Update Mai 2017: Anstatt die Druid-Datenbank im CI-Job zu provisionieren, wird der Druid-Docker-Build jetzt mithilfe eines praktischen Skripts im Dockerfile selbst vorprovisioniert.
Bei GoDataDriven haben wir eine Open-Source-Kultur, wir lieben es, Open-Source-Projekte zu nutzen und zu ihnen beizutragen. In diesem Blog finden Sie ein Beispiel dafür, wie wir
Eine beliebte Methode zum Testen externer Abhängigkeiten ist die Verwendung von Mock-Objekten. Ich persönlich bin kein großer Fan von Mocking, weil es möglicherweise nicht das tatsächliche Verhalten der externen Komponente widerspiegelt. Außerdem könnte es interessant sein, die Software mit verschiedenen Versionen der Datenbank zu testen.
Für diejenigen, die Druid noch nicht kennen. Es handelt sich um einen leistungsstarken, spaltenorientierten und verteilten Datenspeicher. Druid indiziert Daten, um unveränderliche Snapshots zu erstellen, die für die Aggregation und Filterung optimiert sind, mit dem Ziel, Abfragen in Sekundenschnelle über riesige Datenmengen durchzuführen. Das Hauptaugenmerk liegt sowohl auf der Verfügbarkeit als auch auf der Skalierbarkeit. Die Architektur hat keinen einzigen Ausfallpunkt, so dass Druid linear skaliert werden kann, indem weitere Knoten hinzugefügt werden, um die Kapazität sowohl im Hinblick auf das Volumen als auch auf die Abfragen zu erhöhen. Aus der Perspektive des CAP-Theorems betrachtet, muss Druid keine Konsistenz behandeln, da Druid keine Schreibvorgänge unterstützt. Daher liegt das Hauptaugenmerk auf Partitionstoleranz und Verfügbarkeit. Druid ist teilweise von bestehenden analytischen Datenspeichern wie BigQuery/Dremel von Google und PowerDrill von Google inspiriert.
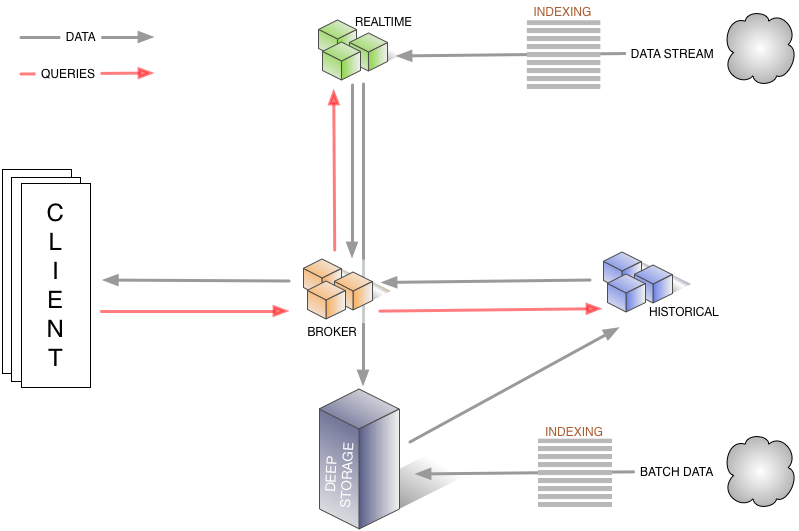
Wenn Sie die obige Abbildung betrachten, ist die Architektur von Druid im Vergleich zu einer einzelnen relationalen Datenbank wie Postgres oder Mysql ziemlich komplex. Sie besteht aus einer Vielzahl von Rollen, die unterschiedliche Aufgaben haben. Der Maklerknoten beispielsweise ist für die Bearbeitung der Abfragen und die Konsolidierung der von den historischen Knoten abgerufenen Teilergebnisse zuständig und liefert das Endergebnis. Die historischen Knoten durchforsten die in Segmente aufgeteilten Daten, die aus einem tiefen Speicher wie HDFS, S3 oder Cassandra geladen werden. Neben den in der Zeichnung erwähnten Rollen gibt es noch weitere unterstützende Prozesse, wie den Koordinator und den Overlord, der für das Ingesting und die Verteilung der Blöcke auf die verschiedenen historischen Knoten verantwortlich ist. Wenn Sie einen tieferen Einblick in die Architektur erhalten möchten, lesen Sie bitte das Druid-Papier.
Druid selbst bietet einen kompletten Druid-Cluster in einem einzigen Container mit Supervisord. Obwohl es keinen Sinn macht, dieses Image in der Produktion zu verwenden, ist es schön, die Möglichkeiten von Druid zu erkunden oder den Container in einer CI-Umgebung einzusetzen. Die modifizierte Version des Druid-Containers, die wir entwickelt haben, nimmt bei der Erstellung des Images einen Datensatz auf. Dies könnte ein Beispielsatz sein, der den Produktionsdatensatz repräsentiert und mit dem Sie Ihre Anwendung testen können. Der Container wird standardmäßig mit dem Wikipedia-Datensatz ausgeliefert, aber es ist auch möglich, einen neuen Datensatz zu erstellen, indem Sie Ihre eigenen Daten einlesen. Ausgehend von unseren Ergebnissen haben wir auch einige Pull Requests vorgeschlagen, um unsere Erkenntnisse an die Community weiterzugeben, und zwar 27, 29, 30, 31 und 32.
Für diesen Blog verwende ich unser Gitlab-Repository in Kombination mit Gitlab CI-Runnern, dem von mir bevorzugten CI-Runner. Gitlab verwendet Docker und ermöglicht es uns, .gitlab-ci.yml definiert, die sich im Stammverzeichnis des Repositorys befindet.
Vor dem Start der eigentlichen CI-Phase werden die Service-Container gestartet, die unter services in der yaml-Datei definiert sind (siehe unten). Die Service-Container sind über einen Hostnamen auflösbar, der mit dem eigentlichen Image-Namen verwandt ist, wobei nur / durch einen doppelten Unterstrich __ ersetzt wird. Weitere Informationen finden Sie in der Gitlab CI-Dokumentation.
Bild: python:2 druid-ci: Dienstleistungen: - fokkodriesprong/docker-druid Skript: - echo "Startklar" - pip install -r anforderungen.txt - Flocke8 - ./provision.py --file wikiticker-index.json --druid-host fokkodriesprong__docker-druid - python -m pytest tests/druid.py --druid-host fokkodriesprong__docker-druid
Sowohl der Druid-Container als auch das Python-Basis-Image beginnen mit einem sauberen Image. Daher installieren wir zunächst einige Python-Pakete mit pip, dann stellen wir die Druid-Datenquelle bereit und schließlich können wir die Anwendung gegen Druid testen. Wir führen auch eine flake8 Code-Stilprüfung durch, um sicherzustellen, dass der Code gemäß den pep8-Standards formatiert ist.
Das Image wird bereits mit einem praktischen Skript bereitgestellt. Während der Docker-Erstellungszeit stellen wir das Image bereit, indem wir eine jq leicht zu ändern, damit sie in der CI-Umgebung funktioniert. Das Skript überwacht den Indizierungsprozess und das eigentliche Laden der Datenquelle, um sicherzustellen, dass die Daten ordnungsgemäß geladen werden, andernfalls wird ein Exit-Code ungleich Null ausgegeben. Nun, da die Daten geladen sind und der Druid-Container gebootet ist, werden wir eine Abfrage an Druid senden:
{
"queryType" : "topN",
"dataSource" : "wikiticker",
"Intervalle" : ["2015-09-12/2015-09-13"],
"Granularität" : "alle",
"Dimension" : "Seite",
"Metrik" : "Bearbeitungen",
"Schwellenwert" : 5,
"Aggregationen" : [
{
"Typ" : "longSum",
"Name" : "Bearbeitungen",
"fieldName" : "Anzahl"
}
]
}
Als nächstes verwenden wir pytest, um zwei Testfälle gegen den Druid-Server auszuführen. Zunächst prüfen wir, ob die Datenquelle verfügbar ist, und führen dann eine topN Abfrage gegen Druid aus. Dadurch wird sichergestellt, dass die Abfragen der Anwendung mit dem aktuellen Datenschema und der Version von Druid kompatibel sind.
Das war's für den Moment. Wie immer stellen wir Data Scientists und Data Engineers ein. Gehen Sie auf unsere Karriereseite, wenn Sie interessiert sind. Sie erhalten viele Möglichkeiten, der Gemeinschaft etwas zurückzugeben.
Unsere Ideen
Weitere Blogs




Contact