Blog
Strukturierung Ihres dbt-Projekts für KI-gestützte Entwicklung

KI-Codierassistenten verändern die Art und Weise, wie wir Software schreiben und pflegen. Im Bereich der Analysetechnik eignen sich dbt-Projekte besonders gut für die Entwicklung von KI. Sie sind sehr konventionslastig, SQL-zentriert und enthalten viele sich wiederholende Aufgaben wie das Schreiben von Tests, die Dokumentation von Spalten und die Durchsetzung von Namensstandards. Aber wenn Sie einfach einen KI-Agenten in Ihr dbt-Projekt einfügen, werden Sie keine großartigen Ergebnisse erzielen. Um einen echten Nutzen zu erzielen, müssen Sie Ihr Repository so strukturieren, dass KI-Agenten darin effektiv arbeiten können.
In diesem Beitrag erfahren Sie, wie Sie ein dbt-Projekt für die KI-gestützte Entwicklung strukturieren. Als Grundlage dient das GitHub-Repository pgoslatara/dbt-ai, das ich für meine Präsentation auf dem NL dbt Meetup erstellt habe : 15th Edition. Die hier beschriebenen Ideen und Prozesse können mit vielen Tools nachgebildet werden - die Demo verwendet GitHub, GCP und Claude Code, weil sie kostenlos sind, großzügige kostenlose Tiers haben und/oder weit verbreitet sind. Sie können ähnliche Setups mit vielen anderen Tools wie Azure DevOps, Gemini, Cortex, Snowflake usw. replizieren.
Ein Nordstern für KI im dbt
Bevor Sie sich mit dem Wie beschäftigen, sollten Sie das Warum klären. Das Ziel ist ganz einfach:
"Wir sollten eine Welt anstreben, in der KI die sich wiederholende, regelbasierte Arbeit übernimmt, damit sich Menschen auf die Geschäftslogik und die Architektur konzentrieren können."
In einem dbt-Projekt gehören zu den sich wiederholenden und regelbasierten Arbeiten Namenskonventionen, Testabdeckung, Dokumentation, SQL-Formatierung, PR-Review-Checklisten und vieles mehr. Die Geschäftslogik - wie eine Faktentabelle zu modellieren ist, wann eine inkrementelle Materialisierung zu verwenden ist, welche Geschäftsfragen die Marts beantworten sollen - profitiert in hohem Maße vom menschlichen Urteilsvermögen. Die KI wird immer leistungsfähiger und es gibt eine wachsende Zahl von Integrationen, aber die besten Verfahren sind noch nicht sehr ausgereift. Die im Folgenden beschriebene Struktur ist darauf ausgelegt, die Effektivität eines KI-Agenten bei regelbasierten Aufgaben zu maximieren.
Erste Schritte
Hier sehen Sie das Verzeichnislayout eines dbt-Projekts, das für die KI-Entwicklung strukturiert ist, wobei die KI-spezifischen Komponenten hervorgehoben sind:
.
├── .claude/
│ ├── commands/ # Slash commands for interactive development
│ ├── settings.local.json # Hooks and permission configuration
│ └── skills/ # Multi-step analytical protocols
├── .github/workflows/ # CI/CD and agentic workflows
├── .mcp.json # MCP server configuration
├── models/
│ ├── staging/
│ ├── intermediate/
│ └── marts/
├── CLAUDE.md # AI project instructions
├── dbt-bouncer.yml # Convention enforcement rules
├── dbt_project.yml
└── pyproject.toml
Die Standardstruktur von dbt (models/, dbt_project.yml, profiles.yml) bleibt unverändert. Die KI-Komponenten ergänzen sie und fügen neue Funktionen hinzu, ohne die Funktionsweise von dbt selbst zu verändern. Schauen wir uns die einzelnen Komponenten an.
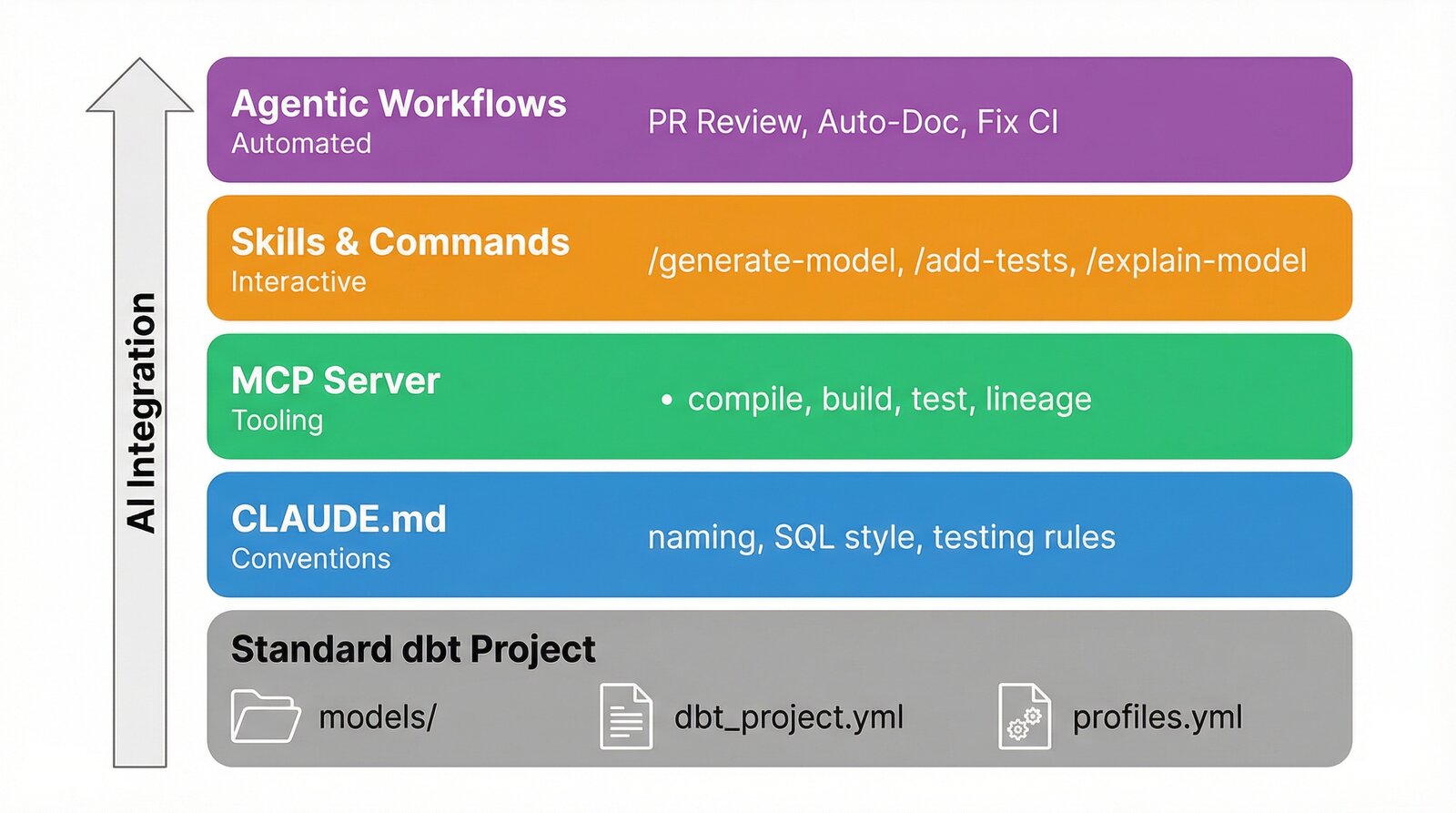
Sie müssen nicht alles auf einmal implementieren. Hier finden Sie einen praktischen Weg zur Einführung von KI-gestützter Entwicklung in Ihrem dbt-Projekt:
- Beginnen Sie mit
CLAUDE.md: Dokumentieren Sie Ihre Konventionen. Dies ist die Maßnahme mit der größten Hebelwirkung, da sie sowohl der KI als auch den menschlichen Entwicklern zugute kommt. Ihre bestehendeREADME.mdoder Confluence-Dokumentation ist ein guter Ausgangspunkt. - Fügen Sie den dbt MCP-Server hinzu: Der dbt MCP-Server ermöglicht es AI-Agenten, Ihr Projekt direkt zu kompilieren, zu erstellen und zu testen. Die Installation besteht aus einer einzigen Konfigurationsdatei.
- Wählen Sie einen agentischen Workflow: Der KI-PR-Review-Workflow ist eine gute erste Wahl - er bietet sofortigen Nutzen für jede Pull-Anfrage und erfordert nur eine minimale Einrichtung über ein Claude Code OAuth-Token hinaus.
- Fügen Sie Skills und Befehle schrittweise hinzu: Wenn Sie sich wiederholende Muster in Ihrem Entwicklungsablauf feststellen, kodieren Sie diese als Fertigkeiten oder Schrägstrichbefehle.
- Mit Hooks durchsetzen: Sobald Ihre Konventionen dokumentiert sind, fügen Sie Hooks hinzu, um sie während der KI-unterstützten Entwicklung automatisch durchzusetzen.
Die folgenden Abschnitte führen Sie durch diese Optionen.
1. CLAUDE.md: AI Ihre Konventionen lehren
Die Grundlage der KI-gestützten dbt-Entwicklung ist eine CLAUDE.md Datei im Stammverzeichnis Ihres Repositorys. Diese Datei enthält projektspezifische Anweisungen, die Claude liest, bevor er eine Arbeit ausführt. Betrachten Sie sie als Einführungsdokumentation für Ihren KI-Paar-Programmierer, ähnlich den Konventionen, die Sie mit Tools wie dbt-bouncer durchsetzen können, aber in natürlicher Sprache für Claude geschrieben.
Eine gute CLAUDE.md für ein dbt-Projekt umfasst:
-
Konventionen zur Namensgebung
Definieren Sie die Benennungsmuster für jede Ebene Ihres Projekts und folgen Sie dabei den Empfehlungen der dbt. Legen Sie Präfixe, Trennzeichen und Entitätsnamen fest.
-
SQL-Stil
Dokumentieren Sie Ihre SQL-Formatierungspräferenzen: Schlüsselwort-Casing, CTE-Muster, Join-Alias-Konventionen und Regeln für Spalten pro Zeile.
-
Materialisierungsregeln
Legen Sie fest, welche Materialisierung jede Ebene verwenden soll und wann Sie inkrementelle Modelle wählen.
-
Anforderungen an Tests und Dokumentation
Geben Sie an, welche Mindestanforderungen Sie an die Testabdeckung stellen, welche Testpakete Sie verwenden (z.B. dbt_expectations) und welche Dokumentationsstandards für Modelle und Spalten gelten.
-
Befehle zur Entwicklung
Listen Sie die Befehle auf, die ein Entwickler (Mensch oder Claude) zum Linting, Formatieren und Erstellen des Projekts verwenden sollte.
Hier ist ein Auszug aus dem Demoprojekt CLAUDE.md:
## Naming Conventions
- Staging models: `stg_<source>__<entity>.sql`
- Intermediate models: `int_<entity>.sql`
- Dimension tables: `dim_<entity>.sql`
- Fact tables: `fct_<entity>.sql`
- Source YAML: `_<source>__sources.yml`
- Model YAML: `_<layer>__models.yml` or `_<source>__models.yml`
## SQL Style
- Lowercase for column and table names using `snake_case`
- One column per line in `select` statements
- Always alias tables in joins
- Use CTEs over nested subqueries
- CTE pattern: `source` → `renamed` → `select` for staging models
Die wichtigste Erkenntnis ist, dass diese Anweisungen Claude nicht nur dabei helfen, besseren Code zu schreiben, sondern dass sie auch die gleichen Konventionen kodieren, die Ihre menschlichen Entwickler befolgen, wodurch eine einzige Quelle der Wahrheit dafür geschaffen wird, wie das Projekt gepflegt werden sollte. Und das Beste daran ist, dass Claude sie bei jedem Aufruf lädt, so dass jeder Entwickler jederzeit Zugriff auf all diese Vorteile hat!
2. Der dbt MCP-Server: Claude Zugang zu dbt geben
Eine CLAUDE.md Datei sagt Claude, was zu tun ist, aber es muss trotzdem die Möglichkeit haben, direkt mit dbt zu interagieren. Das Model Context Protocol (MCP) ermöglicht dies, indem es KI-Agenten erlaubt, externe Tools zu verwenden. Der dbt MCP Server von dbt Labs gibt dem Agenten Zugriff auf dbt CLI-Befehle, Modell-Metadaten, Lineage und die semantische Schicht.
Die Konfiguration ist eine einzelne JSON-Datei (.mcp.json) im Stammverzeichnis Ihres Repositorys:
{
"mcpServers": {
"dbt": {
"command": "uvx",
"args": ["dbt-mcp"],
"env": {
"DBT_PATH": ".venv/bin/dbt",
"DBT_PROJECT_DIR": "."
}
}
}
}
Sie müssen keinen langwierigen, ständig aktiven Prozess im Hintergrund laufen lassen. Nur eine einzige JSON-Datei.
Mit dieser Konfiguration kann Claude Modelle kompilieren, Tests ausführen und das Projektmanifest überprüfen, ohne dbt manuell aufrufen zu müssen. Besonders leistungsfähig ist dies in Kombination mit Slash-Befehlen, die es Claude ermöglichen, das Projekt zu kompilieren, die manifest.json zu lesen und Änderungen anhand des echten Schemas zu validieren. Dadurch werden halluzinierte Tabellen- oder Spaltenverweise erheblich reduziert und gleichzeitig die Verwendung von Token und die Gesamtlaufzeit verringert.
3. Fertigkeiten und Slash-Befehle: Interaktive Entwicklung
Neben den grundlegenden CLAUDE.md und MCP Server können Sie Claude wiederverwendbare Fähigkeiten für allgemeine Entwicklungsaufgaben zur Verfügung stellen. Community-Plugins wie dbt-agent-skills von dbt Labs bieten einen guten Ausgangspunkt (ich empfehle den Skill using-dbt-for-analytics-engineering ), und Sie können Ihre eigenen projektspezifischen Fähigkeiten in zwei Formen erstellen:
-
Fertigkeiten
Mehrstufige analytische Protokolle, die in
.claude/skills/gespeichert sind. Diese kodieren , wie Claude über eine Klasse von Problemen denkt und werden auf natürliche Weise durch Konversation oder durch einen Slash-Befehl ausgelöst. Sie sind ideal für Aufgaben, die Analyse und Urteilsvermögen erfordern, nicht nur für die Codegenerierung. -
Schrägstrich-Befehle
Benutzerinitiierte Verknüpfungen, die in
.claude/commands/gespeichert sind. Diese folgen einem vorhersehbaren, vorgefertigten Ausgabemuster und sind ideal für Aufgaben, die Artefakte erzeugen oder verändern. Sie werden vom Entwickler explizit aus dem Claude-Terminal über/name-of-slash-commandaufgerufen.
Das dbt-ai Demo-Projekt enthält Beispiel-Skills und Slash-Befehle. Hier sind einige Beispiele:
Hier ist ein Beispiel für eine Fähigkeit, die ein dbt-Modell erklärt:
# dbt-explain-model
Explain the dbt model `$ARGUMENTS` in plain English.
1. Read the model's SQL file and understand its transformations.
2. Read the model's YAML file for descriptions and tests.
3. Identify upstream dependencies by finding `ref()` and `source()` calls.
4. Identify downstream dependents by searching for `ref('$ARGUMENTS')`.
5. Produce a summary covering:
- **Purpose**: What this model does and its business value.
- **Lineage**: What feeds into it and what consumes it.
- **Key transformations**: Computed columns, joins, aggregations.
- **Data quality**: What tests protect this model.
- **Materialisation**: How it's materialised and why.
Und hier ist der /generate-staging-model Schrägstrich-Befehl:
Generate a staging model for the source `$ARGUMENTS`.
1. Look up the source table schema in BigQuery or the source YAML.
2. Create the staging SQL file following the CTE pattern:
- `source` CTE: `SELECT * FROM {{ source('<source_name>', '<table_name>') }}`
- `renamed` CTE: rename columns to snake_case, cast types, add `city` column
- Final `SELECT * FROM renamed`
3. Create or update the source and model YAML files with descriptions and tests.
4. Place files in `models/staging/<source_name>/`.
5. Follow all naming conventions from CLAUDE.md.
Das Muster "Fähigkeit zur Analyse, Befehl zur Anwendung" ermöglicht es den Entwicklern, Empfehlungen zu überprüfen, bevor sie sich zu Änderungen verpflichten. Zum Beispiel analysiert /suggest-tests fct_trips das Modell und empfiehlt fehlende Tests, während /add-tests fct_trips die Tests direkt anwendet.
4. Haken: Die KI-Ausgabe konsistent halten
Selbst mit klaren Anweisungen kann Claude SQL erzeugen, das nicht Ihren Formatierungsstandards entspricht. Hooks lösen dieses Problem, indem sie nach jedem Schreiben oder Bearbeiten einer Datei automatische Prüfungen durchführen. Im Demoprojekt überprüft ein PostToolUse Hook die SQL-Formatierung nach jedem Schreibvorgang:
{
"hooks": {
"PostToolUse": [
{
"matcher": "Write|Edit",
"hooks": [
{
"type": "command",
"command": "if echo \"$CLAUDE_FILE_PATHS\" | grep -q '\\.sql$'; then uv run sqlfmt --check $CLAUDE_FILE_PATHS 2>/dev/null || echo 'sqlfmt: formatting issues detected'; fi"
}
]
}
]
}
}
Dadurch wird sichergestellt, dass jede von Claude geschriebene oder geänderte SQL-Datei anhand der sqlfmt-Formatierungsregeln überprüft wird, so dass der Agent sofort eine Rückmeldung über die vorgenommenen Änderungen erhält. Sie können mehrere Hooks hinzufügen, z.B. zum Formatieren von YAML-Dateien, zum Abspielen eines Tons, sobald eine Aufgabe abgeschlossen ist, oder sogar zum Hinzufügen einer Benachrichtigung in der Statusleiste Ihres Laptops, sobald Claude eine Aufgabe abgeschlossen hat. Hooks sind auch fantastisch geeignet, um die Sicherheit Ihrer Claude-Einrichtung zu erhöhen, indem sie beispielsweise Force-Pushes in Ihrer Git-Historie und das Auslesen von Anmeldeinformationen in Ihrer .env Datei verhindern.
5. Agentische Arbeitsabläufe: KI in Ihrer CI/CD-Pipeline
Die oben genannten Komponenten beziehen sich auf einen Entwickler, der lokal mit Claude arbeitet. Claude kann aber auch autonom in Ihrer CI/CD-Pipeline über die Claude Code GitHub Action laufen. Das Demoprojekt implementiert mehrere agentenbasierte Arbeitsabläufe, die ohne menschliches Zutun ablaufen.
Auf Pull-Anfrage
-
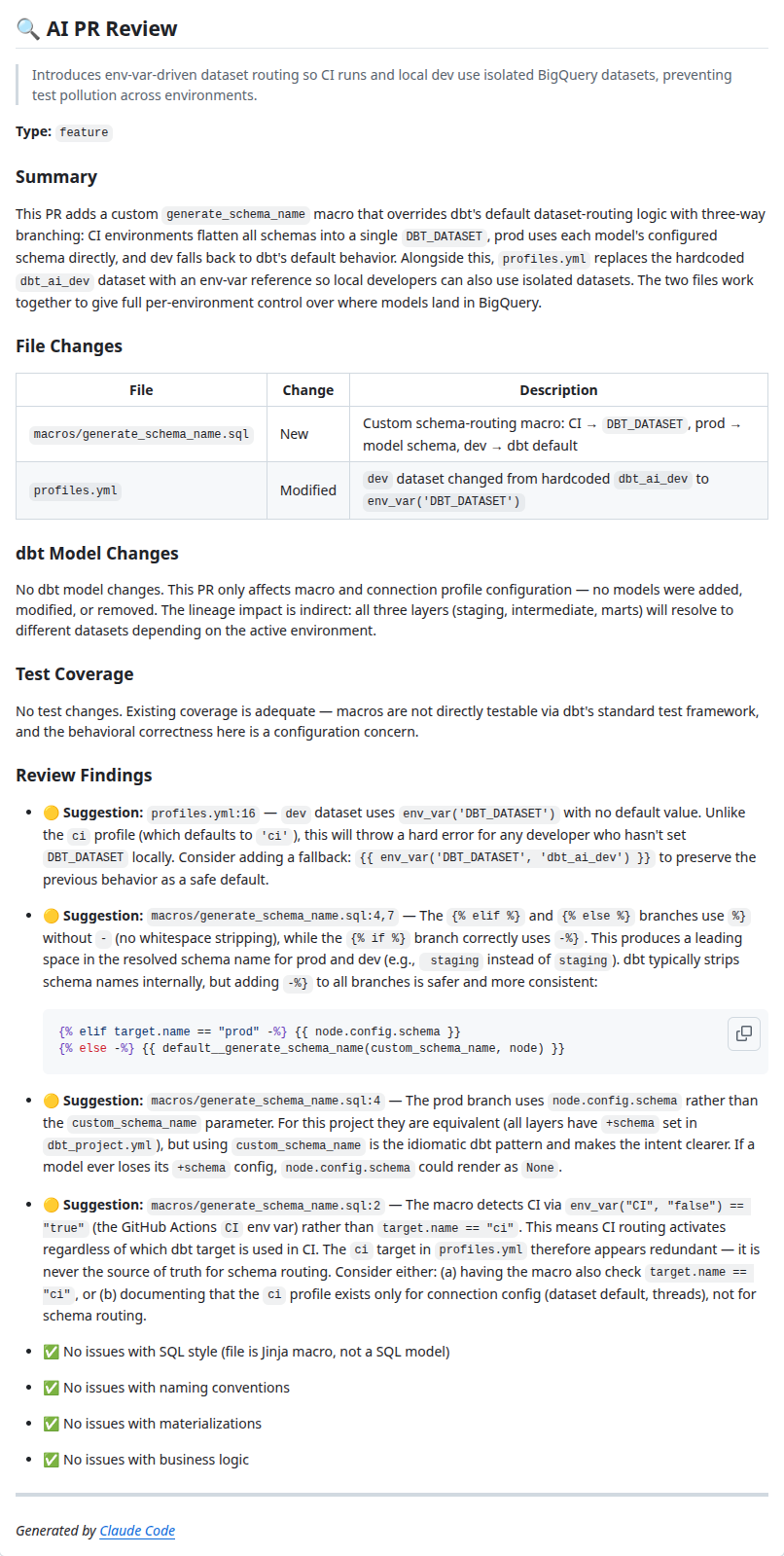
AI PR Rückblick
Jede Pull-Anfrage wird von Claude, einem Senior dbt/Analytics Engineer, überprüft. Bei der Überprüfung werden SQL-Stil, Namenskonventionen, Testabdeckung, Vollständigkeit der Dokumentation usw. geprüft. Die Ergebnisse werden als PR-Kommentar mit folgenden Schweregraden veröffentlicht: 🔴 Problem für Fehler, 🟡 Verbesserungsvorschlag und ✅ Alles klar, um zu bestätigen, dass jede Kategorie geprüft wurde.
-
CI-Fehler beheben
Wenn die CI-Pipeline fehlschlägt, holt Claude die Protokolle der fehlgeschlagenen Aufträge ab, identifiziert die Ursache (unter Nennung des spezifischen Schritts, Modells oder Tests) und veröffentlicht einen PR-Kommentar mit einem konkreten Korrekturvorschlag und den lokalen Befehlen zur Überprüfung. So wird der Arbeitsablauf der Entwickler beschleunigt.
Hier ist ein vereinfachter Auszug aus dem AI PR Review Workflow:
- name: Analyze PR
uses: anthropics/claude-code-action@v1
with:
claude_code_oauth_token: ${{ secrets.CLAUDE_CODE_OAUTH_TOKEN }}
model: claude-opus-4-6
prompt: |-
You are a senior dbt/analytics engineer reviewing a PR.
Check for:
1. SQL Style: snake_case names, one column per line, CTEs over subqueries
2. Naming: stg_, int_, dim_, fct_ prefixes
3. Tests: not_null/unique on primary keys, relationships
4. Documentation: model and column descriptions
5. Performance: full table scans, missing incremental strategies
6. Business Logic: verify computed columns are correct
7. Materialisations: views for staging/intermediate, tables for marts
Ein wesentlicher Vorteil ist, dass die Claude-Instanz, die im GitHub-Workflow läuft, Zugriff auf dieselbe CLAUDE.md Datei, Slash-Befehle, Skills und Hooks hat, die sich in Ihrem Repo befinden. Alle Verbesserungen, die Sie an diesen Dateien für Ihren lokalen Entwicklungsworkflow vornehmen, kommen also auch Ihren automatisierten CI-Reviews zugute.
"Jede Verbesserung, die Sie für Ihren lokalen KI-Workflow vornehmen, verbessert auch Ihre automatisierten KI-Prüfungen."
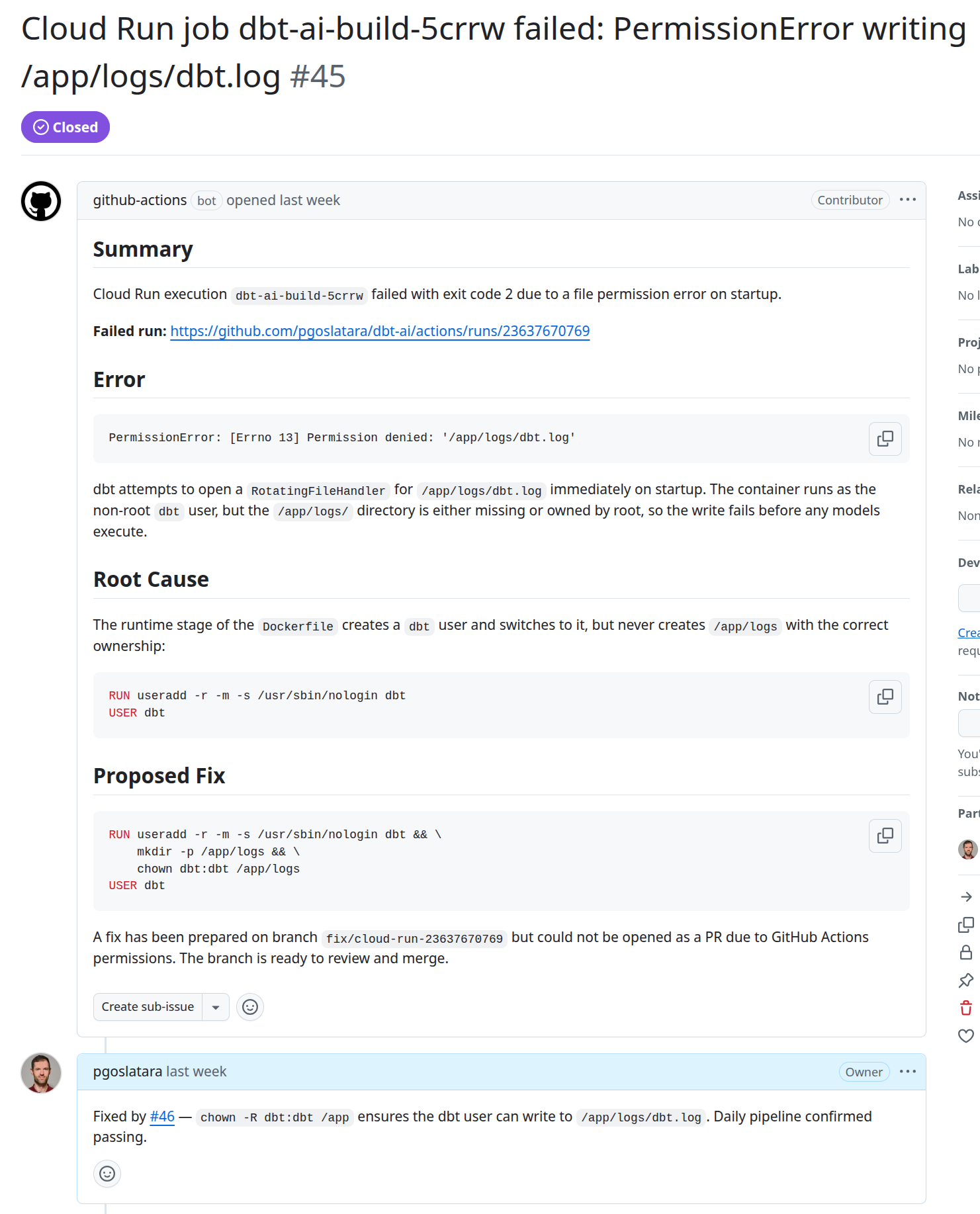
Bei Produktionsausfall
Wenn ein Cloud Run-Auftrag fehlschlägt, löst ein repository_dispatch -Webhook einen agentischen Workflow aus. Claude holt die Ausführungsdetails und Protokolle aus Cloud Logging ab, ermittelt die Ursache und erstellt entweder einen Korrektur-PR mit den erforderlichen Codeänderungen oder eröffnet einen GitHub-Problemfall(Beispiel), wenn es sich bei dem Fehler um ein Infrastrukturproblem und nicht um einen Codefehler handelt.
Dies ist besonders nützlich für dbt-Projekte, bei denen Pipelines über Nacht laufen. Wenn ein Entwickler seinen Arbeitstag beginnt, hat er bereits ein Problem oder eine Pull-Anfrage zu prüfen, das bzw. die sich auf den nächtlichen Fehler bezieht. Dadurch wird die Zeit bis zur Lösung des Problems verkürzt und der Entwickler muss sich nicht mehr um die Suche nach den entsprechenden Protokollen kümmern.
Sicherheit ist ein wichtiger Faktor bei einem Arbeitsablauf wie diesem. Indem Claude über die gcloud CLI und ein schreibgeschütztes Dienstkonto Zugriff auf die GCP-Dienste erhält, wird sichergestellt, dass es auf relevante Informationen zugreifen kann, ohne potenziell schädliche Änderungen vornehmen zu können. Ebenso verhindert die Einrichtung eines Zweigschutzes, dass Claude direkt auf main zusammengeführt wird und stellt sicher, dass der gesamte zusammengeführte Code von einem Menschen überprüft wurde.
Planmäßige Wartung
Drei wöchentliche Workflows laufen jeden Montag:
-
Erkennung verlassener Modelle
Vergleicht das dbt-Manifest mit den tatsächlichen BigQuery-Datensätzen, um verwaiste Tabellen zu finden, die nicht mehr im Projekt definiert sind, und generiert in einer GitHub-Ausgabe Bereinigungs-SQL.
-
Codebase Überprüfung
Claude analysiert die gesamte Codebasis auf Verstöße gegen die Best Practices von dbt - undokumentierte Modelle, Verstöße gegen die Namenskonventionen, falsche Materialisierungen, fehlende Verträge in Marts - und erstellt ein kategorisiertes GitHub-Problem. Dies ist besonders nützlich bei dbt-Projekten mit vielen Entwicklern, da die Gefahr, dass Code, der nicht den Best Practices entspricht, zusammengeführt wird, größer ist.
-
Überwachung der Datenqualität
Fragt BigQuery-Produktionsdaten nach statistischen Anomalien ab, z. B. Volumenspitzen, Ausreißer bei der Dauer und Probleme mit der Datenfrische, und erstellt eine GitHub-Ausgabe mit KI-analysierten Ergebnissen. Dies ist vor allem für dbt-Projekte interessant, die unter minderwertigen Quelldaten leiden, die häufig analysiert werden müssen, um sicherzustellen, dass sie noch den Erwartungen entsprechen.
Fazit
KI wird die Analysetechniker nicht ersetzen, aber Analysetechniker, die KI effektiv nutzen, werden diejenigen, die dies nicht tun, überflügeln. Die Einrichtung Ihres dbt-Projekts für die KI-gestützte Entwicklung ist keine einmalige Angelegenheit. Angesichts der rasanten Verbesserungen in diesem Bereich handelt es sich um einen fortlaufenden Prozess der Kodierung von Konventionen, der Hinzufügung von Funktionen und der Verfeinerung von Arbeitsabläufen. Daher wird einiges von dem, was in diesem Beitrag vorgestellt wird, wahrscheinlich schon in sechs Monaten veraltet sein, wenn sich die Werkzeuge weiterentwickeln.
Der hier beschriebene Ansatz - CLAUDE.md für Konventionen, MCP für Werkzeuge, Fähigkeiten und Befehle für die interaktive Entwicklung und agentenbasierte Workflows für die Automatisierung - bietet einen praktischen Rahmen für die Einbindung von KI in jede Phase Ihres dbt-Lebenszyklus. Fangen Sie klein an, iterieren Sie und sorgen Sie dafür, dass Menschen sich auf das konzentrieren, was sie am besten können: das Geschäft verstehen und Architekturentscheidungen treffen.
Das vollständige Demo-Repository finden Sie unter github.com/pgoslatara/dbt-ai.
Möchten Sie KI in Ihre dbt-Workflows integrieren? Unsere Berater für Analytik-Ingenieure helfen Ihnen gerne weiter - kontaktieren Sie uns einfach und wir melden uns bei Ihnen. Oder sind Sie ein Analytik-Ingenieur und möchten mehr erfahren? Schauen Sie sich unsere Trainingskurse an oder werfen Sie einen Blick auf unsere offenen Stellen.
Verfasst von
Pádraic Slattery
Pádraic is a technical-minded engineer passionate about helping organizations derive business value from data. With experience in data engineering, Business Intelligence development, and data analysis, he specializes in data ingestion pipelines and DataOps.
Unsere Ideen
Weitere Blogs




Contact