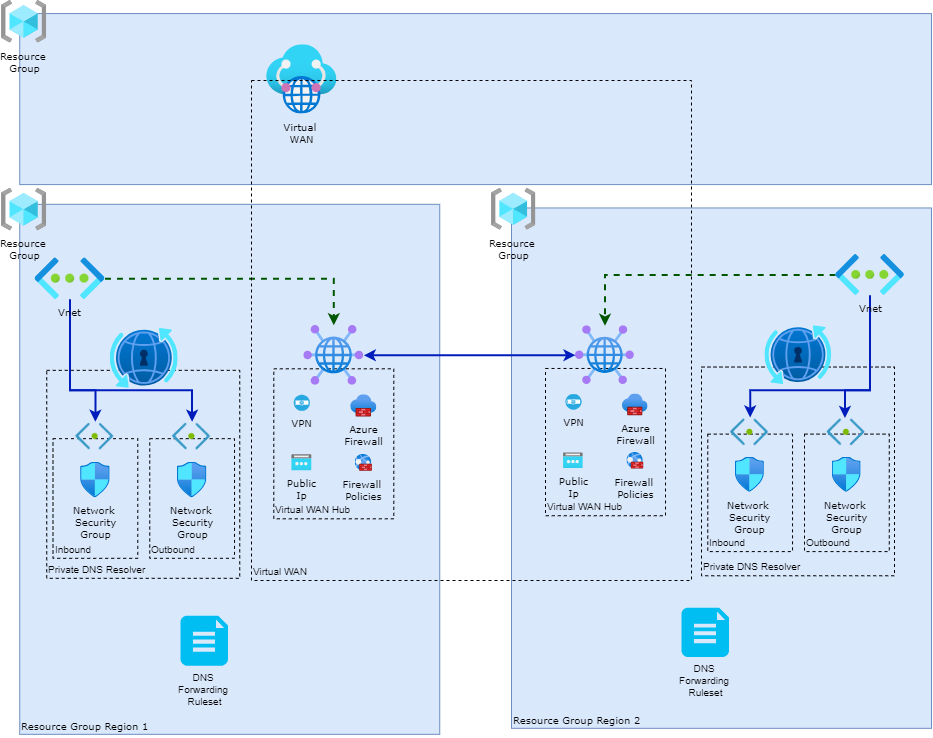
Firewall
Firewalling plays a crucial role in ensuring network security in the landing zone. As part of the architectural design, Azure firewalls are deployed and connected to each virtual hub. This centralizes the firewalling capabilities and provides a consistent security posture across the environment.
A premium Azure Firewall is deployed to provide maximum security features by default. This enables the use of advanced security features, such as:
- Intrusion detection and prevention system
- TLS Inspection
- URL filtering
By default, all traffic is blocked as part of the zero-trust architecture. Traffic that flows between workloads needs to be added to the firewall policies. Firewall rules are considered to be part of the infrastructure. Changes to these firewall rules must be made using Infrastructure as Code and the CI/CD pipelines. This approach ensures that changes to the firewall rules must be approved using the four-eyes principles and version control.
Routing
Besides network security, the firewall is also used as the next hop for all networks. The subnets inside the virtual network all have a routing table. The default rule in this routing table is that all traffic is routed to the firewall. This way, the traffic will traverse the virtual hub and thus virtual WAN.
Private endpoints
Private Endpoints in Azure are a network interface that connects you privately and securely to a service powered by Azure Private Link. Private Endpoints use a private IP address from your Virtual Network (VNet), effectively bringing the service into your VNet. This allows you to access the service without exposing it to the public Internet. Traffic will not use the Microsoft backbone or the public Internet to connect, lowering the latency and improve network security.
DNS
A crucial part of routing all the traffic between the workloads is DNS. In Azure, you can use the Azure Private DNS zones to set up your DNS. We already mentioned that the firewall is not only security-related; it can also be used as a DNS proxy. In order for the firewall to act as a DNS proxy, the DNS Servers for all the virtual networks need to be set to the regional firewall's (private) IP address.You need to enable the DNS settings and DNS proxy inside the firewall policy.
Private DNS Zones
All the private DNS zones are deployed in the connectivity part of the hub. These DNS zones must be globally available for all workloads in the landing zone. All the created private endpoints must have a DNS configuration that connects them to the Private DNS Zone. To make this work, a policy initiative is deployed. This initiative monitors the deployment of private endpoints and adds the DNS configuration to the correct private DNS zone.
resource "azurerm_management_group_policy_assignment" "deploy_private_dns_zones" {
name = "deploy_private_dns_zones"
display_name = "Configure Azure PaaS services to use private DNS zones"
policy_definition_id = "/providers/Microsoft.Management/managementGroups/XebiaRoot/providers/Microsoft.Authorization/policySetDefinitions/Deploy-Private-DNS-Zones"
management_group_id = azurerm_management_group.this.id
# Both location and identity are needed for resource changes when the policy contains "modify" or "deployIfNotExists" effects.
location = var.policy_location
identity {
type = "UserAssigned"
identity_ids = [
azurerm_user_assigned_identity.policy_assignment.id
]
}
parameters = <<PARAMETERS
{
# var.central_dns_zone contains the subscription id and the resource group name
"azureFilePrivateDnsZoneId" : {
"value": "/subscriptions/${split("/", var.central_dns_zones)[0]}/resourceGroups/${split("/", var.central_dns_zones)[1]}/providers/Microsoft.Network/privateDnsZones/privatelink.afs.azure.net"
},
... <long list="" of="" dns="" parameters=""> ..</long>
}
PARAMETERS
}
DNS Forwarding Rulesets
By default, the DNS Setting on the firewall policy uses the Azure DNS to resolve the addresses. There is an option to provide a custom DNS server if Azure DNS is insufficient. One way to do this is to add private DNS Resolvers. A private DNS resolver has an inbound endpoint with an IP address; this address needs to be the custom DNS proxy forwarder on the firewall. If you, for example, have a custom domain controller for a specific domain, you also need to add a ruleset to the DNS Resolver. The traffic will be forwarded to the defined address if the rule matches the DNS requested.
Policies or Guardrails
Policies or guardrails are incorporated into the deployment process to ensure compliance and governance. These guardrails check against predefined rules and guidelines, verifying that the deployed infrastructure and workloads align with security, compliance, and governance requirements.
Azure provides a set of policy initiatives, such as ISO 27001/27002, CIS (Center for Information Security), and NIST. In addition to the standard policies, customized policies like the Security Frameworks can be added to the policies in the Landing Zone.
The policies are set to the relevant management groups to ensure that the policies are active on all management groups and subscriptions (spokes and their resources).
All resources must follow the guardrail approach, which allows them a certain degree of freedom within defined boundaries. This approach balances flexibility and compliance by establishing guardrails consisting of policies and guidelines. These guardrails keep the landing zones in check, ensuring that environments can be customized while operating within the established policies.
Policies are written as code using Json amd deployed with Terraform, enabling version control and automated deployment through CI/CD pipelines. This approach streamlines policy updates and ensures consistency across the landing zones. By treating policies as code, we can easily manage, update, and enforce them.
{
"name": "DenyCreationTagWithCertainValues",
"managementGroupId": null,
"properties": {
"displayName": "Custom - Allow resource creation if tag value in allowed values",
"policyType": "Custom",
"mode": "All",
"description": "Allows resource creation if the tag is set to one of the following values.",
"metadata": {
"version": "1.1.0",
"category": "Xebia Custom - General"
},
"parameters": {
"tagName": {
"type": "String",
"metadata": {
"displayName": "Tag Name",
"description": "Name of the tag, such as 'Environment'"
}
},
"tagValues": {
"type": "Array",
"metadata": {
"displayName": "Tag Values",
"description": "Values of the tag, such as 'PROD', 'TEST', 'QA', etc."
}
}
},
"policyRule": {
"if": {
"allOf": [
{
"field": "type",
"equals": "Microsoft.Resources/subscriptions/resourceGroups"
},
{
"not": {
"field": "[concat('tags[', parameters('tagName'), ']')]",
"in": "[parameters('tagValues')]"
}
}
]
},
"then": {
"effect": "Deny"
}
}
}
}
Enterprise Scale
If you build a landing zone, you do not want to reinvent the wheel. This also applies to a lot of "best practice" policies. The Azure team maintains a repository with all the best practices for an enterprise's landing zone. Besides all kinds of examples for how to deploy the landing zone, it also contains a lot of policy definitions and policy initiatives. You can find them here: Enterprise-Scale
Assignments
As mentioned before, policies are assigned to a management group. Many policy definitions or initiatives contain input variables. These variables can be used to tweak and tune the policy the way you want it. You could, for example, set the "effect" of a policy to "Audit" instead of "Deny." This will still show if resources are not compliant but will not block a deployment. There are a lot of parameters you can set, so be sure to use them wisely.
resource "azurerm_management_group_policy_assignment" "inherittagvalues" {
name = "inherittagvalues"
display_name = "Xebia - Configure - Inherit Tagging Values"
policy_definition_id = "/providers/Microsoft.Management/managementGroups/XebiaRoot/providers/Microsoft.Authorization/policySetDefinitions/InheritTaggingFromResourceGroup"
management_group_id = azurerm_management_group.this.id
# Both location and identity are needed for resource changes when the policy contains "modify" or "deployIfNotExists" effects.
# for this assignment location does not matter it will only inherit the tags from the resource group
location = var.policy_location
identity {
type = "UserAssigned"
identity_ids = [
azurerm_user_assigned_identity.policy_identity.id
]
}
}
Exemptions
Sometimes, it is not possible to make the resources compliant. If needed, you can exempt certain policies for specific resources, resource groups, subscriptions, and event management groups. Exemptions are a way to exclude policies and ensure that only relevant policies are reported.
# Exemption Network Watchers resource location matches resource group location on connectivity subscription
resource "azurerm_resource_group_policy_exemption" "exemption_nww_location" {
name = "exemption_nww_location"
resource_group_id = azurerm_resource_group.network_watcher.id
policy_assignment_id = "/providers/Microsoft.Management/managementGroups/123456-7890-0987-1234-123456789098/providers/Microsoft.Authorization/policyAssignments/LocationMatch"
exemption_category = "Mitigated"
}
Architectural Decisions Records (ADR)
This is a bit of a side step on the landing zones; it, however, is an important concept that comes in handy when building a landing zone or any other product. An Architectural Decision Record (ADR) is a document that captures an essential architectural decision made along with its context and consequences. It is a way to document the rationale behind decisions, ensuring that the reasoning is preserved for future reference. This can be particularly useful when revisiting decisions or when new team members must understand why certain choices were made.
ADR consists of:
- Title: A short, descriptive name for the decision.
- Context: Background information and the problem statement that led to the decision.
- Decision: The actual decision that was made.
- Consequences: The positive and negative outcomes of the decision.
- Status: The current status of the decision (e.g., proposed, accepted, deprecated).
Make sure to place the ADRs in a central place so everyone can read them and understand why certain decisions have been made. An ADR is not something that can never be changed; it is only a way of helping to understand the why behind it.
# ADR 1: Use PostgreSQL for the Database
## Context
Our application needs a robust, scalable, and open-source database solution.
## Decision
We will use PostgreSQL as our primary database.
## Consequences
- Positive:
- PostgreSQL is highly reliable and has strong community support.
- It supports advanced features like JSONB, which can be useful for our application.
- Negative:
- Team members need to get familiar with PostgreSQL-specific features and configurations.
Deployment
Workload Landing Zone Deployment
So, what happens if a workload team needs a subscription? Would it be smart to manually give them a subscription and let them figure out how to set it up properly? Probably not. If you want to help a workload team get started, you are better off helping them kick-start into Azure. In addition to helping the team, it will also help you make sure everything is compliant and connected when the team gets the subscription.
So, by default, we will deploy a virtual network for every new subscription connected to the Virtual Hub with the correct route tables on the two subnets we create. The virtual network also has the correct DNS Settings. Doing this ensures the connection is in place and already working. I can hear your thoughts, but what if I need more subnets? You are free to indicate the network size and add more subnets if necessary.
Besides the virtual network, we will provide a Key Vault, Storage Account, Log Analytics workspace, and default alerting. All the resources are compliant by default and deployed with IaC. The resources, subscriptions, and management groups are deployed using IaC. If needed, we can even deploy policy exemptions for resources. All these resources are what we call a "spoke canvas."
So now we have a management group, a subscription, and resources, but we also need one more thing: permissions. With our zero trust setup, we use the least privilege for everyone. The team will get a "reader" group and an "owner" group to achieve this. The reader group contains everyone from the team. By default, the owner group contains no members. If an incident happens, more permissions are sometimes needed. Privileged Identity Management (PIM) is here to help. PIM offers you the option to get elevated permissions for a short period. The "newest" setup is using groups. In our case, if you are a member of the reader group, you can 'pin' into the owner group to get your temporary permissions. PIM requires a reason and (highly recommended) approval to become active.
What is a workload? A workload is generally defined as an application or a value stream.
Layered deployment
As described earlier, we release a new version of a module or template when we modify the code inside it. These releases are then consumed by either Templates or Solutions. We use semantic versioning. This scheme uses three numbers separated by a dot — MAJOR, MINOR, and PATCH. It communicates the reason for the changes, for example, 2.1.3.
We do this to prevent big-bang module/template upgrades. Let take an example, we have a template called Windows Virtual Machine. Sadly we have to introduce a breaking change in the next release. Without versioning all solutions using this template would automatically consume the new version. This would results and a broken pipeline, cause we introduced a breaking change. However, with versioned templates and modules, we can control when to upgrade. If a breaking change occurs, we can modify the code before selecting the newest version.
However, this concept introduces some overhead. If 30 templates and 100 solutions rely on a single module, we need to update and merge version changes across 130 repositories. Luckly, we can borrow an effective practice from software development called automated dependency updates. This tool scans your repositories to check if a dependency (like a Terraform module) is up to date. If it’s not, it automatically generates a pull request with the necessary version change. In theory, with automated tests in place, we could fully automate patch updates and potentially even minor version changes.
When you use Terraform or any other language to deploy your infrastructure, you would like to see fast and small deployments. When we introduced the Landing Zone, we also introduced the three parts (Connectivity, Management and Identity). Imagine you have a pipeline to deploy all the parts in one go. That may be fine for a single region, but what would happen if you had eight regions? Do you want to deploy all eight areas together? The answer to this question is probably "no."
The concept of Layered deployments helps us here. When using a layered deployment, you will split your deployment into smaller parts, which we call layers. In this case, we split the Landing zone into five parts: baseline, connectivity, management, identity, and diagnostics. The baseline will deploy some base resources we need to set up the other parts of the landing zone, like the DNS zones. We will deploy all the necessary resources for these landing zone parts in the connectivity, management, and identity layers. The diagnostic layer will deploy all the diagnostic settings on the resources.
This layer can be deployed separately to each region. So instead of having one big deployment, we now have eight times five equals forty small deployments. I can hear you think, so what's the difference? I still need to wait for the whole pipeline to complete. And if we leave it like this, then you are correct.
Luckily, because we created the layers, we can do something clever with those layers. We call it a Matrix deployment. With a Matrix deployment, you will run only the layers that have been changed. In order to detect the change you need to create a script that finds the changes for the new deployment.
When you use IaC, you will also need git as a version control tool. Git comes with many powerful and handy features, one of which enables you to get the changed files. So if a file in identity deployment changes, we can, based on that change, only run the identity layers, making our deployment much more minor.
Now, let's take a look at our eight environments. If something changes in West Europe, do you want to run all the other seven environments as well? If we combine our layered deployment with the environments we have and put both in a matrix deployment, we will end up running only West Europe or only North Europe because this is where we changed something. This way, we will save a huge amount of time when deploying the landing zones.
Innersource
Microsoft Azure has a lot of different services, so not all building blocks will be available. To ensure the teams are supported, the principle of Innersource is adopted. If no building block is available or existing building blocks need an update, teams are allowed to change or add Terraform templates and modules to the Platform Team repository. The platform team will verify if the changed or added templates apply to all the policies (four-eyes principle) and approve the merge request. After the approval of the changes, a new version of the template will be released. This puts the platform team in complete control of the building blocks without needing to change everything themselves.
Agents or Runners
When you use IaC, you will eventually need some tools to deploy the code to Azure. Weapons of choice are GitHub or Azure DevOps. Both use agents/runners to run the IaC and deploy your resources to Azure. The agents or runners are usually virtual machines hosted in Azure. And that brings us to an exciting part. You will need a subscription to host your agents on a Virtual Machine, but to deploy your code, you will need an Agent. This chicken-and-egg problem can be solved by initially creating the subscription by hand and the virtual machine from your local laptop using Terraform.
Note: After each deployment the agents/runners are cleaned to make sure no code is "left behind" on the agent that contains sensitive information. This also aligns with the zero trust principles of the landing zone
There is one more thing you need to think about. The location where you deploy your runners. Do you want them to be outside or inside the landing zone? If you deploy them outside your landing zone, you can deploy the resources, but if you need a storage container inside a storage account or a secret in the key vault, it won't be easy. Remember, the firewall closes the landing zone, uses private connections, and isolates networks. On the other hand, if you deploy them inside the landing zone and they become part of the network, this problem is solved. But if you can create multiple landing zones, for example, a sandbox to play around, a nonproduction to test, and a production landing zone, you will also need agents inside each landing zone. If you only have an agent in the production landing zone, it will not be able to connect to the sandbox landing zone, and vice versa.
We ended up with agents inside and outside the landing zone just to ensure we could do everything we needed. Remember that you also need to set up your workflows in GitHub and Pipelines in Azure DevOps so that it knows what agent to use. That might be a different agent for Sandbox, production, and production.
Conclusion
Building a new Azure Landing Zone from scratch is a lot of work. It can be hard to figure out where to start and how to do the setup. The most crucial step is to determine what you need. The following steps are to build up the landing zone slowly. Do it in small steps because the only thing you get from a big bang is a big bang. These small steps can maybe deploy one resource at a time. It will be much easier to handle these changes and adjust anytime. And trust us, you will not get it right the first time; there will always be something that does not work as expected. You will also see that you are never actually 'done' with building a landing zone. There will always be a need for improvements.
This article should help you set up your landing zone and give you some insight into how we did it.
Enjoy your build!
This article is part of XPRT.#17. Download the magazine here.

Written by
Arjan van Bekkum
I am passionate about problem-solving for customers with the help of technology I love to learn new techniques, technologies and ways to improve myself. The endless possibilities are beyond our imagination. If you want to do more than just get the job done, you need to listen, ask, learn, and challenge.
Our Ideas
Explore More Blogs

Embedding Requirement Agents Across Jira, Confluence and Enterprise Agile...
Requirement Agents deliver value far beyond generating superior requirements. When deeply integrated with Jira, Confluence, and Azure DevOps,...
Manoj Sharma



Contact