Blog
Schreiben Sie weniger schrecklichen Code mit Jupyter Notebook

Jupyter Notebook (oder Lab) eignet sich hervorragend für das Prototyping, aber nicht wirklich für das Schreiben von gutem Code. Ich liebe Notebooks zum Ausprobieren neuer Dinge, zum Plotten, zum Dokumentieren meiner Forschung und als Lernwerkzeug. Allerdings helfen sie Ihnen nicht wie eine IDE, z.B. beim Code-Linting und Refactoring. Notebooks, die von Datenwissenschaftlern geschrieben werden, sind berüchtigt dafür, unlesbar, nicht reproduzierbar und voller Fehler zu sein; wie können wir sie dazu bringen, besseren Code zu schreiben?
Eine Lösung, um weniger schrecklichen Code in Notebooks zu schreiben, besteht darin, nur eine IDE zu verwenden und keinen Code in Notebooks zu schreiben. Aber wäre es nicht toll, wenn Sie sowohl die Unterstützung einer IDE als auch die Interaktivität eines Notebooks nutzen könnten?
TL;DR
- Verschieben Sie Ihren Code aus Ihrem Notebook in ein Python-Paket.
- Installieren Sie das Paket in Ihrer virtuellen Umgebung im Entwicklungsmodus.
- Verwenden Sie die Magie von
%autoreload, um aktualisierten Code automatisch wieder zu importieren.
Das Problem
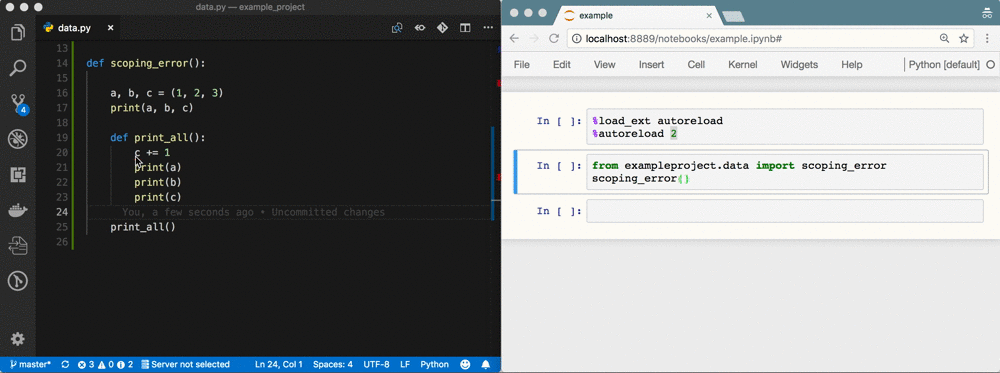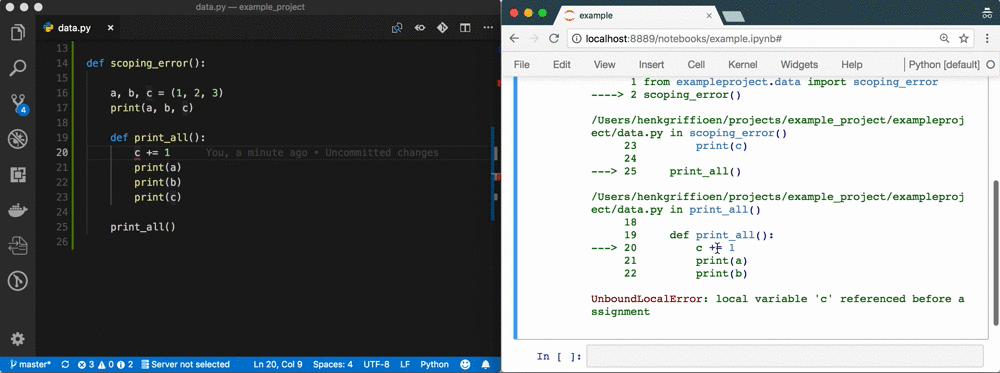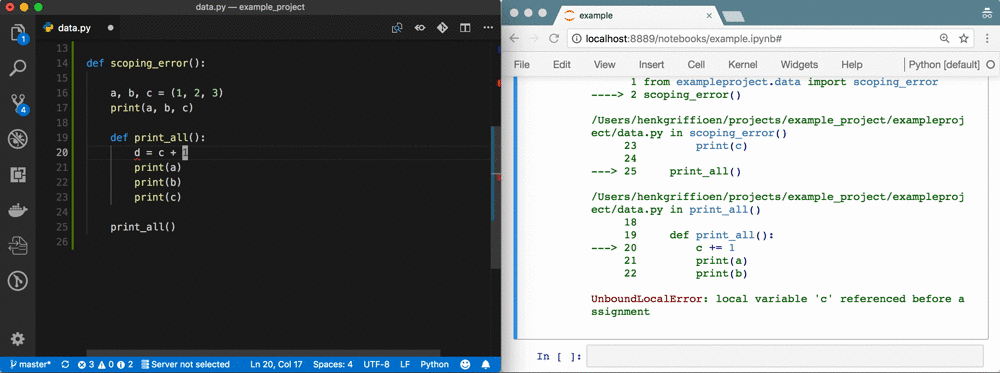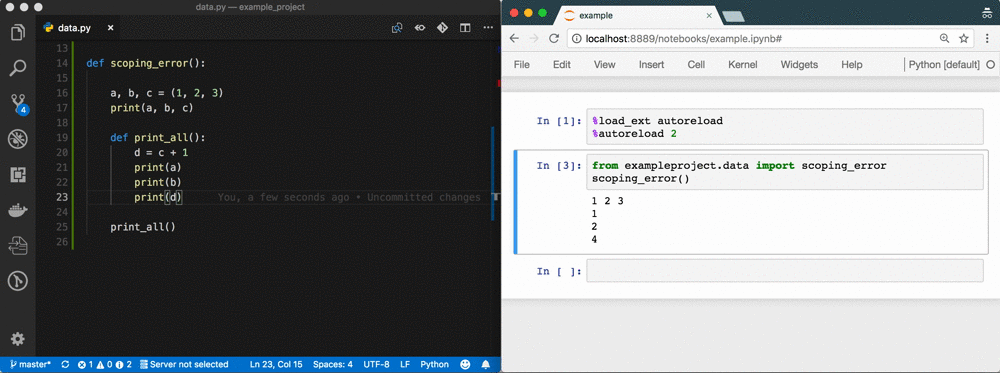
Das Ergebnis einer Woche Data Sciencing sind oft seitenweise Spaghetti-Code in einem Notebook namens Untitled4.ipynb. Der Code wurde in das gesamte Notizbuch kopiert; Abkürzungen werden für Variablennamen verwendet; es werden Variablen verwendet, die nicht mehr existieren oder aus dem falschen Bereich stammen; es gibt keine Reproduzierbarkeit aufgrund eines nicht-linearen Ablaufs
Traumhaftes Konferenzprogramm für Data Science/Engineering pic.twitter.com/qnIY3qicRT
- Vicki Boykis (@vboykis) 16. November 2017
Wir können Nummer 9 reparieren!
Wie kommt es dazu? Datenwissenschaft ist oft ein explorativer Prozess, um eine Idee zu validieren, und das Schreiben von Code ist eines der Werkzeuge der Wissenschaft. Vergleichen Sie dies mit dem Ingenieurwesen, wo das Schreiben von hochwertigem Code eine der Hauptanforderungen ist - die genaue Implementierung kann auch unbekannt sein, aber der Code muss solide sein.
In einer perfekten Welt würden Datenwissenschaftler Modelle erstellen und natürlich hochwertigen Code entwickeln, aber der Prozess und die verwendeten Tools sind nicht immer hilfreich.
1. Vom Notebook zum Paket
Um über das Prototyping hinauszugehen, sollten Sie Ihre Sammlung von Notebooks in ein ordentliches, gut strukturiertes Python-Paket umwandeln. Meine Projekte sehen in der Regel etwa so aus:
example_project/
├── notebooks/ <-- Jupyter notebooks.
└── Untitled4.ipynb
├── exampleproject/ <-- Python package with source code.
└── __init__.py <-- Make the folder a package.
└── example.py <-- Example module in the package.
└── setup.py <-- Install and distribute your module.Das Prototyping findet zunächst in den Ordnern notebooks/ statt, aber die meiste Logik wird in das Paket exampleproject verlagert, wenn die Ideen validiert werden und die Gesamtstruktur klarer wird.
Eine IDE wie PyCharm oder Visual Studio Code kann Sie bei der Entwicklung von Code unterstützen. Diese Editoren warnen Sie im Voraus, wenn Sie einen Fehler machen, und helfen Ihnen beim Code-Stil, beim Refactoring usw. Notebooks hingegen sind nicht so intelligent und warnen Sie nur, wenn Sie etwas wirklich Seltsames mit der Syntax anstellen, oder beschweren sich, nachdem Sie den Code ausgeführt haben.
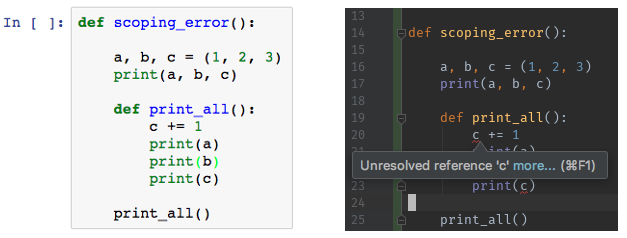
IDEs glänzen wirklich, wenn Ihr Code als Python-Paket strukturiert ist. Das ist die Struktur, die sie erwarten und verstehen. Sie werden also wirklich davon profitieren, wenn Sie ihn richtig organisieren.2.
2. Verwendung Ihres Pakets in einem Notebook
Das Bearbeiten von Code in einer IDE ist schön, aber Sie möchten Ihre Funktionen auch in einem Notebook aufrufen und testen, ob alles funktioniert. Um Ihr Paket für Ihr Notebook verfügbar zu machen, aktivieren Sie die virtuelle Umgebung von conda example_venv und installieren das Paket im Ordner exampleproject/:
$ pwd
~/example_project
$ conda activate example_venv
$ pip install --editable .
running develop
...
Finished processing dependencies for exampleproject==0.0.1Die setup.py enthält Anweisungen für pip zur Installation des Pakets in example_venv3. Wenn Sie es durch die Installation verfügbar machen, ersparen Sie sich unangenehme Dinge wie sys.path.append('../'). Mit der Option --editable können Sie Ihren Code bearbeiten, ohne das Paket neu zu installieren, um die Änderungen zu übernehmen.
Sie können Ihr Paket nun in Ihr Notebook importieren:
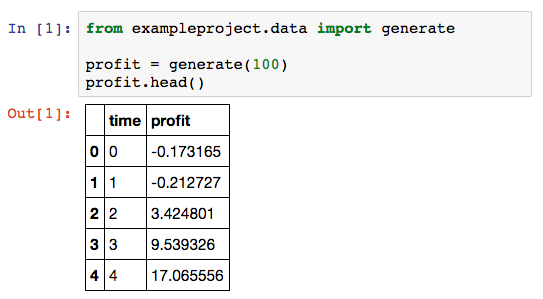
Ein Nachteil der Verwendung eines Pakets ist, dass Sie den Kernel neu starten müssen, wenn Sie den Bibliothekscode ändern. Obwohl Sie nun die Leistungsfähigkeit einer IDE haben, fehlt Ihnen die Interaktivität des Notebooks. Wir brauchen nur noch einen weiteren Schritt, um das zu beheben.
3. Die %autoreload Magie
Wie können Sie die Interaktivität zurückgewinnen und unsere Änderungen sofort in unserem Notizbuch anzeigen lassen? Fügen Sie %autoreload oben in Ihrem Notizbuch hinzu:
%laden_ext automatisch laden # Laden Sie die Erweiterung %automatisch laden 2 # Alle Module automatisch laden
%autoreload ist eine Jupyter-Erweiterung, die Module neu lädt, bevor Sie Ihren Code ausführen. Funktionen und Klassen, die in Notebooks geladen sind, werden jedes Mal aktualisiert, wenn Sie eine Zelle ausführen. Das heißt, wenn Sie neuen Code im Editor speichern, werden die Änderungen sofort in Ihr Notebook geladen, wenn Sie eine Zelle ausführen4.
Mit %autoreload überbrücken Sie die Lücke zwischen Notebook und IDE 5. Sie erhalten alle Vorteile einer IDE, sind aber immer noch so flexibel wie zuvor! Sehen Sie sich das GIF oben als Beispiel an.
Fazit
Notebooks haben nicht die Funktionalität von IDEs, aber das bedeutet nicht, dass wir sie bei der Codeentwicklung nicht verwenden können! Der Package-and-Autoreload-Flow kann Data Scientists dabei helfen, Prototyp-Code leichter in Produktionscode umzuwandeln. In meinem Repo finden Sie ein Beispiel für die Struktur eines Data Science-Projekts und in meinem früheren Blog die grundlegenden Komponenten eines Projekts.
Ein großes Lob an Diederik für die Rezension dieses Blogs!
Lernen Sie Spark oder Python in nur einem Tag
Entwickeln Sie Ihre Data Science-Fähigkeiten. **Online**, unter Anleitung am 23. oder 26. März 2020, 09:00 - 17:00 CET.
Verbessern Sie Ihre Python-Kenntnisse, lernen Sie von den Experten!
Bei GoDataDriven bieten wir eine Vielzahl von Python-Kursen für Anfänger und Experten an, die von den besten Fachleuten auf diesem Gebiet unterrichtet werden. Kommen Sie zu uns und verbessern Sie Ihr Python-Spiel:
- Python Essentials - Ideal, wenn Sie gerade erst mit Python anfangen.
- Data Science with Python Foundation - Möchten Sie den Schritt von der Datenanalyse und -visualisierung zu echter Datenwissenschaft machen? Dies ist der richtige Kurs.
- Advanced Data Science with Python - Lernen Sie, Ihre Modelle wie ein Profi zu produzieren und Python für maschinelles Lernen zu verwenden.
- Siehe diesen Twitter-Thread von Jake Vanderplas und diese Magie, um einen linearen Verlauf zu erzeugen. - Zum Beispiel gibt es im Projektstamm nur ein Python-Paket im Projektordner und dieser Ordner enthält kein
__init__.py.
- Oder verwenden Sie python setup.py develop --no-deps (lesen Sie die Dokumentation).
- Wenn Sie keine Lust haben, %autoreload zu jedem Notebook hinzuzufügen, fügen Sie es zu Ihrem IPython-Profil hinzu.
- Verwenden Sie %autoreload jedoch nicht in Ihrem Produktionscode! Es können alle möglichen unangenehmen Dinge passieren. Verfasst von
Henk Griffioen
Unsere Ideen
Weitere Blogs




Contact