Blog
How I replaced Xebia Leadership with Artificial Intelligence

You've heard of the age-old saying: "If you can't beat them, join them," right? Well, I decided to take it a step further and created an AI replica of the Xebia leadership team. That's right, folks; I replaced the Xebia leadership with artificial intelligence! In this blog post, I'll walk you through my amusing journey of creating Virtual Xebian, a website where visitors can ask questions to the virtual Xebia leadership and receive answers in the spirit of their personalities.
Introducing Virtual Xebian
The first step in my grand experiment was to create a website called Virtual Xebian . Here, visitors can select which member of the Xebia leadership team they want to question. Then, they can ask anything they like, and the Virtual Xebian will provide an answer that aligns with the selected leader's personality, as well as Xebia's mission, vision, and values.

The Technical Wizardry Behind the Scenes
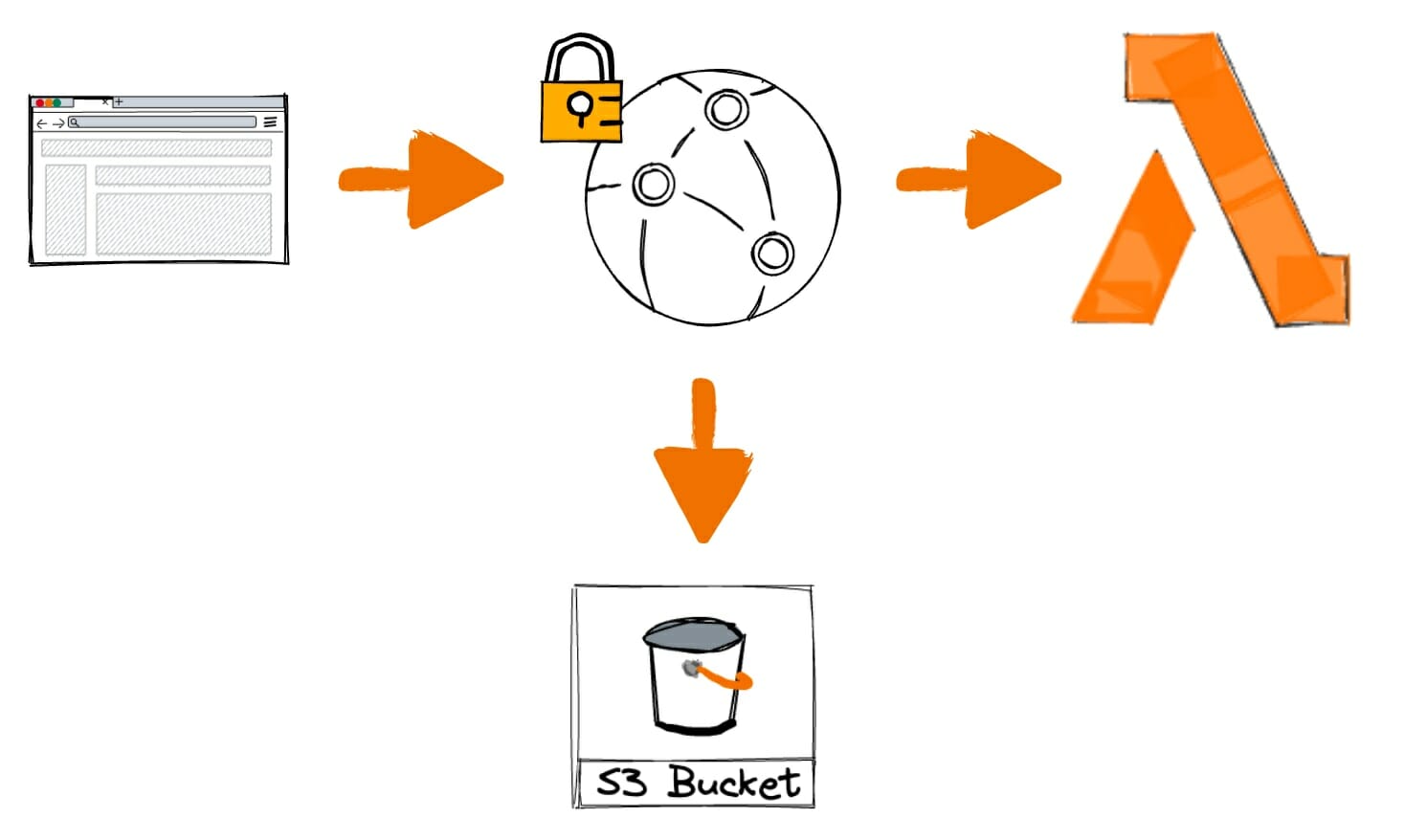
Now, you might be wondering how I pulled this off. The magic happens through a combination of Serverless, user input, a CloudFront distribution, a Lambda function, and the OpenAI API. Here's a brief overview of the process:
- Users submit their questions on the front-end of the website.
- The payload, which includes the selected Xebian and the question, is sent to the API endpoint at https://api.virtualxebian.com.
- This endpoint is a CloudFront distribution in front of an AWS Lambda function that acts as an HTTP endpoint.
- The Lambda function is a Python script that incorporates the Xebia mission, vision, and values, as well as each leader's personality and speaking style. It generates a single prompt that it sends to the OpenAI API.
- The OpenAI API generates a response based on the prompt, which is then returned to the user via the front-end of the website.
I've shared some sample code at github.com/binxio/ai-lambda-starter so that anyone interested can quickly start building their own AI API implementations and integrations.
Architecture
Being a serverless application, its architecture is very simple:
Building an AI-Integrated Lambda: Key Principles
When I created Virtual Xebian, I developed a Lambda function that integrates with the OpenAI API and processes POST requests from the front end. Here are some key principles to consider when building such a Lambda:
- Security and API Key Management: When working with external APIs like OpenAI, it's crucial to securely manage API keys. In my code, I stored the OpenAI API key as an environment variable, ensuring it remains protected and isn't hardcoded into the script (and ends up in GIT). It's better to use SSM or the Parameter Store though, so you won't need credentials on your machine or in the CI/CD pipeline whatsoever.
openai.api_key = os.environ.get('OPENAI_API_KEY')
- Context and Personalization: To provide personalized responses, we need to supply the AI with relevant information about the entity it's emulating. In my example, we define the context, role, job, personality, and preferred writing style for the virtual CEO:
context = """...some long blob of information..."""
role = 'Barry',
job = 'the CEO of PaperCraft Unlimited',
personality = '...'
style = 'Stephen King'
- Asking Questions to the AI: To make our AI respond effectively to user questions, we craft a well-structured prompt that includes the context, personality, and writing style. This prompt is sent to the OpenAI API:
response = openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=[
{"role": "system", "content": f"You are Virtual {role}, {job}"},
{"role": "user", "content": f"... {context}. {personality}. Stay in character. Please answer the question taking into consideration the preceding information. Answer in the style of {style}.nMy question is: {question}."}
]
)
- Handling POST Requests: To process incoming POST requests, we first check if the HTTP method is POST. If so, we parse the request body, extract the user's question, and invoke the ask_ai() function to get a response from the AI:
if event["requestContext"]["http"]["method"] == "POST":
body = json.loads(event['body'])
question = body.get('question')
...
- CORS Handling and Response Formatting: When responding to front-end requests, it's essential to handle Cross-Origin Resource Sharing (CORS) correctly. In our Lambda, we set appropriate CORS headers and return the AI's response as a JSON object:
return {
'statusCode': 200,
'headers': {
'Access-Control-Allow-Origin': '*',
'Access-Control-Allow-Headers': '*',
'Access-Control-Allow-Methods': 'OPTIONS,POST,GET'
},
'body': json.dumps(
{
'answer': ask_ai(question)
}, indent=2
)
}
- Fallback and Non-POST Requests: In the event our Lambda receives a non-POST request, we should provide a fallback response. In our example, we return a playful message indicating the virtual CEO's systems are operational:
Copy code
else:
return {
...
'body': json.dumps({'message': 'The circuits of PaperCraft Unlimited's CEO are functioning perfectly and all systems are operational.'}, indent=2)
}
Emulating Xebia Leadership: Personalities and Speaking Styles
Our Virtual Xebian responses are not only informative but also reflect their unique personality and speaking style.
The ask_xebian() method is designed to handle questions for different leaders, taking into account their individual characteristics. The code snippet provided contains examples for two leaders: Anand, and Andrew.
if role == 'Anand':
job = 'the CEO of Xebia Global.'
personality = '...'
technical = False
style = 'Reid Hoffman'
elif role == 'Andrew':
job = 'the CEO of Xebia Netherlands.'
personality = '...'
technical = False
style = 'John F. Kennedy'By incorporating these details into the AI prompt, the Virtual Xebian's responses not only answer the user's question but also stay true to the character, personality, and speaking style of the selected leader. This attention to detail creates a more engaging and authentic user experience.
Frontend integration with the API
The request being sent to the API looks like this:
{
"question": "What is the answer to life, the universe and everything?",
"role": "anand"
}The response gets rendered in the frontend:
let response = await fetch('https://api.virtualxebian.com/', {
method: 'POST',
headers: {
'Content-Type': 'application/json',
},
body: JSON.stringify({ "question": question, "role": person }),
});
if (response.ok) {
const data = await response.json();
answerTextarea.value = data.answer;
} else {
answerTextarea.value = 'I am sleeping right now. Please try again later.';
}A Look at the Serverless Configuration
To deploy the Virtual Xebian API, we used the Serverless Framework, which simplifies the process of deploying serverless applications on cloud platforms like AWS. The serverless.yml configuration file is the heart of my project and outlines various settings and resources required for deployment. Let's break down the key components of this file:
- Service and framework version: I named my service virtualxebian-api and specified that we're using version 3 of the Serverless Framework.
service: virtualxebian-api
frameworkVersion: '3'
- Plugins: We added the serverless-aws-function-url-custom-domain plugin, which allows us to customize the domain for our API endpoint.
plugins:
- serverless-aws-function-url-custom-domain
- Provider settings: We specified AWS as our cloud provider and configured the runtime, stage, region, timeout, memory size, and other settings.
provider:
name: aws
runtime: python3.9
stage: prod
region: us-east-1
timeout: 60
memorySize: 512
versionFunctions: false
environment:
OPENAI_API_KEY: ${file(../.private.json):OPENAI_API_KEY}
- Functions: We defined a single Lambda function called api-handler that uses the api-handler.api Python script as the handler. We also added an OpenAI Python layer and enabled URL customization for the function.
functions:
api-handler:
handler: api-handler.api
layers:
- arn:aws:lambda:us-east-1:<acount_id>:layer:openai-py-layer:1
url: true
You will find the Docker file for the layer at github.com/binxio/ai-lambda-starter/
Finally, the domain name configuration is done as follows:
custom:
urlDomain:
domains:
- api.virtualxebian.com
hostedZoneName: virtualxebian.com.
certificateArn: 'arn:aws:acm:us-east-1:<account_id>:certificate/some-cert-id'
route53: true
This does mean you have to have an ACM certificate already in the us-east-1 region. You could automate this bit as well. Read more about it at serverless.com/plugins/serverless-certificate-creator. At the time of writing I had an issue with this specific module so decided not to use it.
The Result: A Fun and Valuable Resource
What I have done is add some personal information for each AI character, sort of like a backstory, and made them speak in the style of a public speaker that matched their personality the best, and while the title of this blog post might be a playful jab at the concept of replacing human leadership with AI, the outcome is an interesting conversation starter about the possibilities of AI. It is more than a gimmick, though. These virtual characters are fully aware of the mission, vision and values of Xebia. On top, GPT is already aware of Xebia's existance. When asking work or business-related questions, you will more likely than not receive an answer close to what the actual Xebia leadership would give you.
While we're not quite at the point of replacing real-life leaders with AI, it's fascinating to see how technology can create virtual doppelgangers that are both entertaining and useful. What would you build?
Written by

Dennis Vink
Crafting digital leaders through innovative AI & cloud solutions. Empowering businesses with cutting-edge strategies for growth and transformation.




Contact