Blog
Drei Tipps für datenzentrierte KI und eine Lektion in Datenwissenschaft

Worum geht es bei datenzentrierter KI?
Andrew Ng (Mitbegründer von Coursera, Google Brain, deeplearning.ai, landing.ai) ist vor allem für seinen Kurs Maschinelles Lernen auf Coursera bekannt. Er lehrt die Grundlagen des maschinellen Lernens, wie man Modelle erstellt und wie man sie verwendet, um mit großer Genauigkeit Vorhersagen zu treffen.
Vor kurzem hat er das Konzept der datenzentrierten KI eingeführt. Die Idee dahinter ist, dass er Ihren Datensatz nicht als feststehend betrachtet und sich ausschließlich auf die Verbesserung Ihrer Modelleinrichtung konzentriert, sondern sich auf die Verbesserung Ihres Datensatzes konzentriert. Er argumentiert, dass dies oft sehr viel effektiver ist, um Ihre Leistung zu verbessern.
Gibt es einen Wettbewerb?
Andrew Ng macht Data Centric AI mit einem Wettbewerb populär. Die Idee ist, dass Sie einen Datensatz mit Bildern von handgezeichneten römischen Ziffern und ein festes Modellskript erhalten, das Sie nicht ändern dürfen. Sie können nur Änderungen am Datensatz vornehmen. Sie können zum Beispiel Datenpunkte hinzufügen, Beschriftungen von bestehenden Datenpunkten ändern und die Aufteilung zwischen Training und Validierung festlegen.
Wir haben an diesem Wettbewerb teilgenommen und schneiden ganz gut ab: Wir sind etwa 2% von den Spitzenreitern entfernt. Wir bewundern den Aufwand, den die Teilnehmer betreiben, um ihren Datensatz so zu bearbeiten, dass sie die höchste Punktzahl erreichen.
Drei Tipps für datenzentrierte KI
In diesem Blogbeitrag teilen wir einige der Tricks, die wir während des Wettbewerbs verwendet haben. Wir hoffen, dass sie für die anderen Teams interessant sind, aber noch wichtiger für andere Datenexperten. Wir glauben, dass sie zeigen, wie Data Centric AI die Datenwissenschaft als Beruf verändern wird.
Tipp 1: Verwenden Sie Low-Tech-Tools, um gemeinsam loszulegen
Wir haben Google Sheets zum Korrigieren der Etiketten verwendet, weil wir damit alle notwendigen Informationen leicht darstellen konnten.

Wir haben einen großen Projektor verwendet, um gemeinsam zu beschriften, was einige großartige Diskussionen ausgelöst hat. Wäre dies ein Projekt für einen Kunden, würden wir die sich daraus ergebenden Fragen an die Fachexperten weitergeben, um unser Verständnis des Problems zu verbessern.
Tipp 2: Verwenden Sie Einbettungen, um ein Gefühl für Typizität und stilistische Unausgewogenheit zu bekommen
Zunächst ein netter Trick, um ein Ungleichgewicht zu erkennen. Nehmen Sie ein vortrainiertes Computer-Vision-Modell, nehmen Sie die Einbettungen in der letzten Schicht und projizieren Sie sie dann mit UMAP auf zwei Dimensionen. Das Ergebnis wird wahrscheinlich jedes Ungleichgewicht in Ihren Daten aufzeigen.
Im Folgenden haben wir diese Einbettungen visualisiert, damit Sie sie mit Altair interaktiv erkunden können. Wenn Sie ein Auswahlfenster über das Diagramm ziehen und bewegen, können Sie sehen, welche Bilder sich darunter befinden.
Sie können sich die interaktive Version hier ansehen (Warnung: Langsames Laden). Sie finden ein Snippet mit dem unterstützenden Code hier.
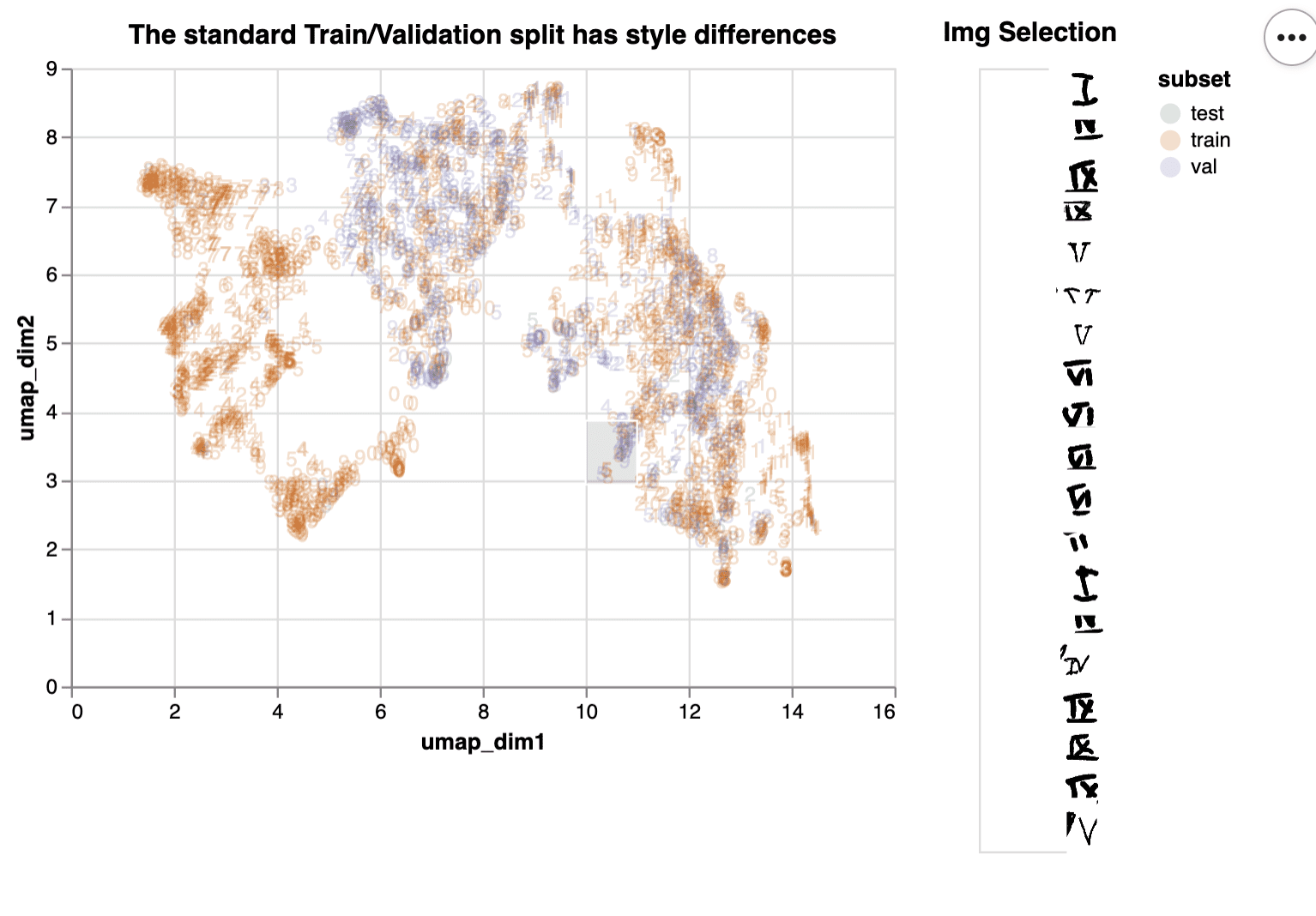
Aus diesem Diagramm können wir ersehen, dass die Aufteilung zwischen Training und Validierung nicht ausgewogen ist, da die Bilder des Validierungssets nicht ähnlich wie das Trainingsset verteilt sind (kein Lila auf der linken Seite).
Eine andere Möglichkeit, diese Einbettungen zu verwenden, besteht darin, verschiedene römische Ziffern zu finden, die im gleichen Stil gezeichnet sind. Das kann ein hübsches Diagramm ergeben, aber es hilft auch dabei, herauszufinden, auf welche Bilder Sie sich konzentrieren sollten, wenn Sie grundlegende Tricks zur Datenerweiterung anwenden, wie z. B. Spiegeln, Drehen, Zoomen, Zuschneiden oder Unschärfe.
Tipp 3: Verwenden Sie Streamlit zur Datenerweiterung
Wir haben festgestellt, dass die Links-Rechts-Spiegelung und die Top-Down-Spiegelung als Augmentierungstechniken recht gut funktionieren. Aber nicht alle römischen Ziffern eignen sich für diesen Ansatz (ich schaue Sie an: VII, VIII und IX). Dafür haben wir uns den folgenden einfachen Trick ausgedacht: Wir haben eine Streamlit-App mit dem Streamlit-drawable-canvas-Plugin erstellt, mit dem Sie Bilder ganz einfach nacheinander erweitern können.
Die Strategie, die wir uns ausgedacht haben, war folgende:
- Nehmen Sie ein Bild von einer römischen 8: VIII
- Löschen Sie das V, und speichern Sie das III
- Löschen Sie dann das rechte I und speichern Sie das II
- Löschen Sie dann das rechte I und speichern Sie das I
- Verwenden Sie Ihre gespeicherten Bilder von V, I und II, um synthetische VI und VII zu erstellen.

Wir hosten diese App nicht, aber Sie finden das Snippet, um sie auf Ihrem eigenen Rechner zum Laufen zu bringen , hier
Das Schöne an dieser Strategie ist, dass Sie recht schnell neue Daten erstellen können. Das ist vor allem für die Bilder interessant, mit denen sich Ihr vorheriges Modell schwer getan hat (z.B. die VIIIer, die fälschlicherweise als VIIer klassifiziert wurden). In gewisser Weise erzeugen Sie kontrafaktische Daten, die Ihrem Modell helfen, den Unterschied zwischen den beiden Klassen zu erkennen.

Welche Lektion gibt es zu lernen?
Neben diesen Tipps gibt es noch eine grundlegende Lektion zu lernen: Kommunikation ist der Schlüssel. Alle Personen, die daran beteiligt sind, die Modellvorhersagen an die Benutzer weiterzugeben, müssen über das Problem kommunizieren, um das Endergebnis zu verbessern. Data Centric AI zeigt, wie das geht: durch die Sprache der Daten. Data Centric AI holt die Datenwissenschaftler aus ihrem Elfenbeinturm (oder Keller), wo sie isoliert über die Hyperparameter des Modells iterieren. Es beginnt Gespräche: Was sehen wir hier? Warum ist das so beschriftet? Warum würde das Modell diese Fehler machen? Fragen, die Sie nicht allein beantworten, sondern gemeinsam mit Fachleuten.
Für gute Datenwissenschaftler ist das nichts Neues, aber wir freuen uns, dass es jetzt eine Bezeichnung für diese Perspektive gibt: "Datenzentrierte KI".
Einpacken
Die Teilnahme am Data Centric AI-Wettbewerb hat uns viel Spaß gemacht. Wir wünschen den anderen Wettbewerbern, die auf der Jagd nach den letzten Prozentpunkten sind, viel Glück. Wenn eines der hier vorgestellten Konzepte für Sie nützlich war, würden wir uns freuen, von Ihnen zu hören.
Und schließlich an alle Datenwissenschaftler da draußen: Seien Sie kreativ und entwickeln Sie Tools, mit denen Sie Gespräche über die Daten führen können! Diese Gespräche erhöhen das gemeinsame Verständnis und helfen Ihnen, das eigentliche Problem zu lösen.
Verfasst von
Rens Dimmendaal




Contact