Blog
Arbeiten mit mehreren Partitionsformaten innerhalb einer Hive-Tabelle mit Spark

Problemstellung und warum ist dies interessant
Eingehende Daten liegen in der Regel in einem anderen Format vor, als wir es für die langfristige Speicherung wünschen. Der erste Schritt, den wir normalerweise tun, ist die Umwandlung der Daten in ein Format wie Parquet, das von Hive/Impala leicht abgefragt werden kann.
Der Anwendungsfall, den wir uns vorgestellt haben, ist das Einlesen von Daten im Avro-Format. Die Benutzer möchten einfachen Zugriff auf die Daten mit Hive oder Spark. Um performante Abfragen zu haben, müssen die historischen Daten im Parquet-Format vorliegen. Wir möchten nicht zwei verschiedene Tabellen haben: eine für die historischen Daten im Parquet-Format und eine für die eingehenden Daten im Avro-Format. Wir bevorzugen eine Tabelle, die alle Daten verarbeiten kann, unabhängig vom Format. Auf diese Weise können wir unseren Konvertierungsprozess (von Avro zu Parquet) beispielsweise jede Nacht durchführen, aber die Benutzer hätten trotzdem jederzeit Zugriff auf alle Daten.
In Hive können Sie dies mit einer partitionierten Tabelle erreichen, bei der Sie das Format der einzelnen Partitionen festlegen können. Spark implementiert dies leider nicht. Da unsere Benutzer auch Spark verwenden, war dies etwas, das wir beheben mussten. Dies war auch eine schöne Herausforderung für ein paar Xebia Freitage, bei denen wir mehr über die Interna von Apache Spark lernen konnten.
Lernen Sie Spark oder Python in nur einem Tag
Entwickeln Sie Ihre Data Science-Fähigkeiten. **Online**, unter Anleitung am 23. oder 26. März 2020, 09:00 - 17:00 CET.
Einrichten einer Testumgebung
Zunächst mussten wir herausfinden, was wir brauchen, um das Problem reproduzieren zu können. Wir benötigten die folgenden Komponenten:- Hive mit persistenter Hive-Metaspeicher
- Hadoop, um die Dateien speichern und darauf zugreifen zu können
- Funke
$ brew install hadoop $ brew install hive $ brew install apache-spark $ mkdir ${HOME}/localhdfs
$ docker pull krisgeus/docker-hive-metastore-postgresql:upgrade-2.3.0 $ docker run -p 5432:5432 krisgeus/docker-hive-metastore-postgresql:upgrade-2.3.0
- Laden Sie postgresql-42.2.4.jar von diesem Link herunter
- Fügen Sie dieses jar zum Hive lib Verzeichnis hinzu (in unserem Fall war die Hive Version 2.3.1)
$ cp postgresql-42.2.4.jar /usr/local/Cellar/hive//libexec/lib.
- Erstellen Sie ein Arbeitsverzeichnis
$ mkdir ${HOME}/spark-hive-schema $ cd ${HOME}/spark-hive-schema
- Erstellen Sie ein Konfigurationsverzeichnis und kopieren Sie die Basis-Konfigurationen von Hadoop und Hive
$ mkdir hadoop_conf $ cp -R /usr/local/Cellar/hadoop/3.0.0/libexec/etc/hadoop/* ${HOME}/spark-hive-schema/hadoop_conf $ cp -R /usr/local/Cellar/hive/2.3.1/libexec/conf/* ${HOME}/spark-hive-schema/hadoop_conf $ cp conf/hive-default.xml.template ${HOME}/spark-hive-schema/hadoop_conf/hive-site.xml
- Ändern Sie die Konfigurationen in der Datei hive-site.xml, damit wir den soeben gestarteten Hive Metastore tatsächlich verwenden
system:java.io.tmpdir /tmp/hive/java system:benutzer.name ${benutzer.name} hive.metastore.warehouse.dir ${user.home}/localhdfs/user/hive/warehouse Speicherort der Standarddatenbank für das Lagerhaus javax.jdo.option.ConnectionUserName Bienenstock Benutzername für den Zugriff auf die Metastore-Datenbank javax.jdo.option.ConnectionURL jdbc:postgresql://localhost:5432/metastore JDBC-Verbindungszeichenfolge für einen JDBC-Metaspeicher. Um SSL zur Verschlüsselung/Authentifizierung der Verbindung zu verwenden, geben Sie ein datenbankspezifisches SSL-Flag in der Verbindungs-URL an. Zum Beispiel jdbc:postgresql://myhost/db?ssl=true für die Postgres-Datenbank. datanucleus.connectionPoolingType KEINE Erwartet eine der Optionen [bonecp, dbcp, hikaricp, none]. Geben Sie die Verbindungspool-Bibliothek für datanucleus an javax.jdo.option.ConnectionDriverName org.postgresql.Driver Name der Treiberklasse für einen JDBC-Metaspeicher javax.jdo.option.ConnectionUserName Bienenstock Benutzername für den Zugriff auf die Metastore-Datenbank
- Machen Sie /tmp/hive beschreibbar:
$ chmod 777
/tmp/hive
- Legen Sie in einem Terminal Pfade fest, damit wir HiveServer2 starten können, wobei hadoop_version=3.0.0, hive_version=2.3.1
$ exportieren HADOOP_HOME=/usr/local/Cellar/hadoop//libexec $ export HIVE_HOME=/usr/local/Cellar/hive/ /libexec $ export HADOOP_CONF_DIR=${HOME}/spark-hive-schema/hadoop_conf $ export HIVE_CONF_DIR=${HOME}/spark-hive-schema/hadoop_conf $ hiveserver2
- Legen Sie in einem anderen Terminal die gleichen Pfade fest und starten Sie beeline, wobei hadoop_version=3.0.0, hive_version=2.3.1
$ exportieren HADOOP_HOME=/usr/local/Cellar/hadoop//libexec $ export HIVE_HOME=/usr/local/Cellar/hive/ /libexec $ export HADOOP_CONF_DIR=${HOME}/spark-hive-schema/hadoop_conf $ export HIVE_CONF_DIR=${HOME}/spark-hive-schema/hadoop_conf $ beeline -u jdbc:hive2://localhost:10000/default -n hive -p hive
Erstellen eines Arbeitsbeispiels in Hive
- Erstellen Sie in beeline eine Datenbank und eine Tabelle
CREATE DATENBANK Test; USE Test; CREATE EXTERN TABELLE IF NICHT EXISTS events(eventType STRING, Stadt STRING) GETEILT BY(dt STRING) GESPEICHERT AS PARQUET;
- Zwei Parkettfächer hinzufügen
ALTER TABELLE events ADD TEILUNG (dt='2018-01-25') TEILUNG (dt='2018-01-26'); ALTER TABELLE events TEILUNG (dt='2018-01-25') SETZEN DATEIFORMAT PARQUET; ALTER TABELLE events TEILUNG (dt='2018-01-26') SETZEN DATEIFORMAT PARQUET;
- Fügen Sie eine Partition hinzu, in die wir die Avro-Daten einfügen werden
ALTER TABELLE events ADD TEILUNG (dt='2018-01-27'); ALTER TABELLE events TEILUNG (dt='2018-01-27') SETZEN DATEIFORMAT AVRO;
- Prüfen Sie die Tabelle
SELECT * VON events;
| events.eventtype | ereignisse.stadt | ereignisse.tt |
|---|---|---|
BESCHREIBEN FORMATIERT events TEILUNG (dt="2018-01-26");
| Name der Spalte | Datentyp |
|---|---|
| # Informationen zur Speicherung | |
| SerDe Bibliothek: | org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe |
| InputFormat: | org.apache.hadoop.hive.ql.io.parquet.MapredParquetInputFormat |
| OutputFormat: | org.apache.hadoop.hive.ql.io.parquet.MapredParquetOutputFormat |
BESCHREIBEN FORMATIERT events TEILUNG (dt="2018-01-27");
| Name der Spalte | Datentyp |
|---|---|
| # Informationen zur Speicherung | |
| SerDe Bibliothek: | org.apache.hadoop.hive.serde2.avro.AvroSerDe |
| InputFormat: | org.apache.hadoop.hive.ql.io.avro.AvroContainerInputFormat |
| OutputFormat: | org.apache.hadoop.hive.ql.io.avro.AvroContainerOutputFormat |
- Testdatenverzeichnis erstellen
mkdir ${HOME}/spark-hive-schema/testdata
- Avro-Daten generieren und zur Tabelle hinzufügen
$ Katze ${HOME}/spark-hive-schema/testdata/data.json { "Ereignistyp": "avro", "Stadt": "Breukelen" } { "Ereignistyp": "avro", "Stadt": "Wilnis" } { "Ereignistyp": "avro", "Stadt": "Abcoude" } { "Ereignistyp": "avro", "Stadt": "Vinkeveen" } $ Katze ${HOME}/spark-hive-schema/testdata/data.avsc { "Typ" : "Rekord", "Name" : "Ereignisse", "Namensraum" : "com.xebia.events", "Felder" : [ { "Name" : "Ereignistyp", "Typ" : "string" }, { "Name" : "Stadt", "Typ" : "string" }] $ brew install avro-tools $ cd ${HOME}/spark-hive-schema/testdata $ avro-tools fromjson --schema-datei data.avsc data.json > ${HOME}/localhdfs/user/hive/warehouse/test.db/events/dt=2018-01-27/data.avro
- Parkettdaten generieren und zur Tabelle hinzufügen
$ cd ${HOME}/spark-hive-schema/testdata $ spark-shell > import org.apache.spark.sql.functions.lit > spark.read.json("data.json").wählen(beleuchtet("Parkett").alias("Ereignistyp"), col("Stadt")).write.parquet("data.pq") > :quit $ cp ./data.pq/part*.parquet ${HOME}/localhdfs/user/hive/warehouse/test.db/events/dt=2018-01-26/
- Einfügen von Daten in die letzte existierende Partition mit beeline
INSERT INTO TABELLE events TEILUNG (dt="2018-01-25") SELECT 'Überschreiben', 'Amsterdam';
- Prüfen Sie, ob wir Daten in beeline haben
SELECT * VON events;
| events.eventtype | ereignisse.stadt | ereignisse.tt |
|---|---|---|
| überschreiben. | Amsterdam | 2018-01-25 |
| Parkett | Breukelen | 2018-01-26 |
| Parkett | Wilnis | 2018-01-26 |
| Parkett | Abcoude | 2018-01-26 |
| Parkett | Vinkeveen | 2018-01-26 |
| avro | Breukelen | 2018-01-27 |
| avro | Wilnis | 2018-01-27 |
| avro | Abcoude | 2018-01-27 |
| avro | Vinkeveen | 2018-01-27 |
- Prüfen Sie, ob die Formate korrekt sind
$ Baum ${HOME}/localhdfs/user/hive/warehouse/test.db/events .../localhdfs/user/hive/warehouse/test.db/events ├── dt=2018-01-25 │ └── 000000_0 ├── dt=2018-01-26 │ └── part-00000-1846ef38-ec33-47ae-aa80-3f72ddb50c7d-c000.snappy.parquet └── dt=2018-01-27 └── data.avro
Erstellen eines fehlgeschlagenen Tests in Spark
Verbinden Sie sich mit Spark und stellen Sie sicher, dass wir auf den Hive Metastore zugreifen, den wir eingerichtet haben:$ exportieren HADOOP_HOME=/usr/local/Cellar/hadoop//libexec $ export HIVE_HOME=/usr/local/Cellar/hive/ /libexec $ export HADOOP_CONF_DIR=${HOME}/spark-hive-schema/hadoop_conf $ export HIVE_CONF_DIR=${HOME}/spark-hive-schema/hadoop_conf $ spark-shell --driver-class-path /usr/local/Cellar/hive/2.3.1/libexec/lib/postgresql-42.2.4.jar --jars /usr/local/Cellar/hive/2.3.1/libexec/lib/postgresql-42.2.4.jar --conf spark.executor.extraClassPath=/usr/local/Cellar/hive/2.3.1/libexec/lib/postgresql-42.2.4.jar --conf spark.hadoop.javax.jdo.option.ConnectionURL=jdbc:postgresql://localhost:5432/metastore --conf spark.hadoop.javax.jdo.option.ConnectionUserName=hive --conf spark.hadoop.javax.jdo.option.ConnectionPassword=hive --conf spark.hadoop.javax.jdo.option.ConnectionDriverName=org.postgresql.Driver --conf spark.hadoop.hive.metastore.schema.verification=true --conf spark.hadoop.hive.metastore.schema.verification.record.version=true --conf spark.sql.hive.metastore.version=2.1.0 --conf spark.sql.hive.metastore.jars=maven > spark.sql("select * from test.events").show() ... java.lang.RuntimeException: file:...localhdfs/user/hive/warehouse/test.db/events/dt=2018-01-27/data.avro is not a Parquet file. erwartete magische Zahl am Ende [80, 65, 82, 49] aber fand [-126, 61, 76, 121] ...
$ git clone https://github.com/krisgeus/spark.git $ cd Funke $ ./build/sbt "hive/testOnly *HiveSQLViewSuite"
- eine Tabelle mit Partitionen erstellen
- eine Tabelle auf der Basis von Avro-Daten erstellen, die sich in einer Partition der zuvor erstellten Tabelle befindet. Fügen Sie einige Daten in diese Tabelle ein.
- eine Tabelle auf der Basis von Parkettdaten erstellen, die sich in einer anderen Partition der zuvor erstellten Tabelle befindet. Fügen Sie einige Daten in diese Tabelle ein.
- versuchen, die Daten aus der Originaltabelle mit Partitionen zu lesen
$ ./build/sbt "hive/testOnly *MultiFormatTableSuite ... - Hive-Tabelle mit mehrformatigen Partitionen erstellen *** FAILED *** (4 Sekunden, 265 Millisekunden) [info] org.apache.spark.sql.catalyst.parser.ParseException: Operation nicht erlaubt: ALTER TABLE SET FILEFORMAT(Zeile 2, Pos 0) [Info] [info] == SQL == [Info] [info] ALTER TABLE ext_multiformat_partition_table [Info] ^^^ [info] PARTITION (dt='2018-01-26') SET FILEFORMAT PARQUET ...
Ausführungspläne verstehen
Die beste Erklärung, die wir gefunden haben, stammt von der Databricks-Website, dem Artikel Deep Dive into Spark SQL's Catalyst Optimizer . Hier ist ein Auszug, falls Sie nicht den ganzen Artikel lesen möchten:Das Herzstück von Spark SQL ist der Catalyst-Optimierer, der fortschrittliche Funktionen der Programmiersprache (z.B. Scalas Pattern-Matching und Quasiquotes) auf eine neuartige Weise nutzt, um einen erweiterbaren Abfrageoptimierer zu erstellen. Wir verwenden das allgemeine Baumtransformations-Framework von Catalyst in vier Phasen, wie unten dargestellt: (1) Analyse eines logischen Plans zur Auflösung von Referenzen, (2) Optimierung des logischen Plans, (3) physische Planung und (4) Codegenerierung zur Kompilierung von Teilen der Abfrage in Java Bytecode. In der physischen Planungsphase kann Catalyst mehrere Pläne generieren und diese anhand der Kosten vergleichen. Alle anderen Phasen sind rein regelbasiert. Jede Phase verwendet unterschiedliche Arten von Baumknoten. Catalyst enthält Bibliotheken mit Knoten für Ausdrücke, Datentypen sowie logische und physische Operatoren.
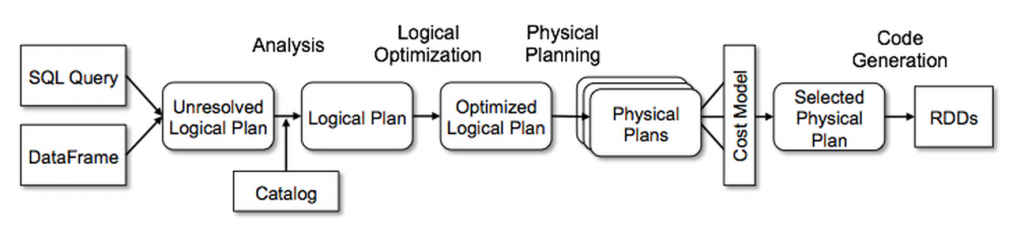
Spark SQL beginnt mit einer zu berechnenden Beziehung, entweder aus einem abstrakten Syntaxbaum (AST), der von einem SQL-Parser zurückgegeben wird, oder aus einem DataFrame-Objekt, das mit der API erstellt wurde. Spark SQL verwendet Catalyst-Regeln und ein Catalog-Objekt, das die Tabellen in allen Datenquellen verfolgt, um diese Attribute aufzulösen. Zunächst wird ein Baum mit ungebundenen Attributen und Datentypen erstellt, der als "ungelöster logischer Plan" bezeichnet wird, und dann werden Regeln angewendet, die Folgendes bewirken: Nachschlagen von Relationen nach Namen aus dem Katalog. Zuordnen von benannten Attributen, wie z.B. col, zu den Kindern des Operators. Bestimmen, welche Attribute sich auf denselben Wert beziehen, um ihnen eine eindeutige ID zu geben (was später die Optimierung von Ausdrücken wie col = col ermöglicht). Weitergeben und Erzwingen von Typen durch Ausdrücke: Wir können z.B. den Rückgabetyp von 1 + col nicht kennen, bevor wir col aufgelöst und möglicherweise seine Unterausdrücke in kompatible Typen gecastet haben. Die logische Optimierungsphase wendet standardmäßige regelbasierte Optimierungen auf den logischen Plan an. Dazu gehören das Falten von Konstanten, das Herunterdrücken von Prädikaten, das Pruning von Projektionen, die Nullpropagation, die Vereinfachung boolescher Ausdrücke und andere Regeln. In der physischen Planungsphase generiert Spark SQL aus einem logischen Plan einen oder mehrere physische Pläne, wobei physische Operatoren verwendet werden, die zur Spark-Ausführungsmaschine passen. Anschließend wählt es einen Plan anhand eines Kostenmodells aus. Derzeit wird die kostenbasierte Optimierung nur für die Auswahl von Join-Algorithmen verwendet: Für Beziehungen, von denen bekannt ist, dass sie klein sind, verwendet Spark SQL einen Broadcast-Join unter Verwendung einer in Spark verfügbaren Peer-to-Peer-Broadcast-Funktion. Das Framework unterstützt jedoch eine breitere Nutzung der kostenbasierten Optimierung, da die Kosten rekursiv für einen ganzen Baum mithilfe einer Regel geschätzt werden können. Wir beabsichtigen daher, in Zukunft eine umfassendere kostenbasierte Optimierung zu implementieren. Der physische Planer führt auch regelbasierte physische Optimierungen durch, wie z.B. das Pipelining von Projektionen oder Filtern in einer Spark-Map-Operation. Außerdem kann er Operationen aus dem logischen Plan in Datenquellen schieben, die Prädikat oder Projektion Pushdown unterstützen. Wir werden die API für diese Datenquellen in einem späteren Abschnitt beschreiben. Die letzte Phase der Abfrageoptimierung umfasst die Generierung von Java-Bytecode, der auf den einzelnen Rechnern ausgeführt wird.
Unterstützung für die Einstellung des Formats einer Partition in einer Hive-Tabelle mit Spark
Zunächst mussten wir feststellen, dass Spark ANTLR verwendet, um seinen SQL-Parser zu generieren. ANTLR ANother Tool for Language Recognition kann eine Grammatik erzeugen, die aufgebaut und ausgeführt werden kann. Die Grammatik für Spark ist in SqlBase.g4 angegeben. Wir müssen also FILEFORMAT für den Fall unterstützen, dass eine Partition gesetzt ist. Daher mussten wir die folgende Zeile in SqlBase.g4 hinzufügen.| ALTER TABLE tableIdentifier (partitionSpec)? SET FILEFORMAT fileFormat
/** * Erstellen Sie einen [[AlterTableFormatPropertiesCommand]]-Befehl. * * Zum Beispiel: * {{{ * ALTER TABLE table [PARTITION spec] SET FILEFORMAT format; * }}} */ Überschreiben Sie def visitSetTableFormat(ctx: SetTableFormatContext): LogicalPlan = withOrigin(ctx) { val Format = (ctx.fileFormat) Spiel { // Erwartetes Format: INPUTFORMAT input_format OUTPUTFORMAT output_format Fall (c: TableFileFormatContext) => visitTableFileFormat(c) // Erwartetes Format: SEQUENCEFILE | TEXTFILE | RCFILE | ORC | PARQUET | AVRO Fall (c: GenericFileFormatContext) => visitGenericFileFormat(c) Fall _ => werfen neu ParseException("Erwartet GESPEICHERT ALS ", ctx) } AlterTableFormatCommand( visitTableIdentifier(ctx.tableIdentifier), Format, // TODO eine Partitionsspezifikation darf optionale Werte haben. Dies wird derzeit nicht eingehalten. Option(ctx.partitionSpec).Karte(visitNonOptionalPartitionSpec)) }
/** * Ein Befehl, der das Format einer Tabelle/View/Partition festlegt. * * Die Syntax dieses Befehls lautet: * {{{ * ALTER TABLE table [PARTITION spec] SET FILEFORMAT format; * }}} */ Fall Klasse AlterTableFormatCommand( tableName: TableIdentifier, Format: CatalogStorageFormat, partSpec: Option[TablePartitionSpec]) erweitert RunnableCommand { Überschreiben Sie def laufen(sparkSession: SparkSession): Seq[Reihe] = { val Katalog = sparkSession.sessionState.Katalog val Tabelle = Katalog.getTableMetadata(tableName) DDLUtils.verifyAlterTableType(Katalog, Tabelle, isView = false) // Für Datenquellentabellen ist die Einstellung von serde oder die Angabe der Partition nicht zulässig wenn (partSpec.isDefined && DDLUtils.isDatasourceTable(Tabelle)) { werfen neu AnalysisException("Operation nicht erlaubt: ALTER TABLE SET FILEFORMAT " + "für eine bestimmte Partition wird nicht unterstützt " + "für Tabellen, die mit der Datenquellen-API erstellt wurden") } wenn (partSpec.isEmpty) { val newTable = Tabelle.withNewStorage( serde = Format.serde.orElse(Tabelle.Lagerung.serde), inputFormat = Format.inputFormat.orElse(Tabelle.Lagerung.inputFormat), outputFormat = Format.outputFormat.orElse(Tabelle.Lagerung.outputFormat), Eigenschaften = Tabelle.Lagerung.Eigenschaften ++ Format.Eigenschaften) Katalog.alterTable(newTable) } sonst { val spec = partSpec.erhalten. val Teil = Katalog.getPartition(Tabelle.Kennung, spec) val newPart = Teil.kopieren(Lagerung = Teil.Lagerung.kopieren( serde = Format.serde.orElse(Teil.Lagerung.serde), inputFormat = Format.inputFormat.orElse(Tabelle.Lagerung.inputFormat), outputFormat = Format.outputFormat.orElse(Tabelle.Lagerung.outputFormat), Eigenschaften = Teil.Lagerung.Eigenschaften ++ Format.Eigenschaften)) Katalog.alterPartitions(Tabelle.Kennung, Seq(newPart)) } Seq.leer[Reihe] } }
Überraschung: Unterschiede im Ausführungsplan...
Wir haben herumgespielt und versehentlich das Format der partitionierten Tabelle in Avro geändert, so dass wir eine Avro-Tabelle mit einer Parquet-Partition darin hatten...und ES FUNKTIONIERTE!!! Wir konnten alle Daten lesen... aber Moment, was?!!? Eine Avro-Tabelle mit einer Parquet-Partition funktioniert also, eine Parquet-Tabelle mit einer Avro-Partition aber nicht? Worin besteht der Unterschied? Schauen wir uns die Ausführungspläne an:- Ausführungsplan für die Parkett-Tabelle mit Avro-Partitionen
[ { "Klasse" : "org.apache.spark.sql.execution.ProjectExec", "num-children" : 1, "projectList" : [ [ { "Klasse" : "org.apache.spark.sql.catalyst.expressions.AttributeReference", ... "Qualifier" : "ext_parquet_partition_table" } ], [ { "Klasse" : "org.apache.spark.sql.catalyst.expressions.AttributeReference", ... "Qualifier" : "ext_parquet_partition_table" } ] ], "Kind" : 0 }, { "Klasse" : "org.apache.spark.sql.execution.FileSourceScanExec", "num-children" : 0, "Beziehung" : null, "Ausgabe" : [ [ { "Klasse" : "org.apache.spark.sql.catalyst.expressions.AttributeReference", ... } ], [ { "Klasse" : "org.apache.spark.sql.catalyst.expressions.AttributeReference", ... } ], [ { "Klasse" : "org.apache.spark.sql.catalyst.expressions.AttributeReference", ... } ] ], "requiredSchema" : { "Typ" : "Struktur", "Felder" : [ { "Name" : "Schlüssel", "Typ" : "Ganzzahl", "löschbar" : true, "Metadaten" : { } }, { "Name" : "Wert", "Typ" : "string", "löschbar" : true, "Metadaten" : { } } ] }, "partitionFilters" : [ ], "dataFilters" : [ ], "tableIdentifier" : { "Produktklasse" : "org.apache.spark.sql.catalyst.TableIdentifier", "Tisch" : "ext_parquet_partition_table", "Datenbank" : "Standard" } } ]
- Ausführungsplan für die Avro-Tabelle mit Parkett-Partitionen
[ { "Klasse" : "org.apache.spark.sql.hive.execution.HiveTableScanExec", "num-children" : 0, "requestedAttributes" : [ [ { "Klasse" : "org.apache.spark.sql.catalyst.expressions.AttributeReference", ... "Qualifier" : "ext_avro_partition_table" } ], [ { "Klasse" : "org.apache.spark.sql.catalyst.expressions.AttributeReference", ... "Qualifier" : "ext_avro_partition_table" } ] ], "Beziehung" : [ { "Klasse" : "org.apache.spark.sql.catalyst.catalog.HiveTableRelation", ... "tableMeta" : { "Produktklasse" : "org.apache.spark.sql.catalyst.catalog.CatalogTable", "Bezeichner" : { "Produktklasse" : "org.apache.spark.sql.catalyst.TableIdentifier", "Tisch" : "ext_avro_partition_table", "Datenbank" : "Standard" }, "tableType" : { "Produktklasse" : "org.apache.spark.sql.catalyst.catalog.CatalogTableType", "Name" : "EXTERN" }, "Lagerung" : { "Produktklasse" : "org.apache.spark.sql.catalyst.catalog.CatalogStorageFormat", "locationUri" : null, "inputFormat" : "org.apache.hadoop.hive.ql.io.avro.AvroContainerInputFormat", "outputFormat" : "org.apache.hadoop.hive.ql.io.avro.AvroContainerOutputFormat", "serde" : "org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe", "komprimiert" : false, "Eigenschaften" : null }, "schema" : { "Typ" : "Struktur", "Felder" : [ { "Name" : "Schlüssel", "Typ" : "Ganzzahl", "löschbar" : true, "Metadaten" : { } }, { "Name" : "Wert", "Typ" : "string", "löschbar" : true, "Metadaten" : { } }, { "Name" : "dt", "Typ" : "string", "löschbar" : true, "Metadaten" : { } } ] }, "Anbieter" : "Bienenstock", "partitionColumnNames" : "[dt]", "Eigentümer" : "geheim", "createTime" : 1532699365000, "lastAccessTime" : 0, "createVersion" : "2.4.0-SNAPSHOT", "Eigenschaften" : null, "Statistiken" : null, "unsupportedFeatures" : [ ], "tracksPartitionsInCatalog" : true, "schemaPreservesCase" : true, "ignoredProperties" : null, "hasMultiFormatPartitionen" : false }, "dataCols" : [ [ { "Klasse" : "org.apache.spark.sql.catalyst.expressions.AttributeReference", "num-children" : 0, "Name" : "Schlüssel", "dataType" : "Ganzzahl", "löschbar" : true, "Metadaten" : { }, "exprId" : { "Produktklasse" : "org.apache.spark.sql.catalyst.expressions.ExprId", "id" : 25, "jvmId" : "5988f5b1-0966-49ca-a6de-2485d5582464" } } ], [ { "Klasse" : "org.apache.spark.sql.catalyst.expressions.AttributeReference", "num-children" : 0, "Name" : "Wert", "dataType" : "string", "löschbar" : true, "Metadaten" : { }, "exprId" : { "Produktklasse" : "org.apache.spark.sql.catalyst.expressions.ExprId", "id" : 26, "jvmId" : "5988f5b1-0966-49ca-a6de-2485d5582464" } } ] ], "partitionCols" : [ [ { "Klasse" : "org.apache.spark.sql.catalyst.expressions.AttributeReference", "num-children" : 0, "Name" : "dt", "dataType" : "string", "löschbar" : true, "Metadaten" : { }, "exprId" : { "Produktklasse" : "org.apache.spark.sql.catalyst.expressions.ExprId", "id" : 27, "jvmId" : "5988f5b1-0966-49ca-a6de-2485d5582464" } } ] ] } ], "partitionPruningPred" : [ ], "sparkSession" : null } ]
Finden Sie die magische Einstellung
Wir haben noch einmal im Code gegraben und die folgende Methode in HiveStrategien.scala/** * Konvertierung von Relationen aus Metaspeicher-Relationen in Datenquellen-Relationen für bessere Leistung * * - Beim Schreiben in nicht-partitionierte Hive-serde Parquet/Orc-Tabellen * - Beim Scannen von Hive-serde Parkett/ORC-Tabellen * * Diese Regel muss vor allen anderen DDL-Post-Hoc-Auflösungsregeln ausgeführt werden, d.h. *PreprocessTableCreation,PreprocessTableInsertion,DataSourceAnalysisundHiveAnalysis. */ Fall Klasse RelationConversions( conf: SQLConf, sessionCatalog: HiveSessionCatalog) erweitert Regel[LogicalPlan] { privat def isConvertible(Beziehung: HiveTableRelation): Boolesche = { val serde = Beziehung.tableMeta.Lagerung.serde.getOrElse("").toLowerCase(Lokales.ROOT) serde.enthält("Parkett") && conf.getConf(HiveUtils.CONVERT_METASTORE_PARQUET) || serde.enthält("Ork") && conf.getConf(HiveUtils.CONVERT_METASTORE_ORC) } ...
false zu setzen, was bedeutet, dass wir die Datenquellenbeziehungen nicht optimieren, wenn wir das Partitionsdateiformat ändern.
Wir haben dies simuliert, indem wir die folgende Zeile zu unserem Unit-Test hinzugefügt haben:
withSQLConf(HiveUtils.CONVERT_METASTORE_PARQUET.key -> "falsch")
Implementieren Sie die Unterstützung von Partitionen mit mehreren Formaten, ohne Optimierungen manuell zu deaktivieren.
Wir haben beschlossen, eine Immobilie hinzuzufügen,hasMultiFormatPartitions zur CatalogTable, die widerspiegelt, ob wir eine Tabelle mit mehreren verschiedenen Formaten in ihren Partitionen haben. Dies musste in HiveClientImpl.scala durchgeführt werden
Die folgende Zeile hat es geschafft:
hasMultiFormatPartitions = Unterlegscheibe.getAllPartitions(Kunde, h).Karte(_.getInputFormatClass).deutlich.Größe > 1
/** * Konvertierung von Relationen aus Metaspeicher-Relationen in Datenquellen-Relationen für bessere Leistung * * - Beim Schreiben in nicht-partitionierte Hive-serde Parquet/Orc-Tabellen * - Beim Scannen von Hive-serde Parkett/ORC-Tabellen * * Diese Regel muss vor allen anderen DDL-Post-Hoc-Auflösungsregeln ausgeführt werden, d.h. *PreprocessTableCreation,PreprocessTableInsertion,DataSourceAnalysisundHiveAnalysis. */ Fall Klasse RelationConversions( conf: SQLConf, sessionCatalog: HiveSessionCatalog) erweitert Regel[LogicalPlan] { privat def isConvertible(Beziehung: HiveTableRelation): Boolesche = { val serde = Beziehung.tableMeta.Lagerung.serde.getOrElse("").toLowerCase(Lokales.ROOT) val hasMultiFormatPartitions = Beziehung.tableMeta.hasMultiFormatPartitions serde.enthält("Parkett") && conf.getConf(HiveUtils.CONVERT_METASTORE_PARQUET) && (!hasMultiFormatPartitions) || serde.enthält("Ork") && conf.getConf(HiveUtils.CONVERT_METASTORE_ORC) } ...
Vertiefen Sie Ihr Wissen über Apache Spark!
Wir bieten einen ausführlichen Kurs zu Data Science mit Spark an, der Data Science im großen Maßstab zu einem Kinderspiel für jeden Datenwissenschaftler, Ingenieur oder Analysten macht!Verfasst von
Kris Geusebroek
Unsere Ideen
Weitere Blogs




Contact