Blog
dbt-Tutorial: Analytik-Engineering leicht gemacht

Der Aufbau von Data Warehouses und die Durchführung von Analysen ist in vielen Unternehmen immer noch ein ungelöstes Problem. Glücklicherweise wird das Leben im heutigen Zeitalter von ETL ELT immer einfacher. Cloud-Anbieter stellen skalierbare Datenbanken wie Snowflake und BigQuery zur Verfügung, das Laden von Daten mit Tools wie
dbt hilft bei der Transformationsphase: Es zielt darauf ab, "Datenanalysten und -ingenieure in die Lage zu versetzen, Daten in ihren Warehouses effektiver zu transformieren". In den letzten Jahren ist die Kluft zwischen Dateningenieuren und Datenanalysten größer geworden. Ingenieure verwenden komplexere Tools und schreiben z.B. Datenpipelines mit Apache Spark in Scala. Auf der anderen Seite bevorzugen Analysten immer noch SQL und verwenden No-Code-Tools, die keine Best Practices wie die Versionierung von Code unterstützen. dbt schließt diese Lücke, indem es SQL erweitert und Tools für Datenumwandlungsmodelle bereitstellt.
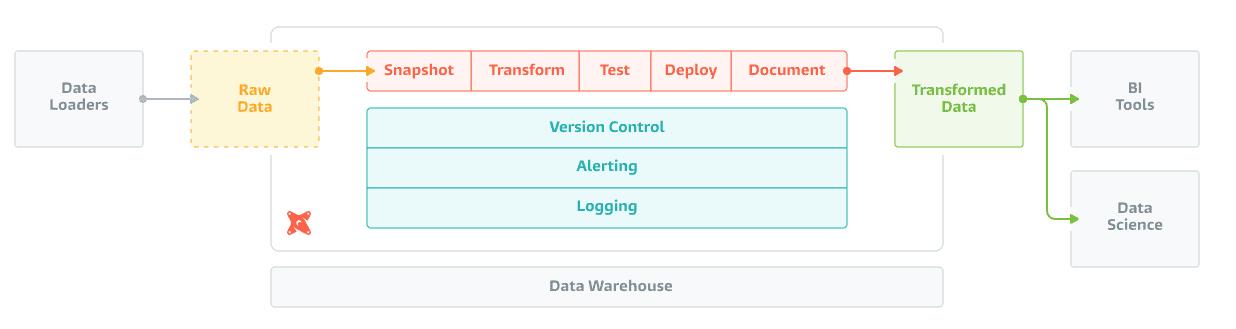
Daten in BigQuery laden
Richten Sie zunächst die Daten in der Landezone ein. Klonen
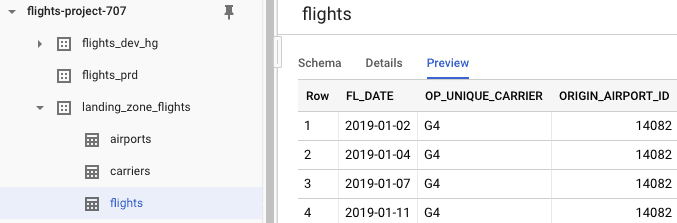
Der nächste Schritt besteht darin, die CSV-Dateien als Tabellen in BigQuery zu laden. Erstellen Sie in BigQuery ein neues Dataset landing_zone_flights und erstellen Sie Tabellen für jede der Dateien. Die Schemaerkennung wird für flights_prd und flights_dev_hg. (Ersetzen Sie hg durch Ihre eigenen Initialen und überprüfen Sie den Speicherort für beide Datensätze).
Die Daten und Tabellen sind nun eingerichtet. Sie sollten nun drei Datensätze und drei Tabellen in landing_zone_flights haben:
Entwicklungsumgebung einrichten
Nachdem Sie Ihre Daten eingerichtet haben, ist es an der Zeit, die Entwicklungsumgebung einzurichten. Erstellen Sie eine neue virtuelle Python-Umgebung mit ~/.dbt/profiles.yml und ändern Sie es so, dass es auf Ihre PRD- und DEV-Umgebung verweist. In der Dokumentation finden Sie Anweisungen zur Profilkonfiguration für BigQuery (vergessen Sie nicht die Autorisierung!).
Mein Profil ist flights und mein Standard-Laufziel ist dev. Sie müssen (mindestens) das Projekt und das Dataset ändern. Stellen Sie sicher, dass der Speicherort mit dem Speicherort Ihrer BigQuery-Datensätze übereinstimmt.
flights:
outputs:
prd:
type: bigquery
method: oauth
project: flights-project-707
dataset: flights_prd
location: EU # Optional, one of US or EU
dev:
type: bigquery
method: oauth
project: flights-project-707
dataset: flights_dev_hg
location: EU # Optional, one of US or EU
target: devIhre Umgebung ist nun einsatzbereit. Führen Sie dbt angewiesen, die in models/ definierten Datenmodelle zu kompilieren und auszuführen. Dies sollte erfolgreich abgeschlossen werden:
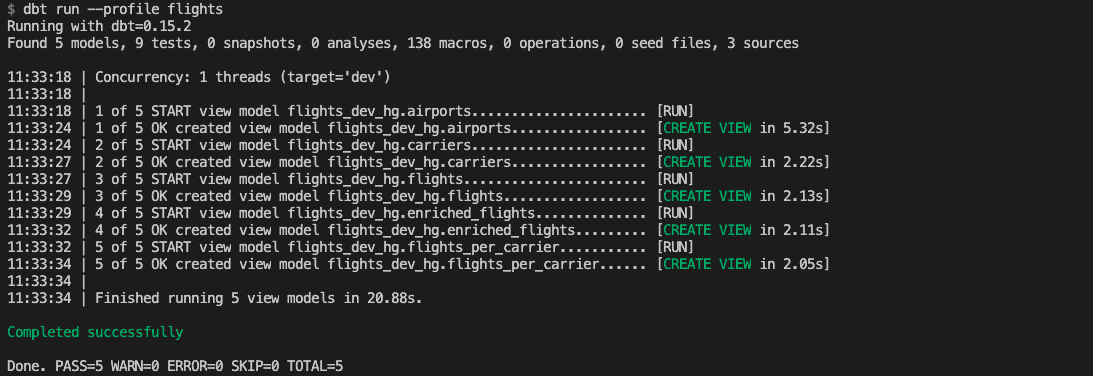
Datenquellen laden und testen
Der erste Schritt der Transformationsphase ist die Harmonisierung der Spaltennamen und die Korrektur falscher Typen. Die Extraktions- und Ladephase wurde manuell durchgeführt, indem die Daten in den Cloud-Speicher hochgeladen und die Landing-Zone-Tabellen in BigQuery erstellt wurden.
Navigieren Sie zu models/base und sehen Sie sich die SQL-Dateien an. Der Code ist recht einfach. Jede Datei enthält eine SELECT Anweisung, die eine Tabelle lädt und bei Bedarf Spalten umbenennt. Sie werden auch das erste Stück dbt-Magie sehen: Es gibt Jinja-Vorlagen in unseren SQL-Abfragen!
Anweisungen wie {{ source('landing_zone_flights', 'flights') }} beziehen sich auf Ihre Quelltabellen: die BigQuery-Tabellen. Diese Tabellen sind in schema.yml definiert, das Ihre Datenmodelle dokumentiert und testet. landing_zone_flights ist eine Quelle mit Definitionen und Dokumentation für die drei BigQuery-Tabellen. Einige Spalten werden auch auf Eindeutigkeit, Nichtvorhandensein von Nullwerten und Beziehungen innerhalb der Tabellen getestet. Die Tests helfen Ihnen sicherzustellen, dass Ihr Datenmodell nicht nur definiert, sondern auch korrekt ist.
Navigieren Sie zu flights.sql. Diese Datei enthält einen netten Trick, um die verarbeiteten Daten bei der Entwicklung zu begrenzen. Die if-Anweisung verwendet eine Variable, um zu prüfen, ob die Anweisung in der Entwicklung oder in der Produktion ausgeführt wird. Die Flugdaten sind auf den 01.01.03 2019 beschränkt, da Sie während der Entwicklung nicht alle Daten benötigen. Dies ist ein weiteres Beispiel dafür, wie dbt Jinja nutzt, um Dinge zu tun, die Sie normalerweise in SQL nicht tun können.
Die Quelltabellen werden in BigQuery als Ansichten (neu) erstellt, wenn Sie dbt run --profile flights ausführen. Führen Sie auf ähnliche Weise Tests mit dbt test --profile flights aus:
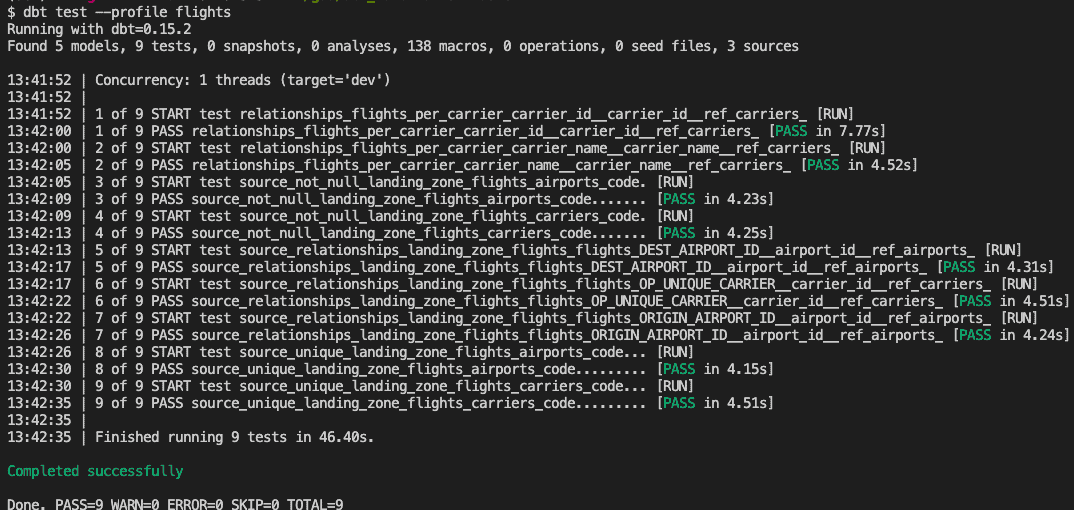
Sie haben nun die Daten in die DEV-Umgebung geladen und können die eingehenden Daten validieren. Versuchen Sie, die PRD-Umgebung aufzufüllen, indem Sie die
Daten transformieren
Unsere Abfragen in models/transform sind unseren Ladeabfragen recht ähnlich. Der größte Unterschied besteht darin, dass jetzt ref() verwendet wird, um auf Datenmodelle zu verweisen: dies ist die wichtigste Funktion in dbt. enriched_flights.sql reichert die Flugtabelle an, indem es die Quellentabellen und flights_per_carriers.sql kombiniert. In der Schemadefinition fehlen Definitionen und Tests für enriched_flights, was nicht mit den dbt-Kodierungskonventionen übereinstimmt - mein Fehler!
dbt verfügt auch über ein Dokumentationswerkzeug zur Überprüfung Ihrer Transformationen. Führen Sie die folgenden Befehle aus, um die Dokumentation zu erstellen und bereitzustellen:
$ dbt docs generate --profile flights
$ dbt docs serve --port 8001 --profile flights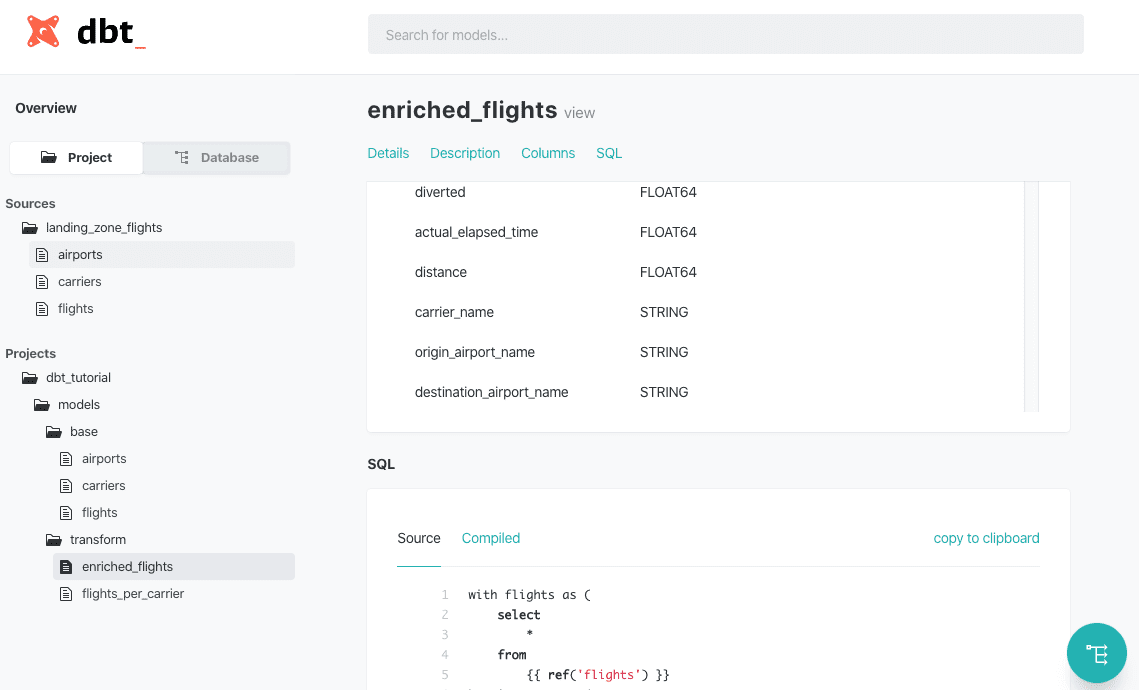
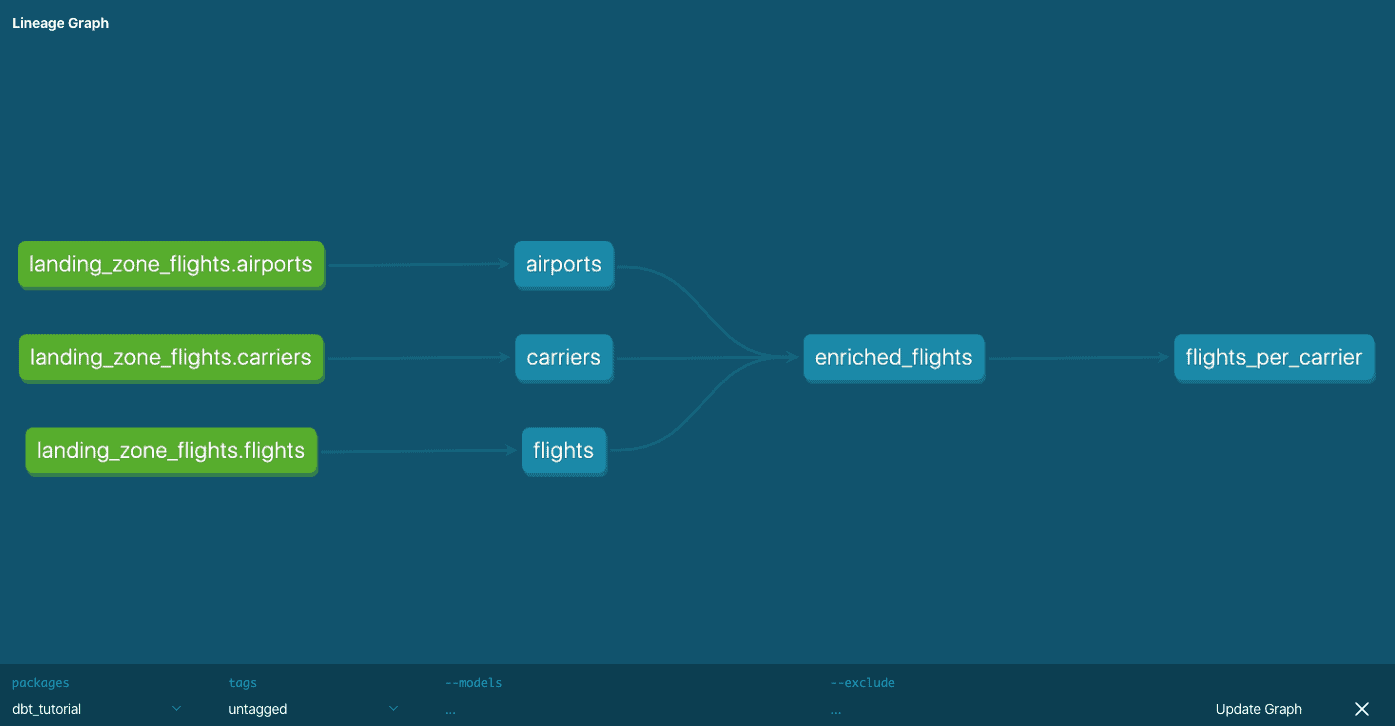
Es sollte sich eine neue Browser-Registerkarte mit der Dokumentation zu dem Projekt und der daraus resultierenden Datenbank öffnen. Die Projektübersicht zeigt die Quellen und Modelle, die in den SQL-Dateien definiert sind. Diese Übersicht enthält die Dokumentation und die Spaltendefinitionen, aber auch die ursprünglichen SQL-Abfragen und die kompilierten Versionen. Die Datenbankübersicht liefert die gleichen Ergebnisse, zeigt sie aber wie ein Datenbankexplorer an. Ganz unten rechts in der Ecke finden Sie das Lineage-Tool, das Ihnen einen Überblick darüber gibt, wie Modelle oder Tabellen miteinander in Beziehung stehen. Die Dokumentation wird einfach als statische HTML-Seite exportiert, so dass sie leicht mit der gesamten Organisation geteilt werden kann.
Fazit
Dieses Tutorial hat Ihnen die Grundlagen von dbt mit BigQuery gezeigt. dbt unterstützt viele andere Datenbanken und Technologien wie Presto, Microsoft SQL Server und Postgres. Unser Team hat
Vielen Dank an Robert Rodger und Daniël Heres für die Rezension dieses Blogs!
Mögen Sie dbt, müssen aber größere Pipelines pflegen? ? Kommen Sie zu uns und erfahren Sie, wie Apache Spark Ihnen dabei helfen kann.
Verfasst von
Henk Griffioen




Contact