Blog
Durch das Spiegelglas: Das Wunderland des Testens von KI-Systemen erforschen

Systeme der Künstlichen Intelligenz (KI) werden allgegenwärtig: von selbstfahrenden Autos über Risikobewertungen bis hin zu großen Sprachmodellen (LLMs). Da wir uns immer mehr auf diese Systeme verlassen, sollte das Testen bei der Einführung oberste Priorität haben.
Software nicht zu testen ist wie einen Scheck auszustellen, ohne den Betrag oder den Empfänger zu überprüfen. Sie können es beim ersten Mal richtig machen, aber Sie überprüfen lieber zweimal, um böse Überraschungen oder sogar katastrophale Ergebnisse zu vermeiden. Nehmen Sie zum Beispiel den Code-Bug, der die Knight Capital Group in den Ruin getrieben hat, weil sie in weniger als einer Stunde 460 Millionen Dollar verloren hat. KI-Systeme sind sogar noch anfälliger, da sie neben dem Code auch Daten und Algorithmen nutzen. Sie müssen also alle Komponenten testen, um Pannen zu vermeiden.
KI ist jedoch die Domäne von Datenwissenschaftlern, die nicht für ihre Fähigkeiten beim Schreiben von Tests bekannt sind - langweilige Details im Vergleich zur Wissenschaft. Man sollte ihnen helfen, in multidisziplinären Teams zu testen, da diese Systeme abteilungsübergreifend aufgebaut und gewartet werden.
Um Verlangsamungen zu vermeiden, müssen die Tester die Verantwortung für das gesamte Projekt übernehmen und sich auf die Bereiche konzentrieren, in denen die geschäftlichen Anforderungen und Risiken am größten sind. Dieser Ansatz stellt sicher, dass sie sich einbringen. In diesem Artikel erfahren Sie, wo Sie ansetzen können und was erforderlich ist, um eine Überdosis Kamille zu vermeiden, damit Sie nachts schlafen können.
Systeme der Künstlichen Intelligenz (KI) und des Maschinellen Lernens (ML) werden allgegenwärtig: von selbstfahrenden Autos über Risikobewertungen bis hin zu großen Sprachmodellen (LLMs). Da wir immer abhängiger von diesen Systemen werden, sollte das Testen für Organisationen und Regierungen, die sie einsetzen, oberste Priorität haben. Sie ungeprüft zu lassen, ist so, als würde man einen Scheck ausstellen, ohne den Betrag oder den Empfänger zu überprüfen. Prüfen kann lästig sein, aber ein Fehler kann fatal sein.
Niederländische Eltern mit doppelter Staatsbürgerschaft wissen das nur zu gut. Ein KI-System, das von der Regierung geschult wurde, um Betrug bei der Kinderbetreuung zu erkennen, diskriminierte diese Elterngruppe. Die Folgen für die diskriminierten Familien waren tragisch. Einige mussten ihre Häuser und ihr Hab und Gut verkaufen. Das niederländische Kabinett trat inmitten der Auswirkungen zurück.
Tests verhindern Überraschungen
Um Überraschungen zu vermeiden, sollten KI-Systeme getestet werden, indem sie mit Daten aus der realen Welt gefüttert werden.
Wenn eine neue Systemversion fertig ist, stellen die Tests sicher, dass sie weiterhin korrekt funktioniert. Und das Testen von Software ist für Regierungen und Unternehmen gleichermaßen wichtig. Im Jahr 2012 verlor die Knight Capital Group aufgrund eines Fehlers in ihrer Handelssoftware 460 Mio. USD (damals 360 Mio. EUR). Da niemand in der Lage war, den Fehler zu erkennen, brach schnell Chaos aus: Innerhalb einer Stunde war das Unternehmen bankrott. Heute ist nur noch ein Wikipedia-Eintrag übrig, kaum ein Vermächtnis für einen Konzern mit einem Einkommen von Hunderten von Millionen Dollar. Das Unternehmen ist inzwischen ein Paradebeispiel dafür, warum man Software testen sollte.
Warum ist diese Praxis dann nicht weiter verbreitet?
KI-Systeme sind komplizierter als Software allein; sie enthalten Daten, Code und Algorithmen. Der Algorithmus ist ein mathematisches Verfahren, das beschreibt, wie man von den Daten zur Ausgabe gelangt. Um zum Beispiel zu wissen, wie viel Steuern wir schulden, wendet das Finanzamt einen Algorithmus an, um unser Bruttoeinkommen in eine kleinere Version von sich selbst (das Nettoeinkommen) umzuwandeln. Die Lücke, also wie viel wir schulden, ist die Ausgabe des Algorithmus. Der Code ist die Übersetzung des Algorithmus in Befehle, die ein Computer verstehen und ausführen kann. Beim maschinellen Lernen gibt es noch eine weitere Zutat: Die Algorithmen werden auf der Grundlage der Muster in den Daten optimiert. Wenn zum Beispiel die Muster verzerrt sind, wird auch das Ergebnis verzerrt sein - wie im Fall des niederländischen Betrugs mit Kinderbetreuungsgeld.
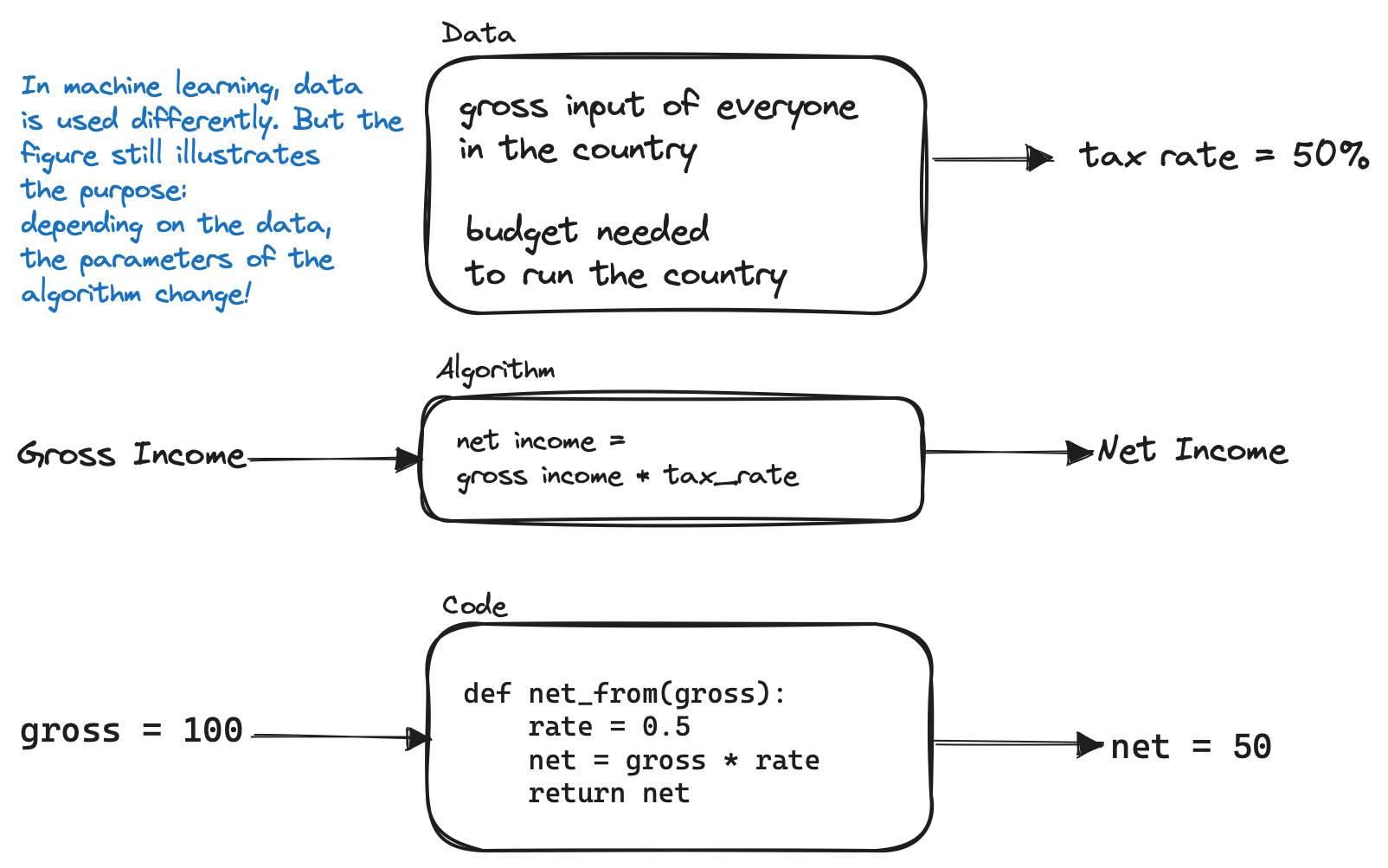
Testen Sie die Daten, den Code und den Algorithmus.
Alle drei Komponenten - Daten, Code und Algorithmus - müssen getestet werden, um sicherzustellen, dass das System ordnungsgemäß funktioniert.
Lassen Sie uns mit den Daten beginnen. Zu den Dingen, die schief gehen können, gehören:
- Voreingenommenheit in den Daten - als mangelnde Repräsentation einer Minderheitengruppe .
- Wir könnten Variablen falsch interpretieren - ist der "Betrag" in USD oder EUR?
- Die zugrundeliegenden Daten könnten abweichen - vielleicht tritt ein Konkurrent in den Markt ein und zerstört die Genauigkeit der Verkaufsprognose. Die frühzeitige Erkennung dieser Leistungsabweichungen wird unterschätzt.
Auf der Seite des Codes könnten wir Fehler haben, die so einfach sein könnten wie das Vertauschen von Einnahmen und Kosten bei der Berechnung des Gewinns.
Und auf der Seite der Algorithmen gibt es häufig Probleme:
- Verwendung eines für die Daten ungeeigneten Algorithmus. Statistische Eigenschaften der Daten, wie z.B. der Durchschnitt und der Median, könnten einige Algorithmus Klassen ausschließen.
- Vergessen Sie zu untersuchen, ob verschiedene Parameter die Leistung des Modells verbessern.
Diese Listen sind leider nicht erschöpfend. Suresh und Guttag, zwei Forscher am MIT, haben kürzlich eine Arbeit veröffentlicht, die sich mit den Auswirkungen von Verzerrungen in ML-Systemen befasst. Das Ergebnis war eine Auflistung von sieben Bereichen des ML-Lebenszyklus, die von Voreingenommenheit beeinflusst werden.
Für einen technischeren Überblick haben Sato, Wider und Windheuser, drei ML-Praktiker, die bei Thoughtworks und Databricks arbeiten, einen umfassenden Artikel über Continuous Delivery von ML-Anwendungen geschrieben.
Was ist mit LLMs?
Das jüngste Interesse an LLMs hat deutlich gemacht, dass sie zusätzliche Herausforderungen mit sich bringen:
- Die Verarbeitung natürlicher Sprache ist mehrdeutig, und da LLMs nicht verstehen, was wir ihnen sagen, kommt die Reproduzierbarkeit nicht aus der Box.
- Die Abwärtskompatibilität ist nicht garantiert. Möglicherweise benötigen Sie zusätzliche Arbeit , um sicherzustellen, dass die Dinge in der Produktion nicht kaputt gehen. Wenn zum Beispiel die Entwickler, die hinter dem LLM stehen, das Sie nutzen, einige Prüfungen hinzufügen, um die Beantwortung einer Klasse von Fragen zu verweigern, könnte Ihr System zusammenbrechen, wenn Sie die Änderung nicht frühzeitig bemerken.
Sogar Microsoft, heute dank der Partnerschaft mit OpenAI der unbestrittene Marktführer in diesem Bereich, wurde kurz nach der Markteinführung von unerwünschtem Verhalten in seinem Bing AI Chatbot heimgesucht. Das Unternehmen hat jedoch seine Lehren daraus gezogen und die richtigen Kontrollen und Tests eingeführt, um sicherzustellen, dass neue Versionen nicht die gleichen Macken aufweisen.
Eine entmutigende Aussicht
Der Umfang und die Tragweite des Themas erscheinen erschreckend, vor allem wenn man die wichtigste Kraft hinter den KI-Systemen betrachtet: die Datenwissenschaftler. Ihre Rolle hat sich erst kürzlich herauskristallisiert. Wie der Name schon sagt, kommen die meisten von ihnen aus dem akademischen Bereich, wo Softwaretests nicht gerade in Mode sind, im Gegensatz zur Veröffentlichung von Arbeiten. Und um erfolgreich zu veröffentlichen, muss die Arbeit besser sein als frühere Arbeiten. Die ganze Aufmerksamkeit gilt daher der Logik und Methodik und nicht der Korrektheit des Codes. Das Testen wird zu einem irrelevanten Ärgernis. In der Industrie ist das Hauptziel jedoch nicht die Leistung, sondern der Wert, den das Modell erzeugt. Ein Modell für maschinelles Lernen, das 5 % ungenauer ist als das der Konkurrenz, ist immer noch nützlich; die Unternehmen machen die Differenz an anderer Stelle wieder wett. Aber um Überraschungen zu vermeiden, wie sie der Knight Capital Group widerfahren sind, werden Tests benötigt.
Das Problem für Datenwissenschaftler mit akademischem Hintergrund wird - wie wir in unserer Praxis routinemäßig beobachten - durch Manager verschärft, die sich auf neue Funktionen konzentrieren und Tests als Hindernis betrachten. Hinzu kommt die weit verbreitete Unkenntnis darüber, wie man gut testet, und es ergibt sich ein Bild, bei dem alle Beteiligten mit dem Finger aufeinander zeigen.

Und es sind nicht nur Datenwissenschaftler, die testen sollten.
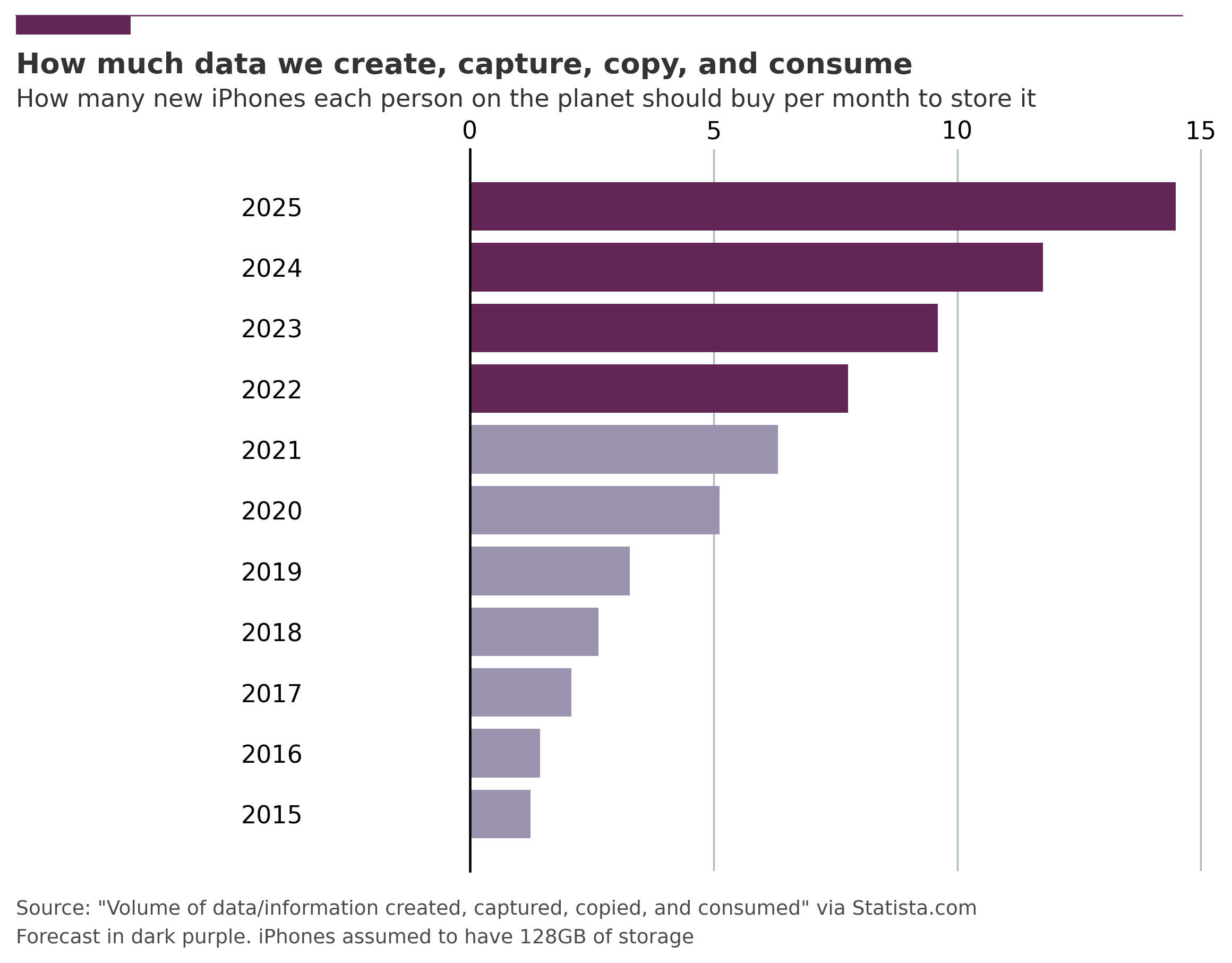
Da sich KI-Systeme über mehrere Abteilungen erstrecken, tragen mehrere Rollen zum richtigen Testen bei: Software- und Plattformingenieure für den Code und die Plattform, auf der er läuft, und Dateningenieure (eine bestimmte Art von Ingenieuren, die auf datenintensive Anwendungen spezialisiert sind) für die Daten. Leider verstehen sich diese Profile nicht immer gegenseitig. Während Datenwissenschaftler nur schwer begreifen, warum man testen sollte, ist Ingenieuren oft nicht klar, wie sich ML-Systeme von reinen Softwaresystemen unterscheiden und wie man mit ihnen umgeht. Und jeder sollte sich darüber im Klaren sein, dass das Testen von Daten eine Herausforderung ist, die nur noch wichtiger wird, vor allem wenn man bedenkt, wie viel wir produzieren (siehe Abbildung
End-to-End-Tests
Ein KI-System umfasst in der Regel mehrere Komponenten: Die Daten befinden sich in Datenbanken, der Code und der Algorithmus in zentralen Repositories (spezialisierten Datenbanken) und das Wissen über die Daten und die damit verbundenen Prozesse bei den Geschäftsinteressenten. Und zwar nicht nur von einer einzigen Abteilung: Verkaufsdaten können in maschinellen Lernmodellen verwendet werden, die von der Finanzabteilung eingesetzt werden, um die Marketingausgaben besser zu verteilen.
Diese krakenähnlichen Systeme sind jedoch effizienter, wenn sie von einem einzigen Team ohne externe Blocker durchgängig getestet werden.
Um dies zu erreichen, müssen interne Barrieren und die Silo-Mentalität durchbrochen werden. Zyniker werden argumentieren, dass es einfacher ist, einen Schneemann in der Wüste am Schmelzen zu hindern, aber die Herausforderung zu ignorieren bedeutet, den Kopf im Wüstensand zu vergraben. Ein Top-Down-Ansatz könnte sich als praktischer erweisen: Wenn die Führungskräfte den Plan entwerfen, wird die Organisation diese starren Barrieren durchbrechen und flüssiger werden - hoffentlich im Gegensatz zu unserem Schneemann.
Gewinnen Sie die Skeptiker für sich
Eine Änderung der Organisation, um die Sicherheit von KI-Systemen zu gewährleisten, scheint entmutigend.
Aber genau wie ein Lehrling langsam in sein Handwerk eingeführt wird, müssen Unternehmen nicht alles auf einmal ändern. Sie können dort beginnen, wo die Auswirkungen am größten und das Risiko am geringsten ist, und schrittweise vorgehen. Einige Komponenten können zunächst manuell oder mit anderen Abteilungen getestet werden - auf Kosten der Geschwindigkeit. Wenn das Vertrauen der Organisation wächst, gehen Sie einen Schritt weiter. Automatisieren Sie einen manuellen Prozess oder erhöhen Sie die Eigenverantwortung des Teams. Wenn das KI-System für eine Abteilung lebenswichtig ist, machen Sie sie zu Ihrem Partner. Wenn Sie offen sind und erklären, warum Tests notwendig sind (Sie können gerne auf diesen Artikel verweisen), werden Sie viele Skeptiker überzeugen. Sagen Sie ihnen, was schief gehen könnte, wenn es schief geht. Und wenn alles andere fehlschlägt, fragen Sie sie, ob sie diejenigen sind, die das Unternehmen wegen ihrer Sturheit in den Bankrott treiben.
Verfasst von
Giovanni Lanzani




Contact