Blog
Startklar: Datenpipeline mit BigQuery und dbt

Heutzutage müssen sich Unternehmen mit der Verarbeitung der im Data Lake des Unternehmens gesammelten Daten befassen. Infolgedessen werden Datenpipelines immer komplizierter, was sich erheblich auf die Entwicklungsgeschwindigkeit auswirkt. Außerdem erfordern ETL-Pipelines manchmal Kenntnisse aus dem Bereich der Softwareentwicklung, z.B. wenn Sie Ihre Pipelines mit Apache Beam erstellen möchten. Heute möchte ich Ihnen ein neues Tool namens dbt vorstellen, das Ihnen helfen kann, Ihre riesigen Datenmengen zu bändigen und die Erstellung komplexer Datenpipelines zu vereinfachen.
Mit Dbt können wir ELT-Pipelines erstellen, die sich von klassischen ETL-Pipelines ein wenig unterscheiden. Lassen Sie uns diese beiden Ansätze vergleichen:
- ETL (Extrahieren, Transformieren, Laden) - bei diesem Ansatz müssen wir Daten transformieren, bevor wir sie in das Unternehmenslager laden können.
- ELT (Extrahieren, Laden, Transformieren) - bei diesem Ansatz können wir Daten in das Unternehmens-Warehouse laden und sie später transformieren. Da die Daten zunächst im Warehouse gespeichert und dann transformiert werden, gehen bei der Transformation in das kanonische Modell keine Informationen aus den Rohdaten verloren. Die Speicherung der Rohdaten im Warehouse ermöglicht es uns, neue Transformationen an den Daten vorzunehmen, wenn wir einen Fehler in der Pipeline finden oder die Ansichten mit zusätzlichen Informationen anreichern möchten.
Dbt eröffnet Ihrem Data-Engineering-Team neue Möglichkeiten und ermöglicht die Erstellung von ELT-Pipelines, selbst durch jemanden, der wenig Erfahrung mit SQL hat.
In diesem Artikel möchte ich Ihnen zeigen, wie Sie Schritt für Schritt eine einfache Datenpipeline mit dbt und BigQuery aufbauen.
Wir werden ein einfaches Datenmodell erstellen, das Daten von Google Analytics verarbeitet. Der Datensatz ist einer der offenen Datensätze, die von BigQuery angeboten werden.
Beispielprojekt
Meiner Meinung nach ist der einfachste Weg, Ihr Abenteuer mit dbt und BigQuery zu beginnen, die Anpassung eines von dbt CLI generierten Beispielprojekts. Bevor wir beginnen, gehe ich davon aus, dass Sie ein leeres GCP-Projekt haben. In diesem Beispiel verwende ich ein Projekt mit dem Namen 'dbt-bq-playground'.
Beginnen wir also mit dem Einrichten der Entwicklungsumgebung. Öffnen Sie zunächst 'Cloud Shell' im GCP-Dashboard und führen Sie den folgenden Befehl aus:
pip3 install --user --upgrade dbt-bigquery

Wenn der Befehl beendet ist, haben Sie dbt CLI in der Befehlszeile zur Verfügung. Wir können die CLI verwenden, um ein Beispielprojekt zu erstellen. Nehmen wir an, das Projekt hat den Namen 'sample_dbt_project' . Um die Projektstruktur zu erzeugen, führen Sie bitte den folgenden Befehl in der Cloud Shell aus:
~/.local/bin/dbt init sample_dbt_project
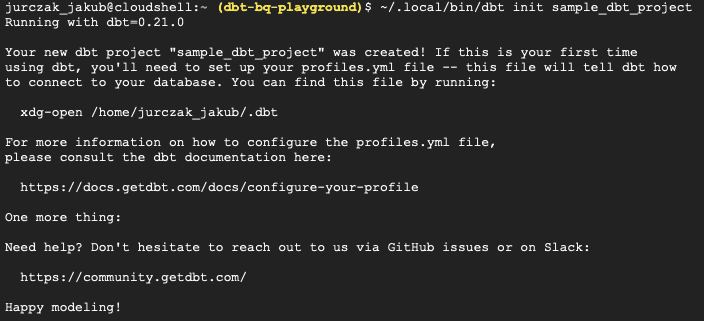
Die CLI sollte die Projektstruktur in einem Verzeichnis "~/sample_dbt_project" erzeugen. Bevor wir unsere erste Pipeline ausführen, müssen wir ein Dataset in BigQuery erstellen und die dbt-Konfiguration einrichten.
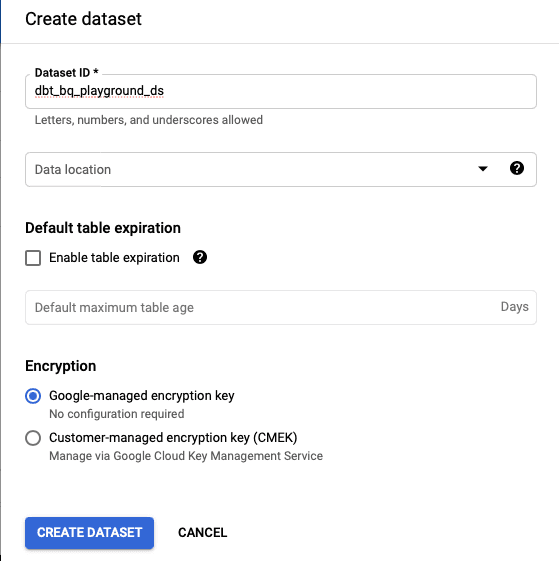
Bitte wählen Sie 'BigQuery' aus dem Navigationsmenü und klicken Sie auf die Schaltfläche 'Datensatz erstellen', um einen Datensatz zu erstellen.

Im Fenster zur Bearbeitung des Datensatzes müssen Sie den Namen des Datensatzes eingeben (in unserem Fall "dbt-bq-playground-ds") und auf die Schaltfläche "Datensatz erstellen" klicken.
Wenn der Datensatz erstellt wurde, können wir die Datei dbt profile.yml ausfüllen, die die dbt-Konfiguration enthält. Dazu bearbeiten Sie bitte:
nano ~/.dbt/profiles.yml
Es sollte so aussehen:
default:
outputs:
dev:
type: bigquery
method: oauth
project: <YOUR_PROJECT_ID>
dataset: dbt_bq_playground_ds
threads: 1
timeout_seconds: 300
location: US # Optional, one of US or EU
priority: interactive
retries: 1
prod:
type: bigquery
method: service-account
project: [GCP project id]
dataset: [the name of your dbt dataset]
threads: [1 or more]
keyfile: [/path/to/bigquery/keyfile.json]
timeout_seconds: 300
priority: interactive
retries: 1
target: devIn den meisten Fällen werden Dev- und Prod-Umgebungen gemeinsam genutzt. Transformationen in diesen Umgebungen sollten nur im Rahmen des CI/CD-Prozesses ausgeführt werden. Wenn Sie Ihre Transformationen lokal testen möchten, können Sie den Ergebnisdatensatz wie folgt parametrisieren:
dataset: "{{ env_var('USER') }}_private_working_schema"
Als nächstes können Sie speichern & beenden, indem Sie STRG + S, STRG + X drücken. Jetzt sind wir bereit, die Beispielpipeline auszuführen. Führen Sie dazu das folgende Programm im dbt-Projektverzeichnis aus:
~/.local/bin/dbt run
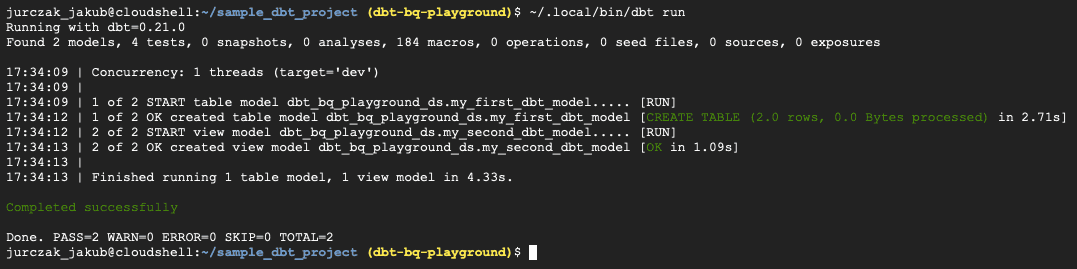
Wenn alles reibungslos verläuft, sollten Sie die Ergebnisse in der BigQuery-Konsole sehen.
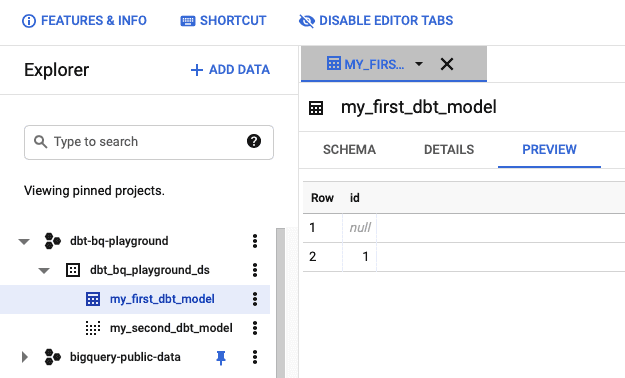
Jetzt können wir mit der Bearbeitung der dbt-Projektdateien beginnen. In diesem Beispiel werde ich den von GCP bereitgestellten 'Cloud Shell Editor' verwenden. Bitte klicken Sie auf die Schaltfläche 'Editor öffnen', um den Editor zu öffnen.

Klicken Sie im Editor-Fenster auf 'Datei → Öffnen' und wählen Sie 'sample_dbt_project' im Home-Verzeichnis. Schließlich sollten Sie ein Editor-Fenster wie unten sehen:
Dbt-Projektstruktur
Wir haben mit der dbt CLI ein Beispielprojekt erstellt. Bevor wir mit der Erstellung unserer benutzerdefinierten Pipelines beginnen, möchte ich kurz die Struktur des dbt-Projekts beschreiben. 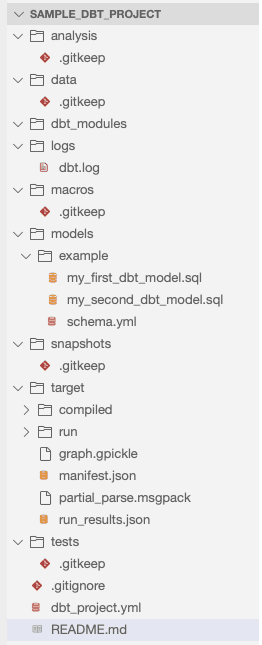
- analysis/ - in diesem Verzeichnis können Sie Ihre analytischen Abfragen speichern, die Sie beim Aufbau der Pipeline verwenden.
- data/ - enthält alle Daten (z.B. CSV-Dateien), die mit dem Befehl
dbt seedin die Datenbank geladen werden sollen. - dbt_modules/ - enthält Pakete, die mit dem Befehl
dbt depsinstalliert wurden. - logs/ - enthält Protokolle der Ausführung des Befehls
dbt run - macros/ - enthält Geschäftslogik, die im Projekt mehrfach wiederverwendet werden kann. Sie können Jinja-Vorlagen im Makrocode verwenden, um Funktionen zu nutzen, die in reinem SQL nicht verfügbar sind.
- models/ - dieser Ordner enthält alle Datenmodelle in Ihrem Projekt.
- target/ - enthält Dateien, die vom dbt während der Build-Phase erzeugt wurden. Die Ordner
target/unddbt_modules/können durch Ausführen vondbt cleangelöscht werden. - tests/ - enthält die im Projekt verwendeten Tests.
- dbt_project.yml - Diese Datei enthält die Hauptkonfiguration für Ihr Projekt. Hier können Sie den Projektnamen, die Version, das Standardprofil und die Definition der Projektordnerstruktur konfigurieren.
Wie funktioniert die Beispiel-Pipeline?
Jetzt sind wir bereit zu analysieren, wie die Beispiel-Pipeline funktioniert. Wir beginnen unsere Reise mit dem Ordner models/example. In diesem Ordner finden Sie die Dateien *.sql und schema.yml. In den Dateien *.sql finden Sie eine Definition unserer Modelle. Öffnen wir die my_first_dbt_model.sql.
/*
Welcome to your first dbt model!
Did you know that you can also configure models directly within SQL files?
This will override configurations stated in dbt_project.yml
Try changing "table" to "view" below
*/
{{ config(materialized='table') }}
with source_data as (
select 1 as id
union all
select null as id
)
select *
from source_data
/*
Uncomment the line below to remove records with null `id` values
*/
-- where id is not nullDiese Datei enthält eine Definition für eine dbt-Transformation. Zu Beginn haben wir festgelegt, dass wir die Transformation als Tabelle materialisieren möchten. In der dbt haben wir einige Optionen, aus denen wir wählen können, wie die Transformation materialisiert werden soll:
- Tabelle - führt die Transformation einmal aus, so dass das Ergebnis möglicherweise nicht aktuell ist. Die Tabelle muss von dbt aktualisiert werden, um auf dem neuesten Stand zu sein.
- Ansicht - führt bei jedem Lesevorgang eine Transformation durch. Sie ist also so aktuell wie die zugrunde liegenden Tabellen, auf die sie verweist.
- Ephemeral - diese Modelle werden nicht in der DB gespeichert, können aber als Tabellenausdruck in anderen Modellen wiederverwendet werden.
- Inkrementell - wenn der Aufbau einer Tabelle zu langsam ist, können wir die inkrementelle Materialisierung verwenden, die es dbt ermöglicht, nur die Zeilen in einer Tabelle zu aktualisieren, die seit dem letzten dbt-Lauf geändert wurden.
Was sind also die besten Praktiken, die Sie für jede von ihnen anwenden sollten?
- Verwenden Sie eine Ansicht, wenn die Verzögerung für Ihren Endbenutzer nicht zu groß ist.
- Verwenden Sie eine Tabelle, wenn Ansichten zu langsam sind. Verwenden Sie inkrementelle Modelle in dbt, wenn die Erstellung einer Tabelle mit dbt zu langsam ist.
- Verwenden Sie ein Ephemeral, wenn Sie wiederverwendbare Logik schreiben und die Erstellung von temporären Tabellen in der DB vermeiden möchten.
- Verwenden Sie inkrementell, wenn das Erstellen von Tabellen zu langsam ist.
Als nächstes sehen wir das Schlüsselwort with. In diesem Abschnitt können wir temporäre Tabellen definieren, die in der endgültigen SQL-Abfrage verwendet werden.
Am Ende der Datei haben wir die SQL-Abfrage definiert, die unsere Transformation beschreibt.
Nun sind wir bereit, das im vorherigen Beispiel definierte Modell zu verwenden. Bitte öffnen Sie die Datei my_second_db_model.sql. Die Datei enthält eine Beispiel-Ansichtsdefinition, die sich auf das vorherige Modell bezieht.
-- Use the `ref` function to select from other models
select *
from {{ ref('my_first_dbt_model') }}
where id = 1In dem Beispiel sehen wir die Verwendung einer ref Funktion. Diese Funktion ermöglicht es uns, ein Modell innerhalb eines anderen zu referenzieren. Sie eröffnet uns neue Möglichkeiten, Datenpipelines aus einem kleinen, wiederverwendbaren Codeblock zu erstellen, der leicht zu verstehen und zu testen ist.
Dbt bietet eine automatische Generierung der Projektdokumentation. Die Schema-Dokumentation befindet sich in der Datei schema.yml und sollte alle Modellbeschreibungen enthalten, wie im folgenden Beispiel:
version: 2
models:
- name: my_first_dbt_model
description: "A starter dbt model"
columns:
- name: id
description: "The primary key for this table"
tests:
- unique
- not_null
- name: my_second_dbt_model
description: "A starter dbt model"
columns:
- name: id
description: "The primary key for this table"
tests:
- unique
- not_nullIn der Schemadefinition können Sie für jedes Modell oder jede Spalte eine Beschreibung hinzufügen, die für die Erstellung der Projektdokumentation verwendet wird. Später in diesem Blogbeitrag werden wir sehen, wie wir aus unseren Transformationen eine interaktive Dokumentation erstellen können.
Jetzt sind wir bereit, unsere erste benutzerdefinierte Datenpipeline zu definieren, die Daten aus einem der offenen BigQuery-Datensätze verarbeiten wird. Aber sehen wir uns erst einmal an, wie das geht.
Unsere erste Datenpipeline
Wir werden mit einem einfachen Szenario arbeiten, das die Erstellung von 2 Tabellen und 1 Ansicht in der dbt erfordert. Schauen wir uns zunächst die Beschreibung an:
Als Data Engineer möchte ich einen Bericht über Benutzeraktivitäten auf der Grundlage von Daten aus Google Analytics erstellen. Daher erwarte ich, dass die folgenden Tabellen erstellt werden:
- totalPageViews - diese Tabelle enthält Spalten: reportDate, operationSystem und totalPageViews (eine Summe der Website-Aufrufe durch ein bestimmtes Betriebssystem an einem bestimmten Tag).
- distinctCountryCount - diese Tabelle enthält Spalten: reportDate, operationSystem und distincCountCountry (eine Summe der eindeutigen Länder unserer Benutzer an einem bestimmten Tag von einem bestimmten Betriebssystem).
- usersReport - diese Ansicht verbindet Daten aus den Tabellen totalPageViews und distincCountryCount, basierend auf den Feldern reportDate und operationSystem.
Bevor wir beginnen, löschen Sie bitte den Ordner example/ und erstellen Sie den Ordner users_report/ im Verzeichnis model/.
Jetzt können wir mit der Erstellung unserer Datenpipelines beginnen. Bitte erstellen Sie Dateien im Ordner users_report/ wie unten angegeben:
distinct_country_count.sql sollte eine Abfrage enthalten, die die einzelnen Länder unserer Benutzer zusammenzählt.
{{ config(materialized='table') }}
SELECT
date AS reportDate,
device.operatingSystem AS operationSystem,
COUNT(DISTINCT geoNetwork.country) AS distincCountCountry,
FROM `bigquery-public-data.google_analytics_sample.ga_sessions_20170801`
GROUP BY date, device.operatingSystemtotal_page_views.sql sollte eine Abfrage enthalten, die die Gesamtzahl der Ansichten unserer Benutzer addiert.
{{ config(materialized='table') }}
SELECT
date AS reportDate,
device.operatingSystem AS operationSystem,
SUM(totals.pageviews) AS totalPageViews,
FROM `bigquery-public-data.google_analytics_sample.ga_sessions_20170801`
GROUP BY date, device.operatingSystemusers_report.sql sollte eine Abfrage enthalten, die den endgültigen Bericht erstellt.
{{ config(materialized='view') }}
SELECT
c.reportDate,
c.operationSystem,
c.distincCountCountry,
t.totalPageViews
FROM {{ ref('distinct_country_count') }} AS c
JOIN {{ ref('total_page_views') }} AS t
ON c.reportDate = t.reportDate AND c.operationSystem = t.operationSystemSchließlich müssen wir die Datei schema.yml erstellen, die Informationen über unsere Modelle enthält.
version: 2
models:
- name: distinct_country_count
description: "Contains information about unique countries"
columns:
- name: reportDate
description: "A day when the statistics have been generated"
- name: operationSystem
description: "A user operating system"
- name: distincCountCountry
description: "Distinct country count"
- name: total_page_views
description: "Contains information about total views"
columns:
- name: reportDate
description: "A day when the statistics have been generated"
- name: operationSystem
description: "A user operating system"
- name: totalPageViews
description: "Distinct country count"
- name: users_report
description: "Final report"
columns:
- name: reportDate
description: "A day when the statistics have been generated"
- name: operationSystem
description: "A user operating system"
- name: distincCountCountry
description: "Distinct country count"
- name: totalPageViews
description: "Distinct country count" Zum Schluss können wir unsere Pipeline ausführen und die Ergebnisse überprüfen. Bitte führen Sie den Befehl ~/.local/bin/dbt run im Projektverzeichnis aus.
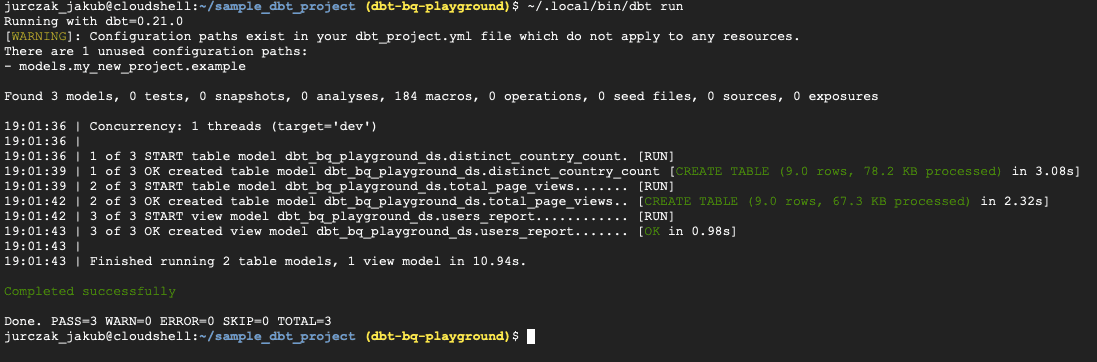
Wenn der Befehl beendet ist, können wir die Ergebnisse im BigQuery-Fenster überprüfen.
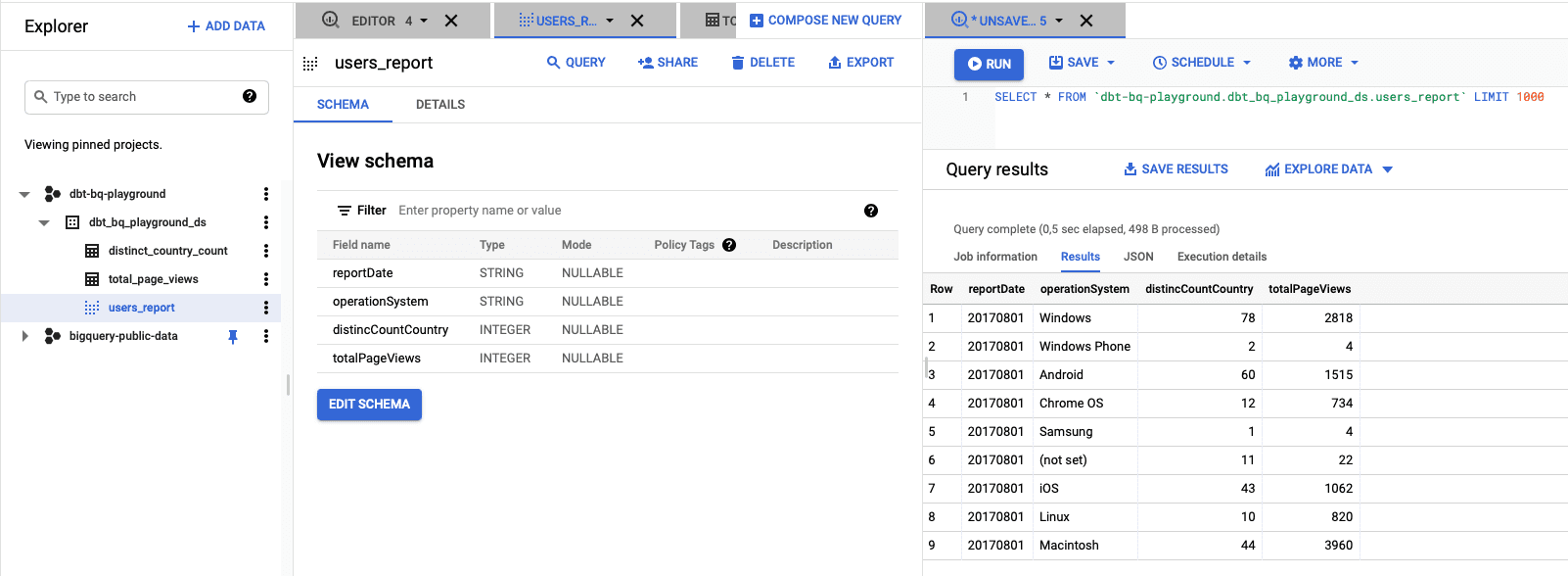
Wie wir sehen können, haben wir den endgültigen Bericht im Datensatz.
Wir können ein Data Studio-Dashboard auf der Grundlage der Daten erstellen, indem wir auf die Schaltfläche "Daten erkunden" klicken. Sie können ein Balkendiagramm erstellen, das wie unten dargestellt aussieht.
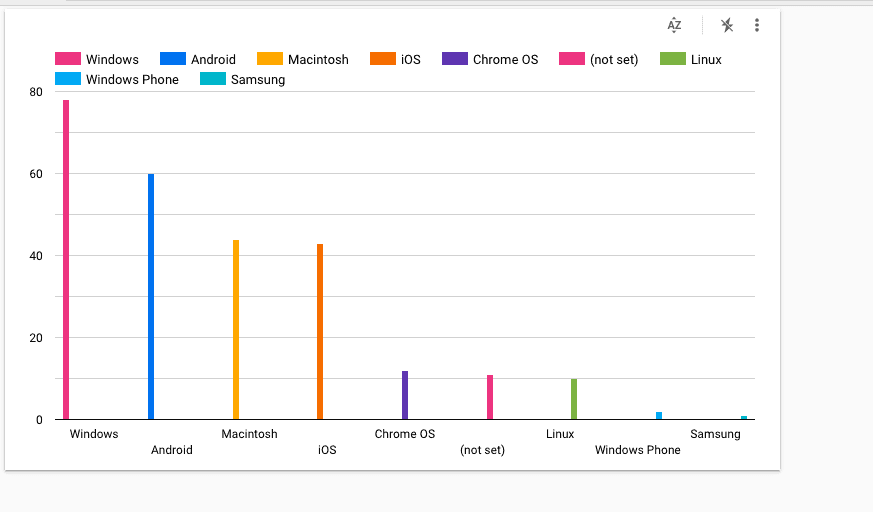
Daten-Tests
Es ist eine gute Praxis, Tests für Ihren Code zu schreiben und ein hohes Maß an Testabdeckung zu gewährleisten. Dbt bietet einen einfachen Mechanismus, mit dem wir Tests für unsere Transformationen schreiben können. Ein Datentest in der dbt ist einfach eine SQL-Datei, die im Verzeichnis /tests gespeichert ist und eine SQL-Abfrage enthält. Wenn wir den Befehl dbt test ausführen, holt sich die dbt die Tests aus dem Projekt, führt die in den Dateien gespeicherten Abfragen aus und überprüft, ob die Abfrage 0 Zeilen zurückgibt. Wenn eine Abfrage >0 Zeilen zurückgibt, behandelt das dbt diese Behauptung als Fail.
Lassen Sie uns zwei einfache Datentests in unserem Projekt schreiben. Wir wollen die folgenden Szenarien abdecken:
- die Gesamtzahl der Seitenaufrufe ist ein nicht-negativer Wert oder Null
- die Anzahl der Länder ist ein nicht-negativer Wert, der nicht null ist
Bitte erstellen Sie zwei Dateien wie unten:

In die Datei assert_country_count_is_positive.sql wollen wir eine Logik schreiben, die die Korrektheit des Wertes 'Total Page Views' überprüft.
SELECT
operationSystem,
distincCountCountry
FROM {{ ref('distinct_country_count') }}
WHERE distincCountCountry < 0 OR distincCountCountry IS NULLIn die Datei assert_page_views_is_positive.sql wollen wir eine Logik schreiben, die die Korrektheit des Länderzählwertes überprüft.
SELECT
operationSystem,
totalPageViews
FROM {{ ref('total_page_views') }}
WHERE totalPageViews < 0 OR totalPageViews IS NULLWir können unsere Datentests ausführen, indem wir ~/.local/bin/dbt test aufrufen.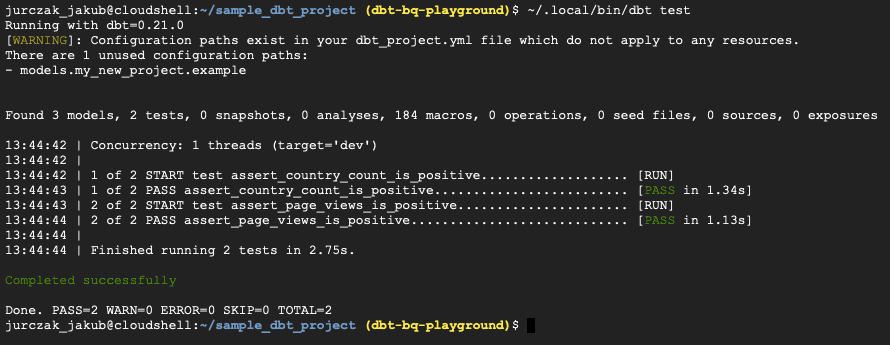
Wie Sie sehen, bestehen alle Assertions, so dass unsere Transformationen wie erwartet funktionieren.
Dokumentation mit dbt generieren
Es gibt eine weitere wichtige Funktion von dbt, die erwähnt werden sollte. Wir können die Dokumentation unserer Datenpipelines auf der Grundlage des Inhalts der Schemadatei erstellen und bereitstellen. Außerdem kann die dbt ein Diagramm der Abhängigkeiten unserer Datenpipelines erstellen.
Um die Dokumentation zu erstellen, führen Sie bitte diesen Befehl aus ~/.local/bin/dbt docs serve.

Das Ergebnis wird über die Adresse in der Konsole ausgegeben. Wenn Sie also auf die Adresse klicken, sollten Sie etwas wie das hier sehen.
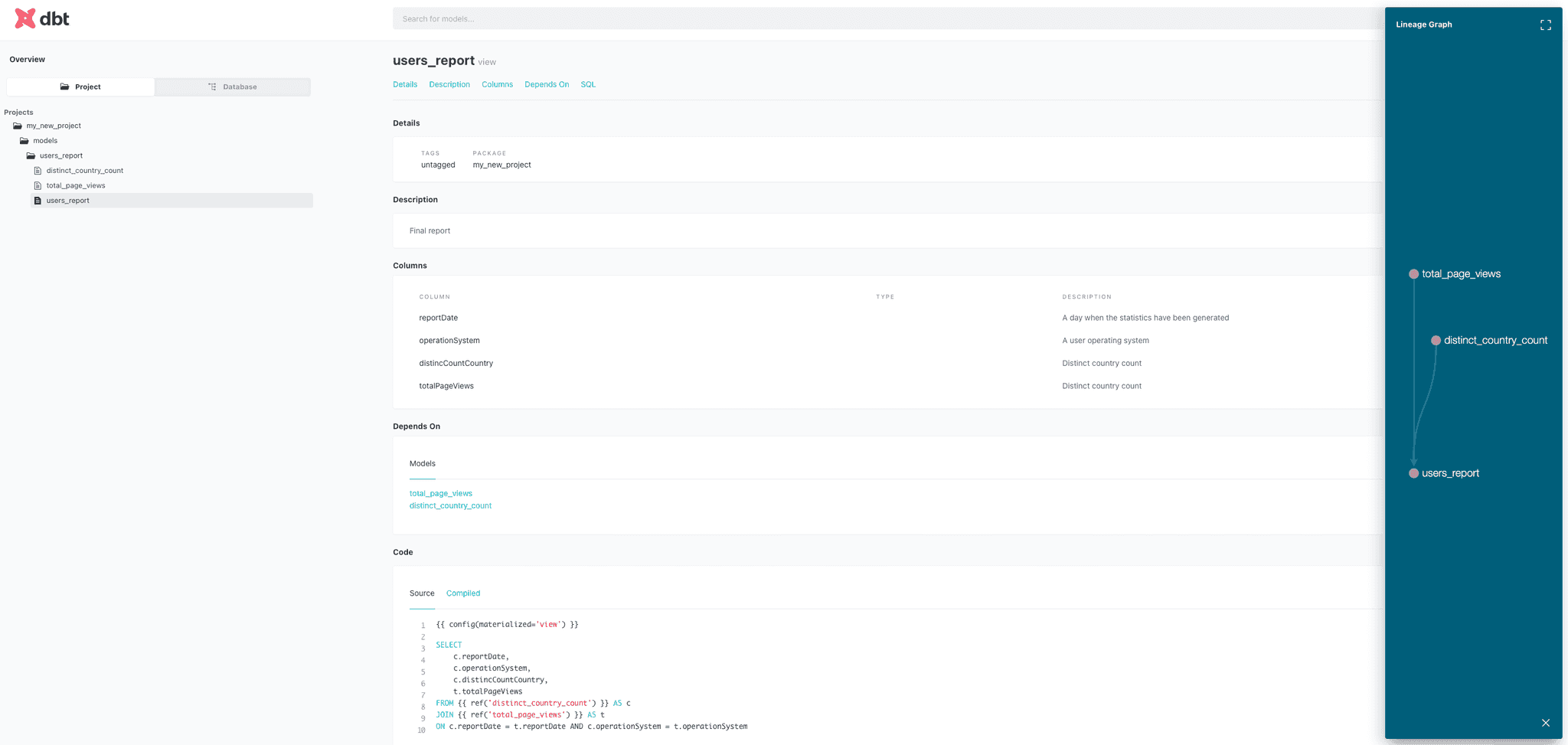
Schlussfolgerungen zu Datenpipelines mit BigQuery und dbt
Dbt bietet neue Möglichkeiten für Dateningenieure, die Datenpipelines mit reinem SQL erstellen und ihren Code schnell testen möchten. Das Tool hilft uns bei der Verwaltung selbst sehr komplexer Datenpipelines dank der Dokumentationsgeneratoren, die es uns ermöglichen, den Graph der Abhängigkeiten im Projekt zu visualisieren. Die Dokumentation ist ein guter Ausgangspunkt für andere Teams, die damit beginnen möchten, Wissen aus Unternehmensdaten zu extrahieren oder maschinelle Lernmodelle zu erstellen. dbt ist für jemanden, der Erfahrung mit der SQL-Syntax hat und seine ersten Schritte im Bereich Data Engineering machen möchte, leicht zu erlernen.
Ich glaube, es ist eine Technologie, die sich für viele Unternehmen, die ein ELT-Framework für ihr Data-Engineering-Team suchen, als sehr nützlich erweisen wird. Darüber hinaus wäre dbt die beste Wahl für Datenwissenschaftler, die SQL beherrschen und nach einem Tool suchen, das ihnen bei der Verarbeitung von Daten aus vielen verschiedenen Datenquellen helfen kann.
Verfasst von
Jakub Jurczak
Unsere Ideen
Weitere Blogs




Contact