Blog
Das Paradox der Zuverlässigkeit: Warum weniger mehr sein kann

Sie haben den Wechsel von On-Premise in die Cloud vollzogen, und Ihre Anwendung läuft wie geschmiert. In echter DevOps-Manier konzentrieren Sie sich auf die Entwicklung und den Betrieb der Anwendung und haben daher bestimmte Vorkehrungen getroffen: Wiederholungsmechanismen, schnelle Failover und intelligente Warnregeln wurden implementiert. Auch wenn die Ausfallsicherheit des Systems verbessert wurde, sollten wir uns vor der Annahme hüten, dass wir die Zuverlässigkeit des Systems vollständig unter Kontrolle haben.
Wenn wir Kunden fragen, wie zuverlässig ihre Anwendung sein soll, liegen die Erwartungen meist bei 100 %. Das wäre in der Tat wünschenswert, aber ist dies wirklich ein Ziel, das es wert ist, verfolgt zu werden? Welchen Preis sind wir bereit, für übermäßig hohe Verfügbarkeitsziele zu zahlen? Um diese Frage zu beantworten, sollten wir uns einen Überblick über die Vor- und Nachteile einer Verschärfung oder Lockerung der Zuverlässigkeitsziele verschaffen. Konzentrieren Sie sich auf die richtigen Dinge? Wer entscheidet, wie zuverlässig Ihre Anwendung sein soll? Und gibt es einen Nachteil bei zu viel Zuverlässigkeit?
Was ist zuverlässige Software?
Moderne Anwendungen basieren auf mehreren Cloud-Komponenten. Diese werden in der Regel mit einem Service Level Agreement (SLA) von drei Neunen (99,9%) oder dreieinhalb Neunen (99,95%) geliefert. Lassen Sie uns als Beispiel das Zusammenspiel von Azure App Service und einer zugrunde liegenden SQL-Datenbank betrachten. Beide Dienste haben eine garantierte Betriebszeit von 99,95, so dass pro Monat etwa 21 Minuten Ausfallzeit zulässig sind. Unsere Anwendung muss sich bei beiden Diensten korrekt verhalten, um vollständig zuverlässig zu sein.
Da diese Komponenten unabhängig voneinander sind, kann der App-Dienst am Montag von 06:00 bis 06:20 Uhr und die Azure SQL-Datenbank am darauffolgenden Tag von 14:20 bis 14:40 Uhr ausfallen. Da die Dienste zu unterschiedlichen Zeiten ausfallen können, ist die
Dann kommunizieren alle Anwendungskomponenten über das Netzwerk, von dem wir wissen, dass es nicht immer zuverlässig ist. Es gibt viele mechanische oder menschliche Fehler oder Naturkatastrophen, die zu Ausfällen ganzer Rechenzentren führen können. Das bedeutet, dass unsere Systeme ein inhärentes Risiko der Nichtverfügbarkeit aufweisen, das von den Entwicklern, dem Unternehmen und den Endbenutzern akzeptiert werden muss (und normalerweise auch wird). Wir sollten daher davon ausgehen, dass jede moderne Anwendung ein gewisses Maß an Unzuverlässigkeit aufweist. Aber das muss uns nicht stressen. Wir werden sehen, dass die Auswirkungen dieser (oft kurzzeitigen) Ausfälle geringer sind als allgemein angenommen.
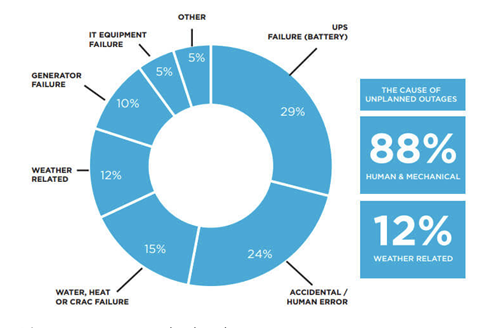
(Überwindung der Ursachen für Ausfälle im Rechenzentrum/)
Es gibt Architekturmuster, die verwendet werden können, um die Auswirkungen auf den Benutzer bei bestimmten Themen zu minimieren.
Sollten wir anfangen, deutlich mehr für Angebote zur Datenredundanz (wie z.B. geozonenredundante Speicher) zu bezahlen, um unsere Unzuverlässigkeit auf ein absolutes Minimum zu reduzieren? Wir sind der Meinung, dass dies immer eine geschäftliche Entscheidung sein sollte, die sich auf die geschäftlichen Auswirkungen bestimmter Ausfälle konzentriert.
Bestimmte Fehler in unserer Anwendung können auftreten, ohne dass der Benutzer davon betroffen ist. Wie wichtig sind diese Probleme? Wir sollten nicht nach Perfektion streben, sondern die Korrelation zwischen Unzuverlässigkeit und Benutzerzufriedenheit herausfinden. Um das herauszufinden, sollten wir uns mit den Auswirkungen von Fehlern befassen - wann ist es wirklich wichtig?
Das Risiko des Scheiterns in Kauf nehmen
Das Anstreben höherer Zuverlässigkeitsziele mag für Produktverantwortliche wie ein vernünftiges (und ehrgeiziges) Ziel erscheinen. Wir möchten Ihnen vermitteln, dass es nicht immer richtig ist, höhere Ziele zu setzen, und dass dies mit hohen und versteckten Kosten verbunden sein kann. Wenn wir die Zuverlässigkeit unseres Systems von 99,9 % auf 99,95 % verbessern wollen und die Anwendung einen Jahresumsatz von 500.000 € generiert, dann ist eine vernünftige Schätzung der zusätzlichen Einnahmen nur 250 €.
Außerdem gibt es viele Szenarien, in denen kleine Unzuverlässigkeiten keine spürbaren Folgen haben. Wenn Ihr LinkedIn-Feed unglaublich langsam dargestellt wird, drücken Sie wahrscheinlich F5 und schon ist das Problem gelöst. Es gibt viele Szenarien, bei denen weder wirtschaftliche Faktoren noch die Benutzerzufriedenheit Gefahr laufen, drastisch reduziert zu werden. Konzentrieren wir uns auf ein Beispiel aus dem Lager, bei dem es um die Verfügbarkeit geht!

Es versteht sich von selbst, dass Endbenutzer Wert auf Zuverlässigkeit legen. Wir sollten uns jedoch ein realistisches Bild davon machen, welche Erwartungen die Kunden an die Anwendung haben. Wenn der Effekt einer Verbesserung der Zuverlässigkeit von drei auf vier Neunen (99,9 auf 99,99 Prozent) durch die Unzuverlässigkeit externer Faktoren vernebelt wird (wodurch die zusätzliche Zuverlässigkeit unbemerkt bleibt), dann können wir vernünftigerweise zögern, die Zuverlässigkeit zu verbessern. Es wäre für unsere Endbenutzer fruchtbarer gewesen, wenn wir unsere Zeit entweder in die schnelle Entwicklung neuer Funktionen, in eine geringere Latenzzeit oder in den Abbau der aufgelaufenen technischen Schulden investiert hätten. Die wichtigsten Dinge, die es zu überwachen gilt, sollten sich auf die Auswirkungen auf die Benutzer und das Geschäft konzentrieren und nicht auf technische Fehler.
Volle Zuverlässigkeit ist übertrieben, ein einziger Datenbankausfall ist katastrophal und diese Ungewissheit führt zu unmittelbarem Stress bei Ihren Mitarbeitern. Es gibt Möglichkeiten, die Zuverlässigkeit zu verbessern, aber dies sollte immer ein Gespräch zwischen dem Geschäftsinhaber und den technischen Teams sein, die die Anwendung erstellen und verwalten.
Definition von Zielen, die für Kunden wichtig sind
Anstatt uns auf zu hohe Zuverlässigkeitsziele zu konzentrieren, sollten wir unsere Erfahrung und unseren gesunden Menschenverstand nutzen, um darüber nachzudenken, welches Serviceniveau wir unseren Kunden bieten wollen.
Die bekannten Service Level Agreements (SLAs) werden durch Service Level Indicators (SLIs) und Objectives (SLOs) untermauert.
Zwar kann jede messbare Größe zu einem Indikator erhoben werden, aber wir empfehlen, nur einige wenige gute Indikatoren auszuwählen . Diese sollten das umfassen, was die Benutzer in der Anwendung für wichtig halten. Es ist in der Regel eine gute Idee, sich von der Kundenerfahrung zu den SLIs zurückzuarbeiten, anstatt Ziele auf der Grundlage der gesammelten Daten festzulegen. Google empfiehlt, dass die nützlichsten Indikatoren für den Zustand Ihres Systems folgende sind: Latenz, Traffic, Fehler und Sättigung, die sie als goldene Signale der Überwachung bezeichnet haben. Diese Indikatoren haben gemeinsam, dass sie sich alle auf die internen Strukturen Ihrer Anwendung beziehen.
Der Trick besteht darin, sich nicht in den Anomalien unseres internen Systems zu verlieren, sondern sich in den Übersetzungsprozess für unsere Endbenutzer einzubringen. Der Fehlerindikator lässt sich beispielsweise nicht immer direkt auf die Benutzererfahrung übertragen, aber es ist eine faire Wette, dass die folgenden Service-Level-Indikatoren stark mit der Benutzerzufriedenheit korreliert sind:
- Latenzzeit (niemand möchte 2 Sekunden auf jede HTTP-Anfrage warten);
- Verfügbarkeit (2% Ausfallzeit sind einfach zu viel);
- Durchsatz (es sollte nicht zu lange dauern, Bilder hochzuladen);
- Korrektheit (Ihr Einkaufswagen sollte Ihre ausgewählten Artikel anzeigen ).
Jetzt ist es an der Zeit, Zielvorgaben für diese Indikatoren zu formulieren, um festzustellen, wie viel Unzuverlässigkeit vernünftigerweise toleriert werden kann, und natürlich werden wir uns die Auswirkungen auf die Kunden ansehen. Ein häufig begangener Fehler ist die Bildung von Zielen auf der Grundlage von Durchschnittswerten. Das ist problematisch, denn die Verteilungen unserer Indikatoren sind in der Regel rechtsschief, d.h. die ersten 1% der Benutzer verhalten sich etwas besser und die letzten 1% haben unglaublich langsame Antworten von mehreren Sekunden.
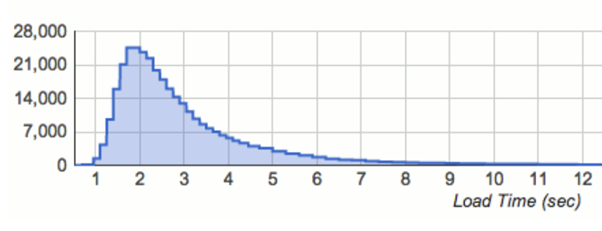
(Quelle: www.lognormal.com)
Das Risiko eines weitreichenden rechten Endes ist eine berechtigte Sorge, und unserer Erfahrung nach ist es sinnvoll, Ziele für hohe Perzentile (z.B. 95%, 99% oder sogar 99,9%) statt für Durchschnittswerte zu erstellen. Dies beruht auf der Überlegung, dass jeder Benutzer eine gute Erfahrung macht, wenn die Worst-Case-Szenarien vernünftige Erfahrungen aufweisen.

Während die Indikatoren für verschiedene Systeme in der Regel gleich sind, kommen die Ziele ins Spiel. Unsere Ziele spiegeln sich in den SLA wider, und das setzt Erwartungen für die Kunden, die unseren Service auf der Grundlage dieser Erwartungen auswählen können oder auch nicht. Kunden haben andere Erwartungen an benutzerorientierte Systeme (Webshops, soziale Medien) als an Archivierungssysteme und, um ein anderes Beispiel zu nennen, an Big Data-Verarbeitungssysteme wie Apache Spark.
Für die Endbenutzer sind diese Indikatoren sicherlich wichtig, aber es gibt nicht immer eine triviale Zuordnungsfunktion dieser Indikatoren zur Kundenerfahrung. Es würde mehr Aufschluss geben, dies aus einem funktionalen Blickwinkel zu betrachten , d.h. wie erleben die Benutzer die Anwendung? Wenn Sie zu viel Zeit auf die Optimierung der Zuverlässigkeit des Systems verwenden, bleibt weniger Zeit für die schnelle Innovation von Funktionen, für Automatisierung und Experimente.
Ein gutes Beispiel ist Outlook im Vergleich zu Youtube. Die erste Anwendung wird von Unternehmen auf der ganzen Welt für die Kommunikation genutzt, und sie erwarten, dass der Dienst hochverfügbar ist. Youtube hingegen wird nicht für kritische Zwecke verwendet. Die Nutzer mögen sich zwar über eine geringere Betriebszeit ärgern, aber das wird wahrscheinlich durch die positiven Erfahrungen mit schnellen Fehlerbehebungen und neuen Funktionen aufgewogen. Aus ähnlichen Gründen hat Google auch niedrigere Zuverlässigkeitsziele für Youtube als für Gmail festgelegt.
An diesem Punkt sollten wir ein Gefühl für die Festlegung vernünftiger SLOs haben. Was sollten wir als nächstes tun? Der nächste Schritt besteht darin, ein perfektes Gleichgewicht zwischen Zuverlässigkeit und Innovation zu finden!
Den goldenen Mittelweg zwischen Zuverlässigkeit und Innovation finden
Fehlerbudgets beruhen auf der Vorstellung, dass ein gewisses Maß an Unzuverlässigkeit akzeptabel ist. Azure SQL strebt beispielsweise ein Verfügbarkeitsziel von 99,95% an, was bedeutet, dass eine Ausfallzeit von 21,6 Minuten pro Monat zulässig ist. Diese 21,6 Minuten stellen ihr monatliches Fehlerbudget dar. Wo früher Ausfälle ein belastendes Ereignis waren, das sofort untersucht werden musste, besagen die modernen Prinzipien des Site Reliability Engineering, dass alles unter Kontrolle ist
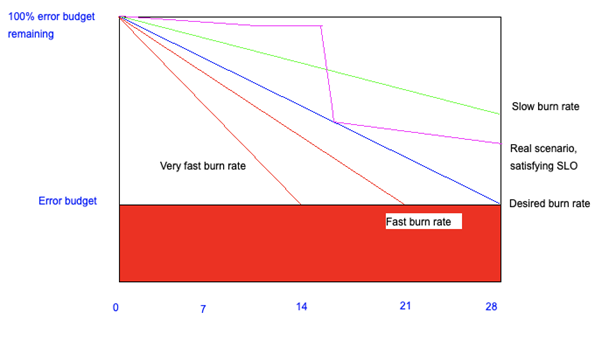
Diese Illustration zeigt die akzeptable Verbrennungsrate (die blaue Linie) und zwei inakzeptabel hohe Verbrennungsraten (+25% und +50%). Die grüne Linie hingegen zeigt einen positiveren Trend an: eine Verbrennungsrate, mit der wir unser Ziel leicht erreichen würden. Werfen wir nun einen Blick auf unser tatsächliches Fehlerbudget beim Verbrennen - die lila Linie. In den ersten zwei Wochen verbrauchen wir allmählich ein wenig von unserem Fehlerbudget. Dann wird aufgrund eines Sommerzeitfehlers an Tag 14 eine übermäßige Menge des Fehlerbudgets verbraucht, so dass wir bei unserer akzeptablen Abbrandrate stehen bleiben. Das bedeutet, dass wir an diesem Punkt vorsichtiger sein müssen und wir beschließen, unsere Veröffentlichungsgeschwindigkeit zu verringern. Nach einer Woche (Tag 21) stellen wir fest, dass wir viel besser abschneiden als die blaue Linie, wir können sogar wieder mehr Risiko in Kauf nehmen .
Ohne ein Fehlerbudget hätte das Unternehmen wahrscheinlich gedacht, dass wir nicht genug Wert liefern - das System war eine ganze Weile lang unzuverlässig! Die Änderung der Philosophie mit einem Fehlerbudget hat spürbare Vorteile. Die Ingenieurteams können sicher arbeiten und sich auf ihre Arbeit konzentrieren, und niemand wird alarmiert, wenn ein Bruchteil des Fehlerbudgets verbrannt ist. Interessanterweise können wir sogar behaupten, dass der größte Teil des Fehlerbudgets genutzt werden sollte, was eine hervorragende Gelegenheit zum Experimentieren bietet. Heutzutage gilt es unter Site Reliability Engineers sogar als Best Practice, keine wesentlich höhere Verfügbarkeit als unser Ziel anzustreben, da dies falsche Erwartungen für die Zukunft weckt.
Das Fehlerbudget erinnert uns daran, dass Unzuverlässigkeit nicht immer unerwünscht ist. Tatsächlich sorgt es sogar für eine
Handlungsfähige Metriken als Gespräch zwischen Unternehmen und Technik
Ein großer Vorteil von Service Level Objectives und Fehlerbudgets ist unserer Meinung nach, dass sie realistische Erwartungen an das System schaffen, auf die sich die Ingenieure und der Product Owner geeinigt haben. Außerdem wird dadurch ein großer Teil der Subjektivität aus den Gesprächen über den Zustand der Anwendung entfernt: Wir wissen genau, wie viele Fehler zulässig sind, ohne dass die Endbenutzer mit dem Produkt unzufrieden sind.
Das Anstreben übermäßig hoher Zuverlässigkeitsziele hat noch ein weiteres Problem: Es steht im Widerspruch zum Wunsch nach neuen Funktionen. Die Entwicklung von Funktionen ist unter dem Gesichtspunkt der Zuverlässigkeit ziemlich gefährlich:
- die Komplexität des Produkts nimmt mit jeder neuen Funktion zu;
- Jede Codeänderung ist mit Risiken verbunden und verändert den (als zuverlässig angenommenen) Zustand der Produktion.
Während Entwicklungsteams nach ihrer Geschwindigkeit bei der Entwicklung von Funktionen bewertet werden, kann es zu Spannungen zwischen Geschäfts- und Entwicklungsteams kommen. Ein Fehlerbudget ist ein sehr effektives Mittel, um ein Gleichgewicht zwischen Zuverlässigkeit und Innovation herzustellen. Wenn das Fehlerbudget eingehalten wird, sollten wir nicht zögern, zu entwickeln und zu implementieren. Das System verhält sich wie erwartet, und unsere Endbenutzer sind sicher froh, wenn neue Funktionen schnell zur Verfügung stehen!
Wenn wir auf dem richtigen Weg sind, sollten wir uns ermutigt fühlen, zu experimentieren. Das Risiko der entstandenen Unzuverlässigkeit wird durch den Wert aufgewogen, den unsere Experimente für die Benutzer (oder für das Entwicklungsteam durch die Automatisierung wiederkehrender Aufgaben) haben.
Lassen Sie uns einen Blick auf neue Technologien werfen. Diese haben oft das Potenzial, der Anwendung einen großen Mehrwert zu verleihen, bergen aber auch ein Risiko für die Zuverlässigkeit des Systems. Lassen Sie uns einige konkrete Beispiele nennen:
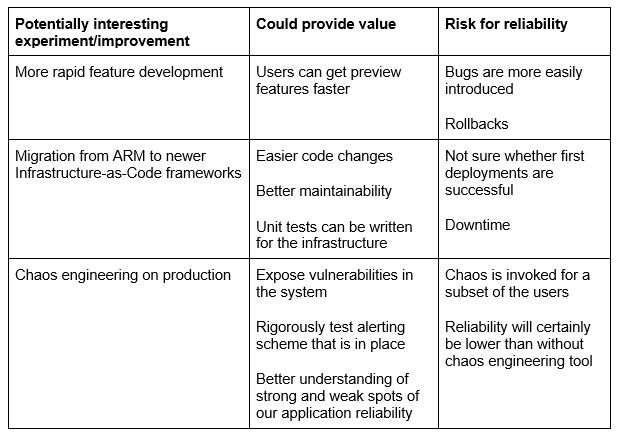
Da wir zum Experimentieren ermutigt werden, wissen wir, wann wir ein Risiko zum Wohle der Allgemeinheit eingehen dürfen!
Starten Sie mit der Zuverlässigkeitstechnik in Ihrer Anwendung!
Wir haben Beispiele dafür gezeigt, dass SLOs die Erwartungen an die Funktionsweise des Systems erhöhen und dass eine Lockerung der SLOs Vorteile haben kann. Fehlerbudgets helfen uns bei der Einschätzung, wie viel Zeit wir für Innovationen und wie viel für die Verbesserung der Zuverlässigkeit aufwenden können. Die Erwartung voller Zuverlässigkeit ist mit unerwünschten Kosten verbunden, von denen wir einige hervorgehoben haben:
- Erhöhter Stress bei den Mitarbeitern:
- Wenn sich das System nicht einwandfrei verhält (auch wenn niemand die Anwendung zu diesem Zeitpunkt benutzt).
- Widerstand gegen die Entwicklung von Funktionen - was, wenn etwas bei der Produktion kaputt geht?
- Die Erwartungen der Kunden:
- In der Regel nicht so hoch wie allgemein angenommen.
- Sie tolerieren gelegentliche Schluckaufs im System.
- Der Kompromiss zwischen Zuverlässigkeit und Innovation
- Unternehmen und Endbenutzer legen nicht nur Wert auf Zuverlässigkeit, sondern auch auf andere Aspekte.
- Die Festlegung vernünftiger Zuverlässigkeitsziele ermöglicht es uns, intelligente Kompromisse zu schließen.
- Diese Ziele zu erreichen bedeutet, dass wir Risiken eingehen und experimentieren können (neue Technologien einsetzen, Dinge automatisieren, schneller bereitstellen usw.), was die Produktivität und die Zufriedenheit der Benutzer erhöhen kann.
Wir hoffen, dass dieser Artikel vielen Unternehmen als Gesprächsanstoß dient, damit Ingenieure und Unternehmen gemeinsam über Zuverlässigkeit nachdenken und gemeinsam die richtigen Entscheidungen treffen, um eine Anwendung zu entwickeln, die so zuverlässig ist wie erforderlich.
Verfasst von
Geert van der Cruijsen
Contact