Blog
Verwendung von Parcern in der Praxis

Dieser Beitrag wurde ursprünglich auf 47deg.com am 2. Juni 2021 veröffentlicht.
Für eines unserer Projekte haben wir unsere eigene kleine Sprache entwickelt, anstatt eine Kodierung in einem Serialisierungsformat zu verwenden. Diese Sprache ist von verschiedenen Sprachen abgeleitet, insbesondere von Kotlin und Haskell. Wenn Sie Ihre eigene Sprache entwickeln, müssen Sie zunächst einmal einen Parser schreiben. Aber wie teilen Sie die Grammatik der Sprache? Und, was noch wichtiger ist, wie testen Sie, dass alle Benutzer der Grammatik die gleiche Menge an Programmen einlesen können? Dieser Blogbeitrag beschreibt unseren Weg und die Lektionen, die wir dabei gelernt haben.
Entscheiden Sie sich für Ihre eigene Sprache
Bevor wir in die technischen Details eintauchen, ist es sinnvoll zu verstehen , warum wir überhaupt eine eigene Sprache entwickeln wollten. Schließlich ist es in der Regel eine gute Praxis, das Rad nicht neu zu erfinden, und die Welt ist nicht frei von Computersprachen. Für uns war der entscheidende Punkt, dass unsere Sprache Bindung unterstützen musste, d.h. die Möglichkeit, neue Namen einzuführen und dann auf diese zu verweisen, wie wir es mit Argumenten in Funktionen tun.
Die Teilmenge der Sprachen mit Serialisierungsunterstützung und Bindung ist viel kleiner. Auf der einen Seite gibt es Erweiterungen von Serialisierungssprachen, wie z.B. JsonLogic. Das Hauptproblem bei diesen Ansätzen ist, dass sie für den menschlichen Verzehr nicht sehr geeignet sind und gleichzeitig dazu neigen, ziemlich langatmig zu sein. Hier ist ein Beispiel aus der JsonLogic-Dokumentation:
{"and" : [
{ ">" : [3,1] },
{ "<" : [1,3] }
] }
Auf der anderen Seite des Spektrums haben wir die Lisp-Familie mit ihrer geklammerten Ausdruckskraft. Einige von ihnen, wie
Aber wer kann schon "nein" zu klammernder Schönheit sagen? S-Ausdrücke bieten ein gutes Gleichgewicht zwischen der Wartbarkeit durch den Menschen - manche Menschen schreiben diese Ausdrücke ihr ganzes Berufsleben lang - und der Einfachheit der Produktion, des Parsens und der Interpretation - da komplexere Elemente in menschlichen Sprachen wie z.B. die Rangfolge in Lisp nicht verwendet werden. Der Ausdruck
Die Entwicklung der Grammatik
Sobald die Frage nach der notwendigen Existenz unserer Sprache geklärt ist (vielleicht habe ich in letzter Zeit zu viel Philosophize This gehört, aber es ist sooooo gut), ist es an der Zeit, die Sprache zu beschreiben und den entsprechenden Parser zu erzeugen. Eines der bekanntesten Tools in diesem Bereich ist
ANTLR folgt dem traditionellen Ansatz, die Grammatik in zwei Teile zu unterteilen: den Lexer (oder Tokenizer) und den Parser. Ersterer kümmert sich darum, zu erkennen, was ein Schlüsselwort, was eine Zahl, was eine Variable ist, während letzterer beschreibt, wie diese Elemente (die sogenannten Token) zusammengesetzt werden. In der menschlichen Grammatik ausgedrückt, erkennt der Lexer die Wörter, der Parser erkennt die Sätze. Folglich "zweifelt" der Lexer nie - if ist ein Schlüsselwort, kein Variablenname - während ein Parser mehrere Kombinationen ausprobieren kann, bevor er aufgibt.
Hier ist der Lexer-Teil einer kleinen Grammatik - in ANTLR verwenden wir ALL_CAPITALS für diese. Zunächst beschreiben wir, wie Kommentare in unserer Sprache aussehen, und weisen ANTLR an, diesen Teil zu überspringen. Dann definieren wir ein paar Schlüsselwörter. Schließlich beschreiben wir, wie ein Symbol aussieht, indem wir einen regulären Ausdruck verwenden: ein Buchstabe oder Unterstrich gefolgt von null oder mehr Buchstaben aus SYM_CHAR.
grammar Thingy;
LINE_COMMENT : '//' ~[rn]* -> skip;
THEN : 'then' ;
ELSE : 'else' ;
IF : 'if' ;
ADD : '+' ;
MULTIPLY : '*' ;
SYMBOL : INITIAL_SYM_CHAR SYM_CHAR* ;
fragment INITIAL_SYM_CHAR : [a-zA-Z_] ;
fragment SYM_CHAR : [a-zA-Z0-9_.%#$'] ;
Sobald wir die Wörter haben, können wir die Sätze beschreiben. Diese kleine Sprache verfügt über Konditionale, Additionen oder Multiplikationen einer Folge von Ausdrücken - wofür wir eine Hilfsregel op einführen -, Funktionsanwendung durch einfaches Auflisten von Funktion und Argumenten und schließlich einfache Symbole. Beachten Sie, dass wir uns keine Sorgen machen müssen, dass ( if x ) fälschlicherweise als Anwendung geparst wird, da if immer als IF und nicht als SYMBOL tokenisiert wird.
op : ADD | MULTIPLY ;
exp : '(' IF exp THEN exp ELSE exp ')'
| '(' op exp+ ')'
| '(' exp+ ')'
| SYMBOL ;
Die ANTLR-Rille
Wie bereits erwähnt, sind JVM-Sprachen eines unserer Ziele für das Parsing. Gradle wird mit einem
sourceSets.main.antlr.srcDirs = [file("${ROOT_DIR}/grammar/").absolutePath]
generateGrammarSource {
maxHeapSize = "64m"
arguments += ['-long-messages', '-package', 'com.fortysevendeg.thingy', '-visitor', '-no-listener']
outputDirectory = file("${projectDir}/src/main/java/com/fortysevendeg/thingy/ast")
}
Und das war's auch schon! Sie haben jetzt einen vollwertigen Parser, den Sie von Java, Kotlin oder Scala aus verwenden können.
Unterwegs nachsehen
Ein übliches Problem bei der Entwicklung neuer Sprachen ist, wie viel Boilerplate für das einfache Testen einiger Beispiele erforderlich ist. Wenn wir uns für Kotlin entscheiden, müssen wir das Projekt neu erstellen und dann eine Möglichkeit zum Aufrufen des Parsers einrichten. Aber selbst in diesem Fall könnte es eine echte Herausforderung sein, herauszufinden, warum ein Beispiel nicht geparst werden kann. Glücklicherweise gibt es ein großartiges Plug-in für Visual Studio Code, das ich nicht genug empfehlen kann.
Neben der üblichen Syntaxhervorhebung und Navigation ist das Kronjuwel dieses Plug-ins die Möglichkeit, den Parsing-Prozess zu debuggen. Dazu müssen Sie eine Startkonfiguration in
{
"version": "2.0.0",
"configurations": [
{
"name": "Debug ANTLR4 grammar",
"type": "antlr-debug",
"request": "launch",
"input": "${file}",
"grammar": "Thingy.g4", // <-- your file
"startRule": "exp", // <-- your "main" rule
"printParseTree": true,
"visualParseTree": true
}
]
}
Öffnen Sie nun eine neue Datei und schreiben Sie etwas in Ihrer neuen Sprache. Wählen Sie auf der Registerkarte Ausführen die Option Debug ANTLR grammar, und Überraschung! Ein Parse-Baum erscheint in einer neuen Registerkarte. In diesem Fall parsen wir (if something then (+ x y) else who_knows).
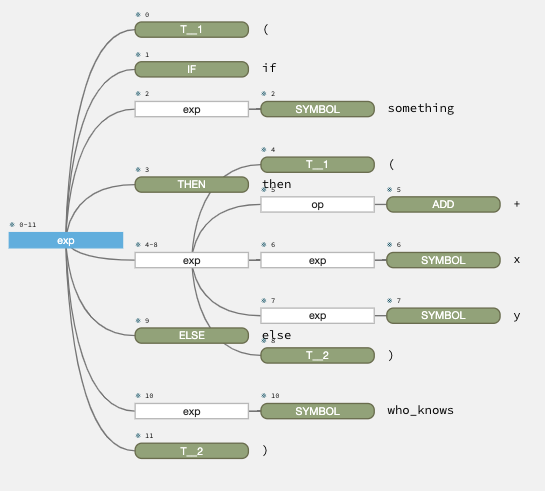
Wenn wir es nun in (if something) ändern, zeigt der Parse-Baum, wo das Problem liegt: wir haben IF und ein Symbol gefunden, aber dann hat die Regel die schließende Klammer nicht erwartet.
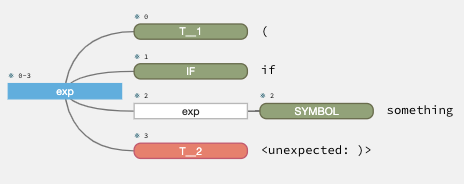
Ehrlich gesagt, hat das ANTLR-Plugin unser Leben so viel einfacher gemacht. Auch wenn das Parsen nur der erste Schritt bei der Arbeit mit einer benutzerdefinierten Sprache ist, so ist er doch in der Regel sehr mühsam, da der Prozess bei der Verwendung eines Generators in der Regel schwer zu kontrollieren ist. Hier haben wir nur die Oberfläche des grafischen Viewers angekratzt. Sie können die Regeln sogar Schritt für Schritt durchgehen und sehen, wann sie fehlschlagen. Das ist besonders nützlich, wenn Ihre Grammatik viele Mehrdeutigkeiten aufweist.
Haskell spielt nach seinen eigenen Regeln
Der nächste Schritt ist klar, oder? Wir müssen nur Haskell-Code aus unserer ANTLR-Grammatik generieren, so wie wir es mit Java getan haben, und das war's. Allerdings ist das nicht so einfach: Das entsprechende Projekt verlangt, dass wir die Regel mit den Haskell-Aktionen annotieren, aber damit unterbrechen wir die Möglichkeit, die Grammatik in Java zu konsumieren. Nach einigem Herumprobieren haben wir beschlossen, dass dies eine Sackgasse ist, und sind zu unserem alten Freund, den Parser-Kombinatoren, zurückgekehrt.
Diese Geschichte wurde bereits mehrfach erzählt, so dass es nicht nötig ist, sie hier zu wiederholen (obwohl, um fair zu sein, die meisten Tutorials sich auf die Implementierung und nicht so sehr auf die Verwendung konzentrieren). Wir erstellen unseren Datentyp zur Darstellung der geparsten Bäume.
data Op = Add | Multiply
data Exp = If Exp Exp Exp
| Op Op [Exp]
| App [Exp]
| Var String
Und dann verwenden wir eine Bibliothek wie
megaparsec
und applicative-style, um die konkrete Syntax der Grammatik zu beschreiben.
opP :: Parser Op
opP = Add <$ reserved "+" <|> Multiply <$ reserved "*"
expP :: Parser Exp
expP = parens go <|> varP
where varP = ... -- variable parser
go = If <$ reserved "if" <*> expP
<*> reserved "then" <*> expP
<*> reserved "else" <*> expP
<|> Op <$> opP <*> many expP
<|> App <$> many expP
Zum Glück ist die Erstellung eines Wrappers zur Ausführung dieser Grammatik eine einfache Aufgabe. Verwenden Sie einfach die parse und geben Sie die Zeichenkette ein, die Sie analysieren möchten.
Sind wir uns alle einig?
Die Lösung ist natürlich alles andere als perfekt. Unser Ziel war es, eine einzige Quelle der Wahrheit zu haben - die ANTLR-Datei - aber jetzt haben wir zwei Beschreibungen derselben Sprache, die unterschiedliche Technologien verwenden. Woher wissen wir überhaupt, dass sie dieselbe Sprache kodieren? Die Lösung kommt wieder von der ANTLR-Seite, indem wir ein Tool namens Grammarinator verwenden.
Grammarinator kehrt den Parser um: Anstatt eine Zeichenkette als Eingabe zu nehmen, erzeugt es eine Zeichenkette als Ausgabe. Dieses Tool arbeitet in zwei Phasen: Zuerst müssen Sie die Grammatik verarbeiten. Dabei werden einige Dateien erzeugt, darunter ThingyUnlexer und ThingyUnparser.
grammarinator-process Thingy.g4 -o test/generator
Und dann können Sie diese generierten Dateien verwenden, um eine Menge von Zeichenfolgen zu erzeugen, die die gewünschte Regel erfüllen, in diesem Fall exp. Sie können die Größe dieser Zeichenfolgen anpassen, indem Sie die -depth und die -numzahl der zu erhaltenden Werte ändern.
grammarinator-generate
-p test/generator/ThingyUnparser.py
-l test/generator/ThingyUnlexer.py
-t Tools.simple_space_serializer
-r exp
-o test/generated/test_%d.thingy -d 10 -n 100
Der letzte Trick besteht dann darin, sowohl den JVM-basierten als auch den Haskell-basierten Parser aufzurufen. Beide sollten die von Grammarinator kommenden Zeichenketten akzeptieren. Nun, das ist die Theorie. In der Praxis hatten wir einige Probleme, weil der Zufallsgenerator manchmal Dinge erzeugte, die eigentlich Variablen sein sollten, aber am Ende mit Schlüsselwörtern kollidierten (wie
class CustomThingyUnlexer(ThingyUnlexer):
def SYMBOL(self):
current = self.create_node(UnlexerRule(name='SYMBOL'))
current += self.unlexer.INITIAL_SYM_CHAR()
current += self.unlexer.DECIMAL()
return current
Dies funktioniert um die Ecke. Grammarinator als Teil unserer Testsuite und CI-Pipeline hat uns davor bewahrt, dass zwei Parser auseinanderdriften.
Fazit
Der Schritt, Ihre eigene Sprache zu entwickeln, kann beängstigend sein. Glücklicherweise kann dies mit der richtigen Toolunterstützung genauso einfach sein wie jeder andere Teil Ihres Systems. Insbesondere ANTLR hat ein großes Ökosystem um sich herum, das wir in unserem Projekt genutzt haben, um den Austausch von Informationen zwischen einer Vielzahl von Sprachen zu erleichtern. Tatsächlich schien es anfangs nicht die beste Idee zu sein, eine weitere Sprache (ANTLR) zu unserer bereits großen Anzahl von Sprachen hinzuzufügen. Aber es war eindeutig eine der besten Entscheidungen, die wir in der Anfangsphase unseres Projekts getroffen haben.
Verfasst von
Alejandro Serrano Mena




Contact