Blog
Einrichten des neuen dbt Semantic Layer und Testen mit DBeaver

Eine einzige, zuverlässige Quelle der Wahrheit ist das, was sich jedes Unternehmen und jeder Entscheidungsträger wünscht. Das ist es auch, was wir als Datenexperten anstreben. Wie können wir sicherstellen, dass zwei verschiedene Dashboards oder andere Datenkonsumenten die Metriken (z.B. Umsatz) auf die gleiche Weise berechnen? Wenn Sie die Definitionen von Metriken aus der BI- und Verbrauchsschicht in die Modellierungsschicht verlagern, können Datenteams und Stakeholder sicher sein, dass verschiedene Geschäftseinheiten mit denselben Metrikdefinitionen arbeiten, unabhängig vom Tool ihrer Wahl. Wenn sich eine Metrikdefinition ändert, wird sie überall, wo sie aufgerufen wird, aktualisiert und schafft Konsistenz in allen Anwendungen.
Hier spielt eine semantische Schicht eine wichtige Rolle. Dabei handelt es sich um eine virtuelle Schicht, die zwischen den Rohdaten und dem Endbenutzer steht und eine vereinfachte und einheitliche Sicht auf die Daten bietet. Sie fungiert als Übersetzungsschicht und wandelt komplexe Datenquellen in ein verständlicheres und geschäftsfreundlicheres Format um. Die semantische Schicht abstrahiert die Komplexität der zugrundeliegenden Datenstrukturen und ermöglicht es den Benutzern, mit den Daten unter Verwendung vertrauter Geschäftsbegriffe und Konzepte zu interagieren.
Zusammenfassend lässt sich sagen, dass die semantische Schicht eine entscheidende Rolle bei der Verbesserung der Datenzugänglichkeit, -konsistenz und -verwendbarkeit spielt, was sie zu einer wesentlichen Komponente in modernen Datenverwaltungs- und Analysearchitekturen macht.
Semantische Schicht in dbt
In der neuesten Version (Stand: Sep/23 - v1.6 ) hat dbt den Semantic Layer neu aufgelegt, der jetzt von MetricFlow unterstützt wird (mehr über MetricFlow finden Sie hier ).
Dieses Update vereinfacht den Prozess der Definition und Verwendung wichtiger Geschäftsmetriken durch die Zentralisierung von Metrikdefinitionen. Wenn sich eine Metrikdefinition in dbt ändert, wird sie automatisch überall dort aktualisiert, wo sie verwendet wird, so dass die Konsistenz in allen Anwendungen gewährleistet ist.
Paradigmenwechsel bei der Datenmodellierung
Das Konzept der OBT (One Big Table) wurde von den dbt-Entwicklern weitgehend übernommen und denormalisiert die Daten in den einzelnen Schichten, von Staging , bis zwischen und marts . Wenn die Projekte jedoch wachsen, entstehen mehrere große Tabellen, was zu doppelten Metriken an verschiedenen Stellen führt und die Komplexität und den Wartungsaufwand erhöht.
Der neue dbt Semantic Layer führt einen Paradigmenwechsel ein, indem er normalisierte Daten anstelle von denormalisierten verwendet. Semantische Modelle , Dimensionen und Metriken definiert sind, während MetricFlow den Rest erledigt, was einen effizienteren und schlankeren Ansatz gewährleistet. Für eine Semantic Layer-Implementierung ist es üblich - und allgemein empfohlen -, direkt eine Inszenierung Modell anstelle eines mart zum Aufbau des Semantisches Modell und Metriken .
Einrichten der dbt-Semantikschicht
Diese Anleitung wurde auf der Grundlage diesem offiziellen Beitrag von dbt.
Verwenden wir dieses Repository als Referenz für unsere Semantic Layer-Implementierung. Dort haben wir ein einfaches dbt-Projekt, das grundlegende Transformationen in einer öffentlichen Datenbank für Taxifahrten in NYC durchführt. Das Projekt ist mit den empfohlenen Ebenen angelegt - Quelle → Inszenierung → Zwischenstufe → Märkte . Für dieses Beispiel halten wir die Dinge einfach und erstellen unsere Semantische Modelle und Metriken unter Verwendung eines mart .
Alle Definitionen der semantischen Ebene ( semantic_models und Metriken ), werden in den .yml-Dateien abgelegt. Dadurch erhöht sich die Anzahl der Zeilen exponentiell, so dass wir statt einer einzigen .yml für jeden Ordner eine Datei für jedes Modell erstellen werden.
Um unsere Implementierung zu beginnen, lassen Sie uns einchecken. zum start-here Zweig.
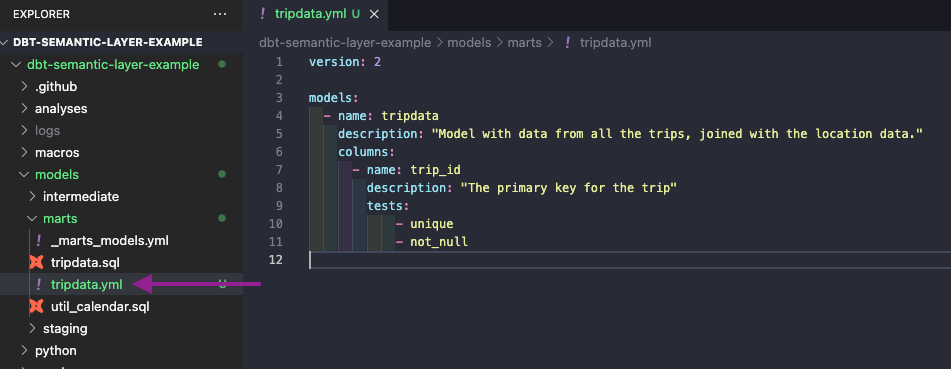
Zunächst erstellen wir eine neue Datei namens tripdata.yml und verschieben unsere aktuellen Konfigurationen der tripdata Modells dorthin.
Als Nächstes beginnen wir mit der Erstellung unserer semantischen Modelldefinitionen.
Es gibt zwei Hauptbestandteile für unsere Semantic Layer-Einstellungen: semantic_models und Metriken .
Wir beginnen mit der Definition der Datei semantischen_Modelle .
semantic_models:
- name: tripdata
defaults:
agg_time_dimension: pickup_date
description: |
Tripdata fact table. This table is at the trip grain with one row per trip.
#The name of the dbt model and schema
model: ref('tripdata')
Verschachtelt in semantischen_modellen definiert, werden wir Entitäten , Maßnahmen und Dimensionen .
Bei den Entitäten entsprechen diese den Schlüsseln einer Tabelle. Die Entitäten werden auch verwendet, um verschiedene Tabellen zu verbinden. Normalerweise werden die ids Spalten sind als Entitäten definiert.
entities:
- name: trip_id
type: primary
- name: vendor
type: foreign
expr: vendor_id
- name: pickup_location
type: foreign
expr: pickup_location_id
- name: dropoff_location
type: foreign
expr: dropoff_location_id
Als nächstes werden wir die Maßnahmen . Hier legen wir fest, wie unsere Daten aggregiert werden sollen. Wir können zum Beispiel definieren, Summe für numerische Spalten, zählen und count_distinct .
Sie können sich vorstellen Maßnahmen wie die Aggregationsfunktionen in SQL (SUM, COUNT, etc.)
measures:
- name: total_amount
description: The total value for each trip.
agg: sum
- name: trip_count
expr: 1
agg: sum
- name: tip_amount
description: The total tip paid on each trip.
agg: sum
- name: passenger_count
description: The total number of passengers on each trip.
agg: sum
Für die Abmessungen definieren sie die Granularität unserer Metriken. Mit den folgenden Parametern können wir zum Beispiel die gesamt_betrag für jede Abholung_Gemeinde , oder abhol_datum .
Sie können sich vorstellen Dimensionen als die Spalten, die in einer Gruppe von in SQL.
dimensions:
- name: pickup_date
type: time
type_params:
time_granularity: day
- name: pickup_borough
type: categorical
- name: dropoff_borough
type: categorical
- name: traject_borough
type: categorical
Schließlich setzen wir die Metriken . Sie sind das, was für die Verbraucher sichtbar sein wird, aufbauend auf misst und andere Metriken .
Es gibt mehrere Optionen und Einstellungen für Metriken ( Filter , Typen , typ_params , etc), können Sie alle überprüfen hier .
Lassen Sie uns für dieses Beispiel ein einfaches Beispiel erstellen.
metrics:
- name: total_amount
description: Sum of total trip amount.
type: simple
label: Total Amount
type_params:
measure: total_amount
Unsere endgültige tripdata.yml Datei sollte wie folgt aussehen.
version: 2
models:
- name: tripdata
description: "Model with data from all the trips, joined with the location data."
columns:
- name: trip_id
description: "The primary key for the trip"
tests:
- unique
- not_null
semantic_models:
- name: tripdata
defaults:
agg_time_dimension: pickup_date
description: |
Tripdata fact table. This table is at the trip grain with one row per trip.
#The name of the dbt model and schema
model: ref('tripdata')
entities:
- name: trip_id
type: primary
- name: vendor
type: foreign
expr: vendor_id
- name: pickup_location
type: foreign
expr: pickup_location_id
- name: dropoff_location
type: foreign
expr: dropoff_location_id
measures:
- name: total_amount
description: The total value for each trip.
agg: sum
- name: trip_count
expr: 1
agg: sum
- name: tip_amount
description: The total tip paid on each trip.
agg: sum
- name: passenger_count
description: The total number of passengers on each trip.
agg: sum
dimensions:
- name: pickup_date
type: time
type_params:
time_granularity: day
- name: pickup_borough
type: categorical
- name: dropoff_borough
type: categorical
- name: traject_borough
type: categorical
metrics:
- name: total_amount
description: Sum of total trip amount.
type: simple
label: Total Amount
type_params:
measure: total_amountSie können den Code, den wir bisher haben, in der Verzweigung sehen create-semantic-layer .
Das war's, unsere erste Semantic Layer-Metrik ist fertig!
Es fehlt nur noch eine Sache, damit es funktioniert: MetricFlow benötigt eine metricflow_time_spine.sql Modell, damit der Semantische Layer richtig funktioniert. Daher werden wir es in der marts Ordner.
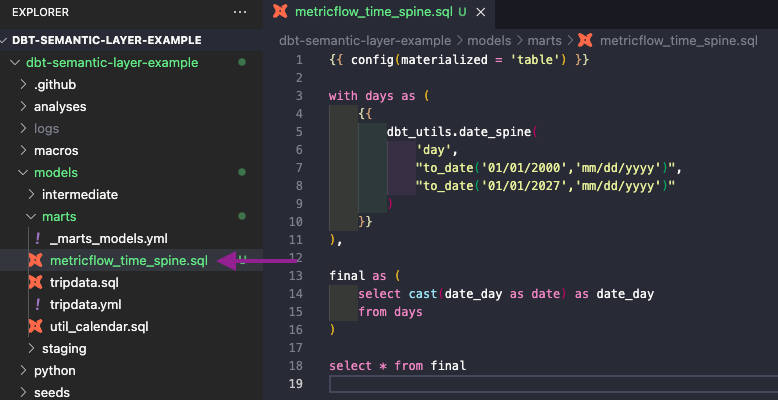
Sie können den folgenden Code in dem neuen Modell verwenden. Er erfordert die dbt_utils Paket, das Sie in Ihrer packages.yml Datei hinzufügen können (Anleitung hier ).
{{ config(materialized = 'table') }}
with days as (
{{
dbt_utils.date_spine(
'day',
"to_date('01/01/2000','mm/dd/yyyy')",
"to_date('01/01/2027','mm/dd/yyyy')"
)
}}
),
final as (
select cast(date_day as date) as date_day
from days
)
select * from finalSie können den Code, den wir bisher haben, in der Verzweigung sehen create-time-spine .
Jetzt müssen wir unsere Änderungen nur noch festschreiben und veröffentlichen.
Derzeit wird die Verbindung zum Semantic Layer nur über die dbt Cloud unterstützt, daher werden wir im nächsten Abschnitt diesen Weg einschlagen.
Einrichten der dbt Cloud Semantic Layer
Bevor wir beginnen, müssen wir einige Bedingungen erfüllen, um den Semantic Layer in dbt Cloud zu konfigurieren. Sie können sie hier nachlesen hier .
Zunächst konfigurieren wir die Anmeldeinformationen, die der Semantic Layer für die Verbindung mit dem Data Warehouse verwenden wird. Dazu müssen wir navigieren zu Kontoeinstellungen → Projekte → [Wählen Sie Ihr Projekt] → Semantische Schicht konfigurieren .
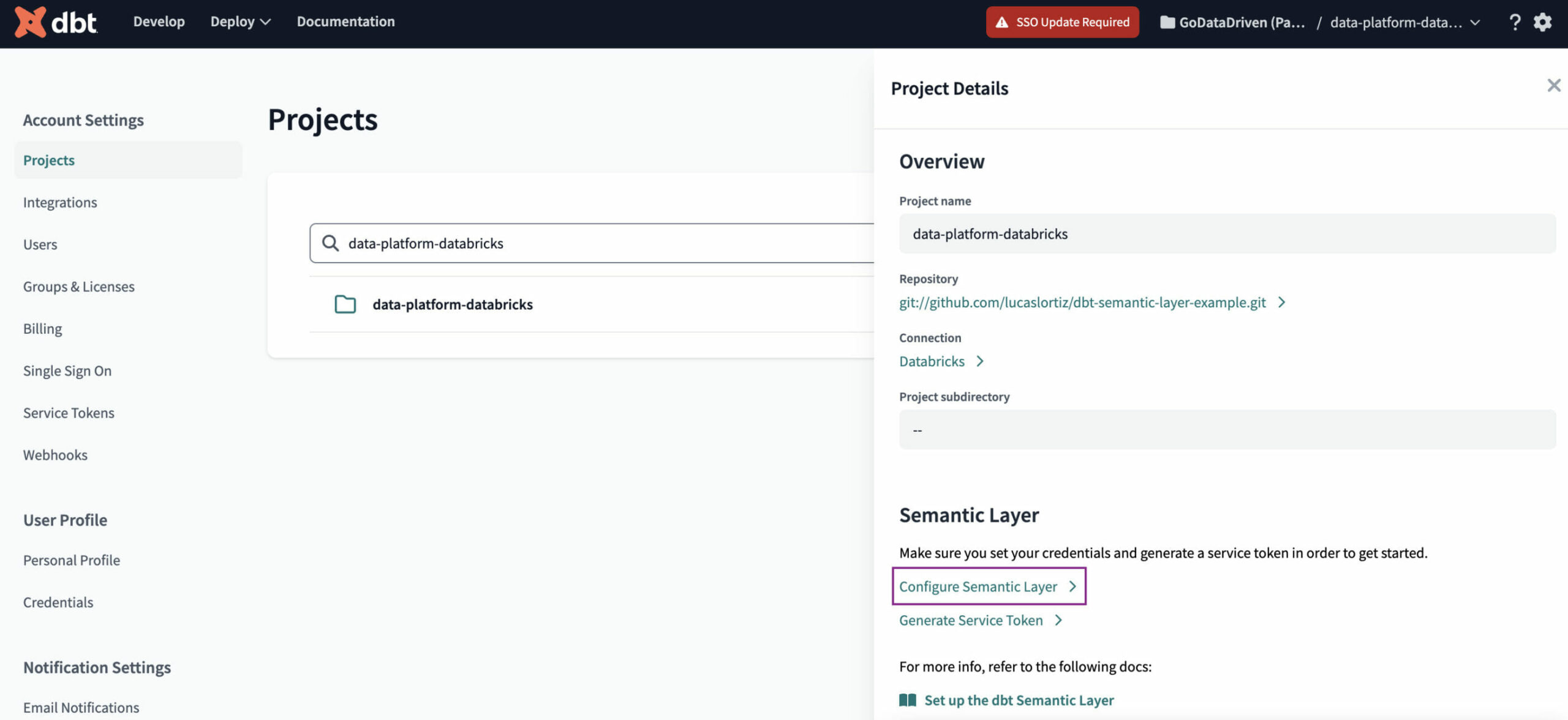
Je nachdem, welches Warehouse Sie verwenden, können die Felder, die Sie ausfüllen müssen, unterschiedlich sein. In unserem Fall haben wir Databricks verwendet, daher müssen wir ein Token und einen Katalog (bei Verwendung von Unity Catalog) angeben.
Für die Umgebung wählen Sie die Produktion ein - Prod in unserem Fall.
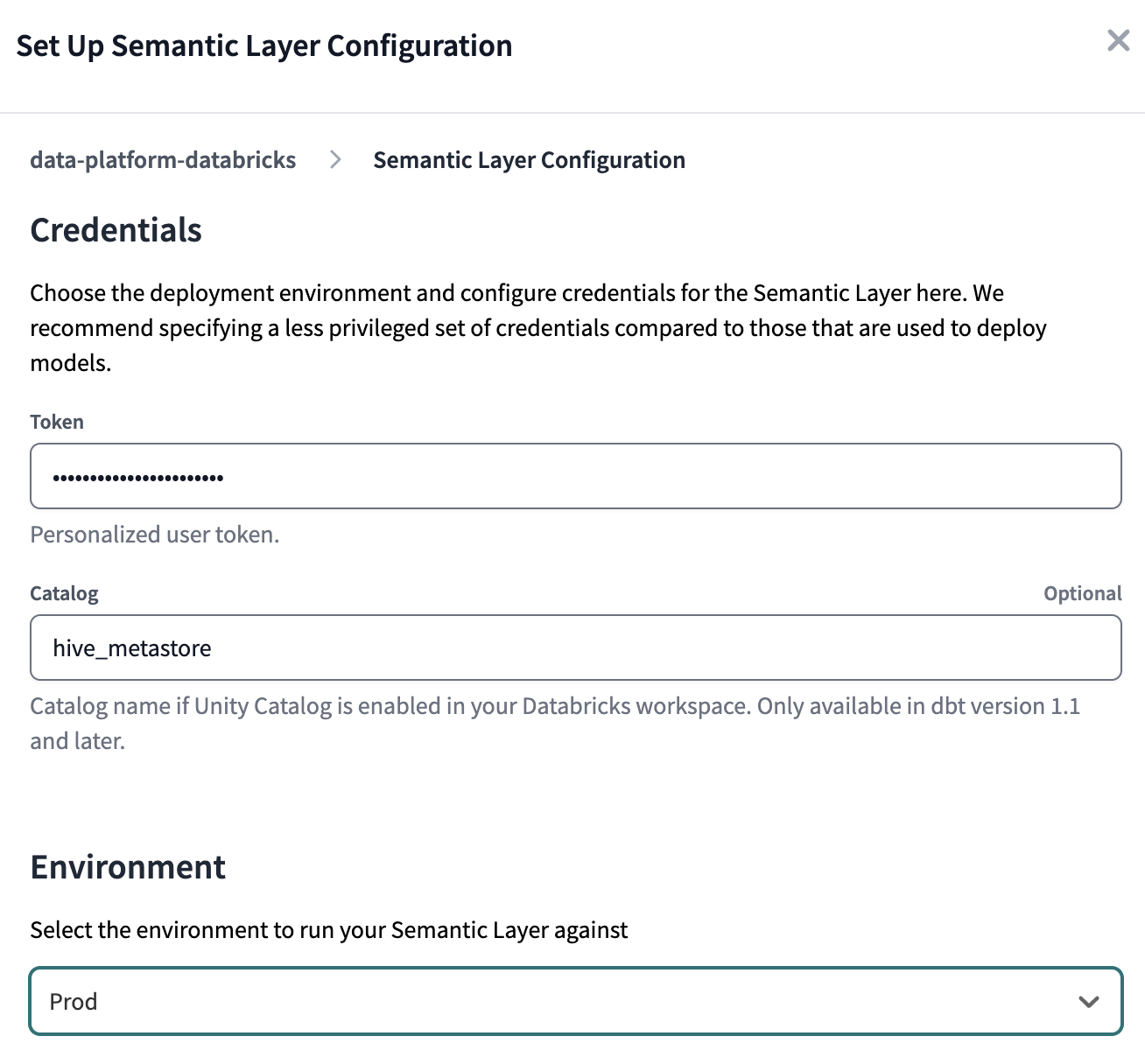
Sobald die Anmeldedaten korrekt eingestellt sind, werden die Details der semantischen Schicht sichtbar. Wir speichern die Umgebungs-ID Wert für die spätere Verwendung.
Schließlich erzeugen wir ein Service-Token, das für den Zugriff auf die Semantic Layer API der dbt Cloud verwendet wird.

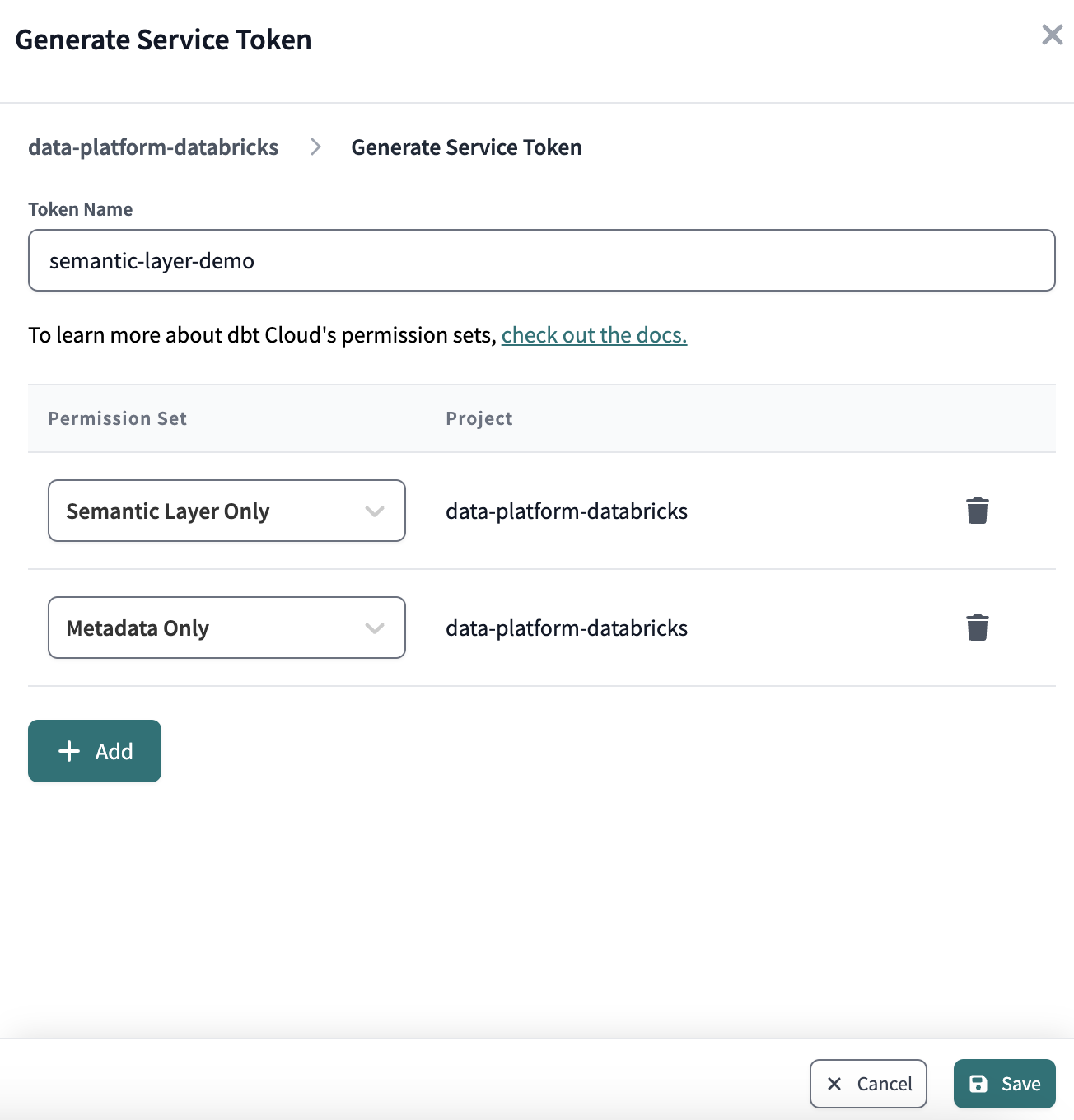
Kopieren Sie den Wert des Tokens, bevor Sie das Fenster schließen - er wird nur einmal angezeigt und wir werden ihn später noch benötigen.
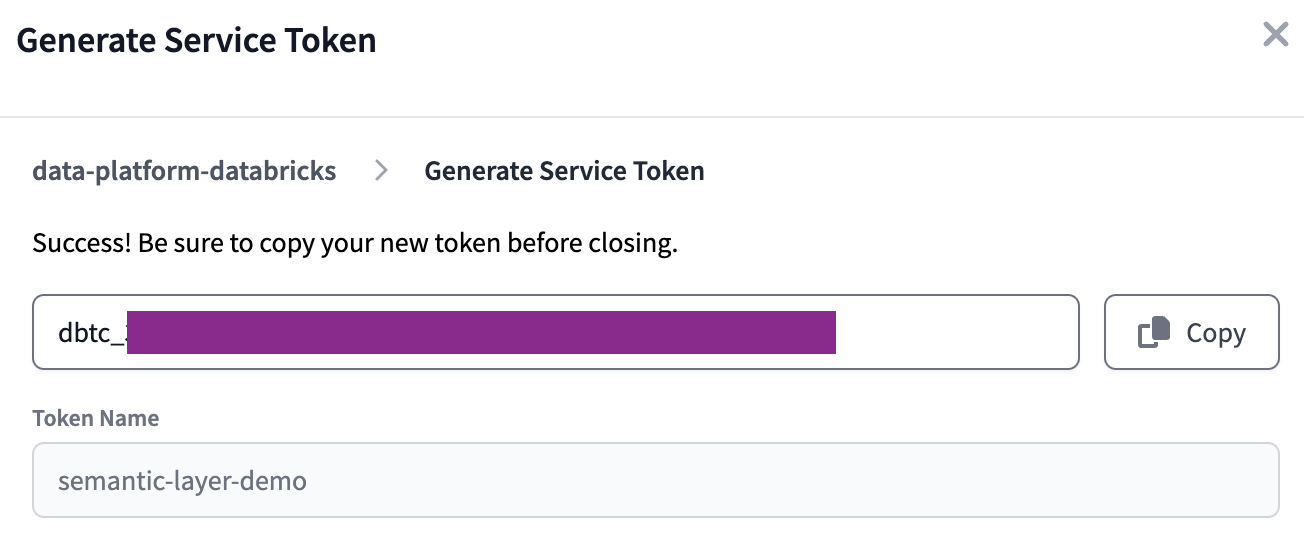
Das war's von Seiten der dbt Cloud! Wenn Sie möchten, können Sie auch zur Develop IDE navigieren und Ihre Abstammung überprüfen.
Die neue Metrik sollte dort zu finden sein und in etwa so aussehen.

Testen der dbt-Semantikschicht mit DBeaver
Jetzt, wo wir unsere erste metrischen definiert, wie können wir das Ergebnis tatsächlich sehen? Da es immer noch nur ein paar Integrationen verfügbarist es nicht so einfach, die Ergebnisse zu überprüfen. Da das Ziel dieser ersten Implementierung darin besteht, sich mit dem neuen dbt Semantic Layer vertraut zu machen, werden wir DBeaver verwenden, um uns mit ihm zu verbinden - natürlich ist dies keine produktionsreife Einrichtung, aber es handelt sich immerhin um eine öffentliche Beta des dbt Semantic Layer.
Der erste Schritt besteht darin, DBeaver herunterzuladen und auf Ihrem Computer zu installieren. Sie können es finden hier .
Für diese Einrichtung werden wir eine Verbindung zum dbt Semantic Layer mit ArrowFlightSQL herstellen. Der nächste Schritt ist daher der Download der neuesten Version des ArrowFlightSQL-Treibers. Sie finden ihn unter hier - Laden Sie Version 12 oder höher herunter.
Beachten Sie, dass Sie bei der Suche nach dem Treiber bei Google möglicherweise die Website von Dremio finden, die Sie zu einer älteren Version führt.

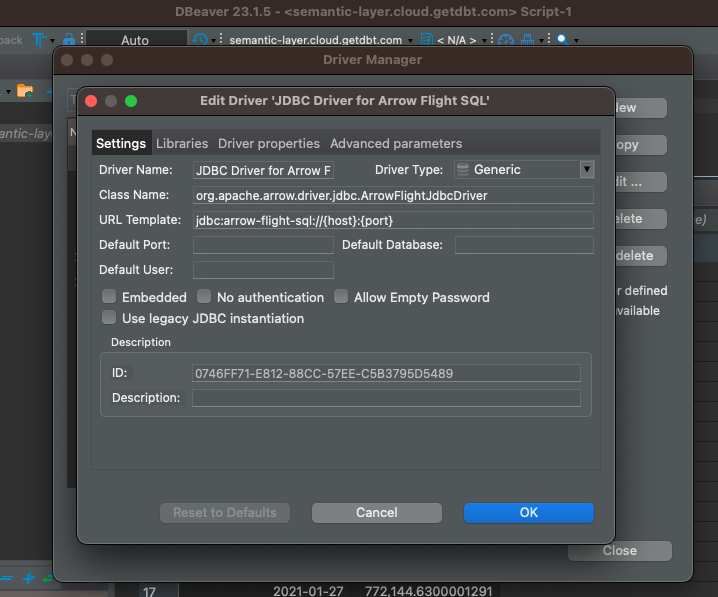
Als nächstes öffnen wir den Treiber-Manager auf der Registerkarte Datenbank und erstellen einen neuen Treiber. Wir stellen die Werte wie folgt ein.
Name des Treibers: JDBC Driver for Arrow Flight SQL
Treiber Typ: Generic
Name der Klasse: org.apache.arrow.driver.jdbc.ArrowFlightJdbcDriver
URL-Vorlage: jdbc:arrow-flight-sql://{host}:{port}
Auf der Registerkarte Bibliotheken klicken wir auf Datei hinzufügen und wählen den Treiber aus, den wir im vorherigen Schritt heruntergeladen haben.
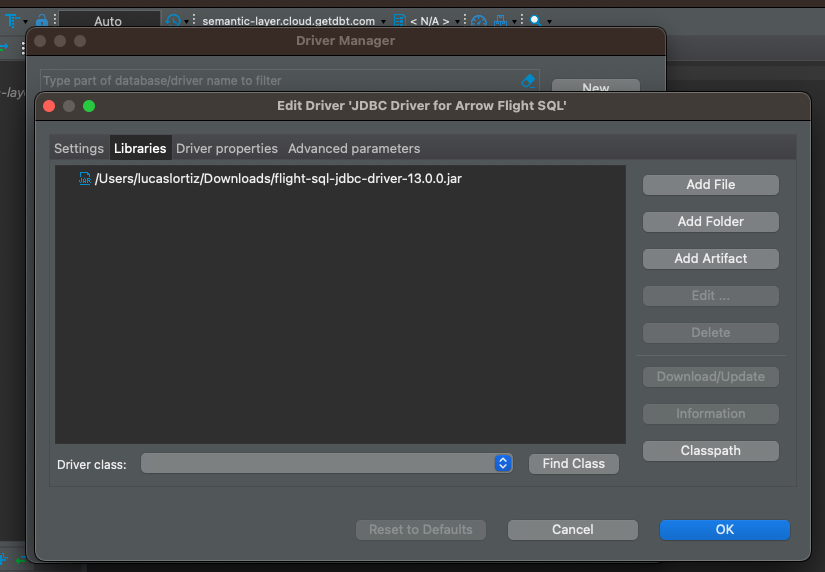
Nun ist es an der Zeit, unsere Verbindung zu erstellen. Wir klicken zunächst auf eine neue Verbindung und wählen Von JDBC Url...
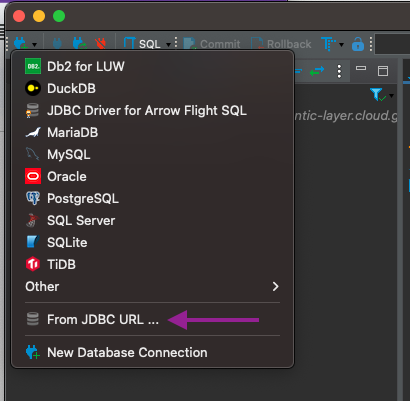
Wir setzen die URL als jdbc:arrow-flight-sql://semantic-layer.cloud.getdbt.com:443
Sobald wir diesen Wert eingeben, wird unser kürzlich erstellter Treiber automatisch geladen. Klicken Sie einfach auf Fortfahren.
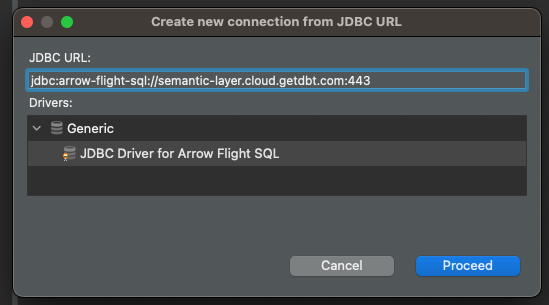
Jetzt werden wir die spezifischen Einstellungen für diese Verbindung vornehmen. Das Wichtigste dabei ist, dass Sie die richtigen Verbindungsparameter hinzufügen. Navigieren Sie dazu zur Seite Treiber-Eigenschaften klicken Sie mit der rechten Maustaste auf die Registerkarte Benutzereigenschaften und wählen Sie Neue Eigenschaft hinzufügen . Wir werden drei Eigenschaften erstellen: environmentId , token und useSystemTrustStore . Die ersten beiden haben wir im vorigen Abschnitt zusammengetragen, den letzten setzen wir als falsch.
Sobald alles eingestellt ist, klicken Sie auf Verbindung testen... und bestätigen Sie in dem sich öffnenden Fenster.
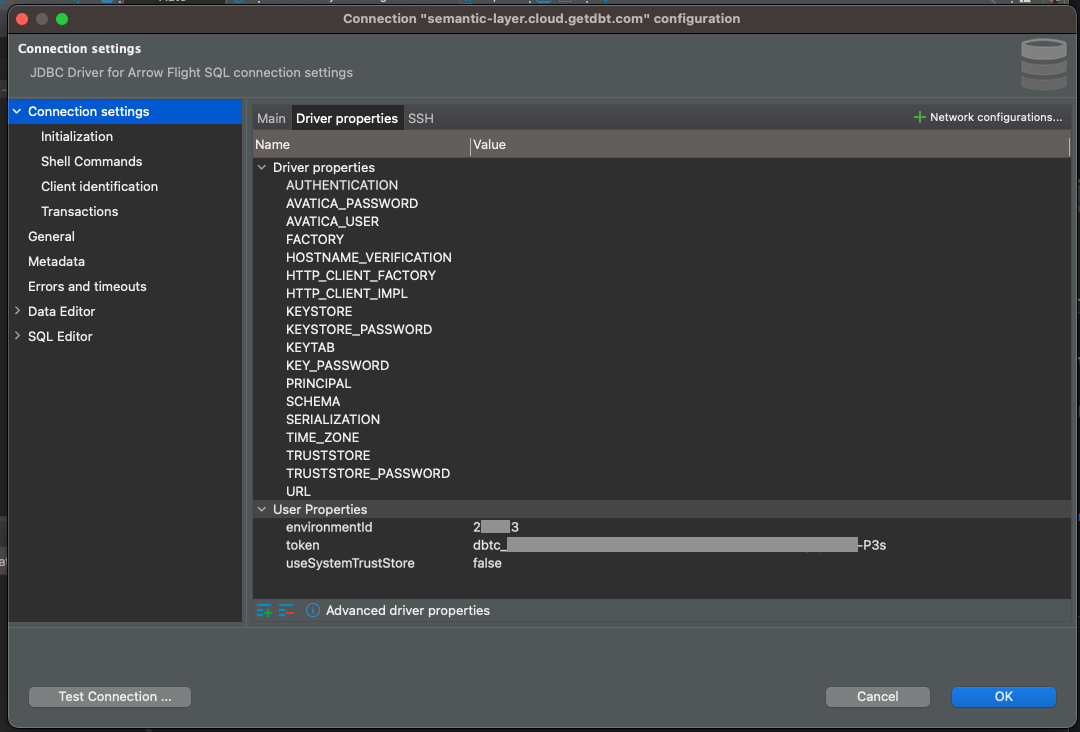
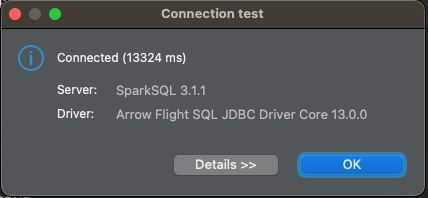
Das war's! Unsere Verbindung zum dbt Semantic Layer ist hergestellt. Jetzt müssen wir nur noch unsere Metriken abfragen.
Hier finden Sie alle Einzelheiten zur Abfrage Ihres dbt Semantic Layer, unten finden Sie zwei Beispiele.
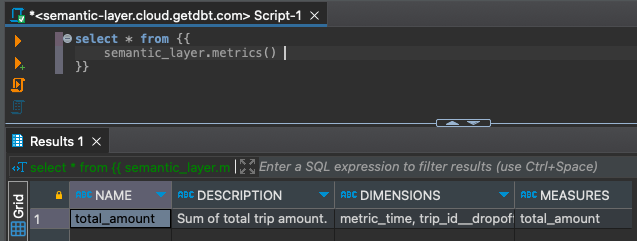
Um alle erstellten Metriken abzurufen.
select * from {{
semantic_layer.metrics()
}}
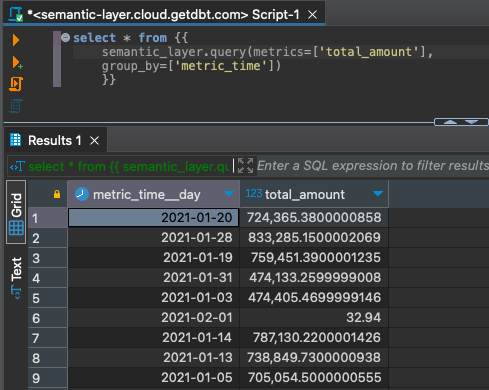
Zum Abrufen der Werte einer Metrik, gruppiert nach jedem Zeitkorn.
select * from {{
semantic_layer.query(metrics=['total_amount'],
group_by=['metric_time'])
}}
Fazit
Die Implementierung einer semantischen Schicht bietet zahlreiche Vorteile für die Datenverwaltung in Projekten jeder Größe. Durch die Zentralisierung von Metrikdefinitionen und die Normalisierung von Daten vereinfacht ein Semantic Layer den Prozess der Definition und Verwendung wichtiger Geschäftsmetriken und gewährleistet gleichzeitig die Konsistenz zwischen verschiedenen Anwendungen.
In diesem Sinne kann der dbt Semantic Layer ein wertvoller Verbündeter bei der Sicherstellung der korrekten Quelle der Wahrheit werden. Es handelt sich um eine neue Funktion, für die noch viele Entwicklungen, Best Practices und Verbesserungen erforderlich sind. Aber je früher Sie sich mit dem Tool und den Konzepten vertraut machen, desto besser werden Sie in der Lage sein, es produktionsgerecht zu implementieren, wenn sich der Markt weiterentwickelt.
Verfasst von
Lucas Ortiz
I've always been fascinated by technology and problem-solving. Great challenges are what keep me motivated, I rarely accept that a task can’t be done, it’s only a matter of finding new paths to solve the puzzle.
Unsere Ideen
Weitere Blogs




Contact