Blog
Did You Update The Documentation?

Nobody likes writing documentation. It's a boring and tedious task. And the worst thing is that the moment you write it, it's already outdated. Yet, it's one of the most important parts of the software we create. No matter how many times developers say, "The code is self-explanatory," it's not. Documentation helps new people get onboarded more quickly, and more importantly, it can improve collaboration between teams. Documentation is key when you build applications that expose APIs.
In the case of APIs, most developers will first ask for an OpenAPI specification as their documentation of choice. If you're unfamiliar with OpenAPI, it's a standard way to describe your API. This file contains all the information about your API, like the endpoints, the request and response bodies, and the authentication methods. It often surfaces through a Swagger UI, which provides a friendly way to explore the API from your browser. These files are automatically generated from your codebase, so creating and sharing them is not a problem at all. However, not everybody understands these specifications or has the tools to interpret them. Some people, yes, even developers, prefer to read human-readable documentation.
This presents us with a problem. The typical developer stereotype is that we don't like the following three things:
- Writing documentation
- Writing unit tests
- Writing regular expressions
Unsurprisingly, when the newest wave of LLMs hit in 2022, people started making tooling that solved the latter two. Github Copilot, especially, has been a game-changer for many developers. While you can use it to extract documentation from your code, it suffers from one big problem: it's a copilot, not a captain. It can help you write documentation, but you need to tell it to do so. If you aren't going to remember to write documentation, why would you remember to ask Copilot to write it for you? So, in true developer fashion, the best way to get out of doing something boring is to write a tool for it.
Continuous Integration/Continuous Documentation
We're currently building an Integration Platform for our client. The platform offers developers a quick way to get their integrations off the ground, no matter the programming language they want to use. Many of these integrations are APIs that all need to be documented. In our Platform Engineering journey, we spend a lot of time and attention on perfecting our integration and deployment pipelines. Next to all the big jobs like building, testing, and deploying, we use these pipelines to make our jobs easier. So we decided to put the machines to work on doing the task we would surely forget. We can automatically generate human-readable documentation from the OpenAPI specification for all the APIs that land on our platform.
After we build, test, and deploy our software, we need to acquire the OpenAPI specification and offer it to a Large Language Model (LLM). The software we wrote to do this could have been implemented in various ways, from building a custom pipeline step to using a simple script in our pipeline. Whatever the solution, we need credentials to access the LLM, as well as credentials to push the documentation to Confluence. While we could securely obtain these credentials in all our pipelines, they would need to be accessible by all the pipelines that we run for these different APIs. Instead, we decided to build a separate service in our integration platform that all the pipelines can call. This service generates the documentation and pushes it to Confluence. All our API pipelines run with their own service principal, which can be granted access to this service. This way, we can keep the credentials for the LLM and Confluence in one place and only have to manage them in one place.
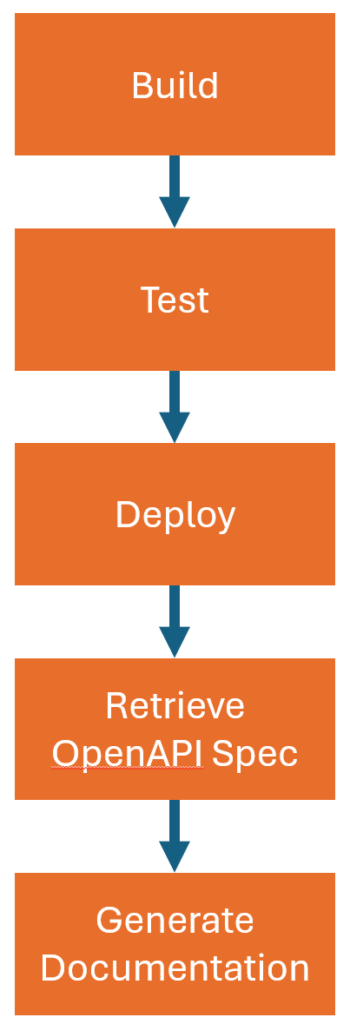
The Service
This central service is an API built on ASP.NET Core and leverages two different technologies: Semantic Kernel and Prompty. While you can achieve the same with the Azure OpenAI REST API, these tools will make your life easier. Semantic Kernel abstracts away specific LLM implementations and is helpful in bootstrapping authentication to Azure OpenAI. Prompty is a convenient way to bundle your prompt, parameters and sample input in a single file. You can find out more about Prompty in another article in this magazine: "Stop Creating Content With ChatGPT!". Together, these two tools make interacting with LLMs a breeze. It reduces the code you need to execute to only a few lines:
KernelArguments kernelArguments = new()
{
{ "specification", openApiSpec }
};
var prompty = kernel.CreateFunctionFromPromptyFile("./Prompts/openapi.prompty");
var promptResult = await prompty.InvokeAsync<string>(kernel, kernelArguments);
```
The Prompty file includes all the instructions the LLM needs to turn a complex JSON file into English. It also contains part of the Confluence documentation that describes the specific formatting rules for a Confluence page. This way, the LLM can generate the documentation in the correct format. The API then takes the generated documentation and uploads it to Confluence.
All the different workloads that make up our integration platform run on our Azure Landing Zones. These landing zones come with a lot of benefits for networking, security, and governance. To host this central service, we gave it its own Azure Landing Zone. The Landing Zone offers us a blank canvas to deploy our service, and in our case, this is limited to just a few services.
First of all, we need something to run our code. Azure offers many different compute products to host a simple API. We decided on an Azure Container App. This has easily become our hosting model of choice in our integration platform because it offers container-based hosting with many different scaling options. This might sound like overkill for a relatively simple API that is called maybe once or twice per hour, but a benefit is that the API can automatically scale back to zero instances, so it does not cost any money. This makes it a very cost-effective solution.
Next to the Container App, the API needs to interact with an LLM in order to generate the documentation. For this, we decided to use the Azure OpenAI service and deployed the GPT-4o model. Through Azure OpenAI, we get access to all leading LLMs without a matching price tag. Just like with Container Apps, you only pay for what you actually use. In the case of our GPT-4o model, we only pay for the amount of tokens we exchange. When we generate documentation, the LLM costs are below 2 cents per run. When no documentation is generated, we pay nothing for these resources. The API sets up a secure connection through the Managed Identity, which is built into the Container App, which saves us from having to manage credentials for it. As long as the identity has the correct access permissions, it can connect.
Finally, we also need a place to store the credentials that are needed to upload the documentation to Confluence. This is simply solved by adding a Keyvault and having the API connect to it to retrieve the necessary credentials.
<h3>Using it</h3>
Now that it is all available and running, we can actually use it in our pipelines. We have multiple environments, and as all of them can have different versions of an API running, we need to generate the documentation per environment. We have accomplished this by adding a 'Generate documentation' step after all our deployments, which will retrieve the OpenAPI specification from the deployed resource and call the documentation service with the retrieved specification as content, together with the identifier of the environment. The documentation service will make sure that a page on Confluence is created or updated for that environment and that the generated documentation is on that page. To make it easier for all users of our platform, we turned it into a templated step. So, all they have to do is add the following to their pipeline:
```yml
- job: generate_documentation_nonprod
displayName: Generate Documentation Nonprod
steps:
- script: curl -o swagger.json https://apiname.nonprod.integrations.clientname.org/swagger/v1/swagger.json
displayName: Download Swagger JSON
- template: /pipelines/templates/steps/generate-documentation.yml@platform
parameters:
name: ApiName
environment: nonprod
filePath: swagger.jsonConclusion
We're building an integration platform that will host dozens of APIs by different authors using different programming languages. In every decision that we make on our Platform Engineering journey, we try to maximize the automation to make the developer experience the best we can. All of the users of our platform can now use our documentation generation API to make certain that their documentation continuously matches their actual features. This way, we can ensure that the documentation is always up to date and that we can focus on the things we love to do, such as adding value by building features.
This article is part of XPRT.#17. Download the magazine here.

Written by
Matthijs van der Veer
Matthijs is a consultant at Xebia, with a strong focus on Generative AI. He loves helping people achieve more in the cloud.
Our Ideas
Explore More Blogs


From Spec to Code: Building Software with Spec Kit
This article walks through the full workflow, from installation to a working implementation, covering both greenfield projects and extending an...
Hidde de Smet, Emanuele Bartolesi


Contact