SQL-Abfragen mit doobie typisieren
Für einen unserer Kunden habe ich kürzlich an einer Scala-basierten API gearbeitet, die für den Großteil ihrer Daten auf eine PostgreSQL-Integration angewiesen war. Für die Abfrage der Daten wurde der standardmäßige Java PostgreSQL JDBC-Connector in Kombination mit einer Handvoll benutzerdefinierter Funktionen verwendet, um die Boilerplate so weit wie möglich zu entfernen. Die Lösung erfüllte ihre Aufgabe, aber als sich die Anforderungen und die Codebasis weiterentwickelten, stießen wir an einige Grenzen:
- Die benutzerdefinierte Funktion, die wir zum Erstellen von
PreparedStatementverwendet haben, nutzte den Mustervergleich für die Funktionsargumente, um die korrekte Zuordnung vom Scala-Typ zum SQL-Datentyp zu ermitteln. Das funktioniert gut für die primitiven Typen, aber nicht so sehr für komplexere Containertypen wieOption[T]. Beim Musterabgleich mit diesen Containertypen stoßen Sie auf die Typlöschung von Scala. In dem speziellen Fall, in dem Sie einenOption[T]abgleichen, können Sie daher feststellen, ob es sich um einen tatsächlichen Wert oder einenNonehandelt. Sie haben jedoch keine Möglichkeit, den Typ vonTzu bestimmen und somit auch keine Möglichkeit, den SQL-Datentyp zu ermitteln, auf den Sie mappen können. - Es gab keine Möglichkeit, festzustellen, ob die Zuordnung vom SQL-Datentyp zum Scala-Typ korrekt war. So konnte z.B. eine Spalte
ohne Probleme auf einen in Scala abgebildet werden, bis zu dem Moment, an dem Sie diesen Wert irgendwo in Ihrem Scala-Code verwenden wollten. Wenn PostgreSQL hier einen NULLzurückgeben würde, erwartet Sie zur Laufzeit ein hässlichesNullPointerException. - Alle Aufrufe an PostgreSQL wurden blockierend ausgeführt. Es wäre jedoch eine gute Praxis, die Datenbank asynchron abzufragen (oder zumindest einen separaten Threadpool für blockierende E/A zu verwenden), damit die API weiterhin eingehende Anfragen bedienen kann.
Experimentieren mit Doobie
Um diese Probleme zu überwinden, wollte ich eine Bibliothek namens doobie ausprobieren, auf die ich kürzlich gestoßen bin. doobie ist ein Typelevel.scala-Projekt, das einen prinzipiellen Ansatz für die Verwendung von JDBC bietet. Warum doobie?
- Die Codebasis unseres Kunden verwendete bereits (recht komplexe) SQL-Anweisungen, und ich hatte das Gefühl, dass sie ihre Absichten gut zum Ausdruck brachten, wahrscheinlich besser, als zu versuchen, sie umständlich in eine DSL zu gießen, wie sie z. B. von Slick bereitgestellt wird. doobie umfasst die SQL-Sprache, so dass es in Kombination mit dem, was wir bereits zur Verfügung hatten, gut zu passen schien.
- Es bietet integrierte Unterstützung für Unit-Tests und die Typüberprüfung Ihrer SQL-Abfragen. Sie erhalten umfassendes Feedback darüber, welche Verbesserungen vorgenommen werden sollten.
- Es ist einfach, Ihre SQL-Ergebnisse direkt auf Scala-Fallklassen abzubilden. Das verbessert die Lesbarkeit und begrenzt die Menge an Boilerplate.
- Es ist einfach, Doobie mit Monix, einer weiteren meiner bevorzugten Typelevel.scala-Bibliotheken, für die kontrollierte asynchrone Codeausführung zusammenarbeiten zu lassen.
Erste Schritte
In diesem Beispiel verwende ich einen Datensatz, den auch doobie für seine Beispiele verwendet, eine Reihe von Tabellen (u.a. Länder und Städte), die zusammen "die Welt" beschreiben. Schauen wir uns einige Beispieldaten aus der Tabelle countries an:
| Code | Name | Kontinent | Region | Oberflächenbereich | unabhängig vom Jahr | ... |
|---|---|---|---|---|---|---|
| AFG | Afghanistan | Asien | Süd- und Zentralasien | 652090.0 | 1919 | |
| NLD | Niederlande | Europa | Westeuropa | 41526.0 | 1581 | |
| ANT | Niederländische Antillen | Nord-Amerika | Karibik | 800.0 |
Basierend auf einer Teilmenge der Eigenschaften, die uns in der Tabelle zur Verfügung stehen, definieren wir eine Country wie folgt:
Fall Klasse Land( Code: Zeichenfolge, Name: Zeichenfolge, surfaceArea: Schwimmer, UnabhängigkeitJahr: Int )
Mit der API, die doobie zur Verfügung stellt, können wir eine Abfrageanweisung erstellen:
val Abfrage = sql"""SELECT code, name, oberflächenbereich, indepyear AUS Ländern LIMIT 10""".Abfrage[Land]
query enthält keine Antworten aus der Datenbank, sondern ist eine Beschreibung eines Programms, das ausgeführt werden muss, um diese Antworten zu erhalten. Dafür können wir ein Transactor verwenden. Transactor weiß, wie man eine Verbindung zur Datenbank herstellt und wie man das Programm query in einen asynchronen Effekt verwandelt, eine Funktion, die wir gesucht haben!
Bei meinem Kunden haben wir HikariCP verwendet, um den Verbindungspool zu PostgreSQL aufrechtzuerhalten. Mit doobie können Sie Hikari weiterhin verwenden, indem Sie eine HikariTransactor bereitstellen:
val Transactor: Aufgabe[HikariTransactor[Aufgabe]] = HikariTransactor.newHikariTransactor[Aufgabe]( driverClassName = "org.postgresql.Driver", url = "jdbc:postgresql://localhost/world", Benutzer = "Demo", passieren = "" ).memoisieren
Was passiert also hier? Hier erstellen wir eine HikariTransactor, indem wir ihr die Verbindungsdetails zur PostgreSQL-Datenbank mitteilen und ihr sagen, dass eingehende Doobie-Programme in eine (Monix) Task umgewandelt werden sollen, d.h. eine asynchrone Operation, die (wenn sie ausgeführt wird) die Datenbankabfrage ausführt. Eine Monix Task ist wie eine Scala Future, wird aber faul ausgewertet und hat viel mehr Möglichkeiten, ausgeführt zu werden (z.B. auf geplante Weise). Lesen Sie die ausführliche Dokumentation, um mehr über Monix zu erfahren.
Da die Konstruktion des HikariTransactors einen Zustand erfordert und daher ein Effekt ist, erhalten wir tatsächlich ein Task zurück, das uns die HikariTransactor liefert. Da Taskstandardmäßig bei jedem Lauf (neu) ausgewertet wird, weisen wir ihn explizit an, memoize das Ergebnis beim ersten Lauf zu liefern, so dass wir genau einen Hikari-Verbindungspool erstellen, egal wie oft wir den Task ausführen.
Da wir nun eine Transactor haben, können wir unsere query wie folgt ausführen:
def Wählen Sie[T](Abfrage: VerbindungIO[T]): Aufgabe[T] = für { xa Transactor Ergebnis Abfrage.transact(xa) } ergeben Ergebnis val asyncResult: Aufgabe[Liste[Land]] = Wählen Sie(Abfrage.Liste)
Anstelle von query.list, was uns eine List[Country]könnten wir auch wählen, ob wir query.option für eine Option[Country] oder query.unique für eine Country (oder eine Ausnahme, falls die Abfrage nicht genau eine Zeile zurückgegeben hat).
Abfrage-Typüberprüfung
In der query, die wir oben definiert haben, ordnen wir einige Felder aus einer SQL-Abfrage einer Case-Klasse zu. Aber woher wissen wir, dass dies tatsächlich wie erwartet funktioniert? doobie bietet leider keine Typüberprüfung während der Kompilierung, aber es macht die Typüberprüfung Ihrer Abfragen während der Unit-Tests wirklich einfach:
Klasse AbfragenSpec erweitert WordSpec mit Matcher mit IOChecker { ... "Abfrage prüfen" in { siehe(Abfrage) } }
Wenn mit Ihrer Abfrage etwas nicht in Ordnung ist, gibt doobie ausführliche Rückmeldungen darüber, was schief läuft. Die Abfrage lässt sich z.B. nicht kompilieren:
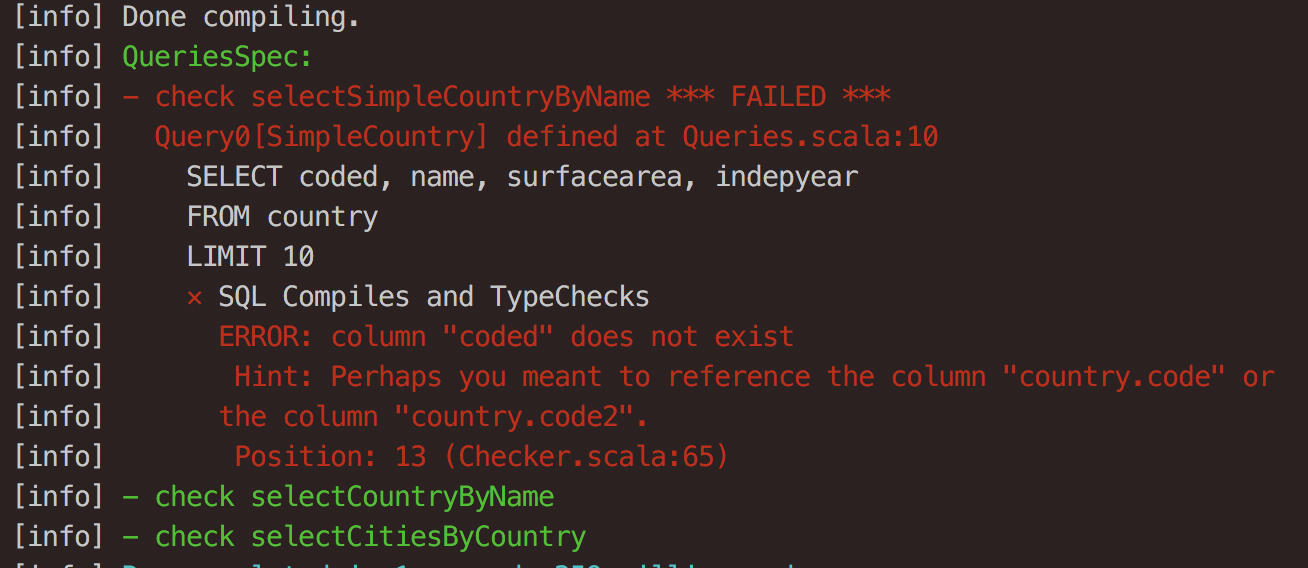
oder, die Typen passen nicht zusammen:
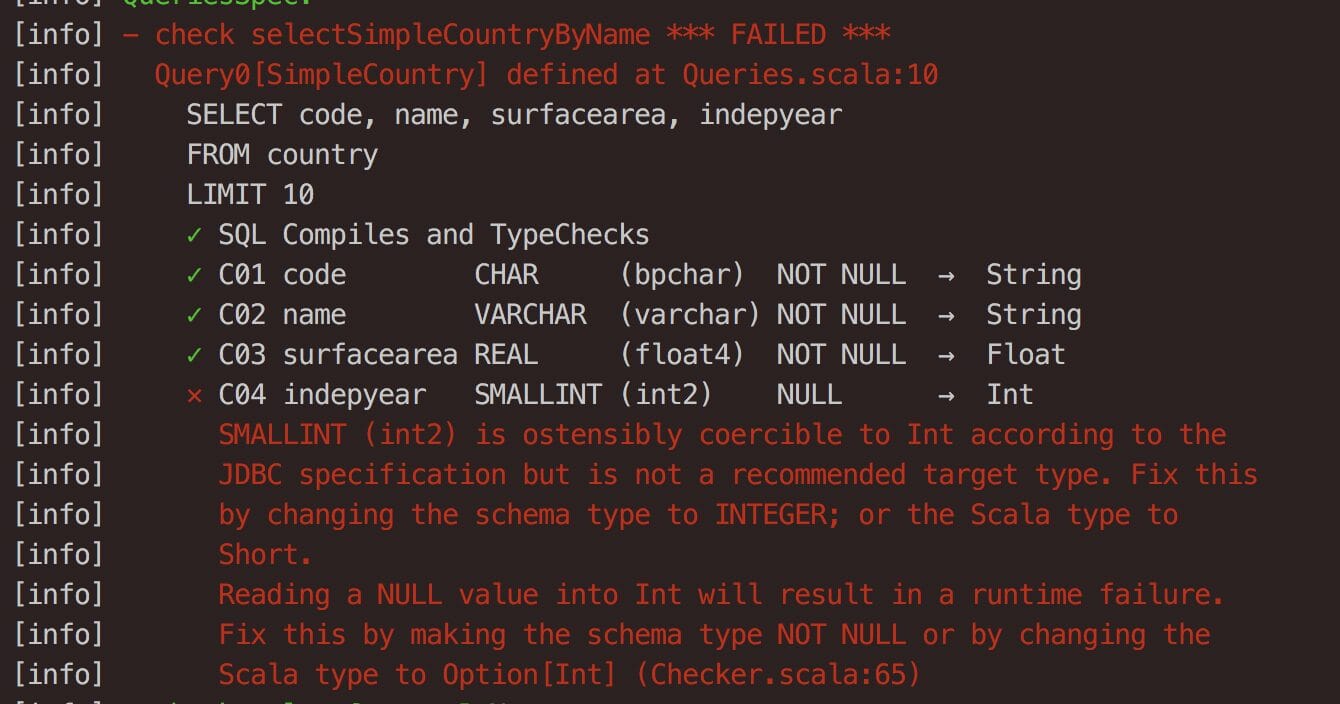
oder Sie wählen mehr Felder aus, als Sie verwenden:
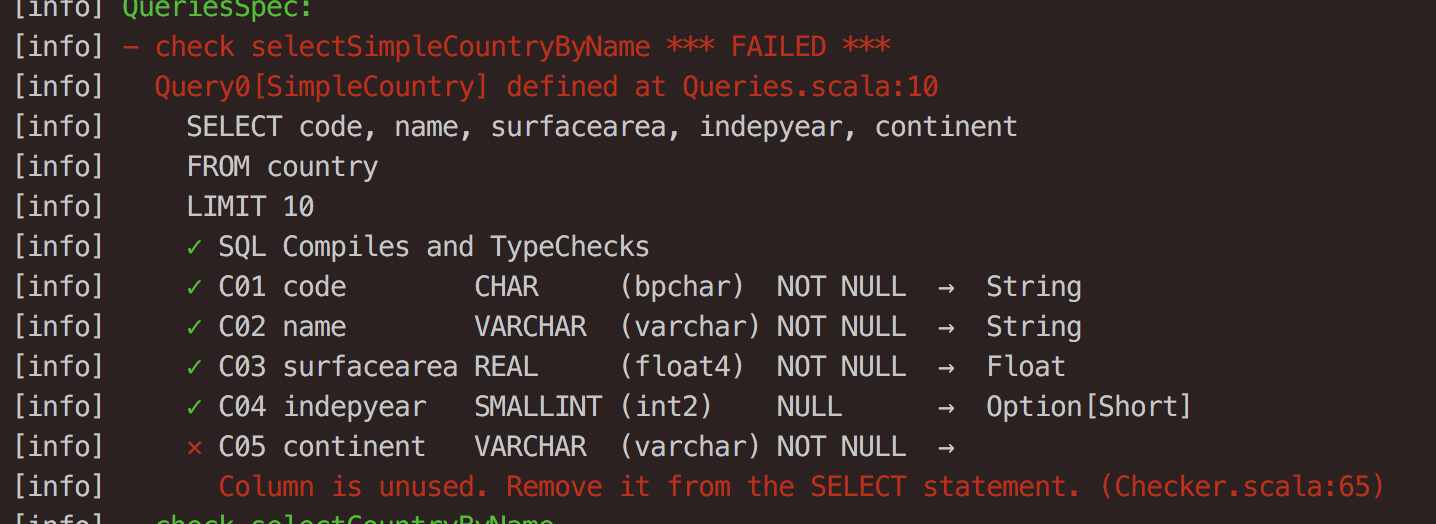
Die Leichtigkeit, mit der Sie Ihre Abfragen testen können, macht dies zu einer großartigen Funktion von doobie.
Parametrisierte Abfragen
Es ist ziemlich einfach, Parameter zu Ihren Abfragen hinzuzufügen. Nehmen wir zum Beispiel an, dass wir unsere ursprüngliche Abfrage wie oben definiert erweitern möchten, indem wir ein konfigurierbares Limit festlegen und nur Länder abfragen möchten, die nach einem bestimmten Jahr unabhängig wurden:
def selectCountries(unabhängigNach: Kurz, Grenze: Lang) = sql""" SELECT code, name, flächenbereich, indepyear AUS Ländern WHERE indepyear > $independentAfter LIMIT $limit """.Abfrage[Land]
Diese wird tatsächlich in eine PreparedStatement umgewandelt, bei der die Eingabeparameter getrennt von der eigentlichen Abfrage gesendet werden. Gleichzeitig wird dadurch die Lesbarkeit Ihrer Abfrage erheblich verbessert.
Hier gibt es einen Haken. Hin und wieder möchten Sie Ihre Abfragen dynamisch aufbauen. In diesem Fall sollten Ihre Parameter Teil der Abfrage und nicht Teil der Eingabedaten sein. Um dieses Problem zu lösen, bietet doobie mit Fragments eine feinere Möglichkeit, Ihre Abfrage zu konstruieren. Nehmen wir an, dass Sie (als künstliches Beispiel) zwei Tabellen mit Länderdaten haben. Je nach Kontext wollen Sie entweder aus der einen oder aus der anderen Tabelle lesen:
def selectCountriesFrom(Tabelle: Zeichenfolge, Grenze: Lang) = (const(""" SELECT code, name, flächenbereich, indepyear FROM $Tabelle""") ++ fr""" LIMIT $limit """).Abfrage[Land]
Der von doobie gewählte Ansatz ist klar, aber mir persönlich lenkt diese const() Funktion zu sehr vom interessanten Teil ab. Bei dem Projekt unseres Kunden zogen wir es vor, eine implizite Konvertierung zu verwenden, um normale Strings mit Fragments einfach zu verketten:
implizit def stringToConst(str: Zeichenfolge) = const(str) def selectCountriesFrom(Tabelle: Zeichenfolge, Grenze: Lang) = ( """SELECT code, name, oberflächenbereich, indepyear FROM $Tabelle""" ++ fr""" LIMIT $limit""" ).Abfrage[Land]
Dies sollte natürlich mit Vorsicht verwendet werden, denn Sie wollen nicht versehentlich in SQL-Injection-Probleme geraten!
Passen Sie auf!
Bis jetzt habe ich Ihnen gezeigt, wie hilfreich doobie sein kann. Die Prägnanz und Einfachheit der Zuordnung, die doobie bietet, hat jedoch auch einen Nachteil, dessen Sie sich bewusst sein sollten. Da doobie nur prüft, ob die Typen übereinstimmen und es keine explizite Zuordnung von einem benannten Feld in Ihrer Fallklasse zu einem Spaltennamen in der Tabelle gibt, ist es wichtig, dass Sie die Felder, die Sie abfragen, genau so anordnen wie die Reihenfolge in Ihrer Fallklasse (oder umgekehrt). Zum Beispiel, wenn ich habe:
Fall Klasse Foo(a: Zeichenfolge, b: Zeichenfolge) val Abfrage = sql"SELECT b, a FROM Foo").Abfrage[Foo]
Die Abfrage wird kompiliert, die Typen addieren sich, aber das Ergebnis entspricht nicht dem, was Sie wahrscheinlich beabsichtigt haben. Einige zusätzliche Unit-Tests zur Überprüfung des Inhalts Ihrer Ergebnisse sind daher ratsam!
Fazit
Die Verwendung von doobie ist sehr einfach und führt zu einem prägnanten und klaren Code. Es ist eine willkommene Ergänzung in meinem Toolset als Daten- und Softwareentwickler. Durch den Einsatz von doobie bei dem Projekt unseres Kunden haben wir:
- die zu pflegenden Zeilen des benutzerdefinierten Codes um ± 50% reduziert!
- viele (potenzielle) Fehler behoben, die durch Unstimmigkeiten bei den Typen zwischen der Datenbank und unseren Scala-Fallklassen entstanden.
- machte es einfach, asynchrone, hoffentlich nicht blockierende E/A bereitzustellen (dies hängt noch von der Implementierung des JDBC-Treibers ab!)
Die Code-Beispiele in diesem Blogpost sind (lose) einem vollständigen Beispielprojekt entnommen, das ich erstellt und hier zur Verfügung gestellt habe. Sie können es gerne klonen und sich umsehen. Eine ausführliche Dokumentation über doobie finden Sie auch in dem Buch von doobie




Contact