Blog
CI/CD in dbt Cloud with GitHub Actions: Automating multiple environments deployment

Dbt streamlines the analytics engineering workflow, covering all steps from development and testing to documentation and deployment, all in a non-intrusive way. This means that you can create documentation, tests, and deploy changes with minimal effort and maintain them easily.
In my previous blog post, I discussed how to manage multiple BigQuery projects with one dbt Cloud project, but left the setup of the deployment pipeline for a later moment. This moment is now! In this post, I will guide you through setting up an automated deployment pipeline that continuously runs integration tests and delivers changes (CI/CD), including multiple environments and CI/CD builds as soon as pull requests are opened in the code repository. By setting up your environment like this, you can confidently release changes as many times as you want, making your job easier.
Create a Job to build the preprod environment daily
The first step in setting up our CI/CD pipeline in dbt Cloud is to create a Job that runs daily. This way, we ensure that we are developing with the most up-to-date transformations, without compromising too much resources.
To create the Job, we will navigate to the Jobs tab, under the Deploy top-bar item, and click the Create Job button.
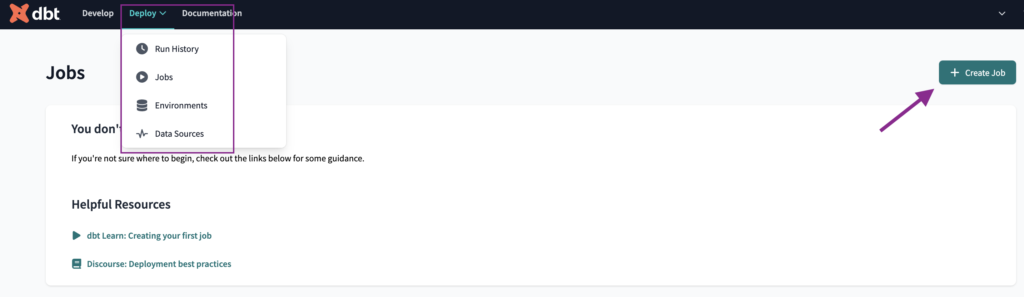
We will name the Job as Build preprod and select the preprod environment.
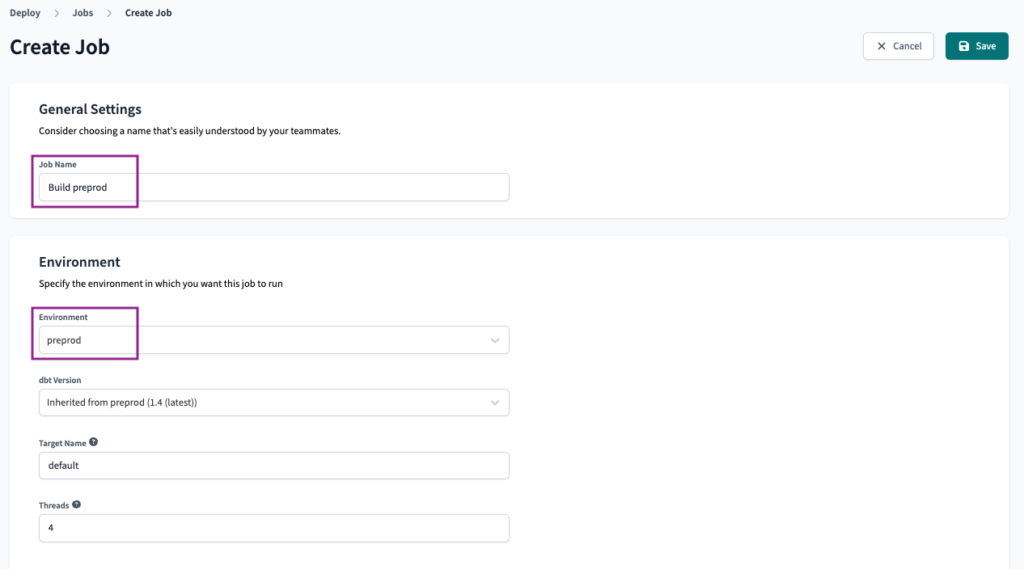
We will keep the Execution Settings as the default, with just the dbt build command. You can edit this depending on your requirements.
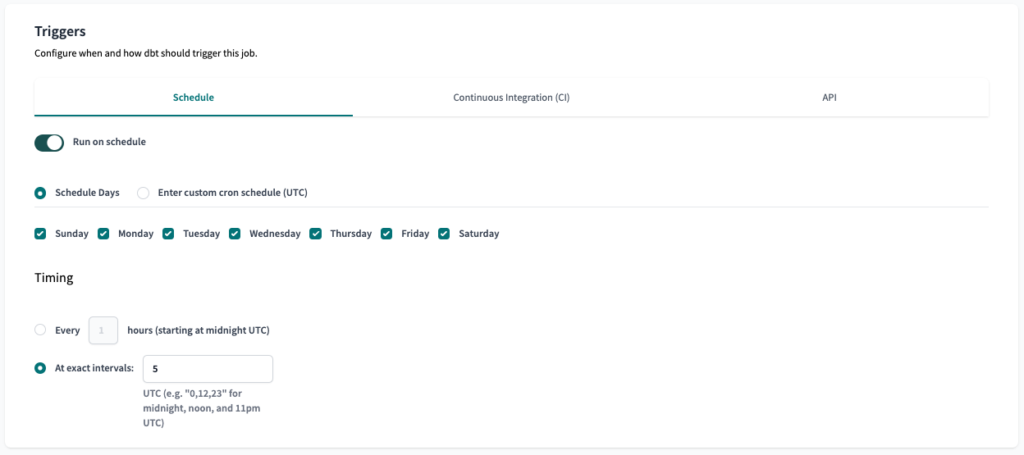
For the Triggers, we will set the Schedule to run daily in the morning.
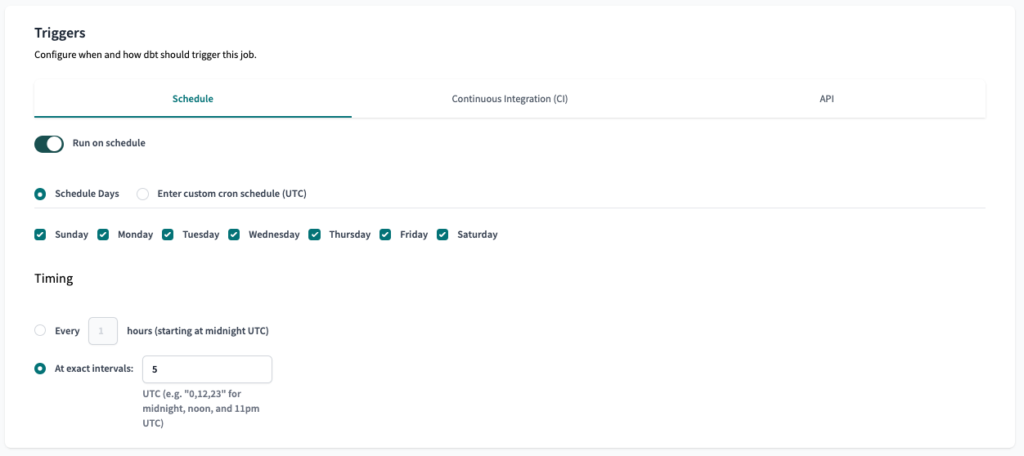
The first step of our configuration is done, just Save the Job and it will start to run daily.
Create a Job to build the modified models on the preprod environment on every PR
Next, we will create a job that is triggered whenever a Pull Request is opened. This Job should run the necessary tests and validations to ensure that the code changes are ready to be merged into the main branch. The job will build only the modified models and their dependent downstream models.
In this case, we'll assume that you're using GitHub as your code repository, but other services like GitLab and Azure DevOps are also supported.
We will name the job “CI preprod” and select the preprod environment.
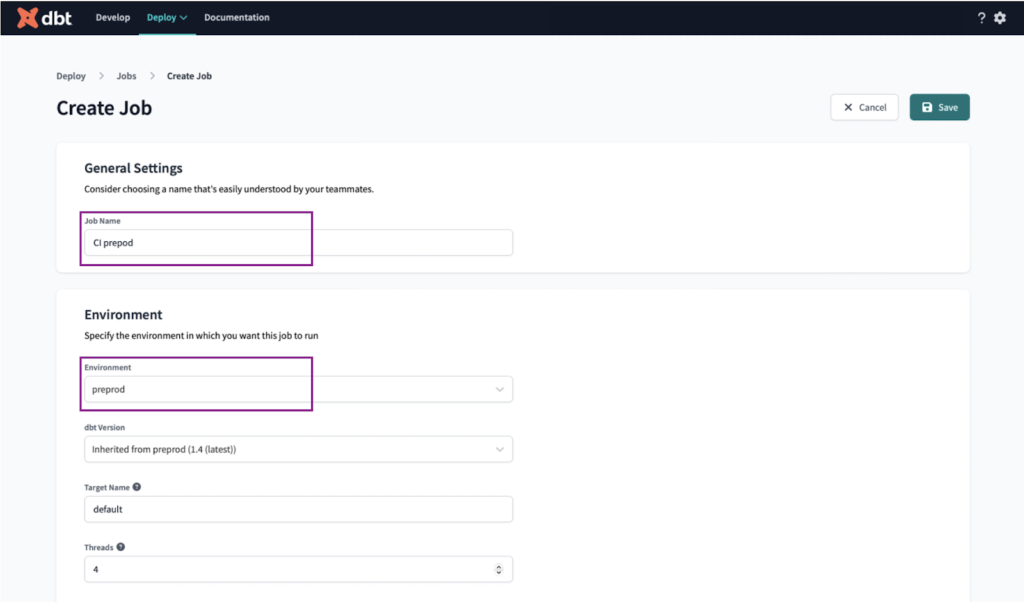
On the Execution settings we set the following:
- Set “Defer to previous run state?” to the “Build preprod”. This ensures our CI job won’t be triggered in case there are issues with the environment.
- Set the commands to
dbt build --select state:modified+
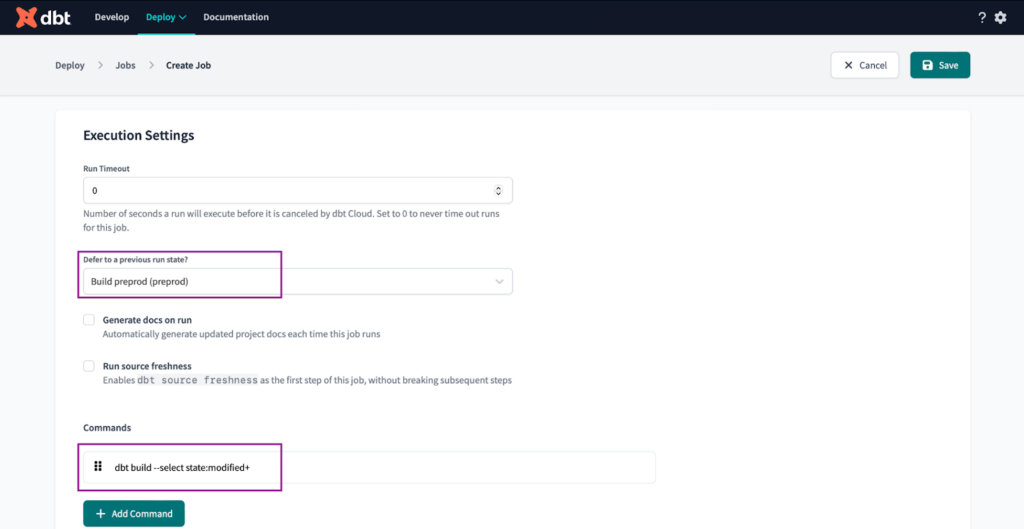
We execute this command to build only the modified models and their dependent downstream models, which are identified by the ‘+’ symbol at the end of the command.
You may be wondering why we follow this CI/CD build process, instead of building the whole project. There are some main reasons:
✅ Building the modified models and related downstream models is just right. Only the necessary models are executed to detect any issues caused by the modifications.
❌ Building the modified models with related up and downstream models by executing “dbt build --select +state:modified+” (notice the extra ‘+’ before state) could be an option, but we prefer to refresh the preprod environment daily so we don’t require fresh data at every CI run.
❌ Building the entire project is too heavy, a waste of resources and probably time-consuming.
❌ Building only changed models is insufficient as it doesn't identify issues in downstream models.
Finally, to set the Continuous Integration (CI) trigger, all we have to do is select the Run on Pull Request? checkbox.
Note: To enable the CI trigger, you must connect your dbt Cloud project with either GitHub, GitLab or Azure DevOps.
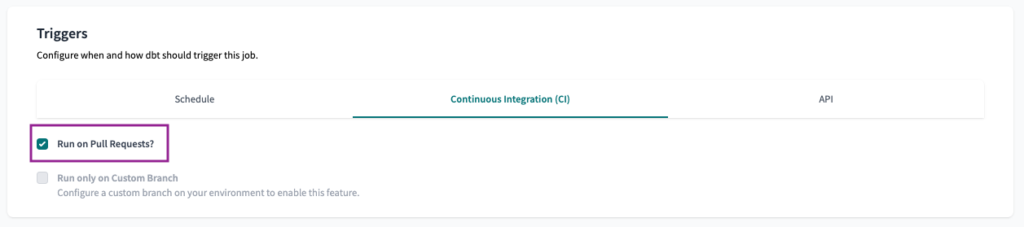
Once the trigger is set, Save the Job and create a Pull Request to check if the CI job is working. Every new or updated Pull Request should trigger a Job run in the dbt Cloud environment.
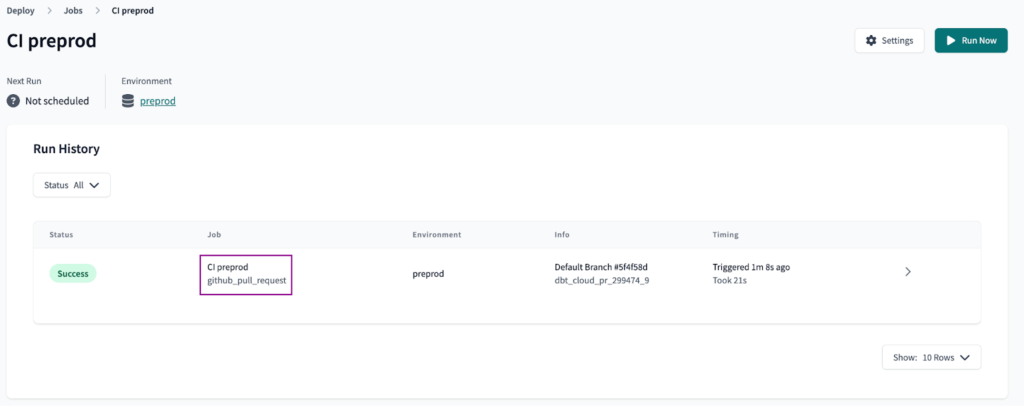
Create a Job to build the prod environment
Next, we will set the Job to run the prod environment. The goal is to have a Job that runs the production environment by a Schedule and to run once a Pull Request is merged.
For the last, there are no native options from dbt, so we will have to set a GitHub Action to run the Job using dbt Cloud API. The same can be done using Azure DevOps or GitLab, but we will focus on GitHub for this article.
First things first, we will create a new Job, name it Build prod and select prod as the environment.
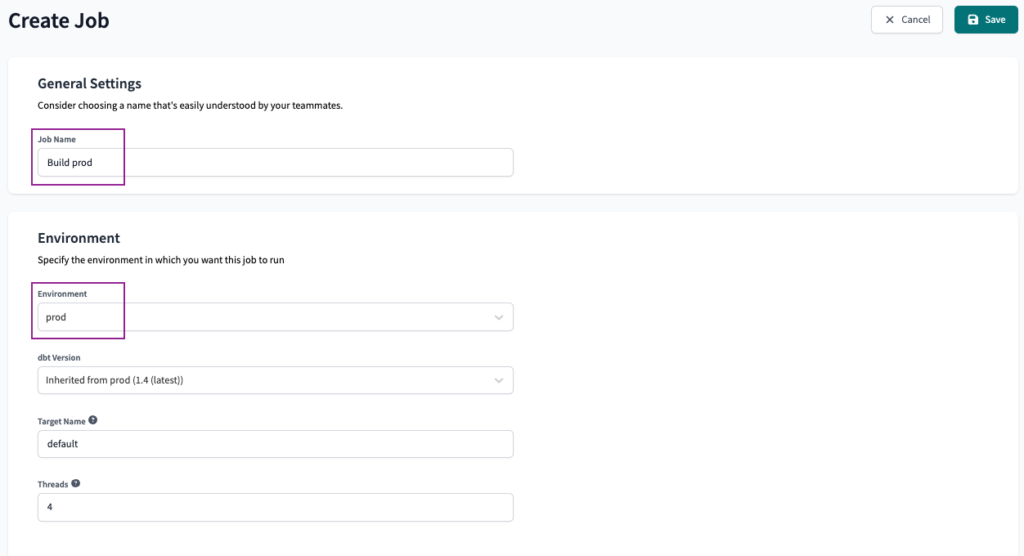
We will keep the Execution Settings as the default, with just the dbt build command.
For the Schedule trigger, we will also set the Schedule to run daily in the morning.
The Job configuration from the dbt side is done, now the setup begins to become more challenging. We will set a GitHub Action to call the dbt Cloud API once the PR is merged.
Setup a GitHub Action
To setup the GitHub Action, we will first need some information from dbt: Account Id, Job Id, Project Id and API Key.
For the first two, we will navigate to the API tab on the Job Configuration. There, we can find the Account Id and Job Id. We must save these values to be used later on.
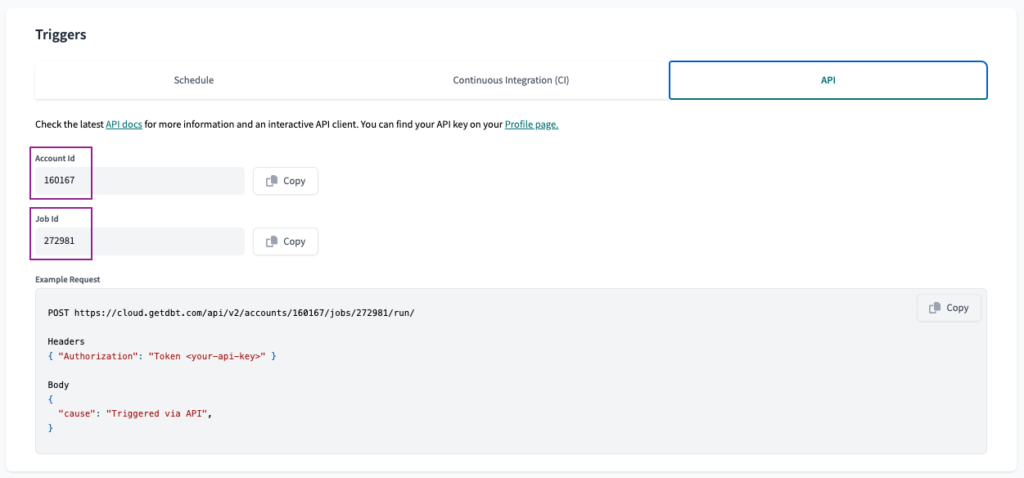
On the same page, we will look for the URL. There we can find the Project ID.

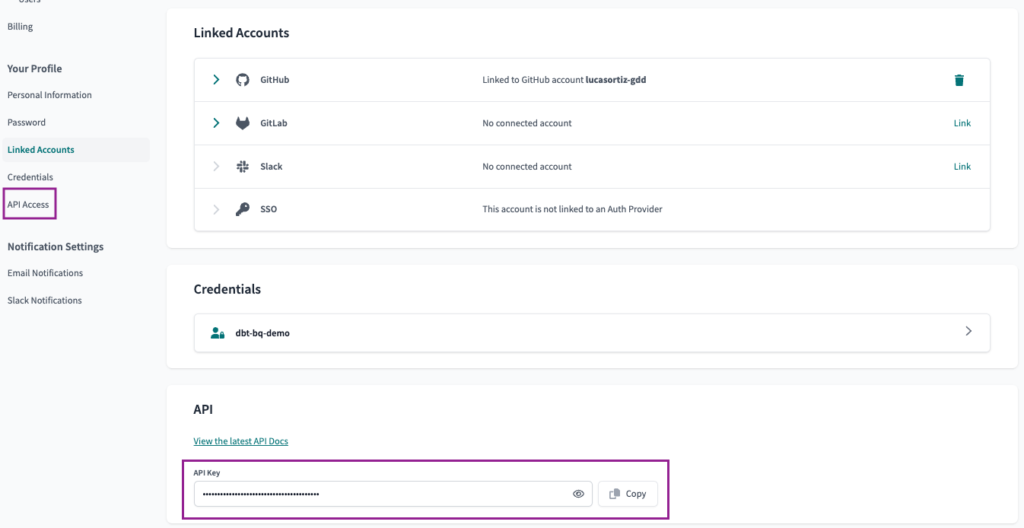
Finally, we will navigate to the API Access page under the Account Settings option. There we can find the API Key value.
With all four parameters in hand, we can head to our GitHub repository to setup the Action.
Once the repository is open, we will navigate to Settings > Secrets and variables > Actions. We will create a New repository secret, naming it DBT_API_KEY and setting it as the API Key value we copied from dbt.
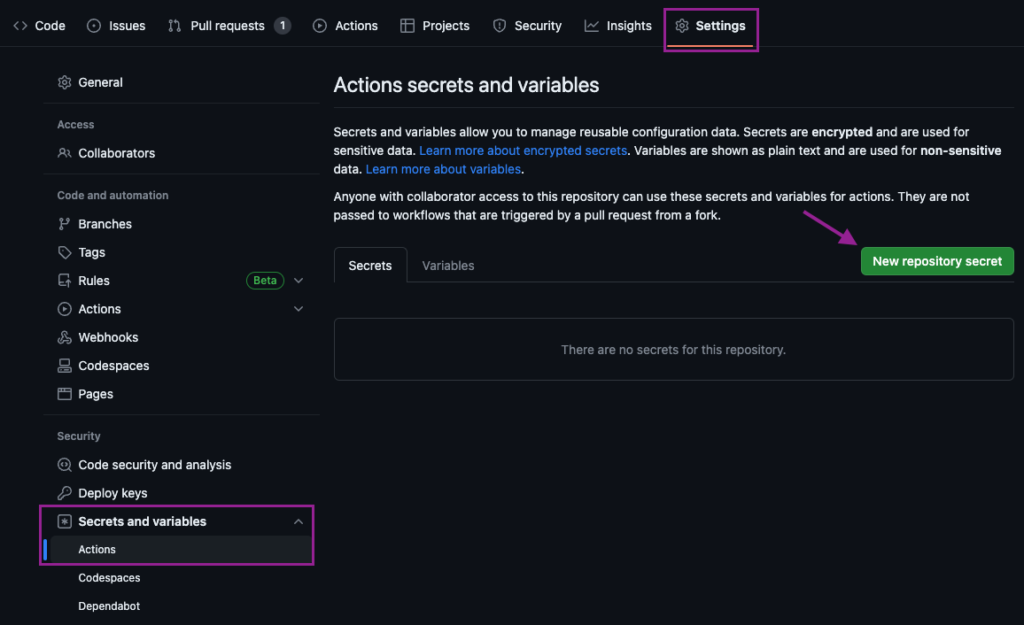
Once it is set, we will navigate to the Variables tab and set the other three values as Variables. Since these values are not sensitive, there is no need to set them as secrets.
DBT_ACCOUNT_IDDBT_JOB_IDDBT_PROJECT_ID
Now, there are only two steps left to finish our setup: Add a python script that will call the API and set the GitHub Action that will run the script. We will perform both on the dbt Develop IDE.
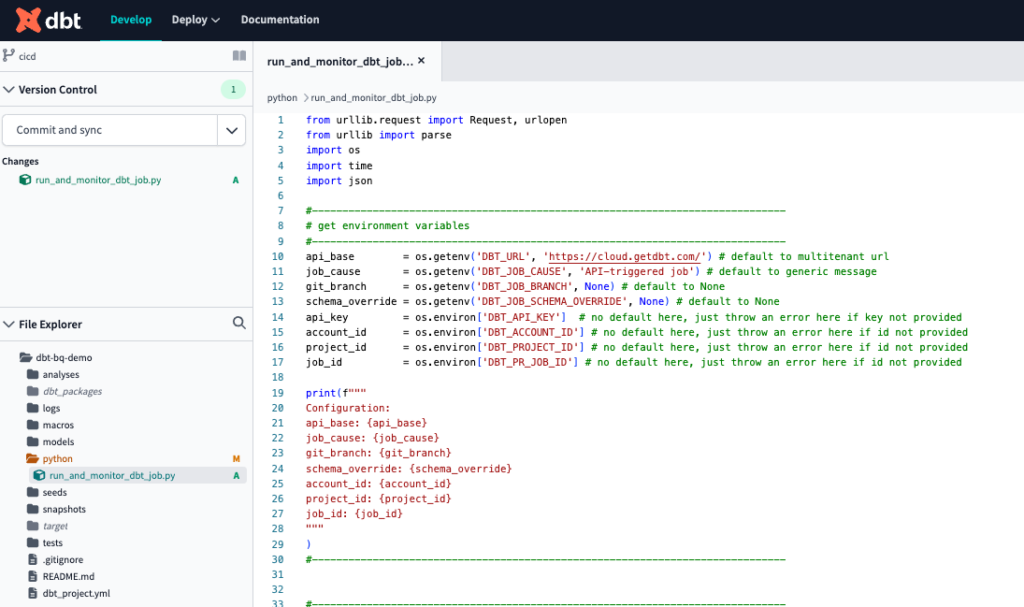
Once it is opened, we will first create a new folder named python. There we can centralize all our python scripts. Inside this folder, we will create a file named run_and_monitor_dbt_job.py. Copy the contents from this gist into the new file. This script has all you need to call the dbt Cloud API, the inputs required are fed within the next step, as environment variables.
The final result should look like this.
The next step is to finally set the GitHub Action.
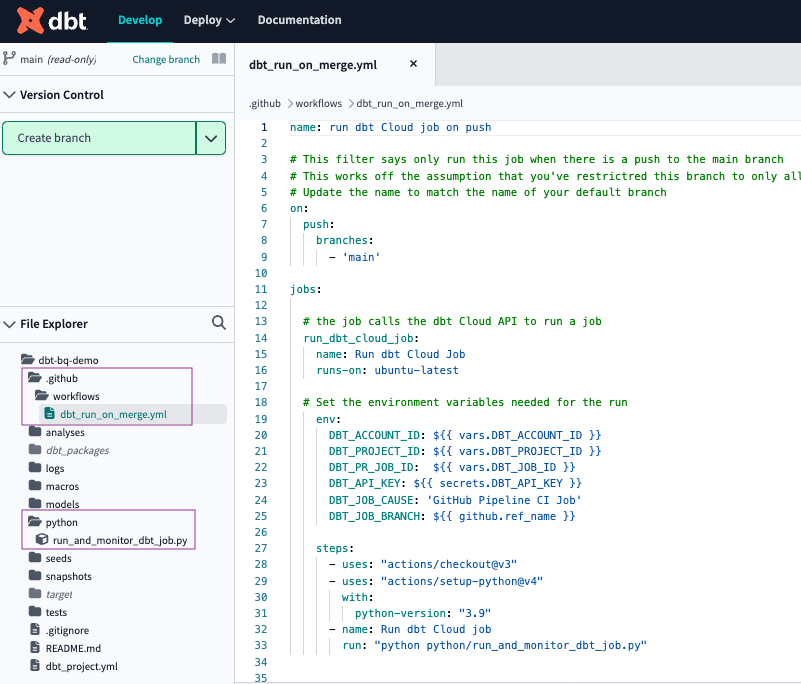
We will first create a folder named .github, with a subfolder named workflows and a file named dbt_run_on_merge.yml. Copy the following code and paste it into the new file. Since it is connected with the secrets and variables, you don't have to edit it.
name: run dbt Cloud job on push
# This filter says only run this job when there is a push to the main branch
# This works off the assumption that you've restricted this branch to only all PRs to push to the default branch
# Update the name to match the name of your default branch
on:
push:
branches:
- 'main'
jobs:
# the job calls the dbt Cloud API to run a job
run_dbt_cloud_job:
name: Run dbt Cloud Job
runs-on: ubuntu-latest
# Set the environment variables needed for the run
env:
DBT_ACCOUNT_ID: ${{ vars.DBT_ACCOUNT_ID }}
DBT_PROJECT_ID: ${{ vars.DBT_PROJECT_ID }}
DBT_PR_JOB_ID: ${{ vars.DBT_JOB_ID }}
DBT_API_KEY: ${{ secrets.DBT_API_KEY }}
DBT_JOB_CAUSE: 'GitHub Pipeline CI Job'
DBT_JOB_BRANCH: ${{ github.ref_name }}
steps:
- uses: "actions/checkout@v3"
- uses: "actions/setup-python@v4"
with:
python-version: "3.9"
- name: Run dbt Cloud job
run: "python python/run_and_monitor_dbt_job.py"
Finally, this is what your project should look like, with the new folders and files.
Now, all that is left is to create a Pull Request with our newly-made changes, Merge it and wait for the magic to happen!
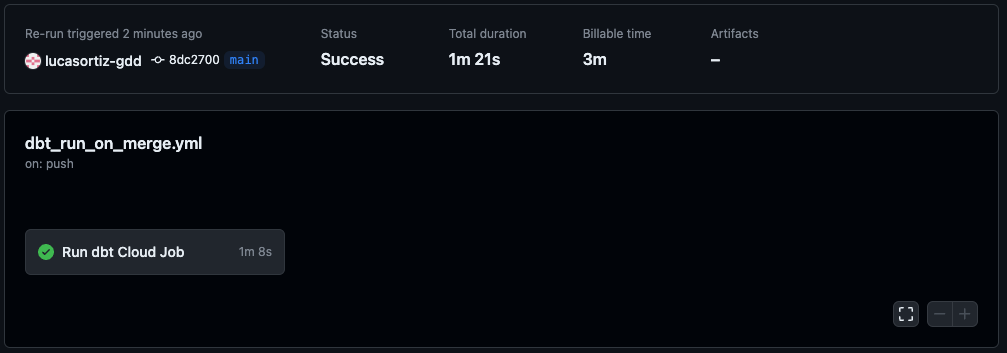
You can check if the run succeeded both on GitHub, under the Actions tab or on dbt, under the Jobs tab.
GitHub Actions
dbt Jobs

Conclusion
As Analytics Engineers, we can significantly simplify our jobs by implementing a CI/CD pipeline. With this pipeline, we no longer have to worry about the manual effort required for deployment and testing. The CI job detects errors or issues that may occur in the code, enabling us to deliver with confidence to different environments. Once a Pull Request is merged, this automation triggers automatically, freeing up our time to focus on our main responsibility of data modeling and analysis.
Written by
Lucas Ortiz
I've always been fascinated by technology and problem-solving. Great challenges are what keep me motivated, I rarely accept that a task can’t be done, it’s only a matter of finding new paths to solve the puzzle.




Contact